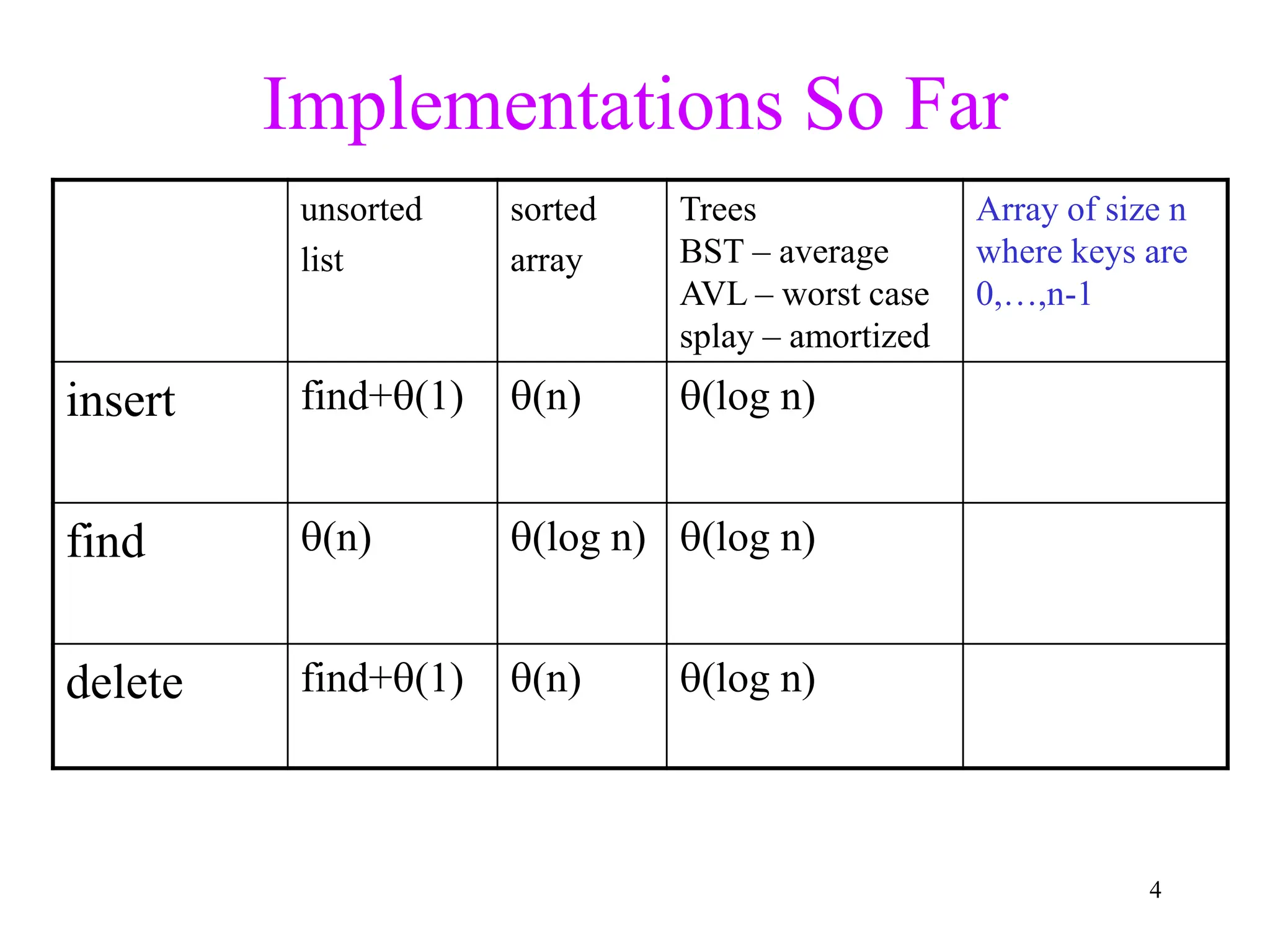
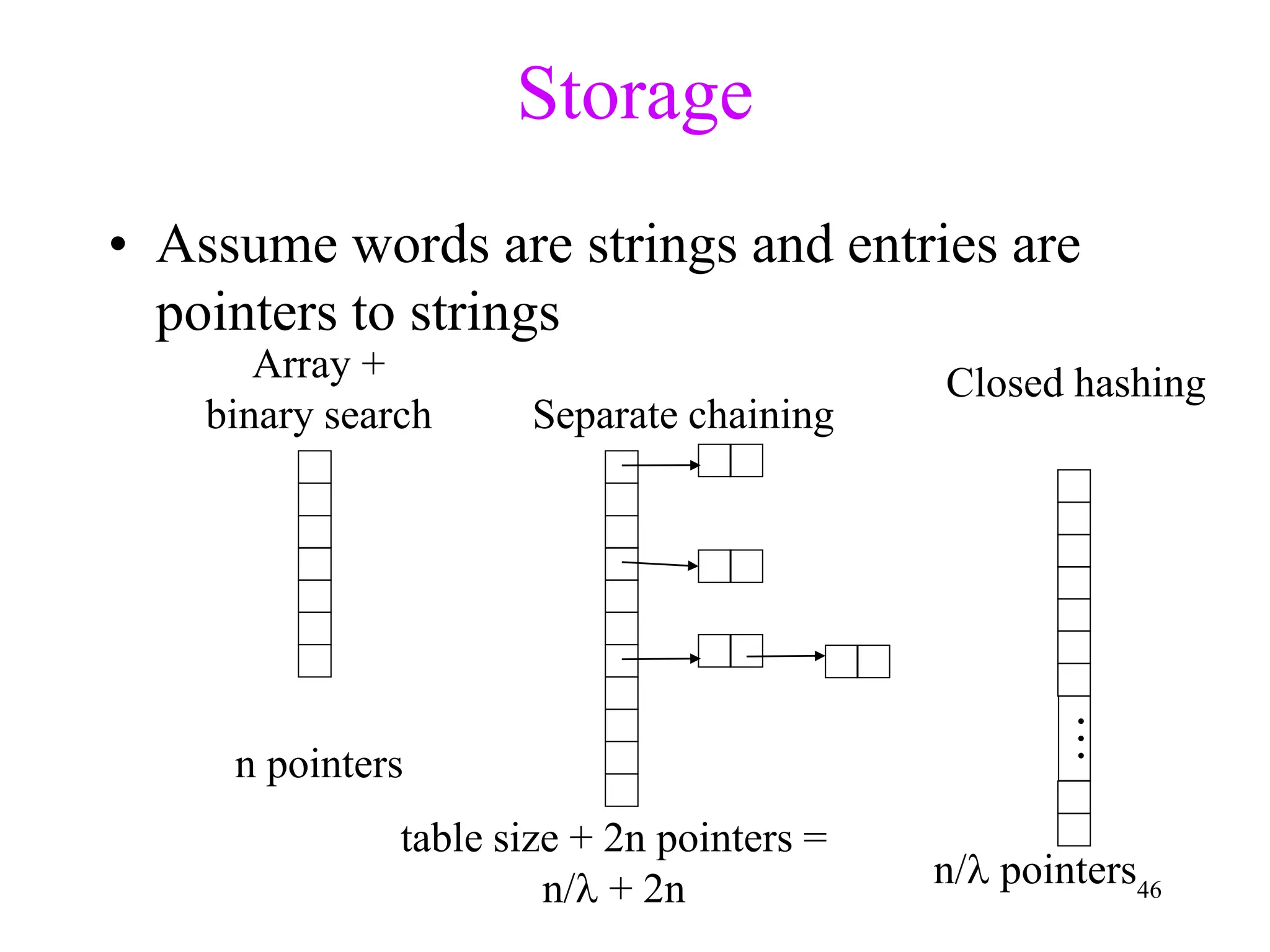
1. The document discusses hashing techniques for implementing dictionaries and search data structures, including separate chaining and closed hashing (linear probing, quadratic probing, and double hashing).
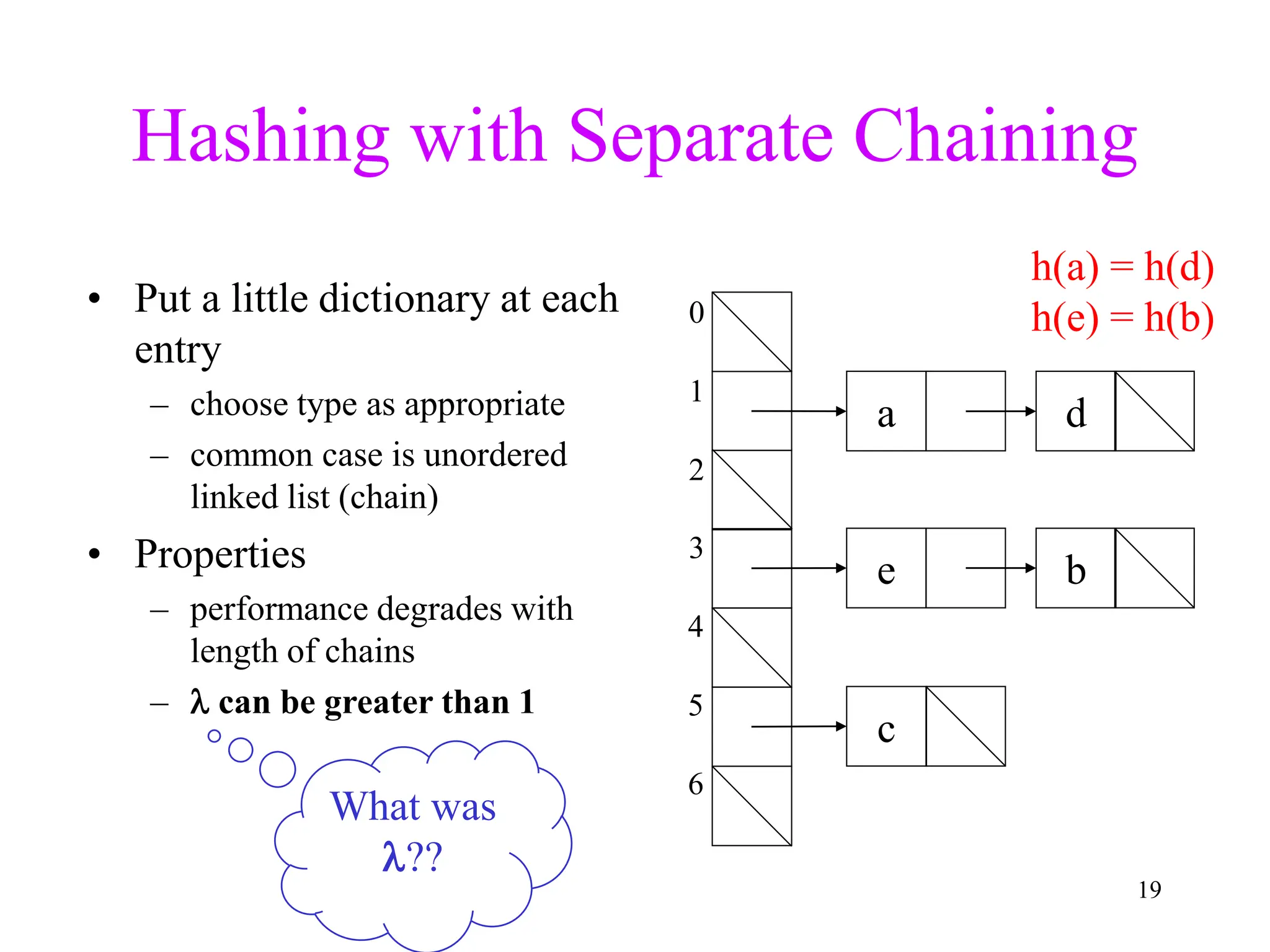
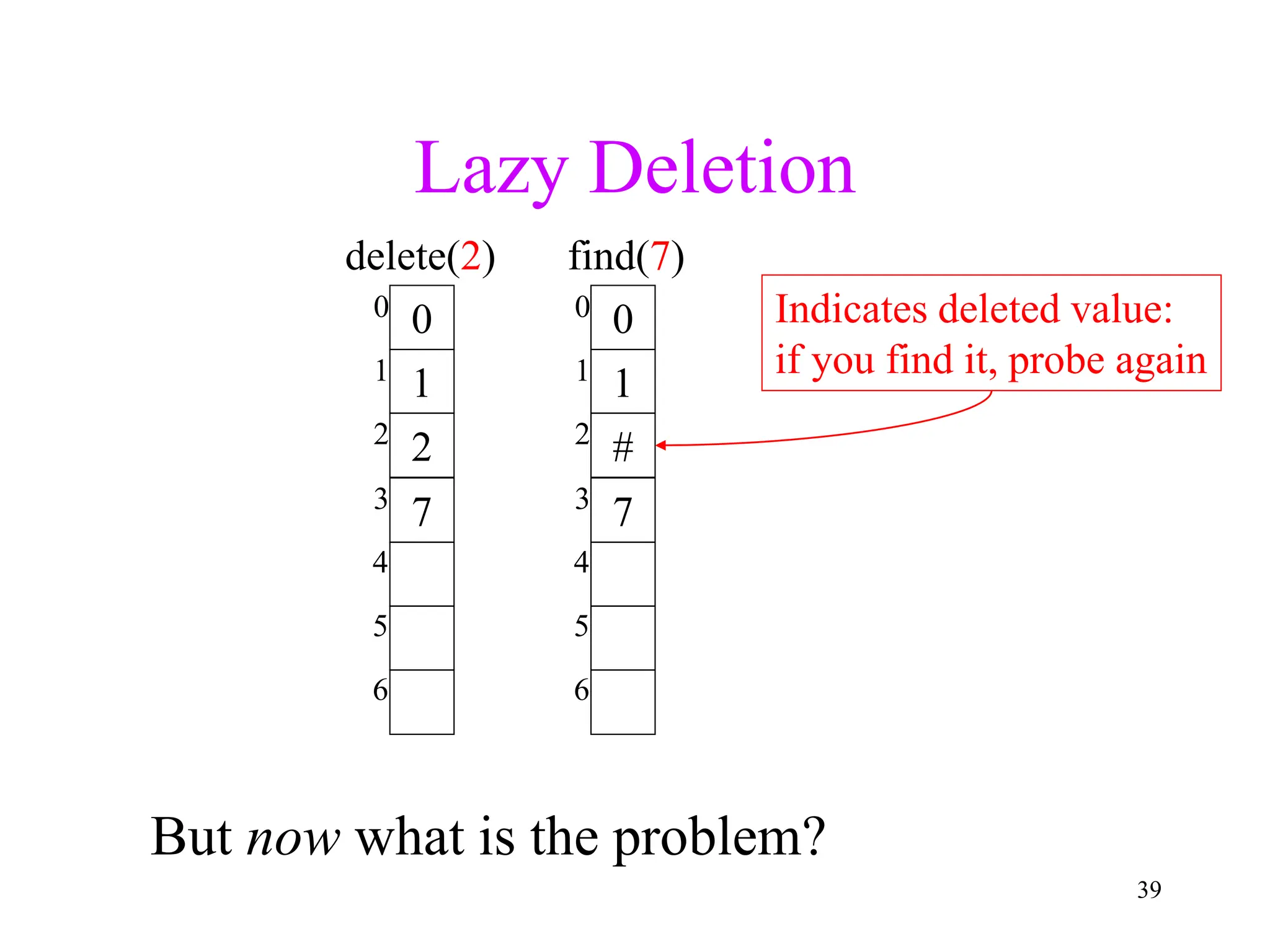
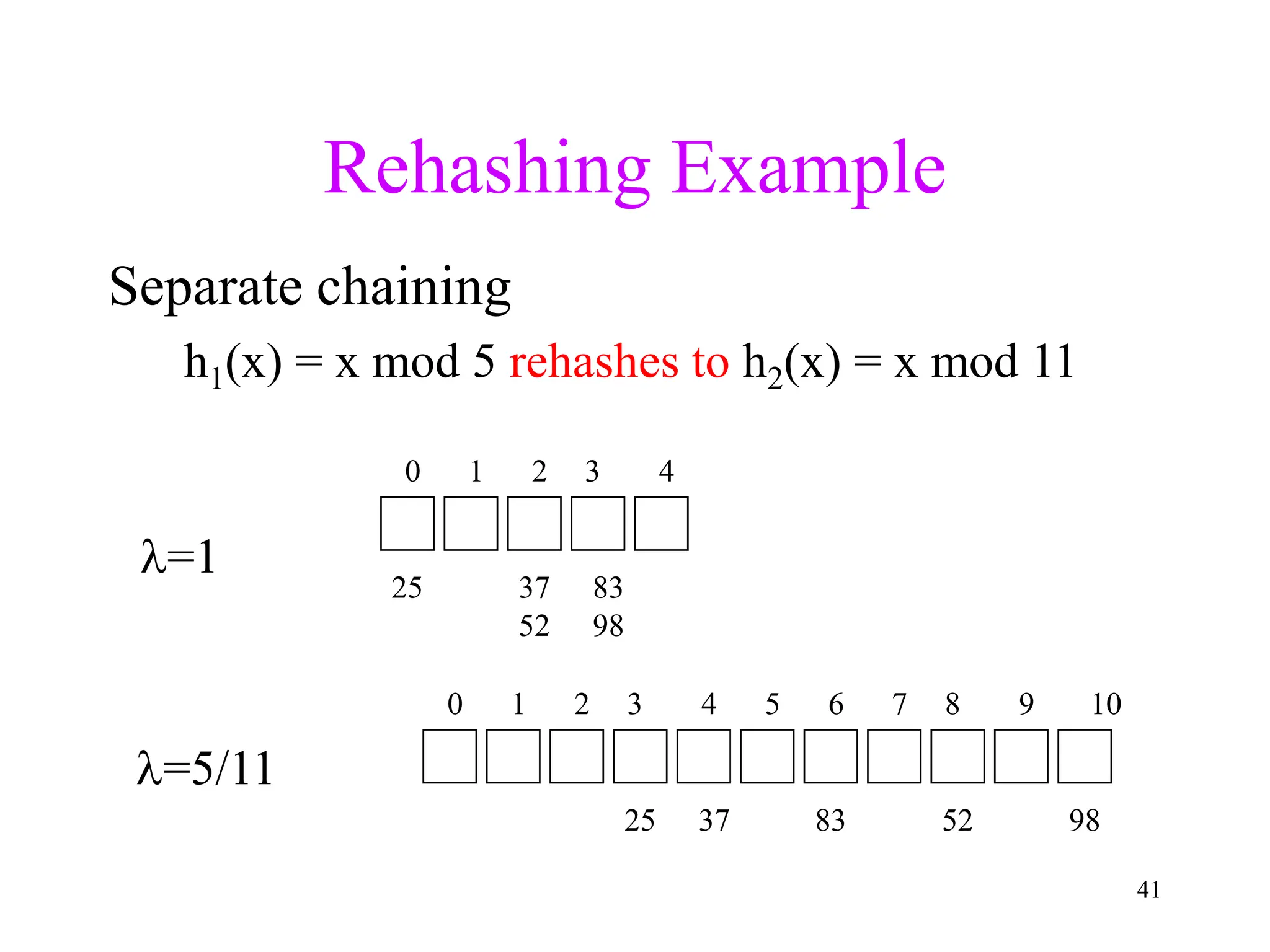
2. Separate chaining uses a linked list at each index to handle collisions, while closed hashing searches for empty slots using a collision resolution function.
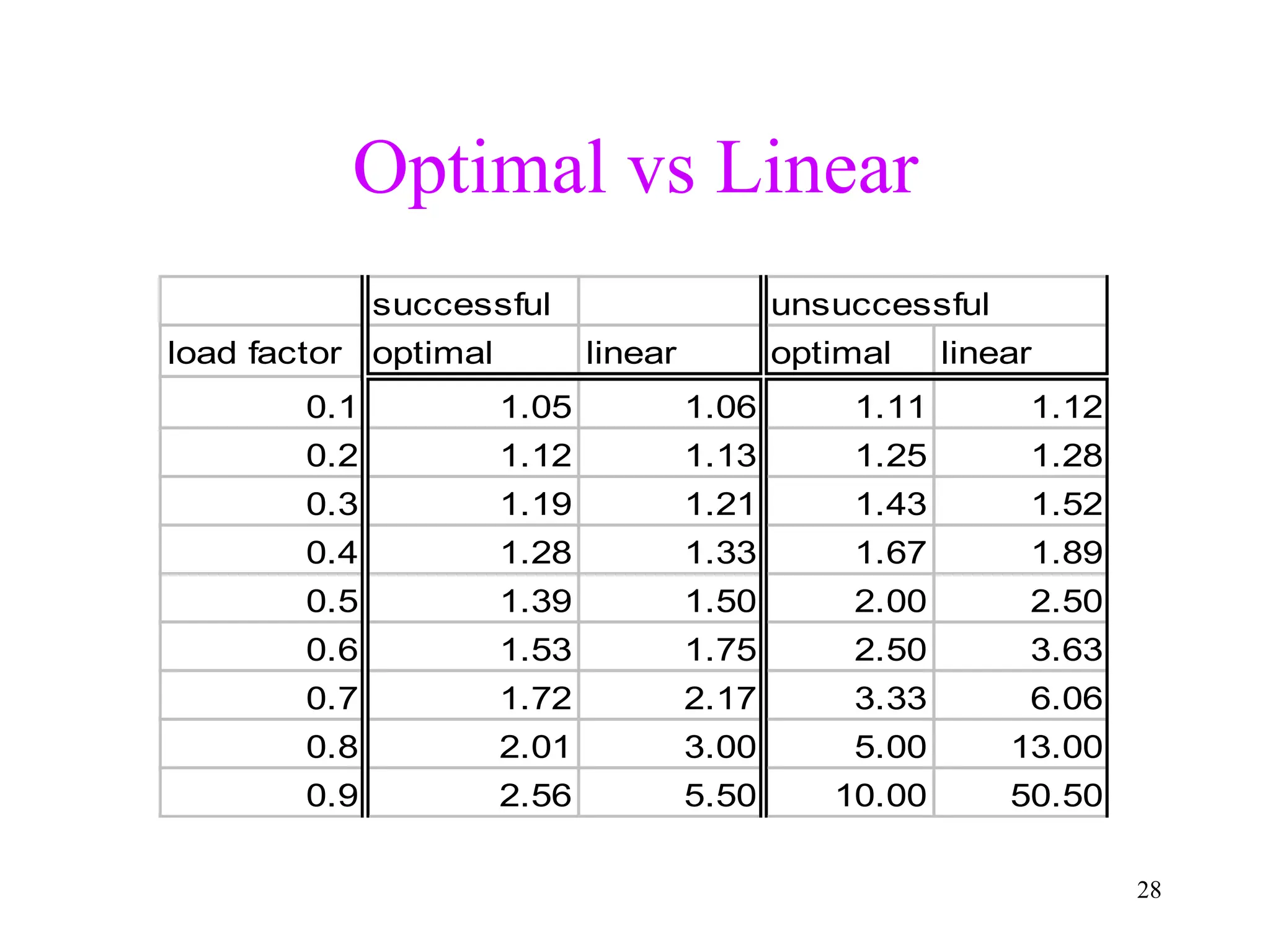
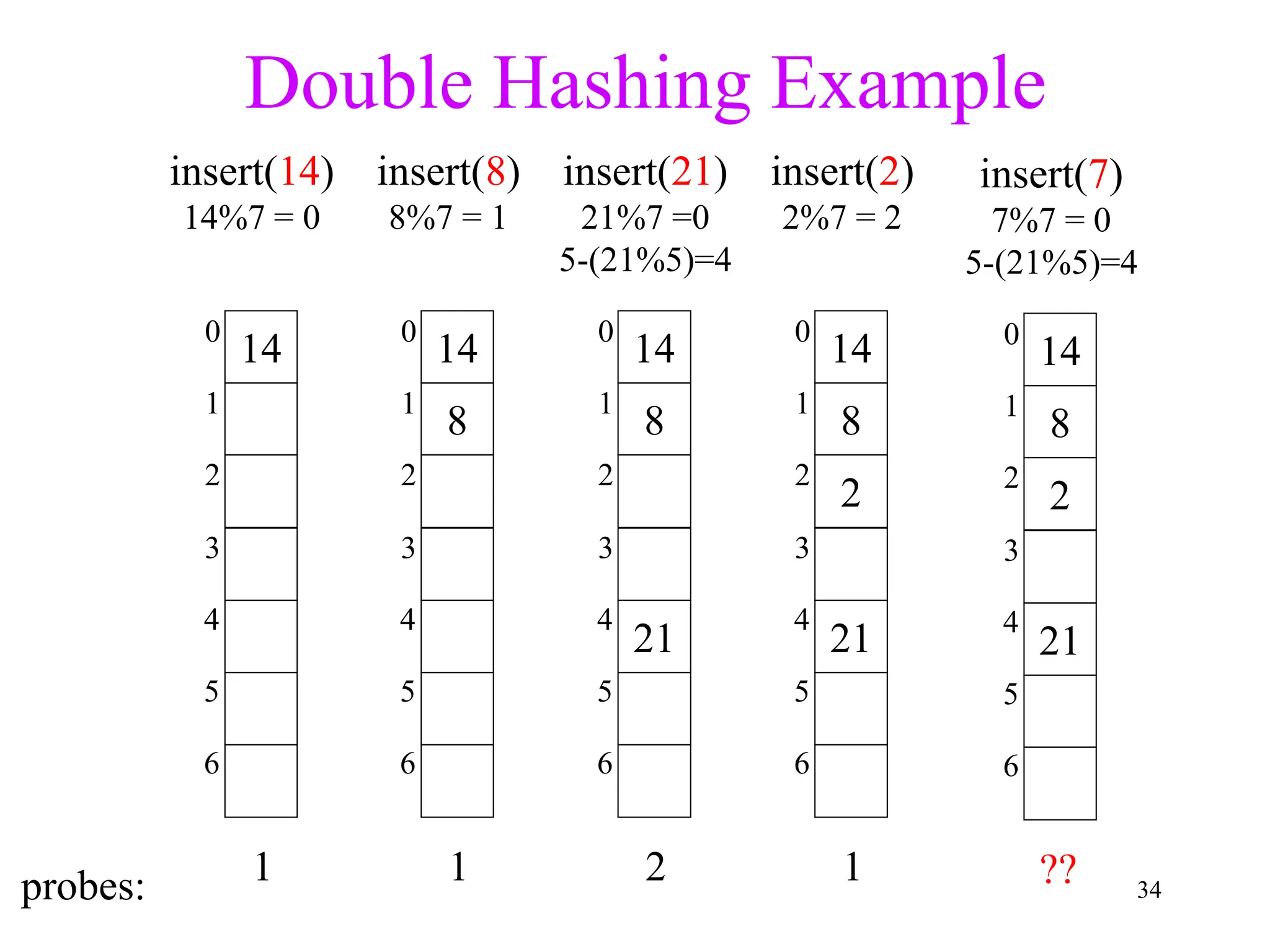
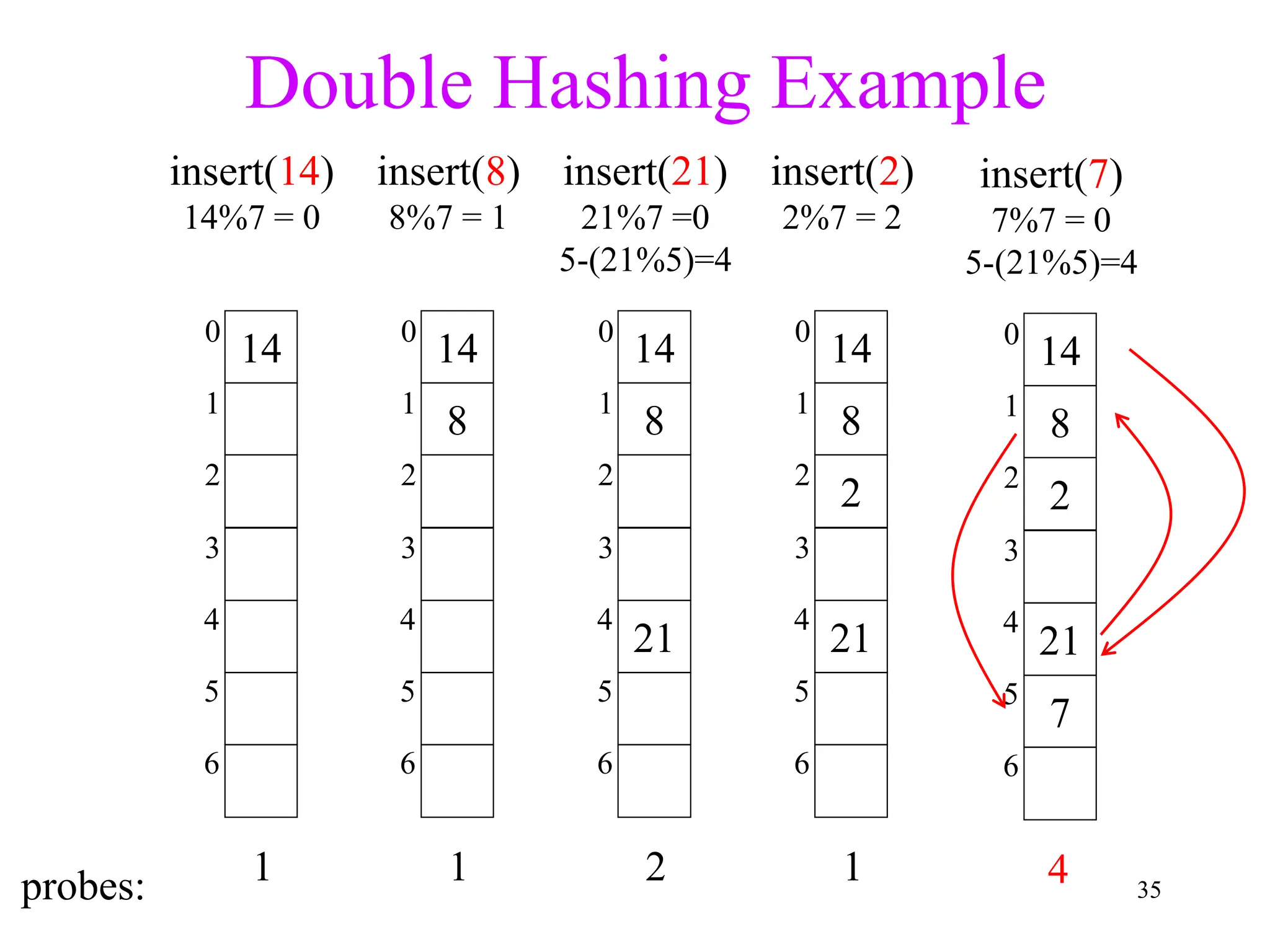
3. Double hashing is described as the best closed hashing technique, as it uses a second hash function to spread keys out and avoid clustering completely.



![5
Hash Tables: Basic Idea
• Use a key (arbitrary string or number) to index
directly into an array – O(1) time to access records
– A[“kreplach”] = “tasty stuffed dough”
– Need a hash function to convert the key to an integer
Key Data
0 kim chi spicy cabbage
1 kreplach tasty stuffed dough
2 kiwi Australian fruit](https://image.slidesharecdn.com/part5-hashing-240320060630-dba28dc3/75/Hashing-In-Data-Structure-Download-PPT-i-5-2048.jpg)









































![55
Databases
• A database is a set of records, each a tuple
of values
– E.g.: [ name, ss#, dept., salary ]
• How can we speed up queries that ask for
all employees in a given department?
• How can we speed up queries that ask for
all employees whose salary falls in a given
range?](https://image.slidesharecdn.com/part5-hashing-240320060630-dba28dc3/75/Hashing-In-Data-Structure-Download-PPT-i-55-2048.jpg)



































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)

