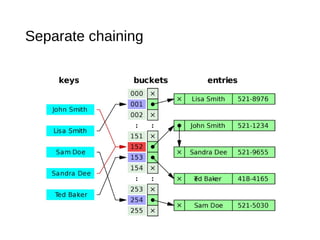
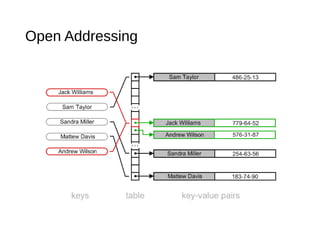
The document describes maps and hash tables as data structures that store unique key-value entries for efficient retrieval. It details methods for map operations like adding, retrieving, and removing entries, along with the concept of hash tables that use a bucket array and hashing functions for faster access. Various collision resolution techniques, such as separate chaining and open addressing, are also covered, highlighting their implementation strategies and time complexities.








![Bucket Array
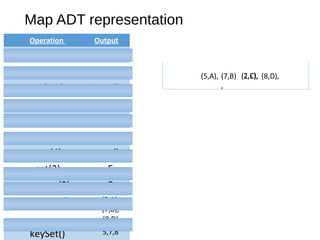
• Consider array A of size N (array size)
• each cell is a bucket (i.e. a collection of (k,v))
• The keys of entries are integers in the range of [0, N-1], each
bucket holds at most one entry.
• Search, insertion and removal in the bucket array seems to take
O(1) time.](https://image.slidesharecdn.com/mapshashtables-170515074702/85/Maps-hash-tables-14-320.jpg)
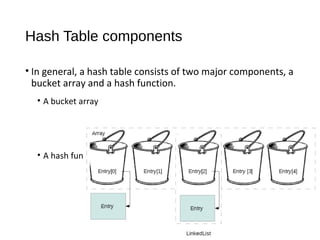
![Bucket Array(cont.)
• It has two drawbacks:
• As the space used is proportional to N (array size).
• if N >> number of entries n present in the map, there is a waste of space.
• keys are required to be integers (range [0, N − 1]), which is often not the case.
• Overcome:
• Use the bucket array in conjunction with a "good" mapping from the keys to the
integers in the range [0,N − 1] like hash functions.](https://image.slidesharecdn.com/mapshashtables-170515074702/85/Maps-hash-tables-15-320.jpg)
![Hash functions (h)
• Is second part of hash table structure.
• Hash function value, h(k), is an index into the bucket array,
instead of k.
• So entry (k, v) is stored in the bucket A[h(k)].](https://image.slidesharecdn.com/mapshashtables-170515074702/85/Maps-hash-tables-16-320.jpg)
![Evaluation of a hash function, h(k),
• Consists of two functions:
• mapping the key k to an integer, called the hash code.
• mapping the hash code to an integer within the range of
indices ([0, N − 1]) of a bucket array, called the
compression function.
• Hash codes may be generated by casting to an integer,
summing components, Polynomial hash codes etc.](https://image.slidesharecdn.com/mapshashtables-170515074702/85/Maps-hash-tables-17-320.jpg)



![Linear probing
• Distance between probes is constant (i.e. 1, when probe
examines consequent slots).
• When an entry into a bucket A[i] is already occupied,
where i = h(k) then :
• Try next at A[(i + 1) modN]. If this is also occupied, then
• Try A[(i + 2) mod N], and so on.
• until we find an empty bucket that can accept the new entry.](https://image.slidesharecdn.com/mapshashtables-170515074702/85/Maps-hash-tables-23-320.jpg)

![Quadratic probing
• trying the buckets
A[h(k) + j2] (mod N), for j = 0,1,..., N −1
until finding an empty bucket.
• N has to be a prime number.
• Bucket array must be less than half full.](https://image.slidesharecdn.com/mapshashtables-170515074702/85/Maps-hash-tables-25-320.jpg)





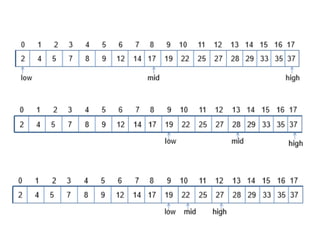
![Searching algorithm – Binary search
Algorithm BinarySearch(S, k, low, high)
if low > high then
return null
else
mid ← [(low + high)/2 ]
e ← S.get(mid)
if k = e.getKey() then
return e
else if k < e.getKey() then
return BinarySearch(S, k, low, mid-1)
else
return BinarySearch(S, k, mid+1, high)](https://image.slidesharecdn.com/mapshashtables-170515074702/85/Maps-hash-tables-31-320.jpg)