Hashing is a technique used to map data of arbitrary size to values of fixed size. It allows for fast lookup of data in near constant time. Common applications include dictionaries, databases, and search engines. Hashing works by applying a hash function to a key that returns an index value. Collisions occur when different keys hash to the same index, and must be resolved through techniques like separate chaining or open addressing.

![2
The Search Problem
Find items with keys matching a given
search key
Given an array A, containing n keys, and a
search key x, find the index i such as x=A[i]
As in the case of sorting, a key could be part
of a large record.](https://image.slidesharecdn.com/session15hashing-230831085925-86983a18/85/session-15-hashing-pptx-2-320.jpg)


![5
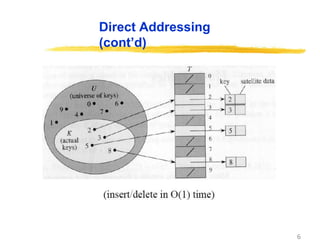
Direct Addressing
Assumptions:
Key values are distinct
Each key is drawn from a universe U = {0, 1, . . . , m - 1}
Idea:
Store the items in an array, indexed by keys
• Direct-address table representation:
– An array T[0 . . . m - 1]
– Each slot, or position, in T corresponds to a key in U
– For an element x with key k, a pointer to x (or x itself) will be placed
in location T[k]
– If there are no elements with key k in the set, T[k] is empty,
represented by NIL](https://image.slidesharecdn.com/session15hashing-230831085925-86983a18/85/session-15-hashing-pptx-5-320.jpg)
![7
Operations
Alg.: DIRECT-ADDRESS-SEARCH(T, k)
return T[k]
Alg.: DIRECT-ADDRESS-INSERT(T, x)
T[key[x]] ← x
Alg.: DIRECT-ADDRESS-DELETE(T, x)
T[key[x]] ← NIL
Running time for these operations: O(1)](https://image.slidesharecdn.com/session15hashing-230831085925-86983a18/85/session-15-hashing-pptx-7-320.jpg)




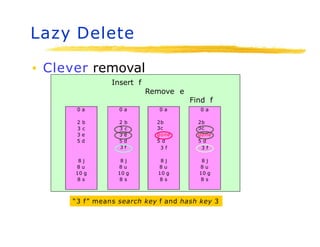
![Big Idea in Hashing
▪ Let S={a1,a2,…am} be a set of objects that
we need to map into a table of size N.
➢Find a function such that H:S [1…n]
➢Ideally we’d like to have a 1-1 map
➢But it is not easy to find one
➢Also function must be easy to compute
➢It is a good idea to pick a prime as the table
size to have a better distribution of values
▪ Assume ai is a 16-bit integer.
➢Of course there is a trivial map H(ai)=ai
➢But this may not be practical. Why?](https://image.slidesharecdn.com/session15hashing-230831085925-86983a18/85/session-15-hashing-pptx-14-320.jpg)
![Finding a hash Function
▪ Assume that N = 5 and the values
we need to insert are: cab, bea, bad
etc.
▪ Let a=0, b=1, c=2, etc
▪ Define H such that
➢H[data] = (∑ characters) Mod N
▪ H[cab] = (2+0+1) Mod 5 = 3
▪ H[bea] = (1+4+0) Mod 5 = 0
▪ H[bad] = (1+0+3) Mod 5 = 4](https://image.slidesharecdn.com/session15hashing-230831085925-86983a18/85/session-15-hashing-pptx-15-320.jpg)



![Choosing a Hash Function
▪ Suppose we need to hash a set of strings
S ={Si} to a table of size N
▪ H(Si) = ( Si[j].dj ) mod N, where Si[j] is
the jth character of string Si
➢How expensive is to compute this function?
• cost with direct calculation
• Is it always possible to do direct calculation?
➢Is there a cheaper way to calculate this? Hint:
use Horners Rule.](https://image.slidesharecdn.com/session15hashing-230831085925-86983a18/85/session-15-hashing-pptx-19-320.jpg)


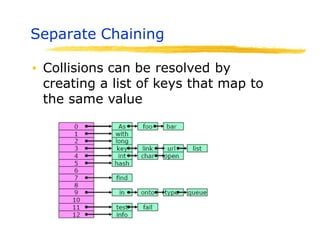
![Separate Chaining
▪ Use an array of linked lists
➢LinkedList[ ] Table;
➢Table = new LinkedList(N), where N is the
table size
▪ Define Load Factor of Table as
➢ = number of keys/size of the table
( can be more than 1)
▪ Still need a good hash function to
distribute keys evenly
➢For search and updates](https://image.slidesharecdn.com/session15hashing-230831085925-86983a18/85/session-15-hashing-pptx-23-320.jpg)