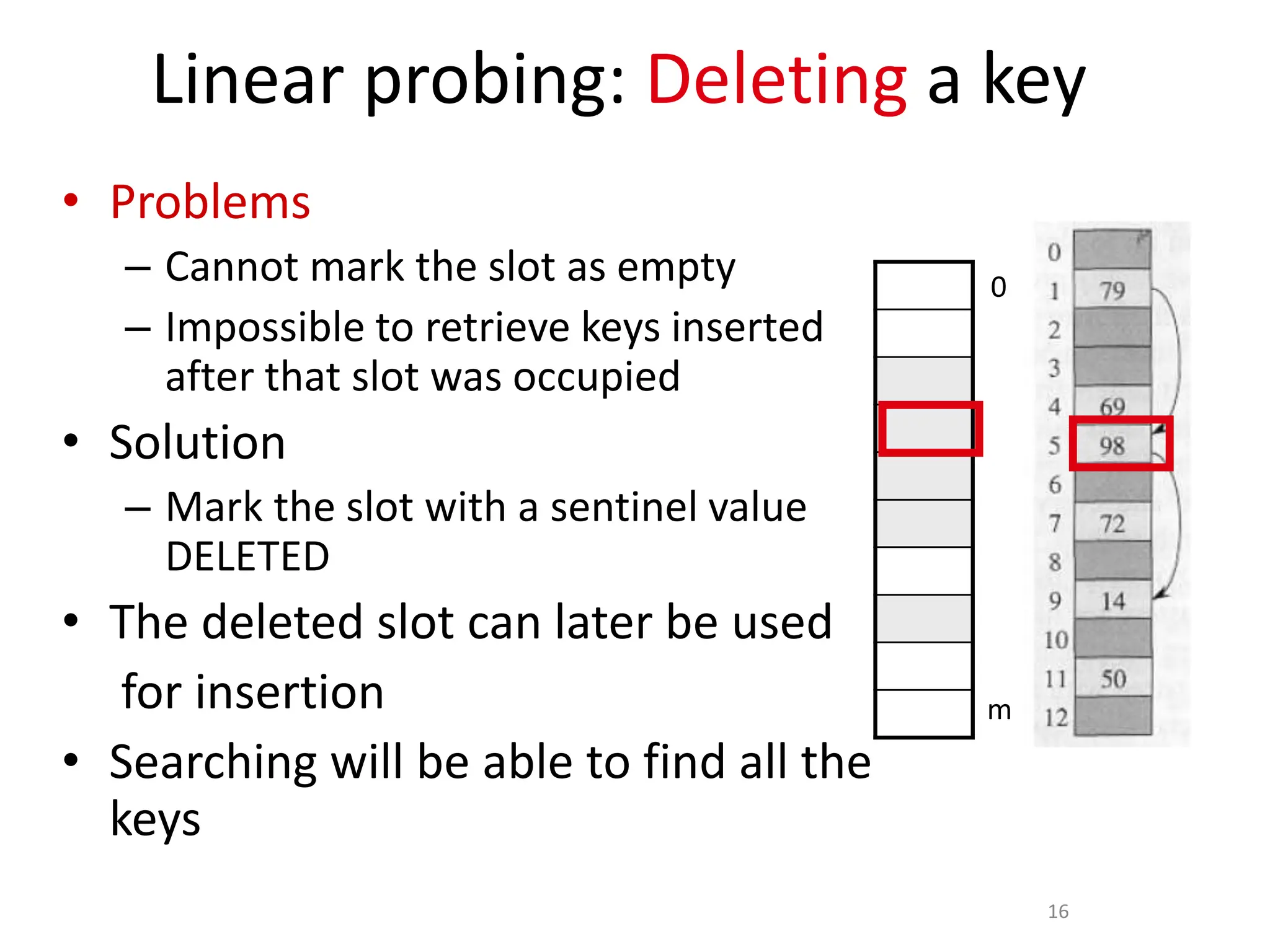
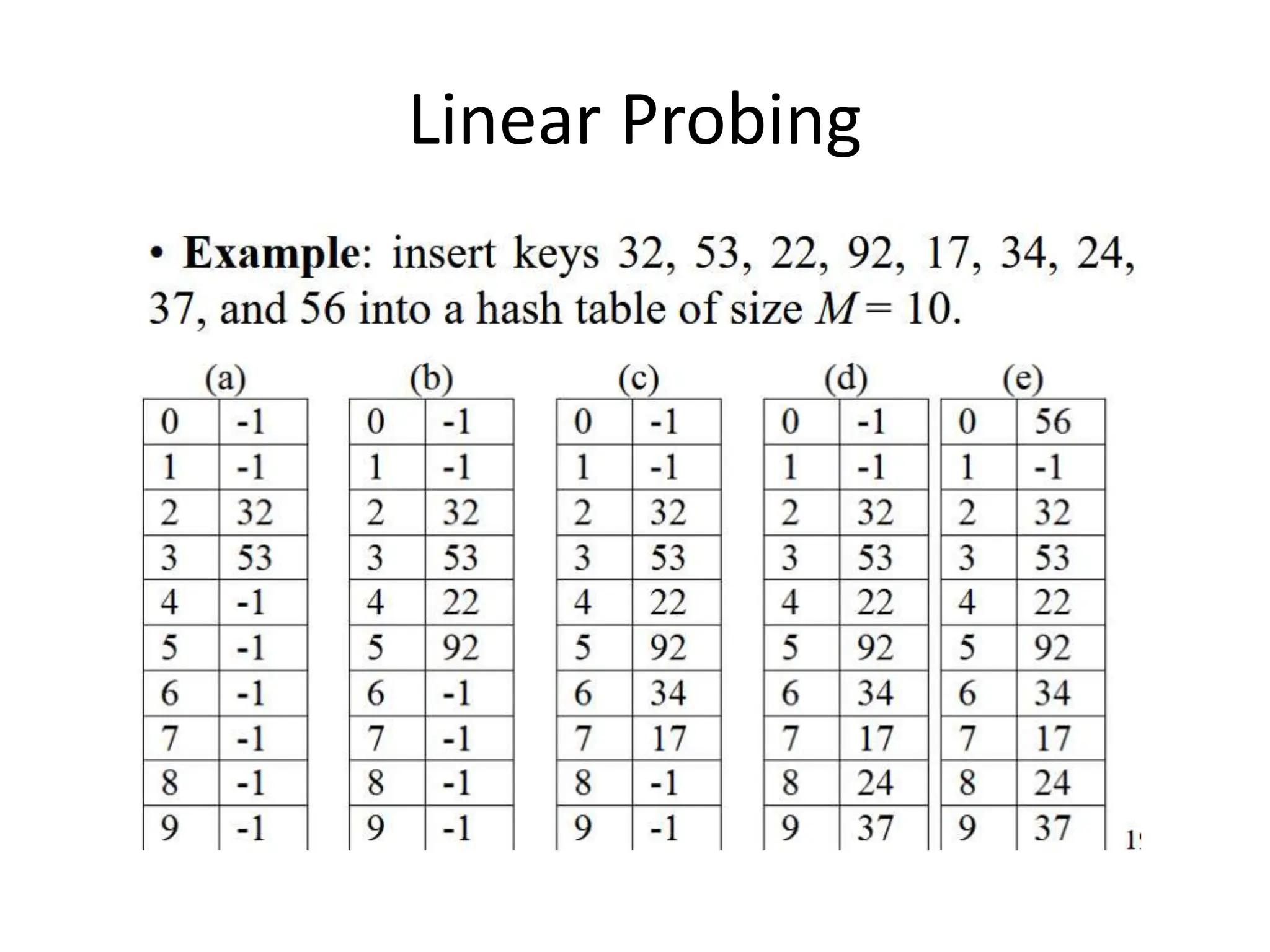
Here are the steps to solve this problem:
1) Construct the open hash table with separate chaining for the keys 30, 20, 56, 75, 31, 19 using h(K) = K mod 11:
Index: 0 1 2 3 4 5 6 7 8 9 10
Keys: 30 20 56 75 31 19
2) The largest number of key comparisons for a successful search is 2 (to search the linked list for key 56).
3) The average number of key comparisons is 1 (each key is directly stored without collisions).
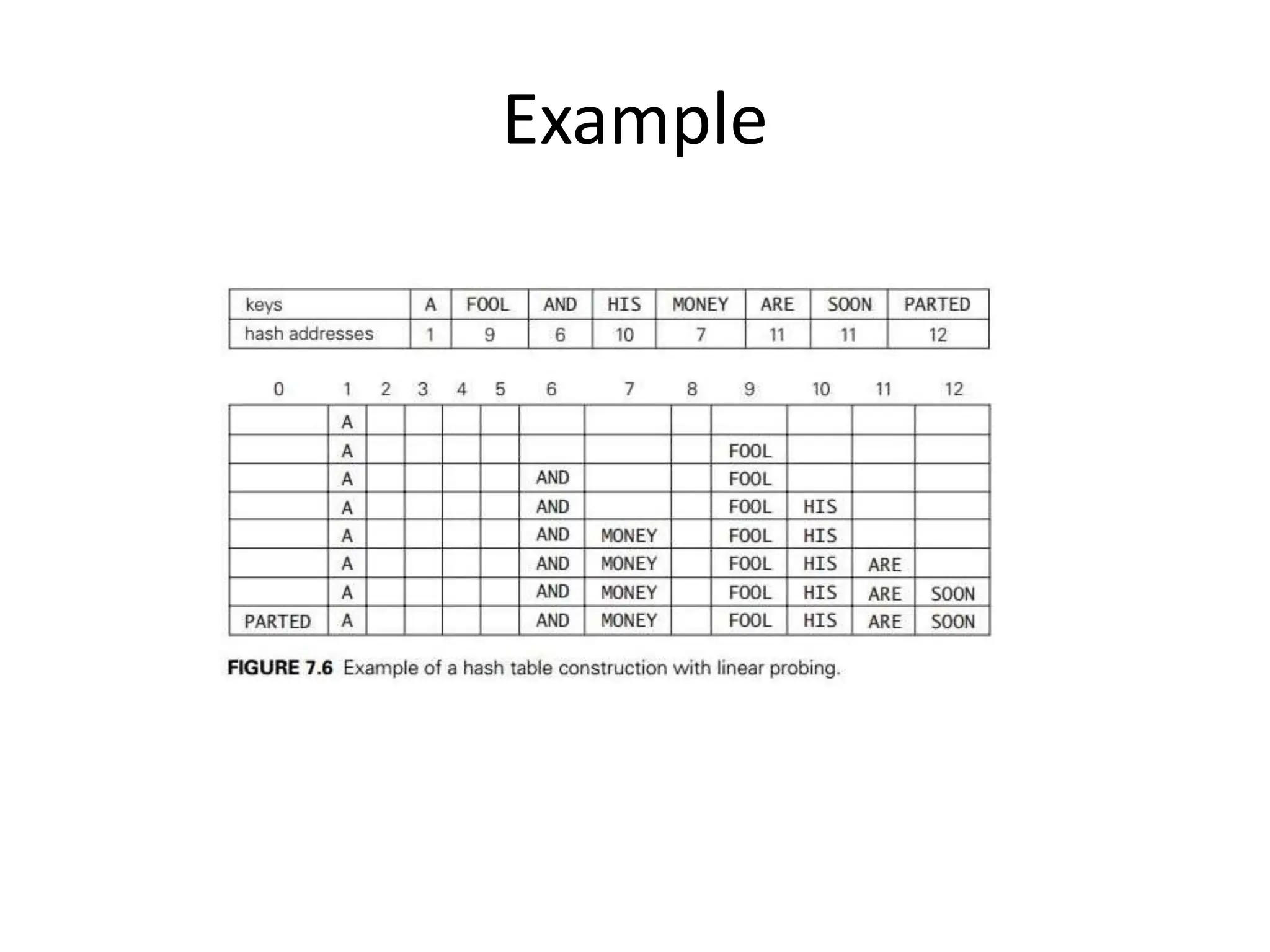
4) Construct the closed hash table using linear probing for the same keys:
Index: 0 1 2 3 4 5 6 7 8 9 10






![Insert 36,48,90,12 using key%10 hash
function
Index HT[index]
0 90
1 12
2
3
4
5
6 36
7
8 48
9
10](https://image.slidesharecdn.com/hashing-240317144023-7036b666/75/Hashing-using-a-different-methods-of-technic-9-2048.jpg)


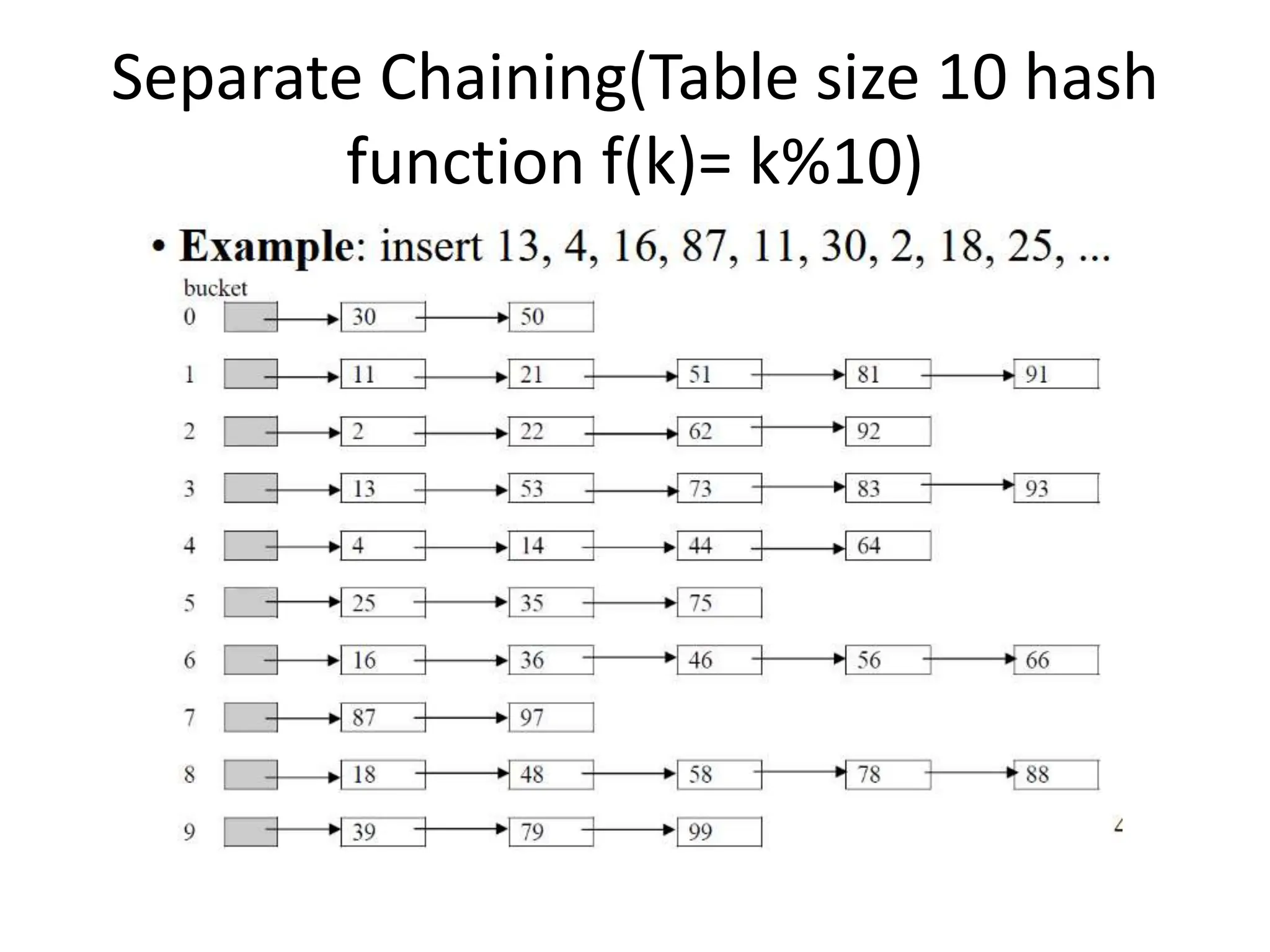
![Separate Chaining
• When an element needs to be searched on the hash table, the hash
function f(k) = k % M will specify the address i within the range [0,
M -1]corresponding the singly linked list i that may contain the
node.
• Searching an element on the hash table turns out the problem of
searching an element on the singly linked list
• The hash table is implemented by using singly linked list.
• Elements on the hash table are hashed into M (e.g., M = 10) singly
linked lists (from list 0 to list M-1).
• Elements conflicted at the address i are directly connected in the
list i, where 0 ≤i ≤M-1.
• When an element with the key k is added into the hash table, the
hash function f(k) = k % M will identify the address i between 0 and
M -1 corresponding the singly linked list i where this node will be
added](https://image.slidesharecdn.com/hashing-240317144023-7036b666/75/Hashing-using-a-different-methods-of-technic-12-2048.jpg)
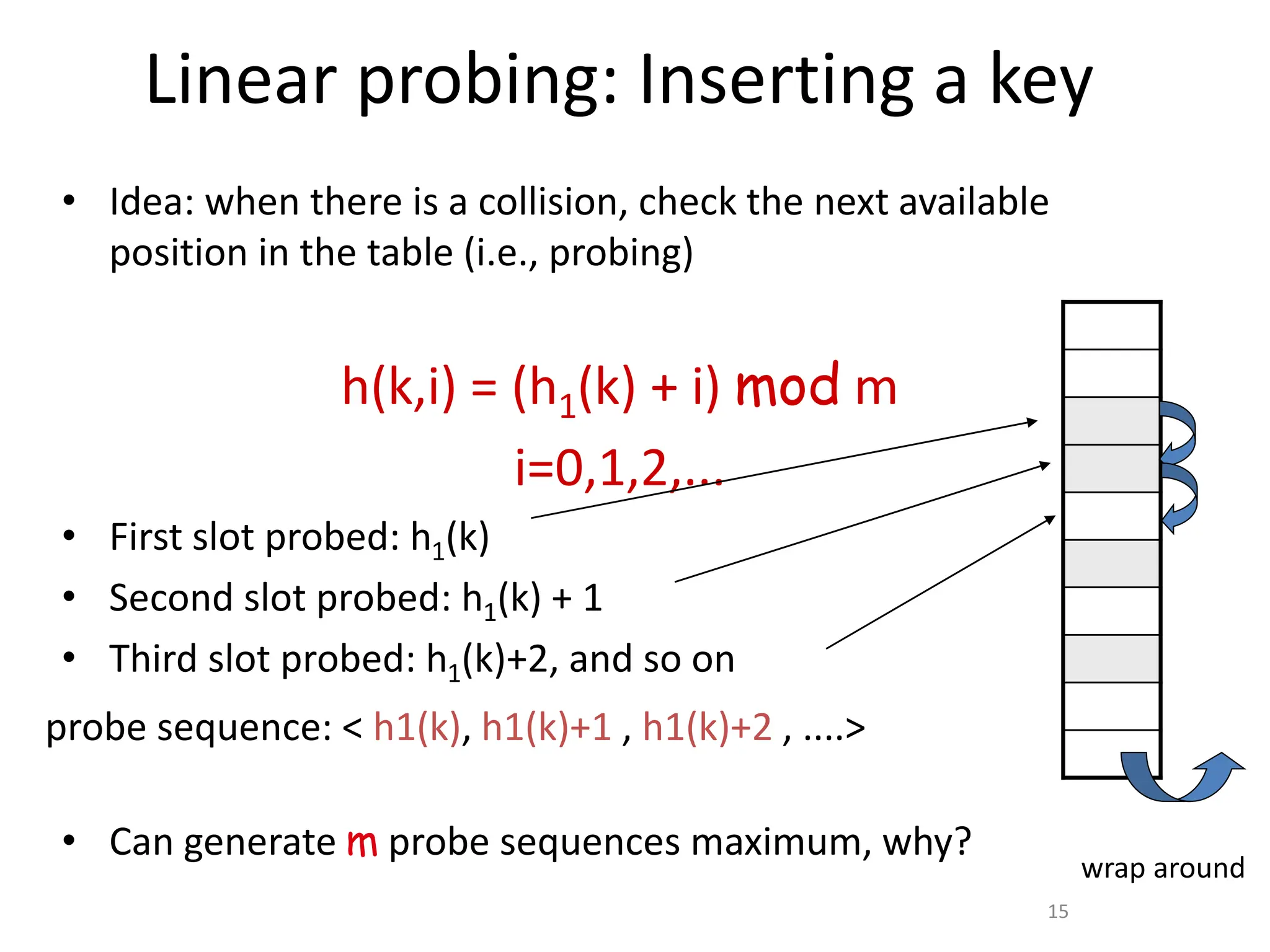
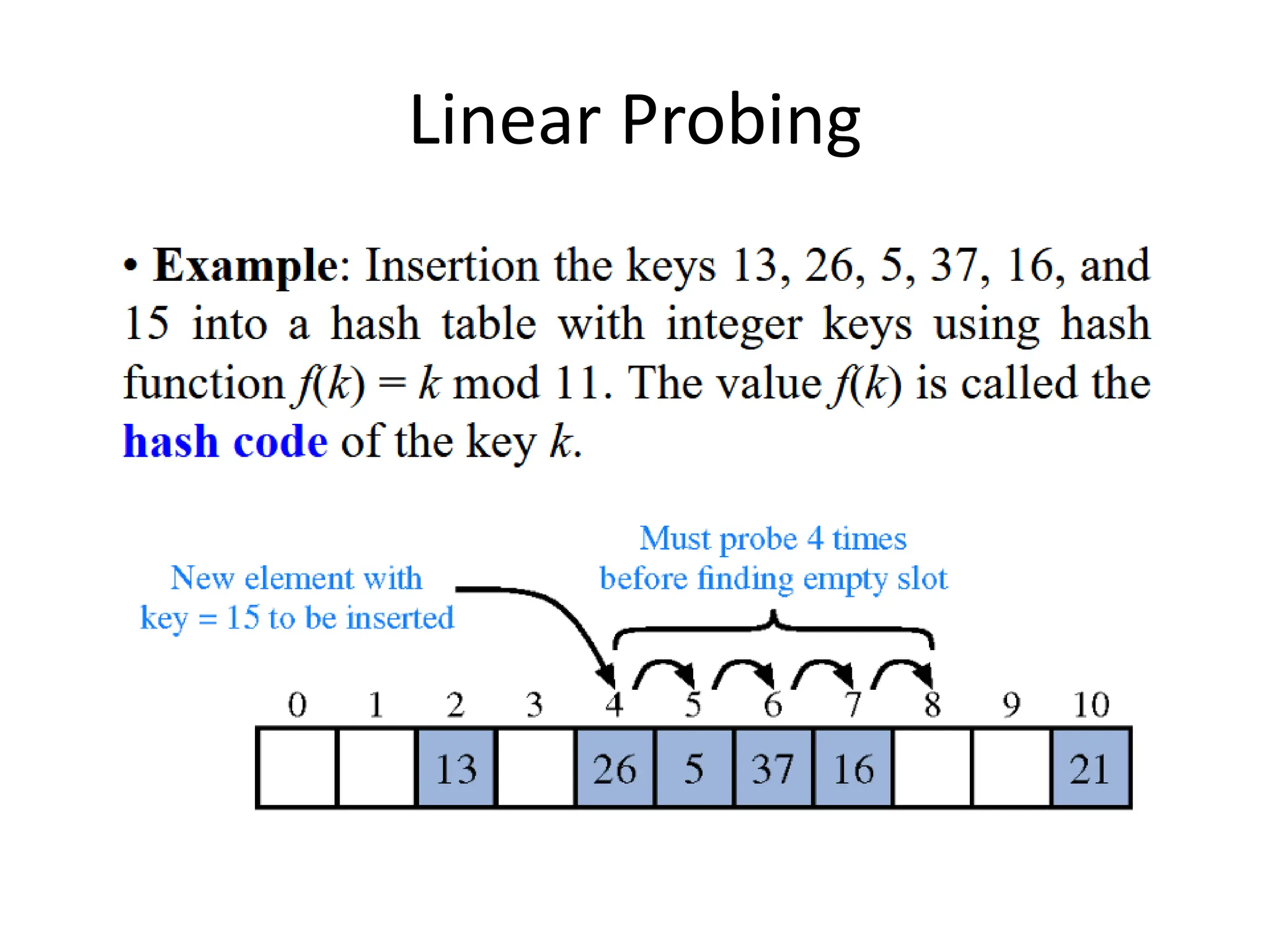
![Linear Probing Method
• All elements are stored in the hash table itself
• The hash table is initialized, all M locations assigned to -1 (i.e., empty or vacant).
• When a node with the key k needs to be added into the hash table, the hash function
f(k) = k % M
will specify the address/index
i = f(k) (i.e., an index of an array)
within the range [0, M-1].
• If there is no conflict (i.e., the cell i is unoccupied), then this node is added into the hash
table at the address i.
• If a collision takes place, then the hash function rehashes first time to consider the
next address (i.e., i + 1).
• If conflict occurs again, then the hash function rehashes second time to examine the
next address (i.e., i + 2).
• This process repeats until the available address found then this node will be added at
this address.](https://image.slidesharecdn.com/hashing-240317144023-7036b666/75/Hashing-using-a-different-methods-of-technic-14-2048.jpg)
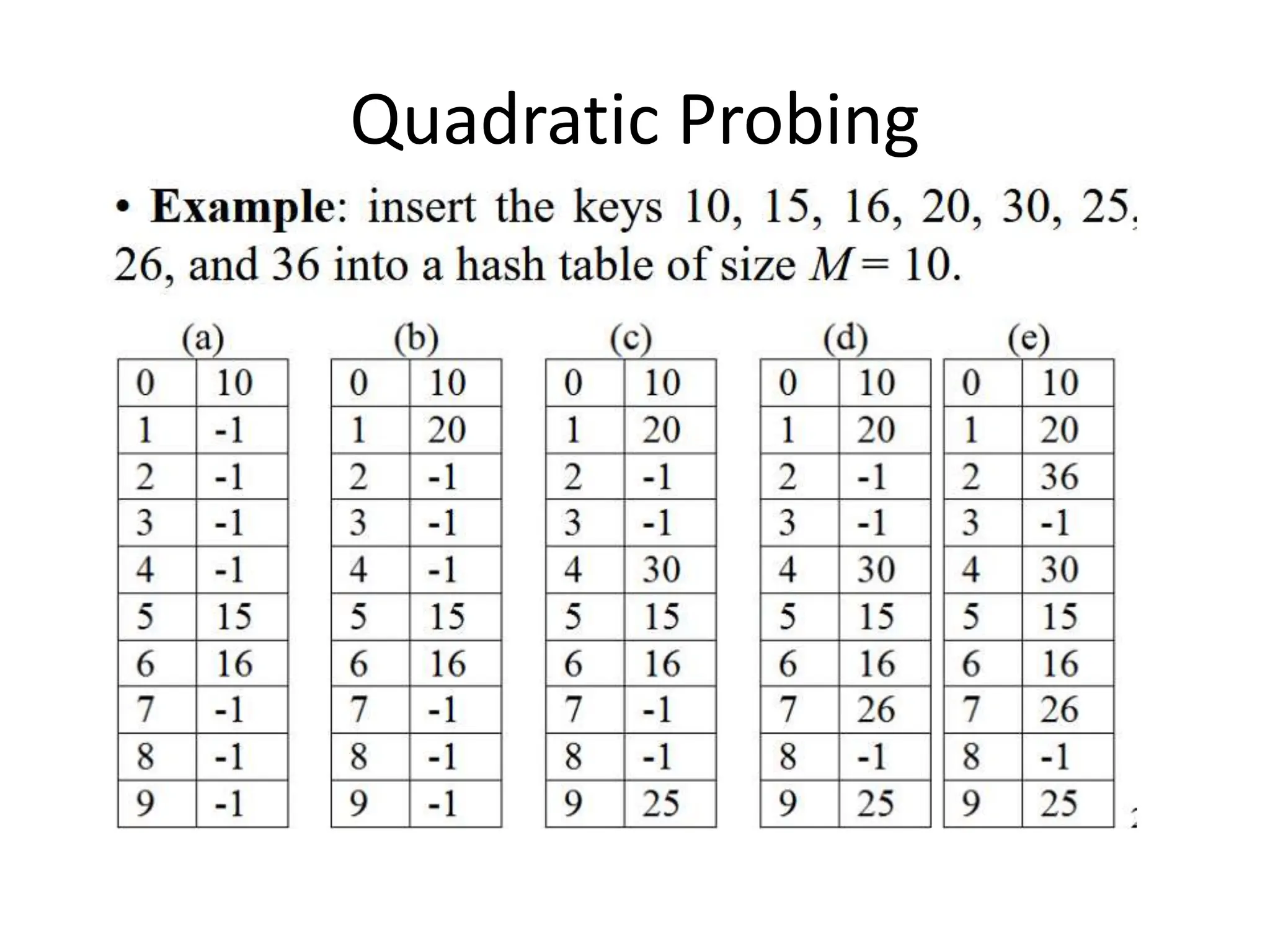
![Linear Probing
• Hash Table Size : 7 , So f(k) = k%7
Probe Sequence is for Insert(47): {5,6,0,1,2,3,4}
Table[4]= 47 //Insert](https://image.slidesharecdn.com/hashing-240317144023-7036b666/75/Hashing-using-a-different-methods-of-technic-18-2048.jpg)









































![Sustainable and ife cycle analysis PPT[1] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/sustainableppt11-250505054638-4290ca88-thumbnail.jpg?width=640&height=640&fit=bounds)



















