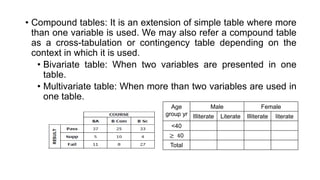
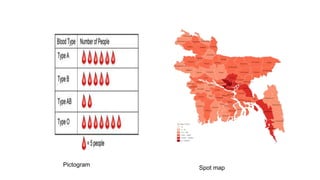
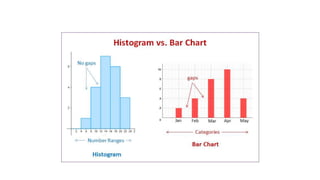
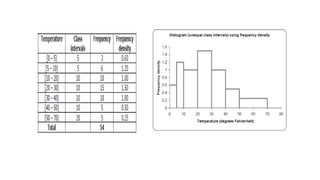
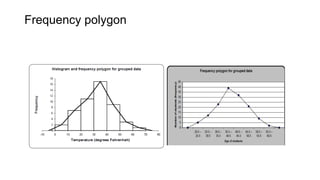
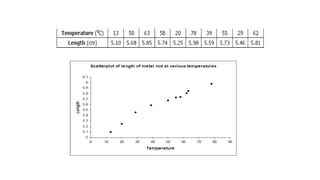
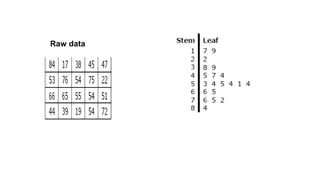
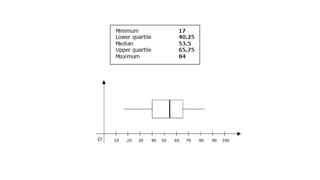
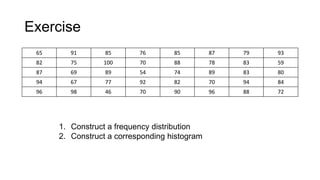
Here are the steps to construct a frequency distribution and histogram for the given data:
1. Group the data into class intervals of width 10. The class intervals are: 40-49, 50-59, 60-69, 70-79, 80-89, 90-99, 100-109.
2. Count the frequency of observations in each class interval.
3. The frequency distribution is:
Class interval: Frequency
40-49: 1
50-59: 2
60-69: 4
70-79: 6
80-89: 8
90-99: 3
100-109: 1
4. Construct a histogram with the class intervals on the x