Downloaded 11 times



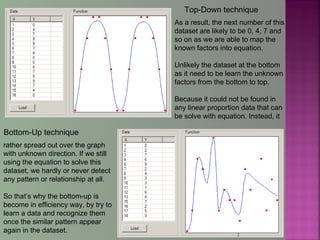



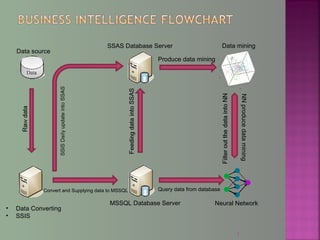


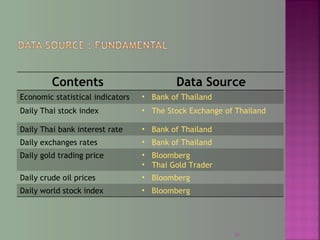
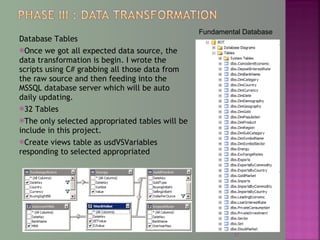

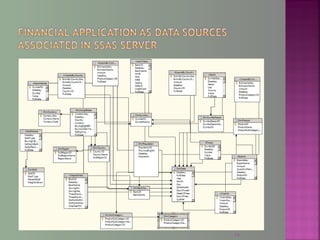


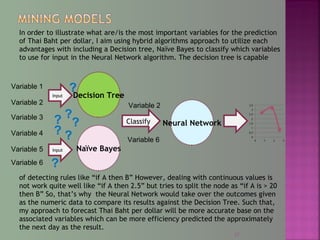

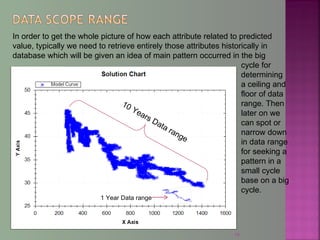
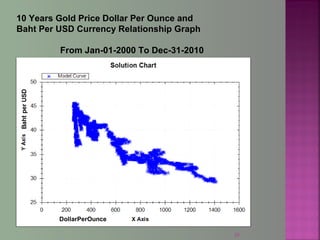
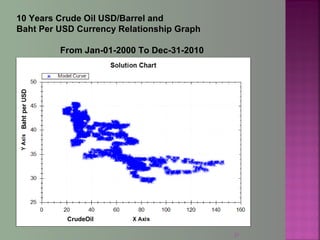
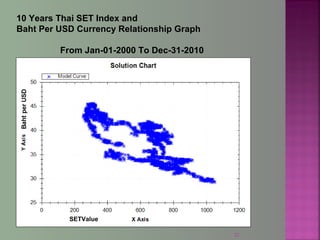
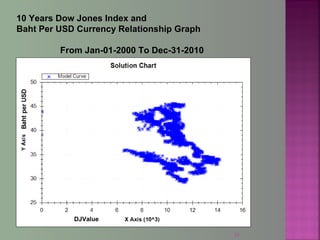

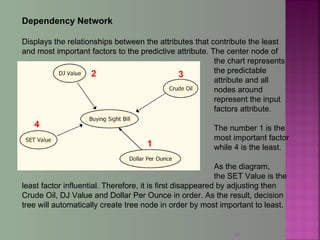
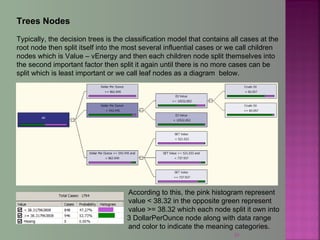

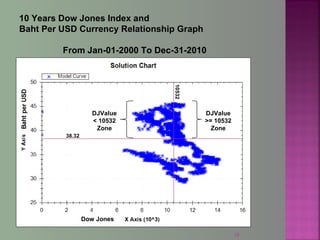
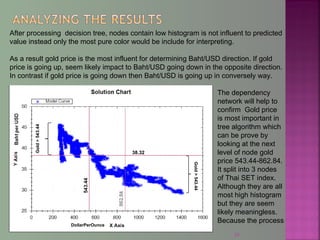
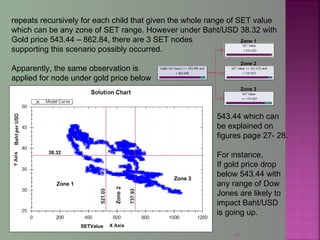

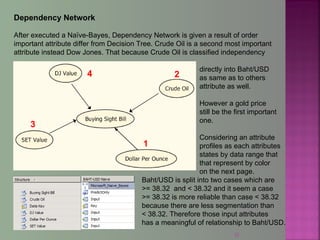

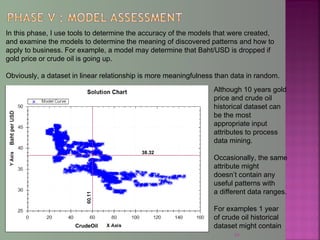
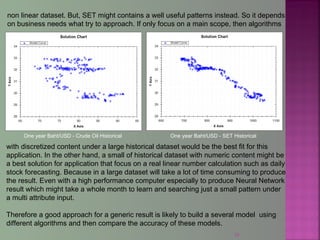
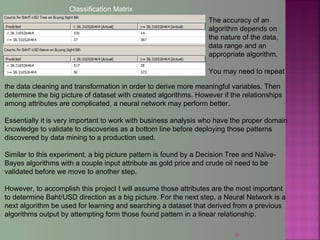

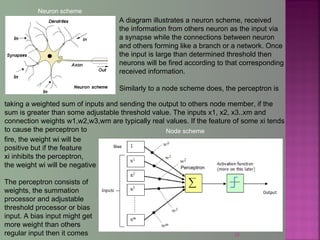
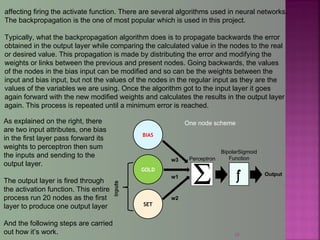
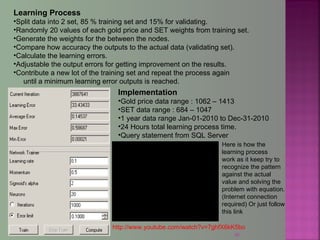
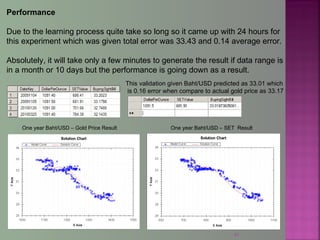
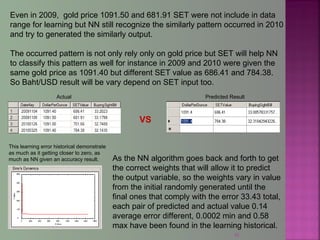



The document discusses data mining techniques for predicting currency exchange rates between the US Dollar and Thai Baht. It describes collecting historical data on economic indicators and financial factors from sources like the Bank of Thailand to build a database. Various data mining algorithms like decision trees, naive Bayes, and neural networks are used to analyze the data and identify the most important variables for predicting exchange rates. Graphs show relationships between the Baht exchange rate and factors like gold prices, crude oil prices, stock indexes over 10 years. The goal is to accurately forecast future exchange rates based on the patterns found in the historical data.



































































