Download as PDF, PPTX




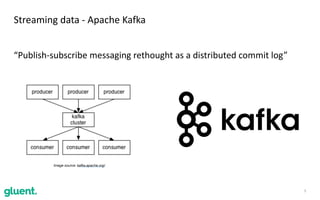

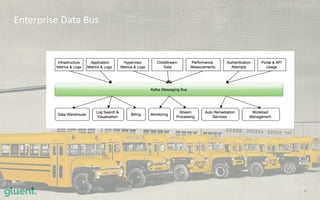
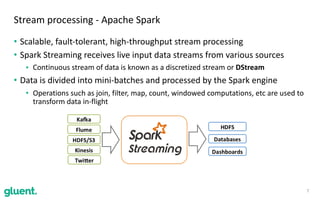


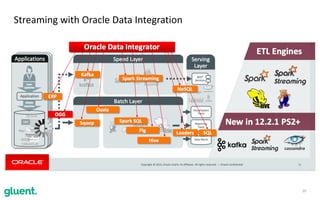
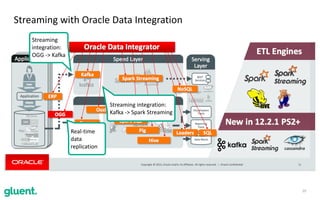
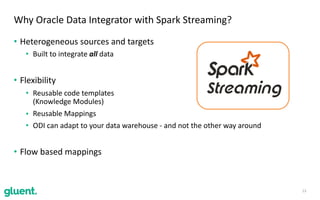

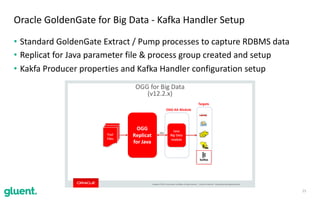

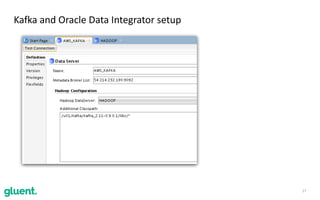
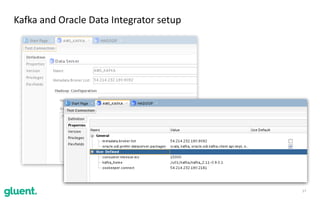
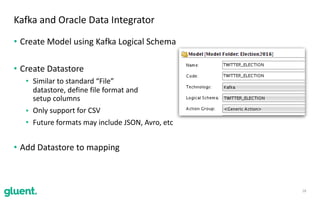

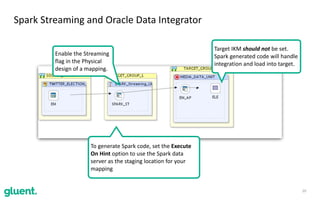
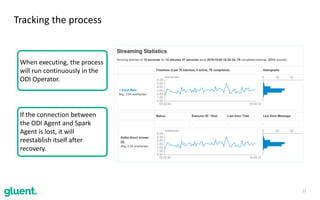



The document discusses streaming transformations using Oracle Data Integration, emphasizing the importance of real-time data processing and its applications, such as retail analysis and IoT data analysis. It outlines the benefits of Oracle Data Integration, specifically its scalability, and interaction with Apache Kafka and Spark Streaming for efficient data handling. Additionally, it highlights the ease of setup and management provided by Goldengate in facilitating data integration from various sources.



































































![[WSO2Con EU 2018] Streaming SQL in the Real World](https://cdn.slidesharecdn.com/ss_thumbnails/wso2coneu2018streamingsqlintherealworld-181113090808-thumbnail.jpg?width=640&height=640&fit=bounds)





































