



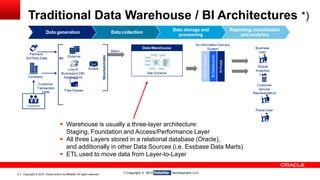

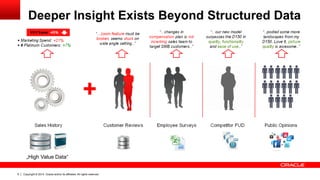


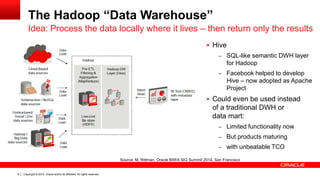
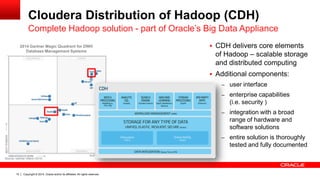
![Copyright © 2014, Oracle and/or its affiliates. 11 All rights reserved.
“[Facebook] started in the Hadoop world. We are now
bringing in relational to enhance that. We're kind of going [in]
the other direction ... We've been there, and [we] realized
that using the wrong technology for certain kinds of
problems can be difficult.”
Ken Rubin
Director of Analytics
Facebook
Source: http://tdwi.org/Articles/2013/05/06/Facebooks-Relational-Platform.aspx?Page=1
No need for Relational Warehouses anymore?](https://image.slidesharecdn.com/doagbi2014-oracleuiaanalyticsbyexample-141208073340-conversion-gate01/85/Oracle-Unified-Information-Architeture-Analytics-by-Example-11-320.jpg)





![Copyright © 2014, Oracle and/or its affiliates. 37 All rights reserved.
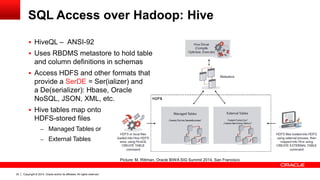
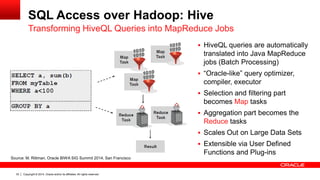
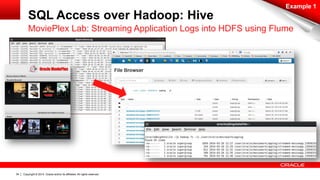
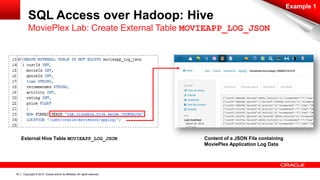
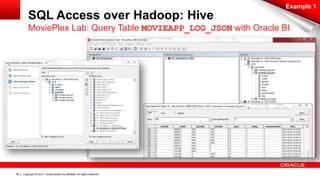
SQL Access over Hadoop: Hive
Set up ODBC Connection at the Oracle BI Server
OBIEE 11.1.1.7+ ships with HiveODBC
drivers, need to use DataDirect 7.x versions
though (only Linux supported)
For testing ok, but not yet certified:
Cloudera ODBC Driver for Apache Hive,
Version 2.5.5
Configure the ODBC connection in odbc.ini,
name needs to match BI Server Repository
ODBC name
Server Configuration see Metadata
Repository Builder's Guide – Chapter 16
[ODBC Data Sources]
AnalyticsWeb=Oracle BI Server
Cluster=Oracle BI Server
SSL_Sample=Oracle BI Server
bda_vm=Oracle 7.1 Apache Hive Wire Protocol
[bda_vm]
Driver=/u01/app/Middleware/Oracle_BI1/common
/ODBC/Merant/7.0.1/lib/ARhive27.so
Description=Oracle 7.1 Apache Hive Wire
Protocol ArraySize=16384
Database=moviework
DefaultLongDataBuffLen=1024
EnableLongDataBuffLen=1024
EnableDescribeParam=0
Hostname=bigdatalite
LoginTimeout=30
MaxVarcharSize=2000
PortNumber=10000
RemoveColumnQualifiers=0
StringDescribeType=12
TransactionMode=0
UseCurrentSchema=0](https://image.slidesharecdn.com/doagbi2014-oracleuiaanalyticsbyexample-141208073340-conversion-gate01/85/Oracle-Unified-Information-Architeture-Analytics-by-Example-37-320.jpg)
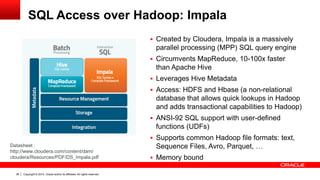


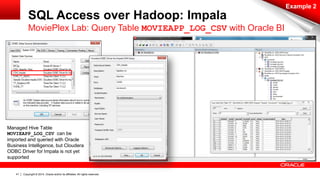
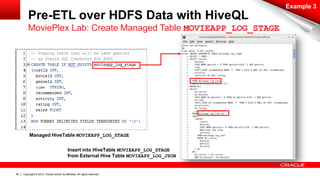





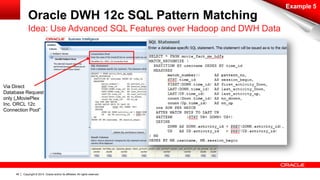
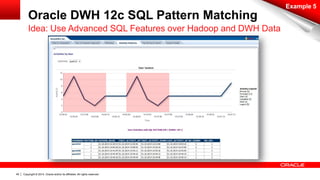

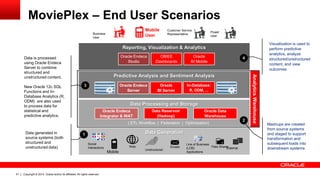
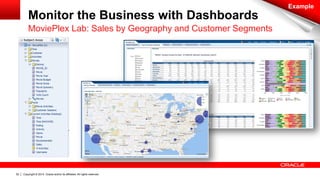


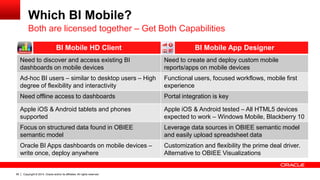
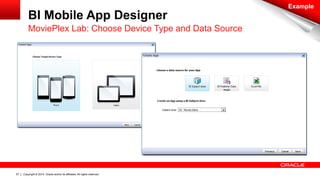
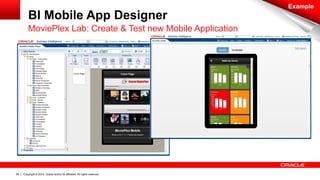
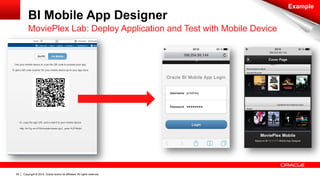
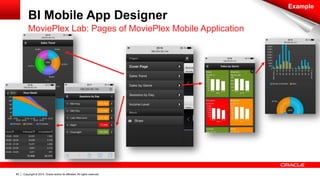



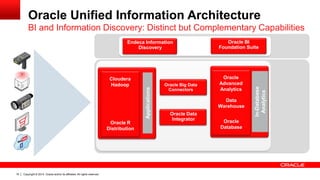
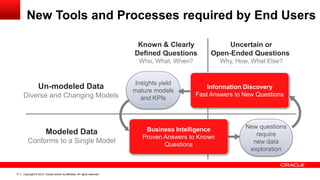
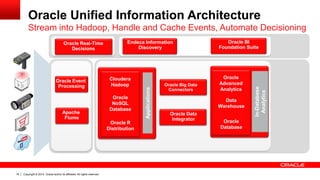
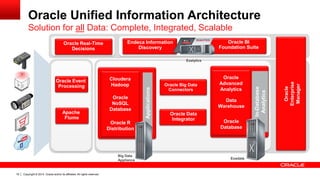
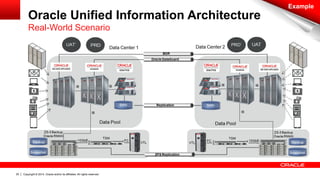
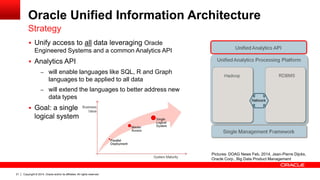
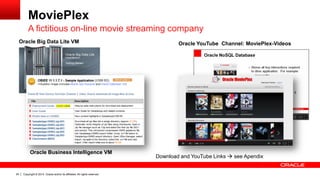
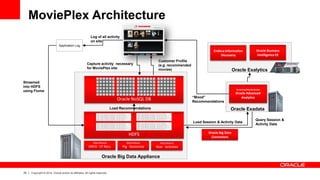
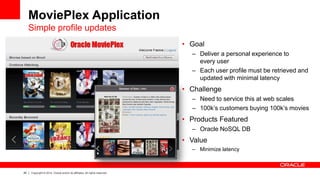
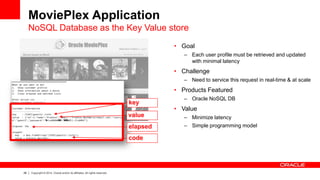
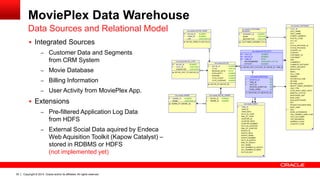
The document discusses Oracle's Unified Information Architecture, presenting the integration of traditional data warehouses with big data technologies like Hadoop for enhanced analytics capabilities. It explores a case study involving the Movieplex application, detailing how SQL access over Hadoop can optimize data processing and real-time analytics. Key components include using Hive and Impala for querying, and features of Oracle's data solutions to support scalable, fault-tolerant storage and advanced analytics.






























































































