Download as PDF, PPTX



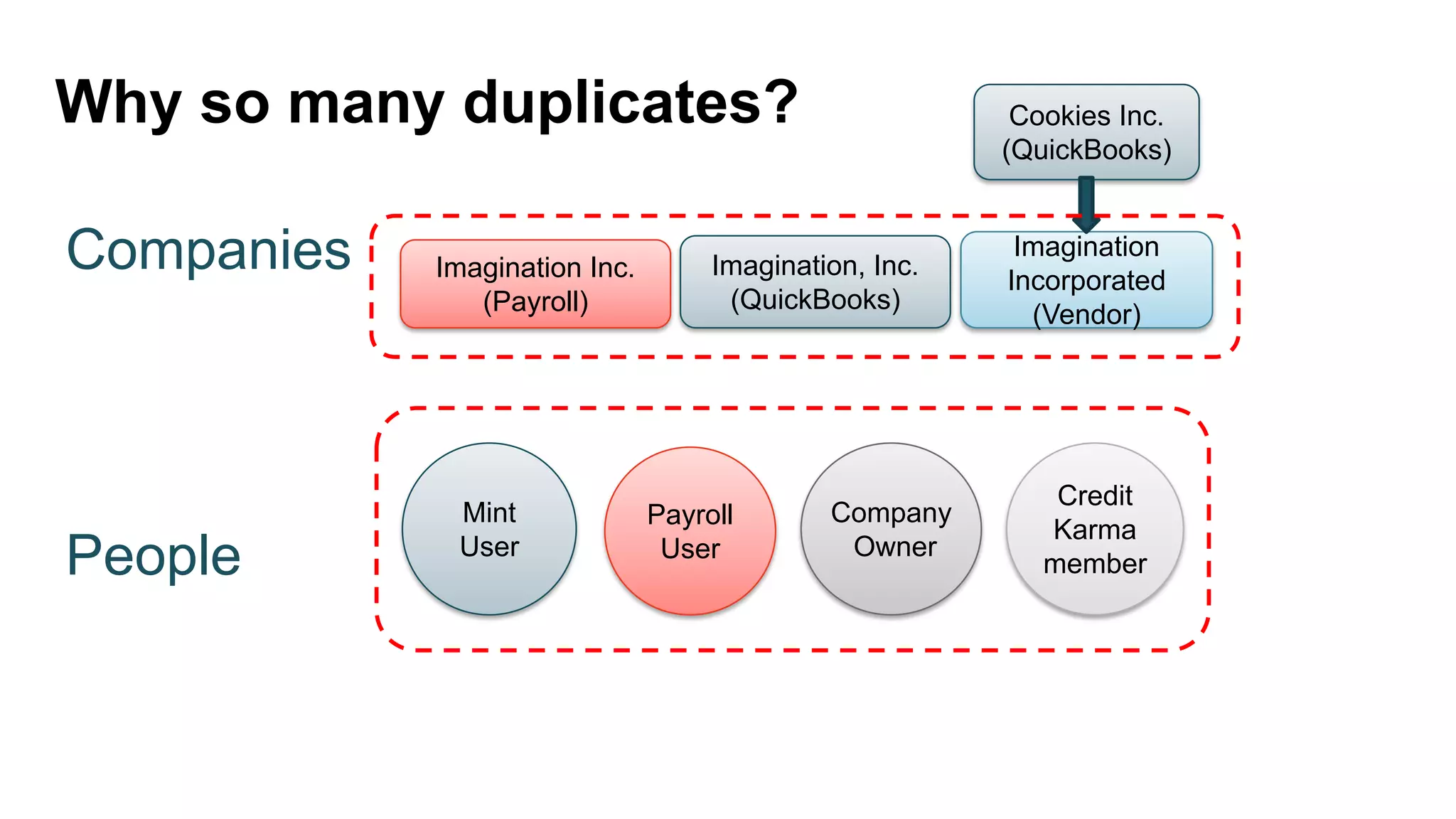




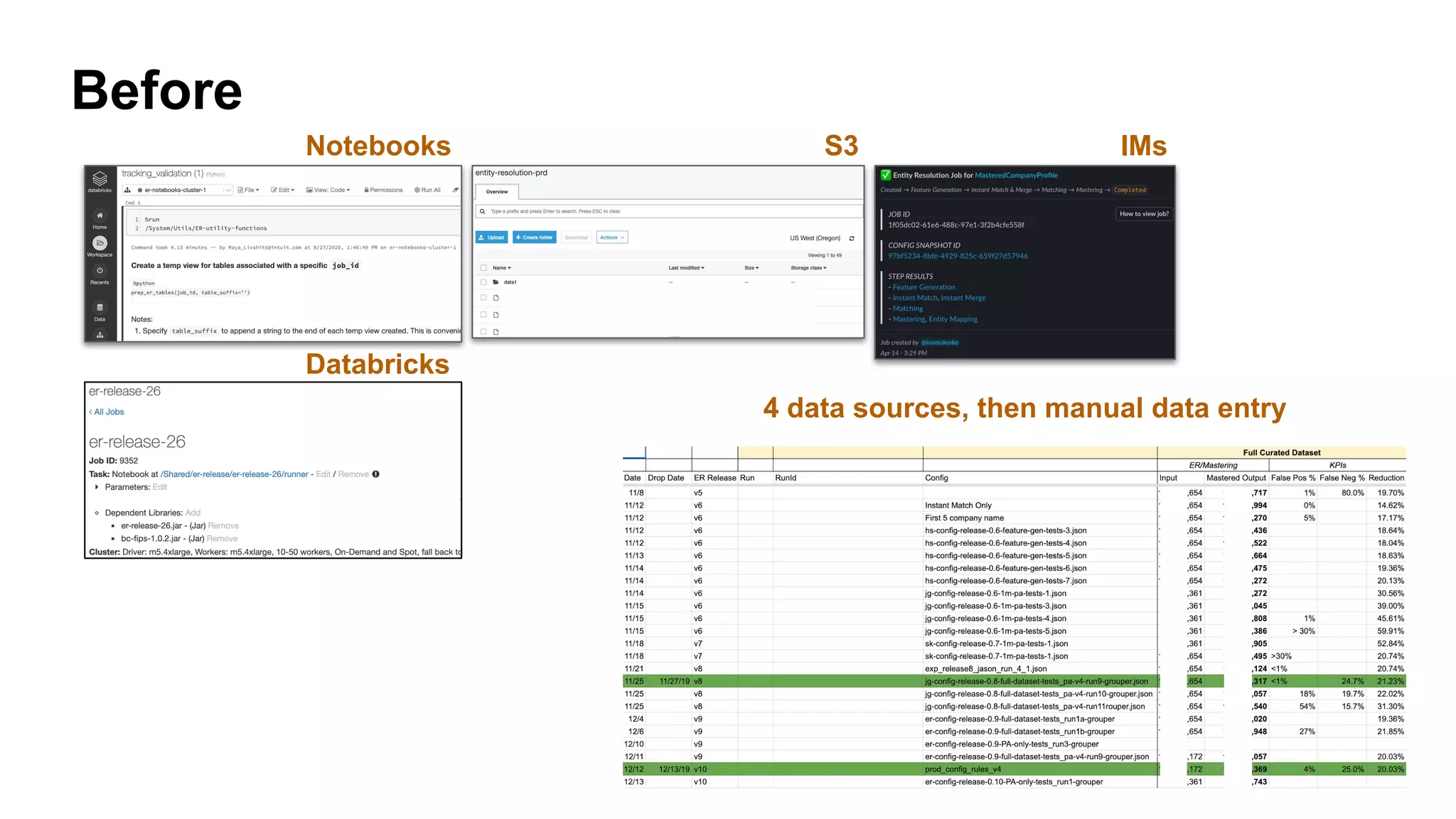

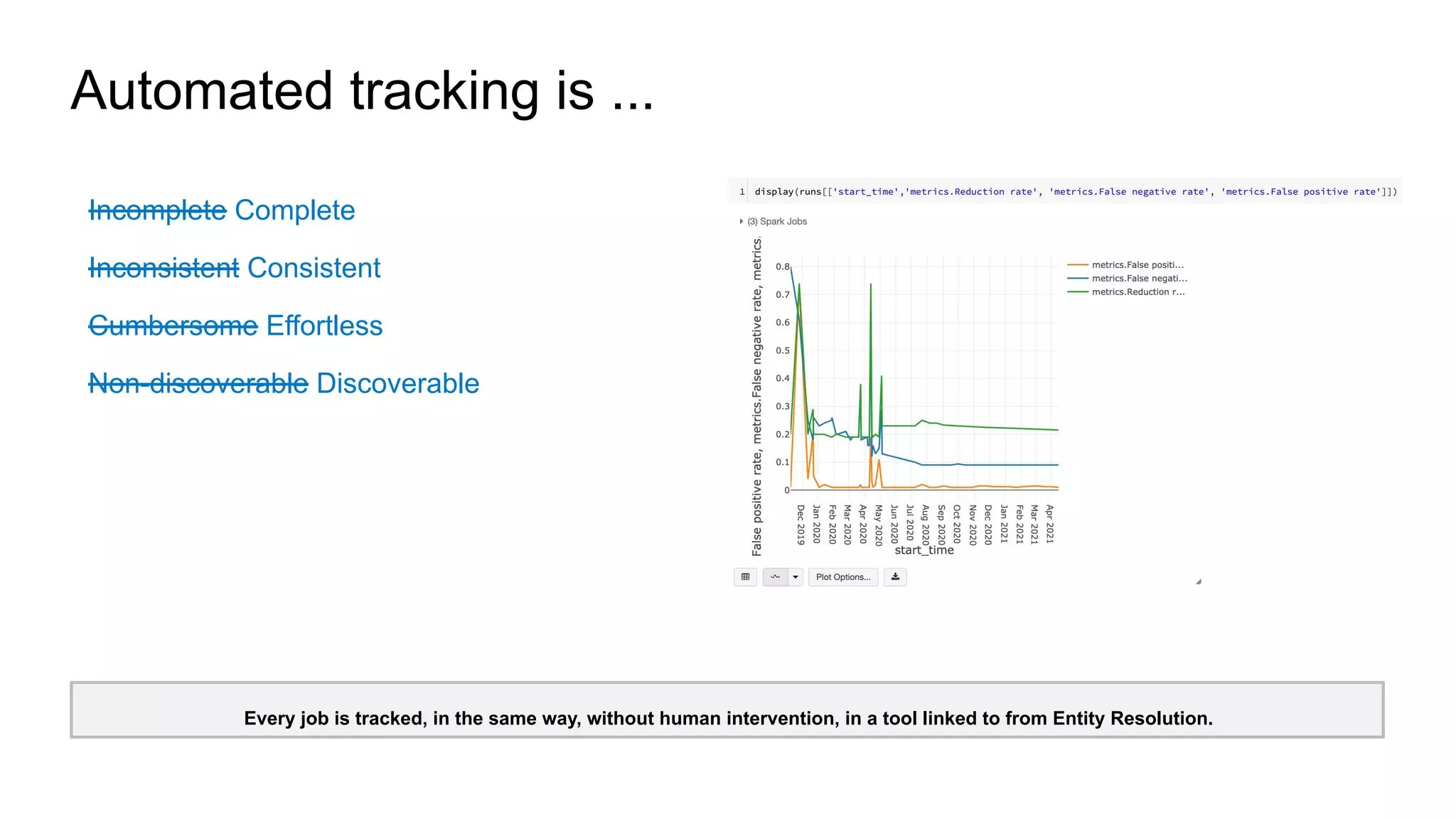


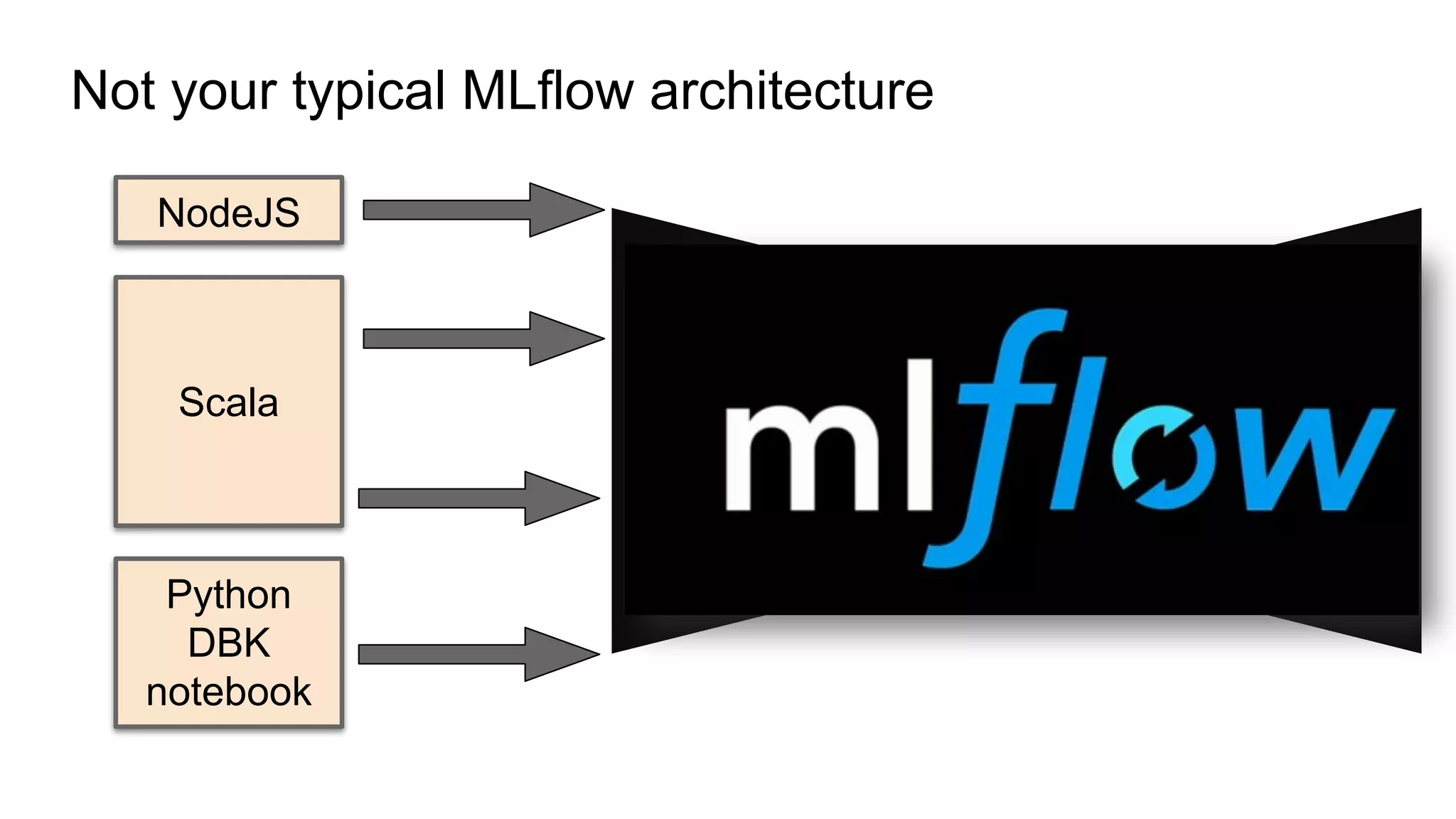
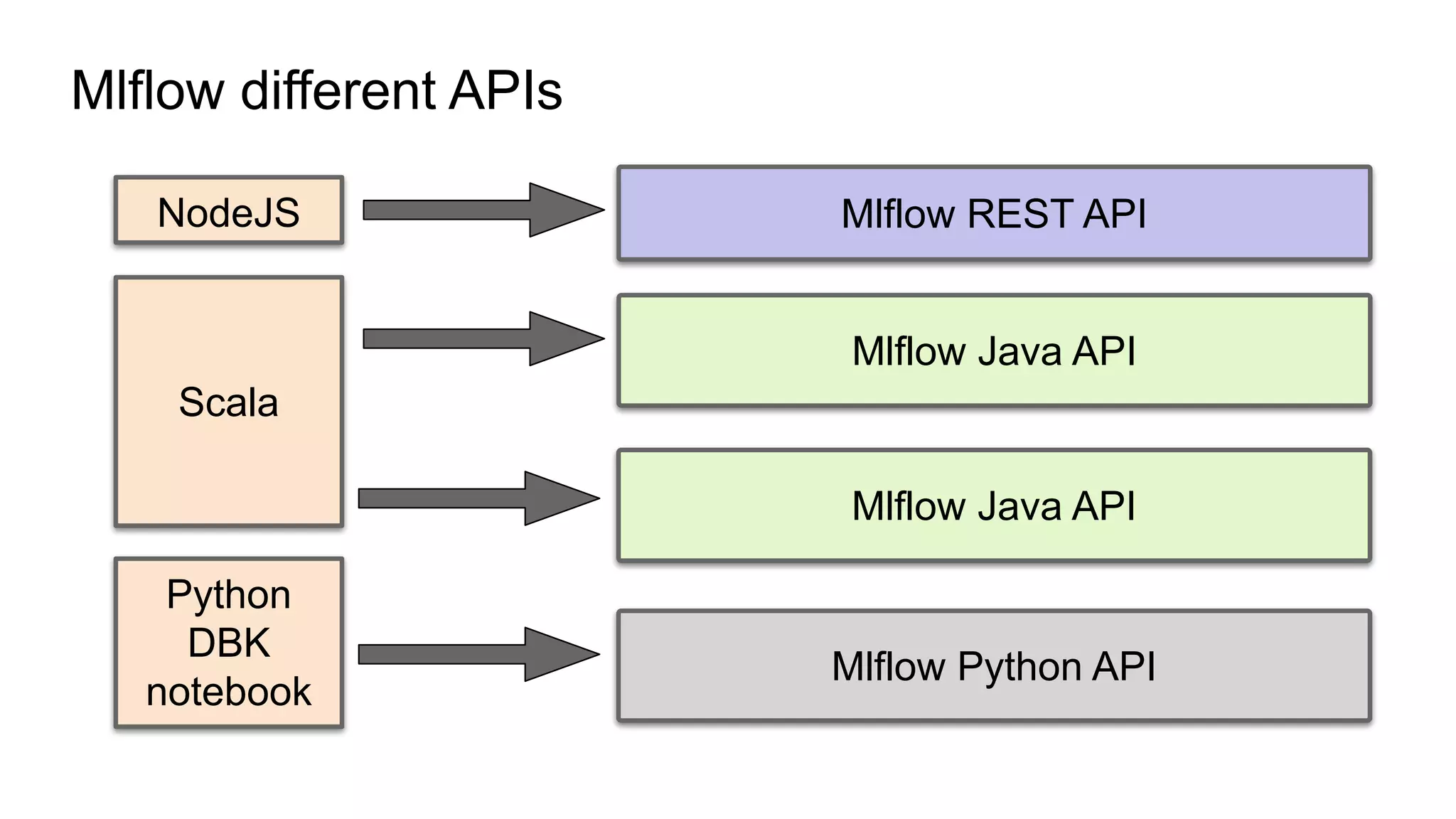

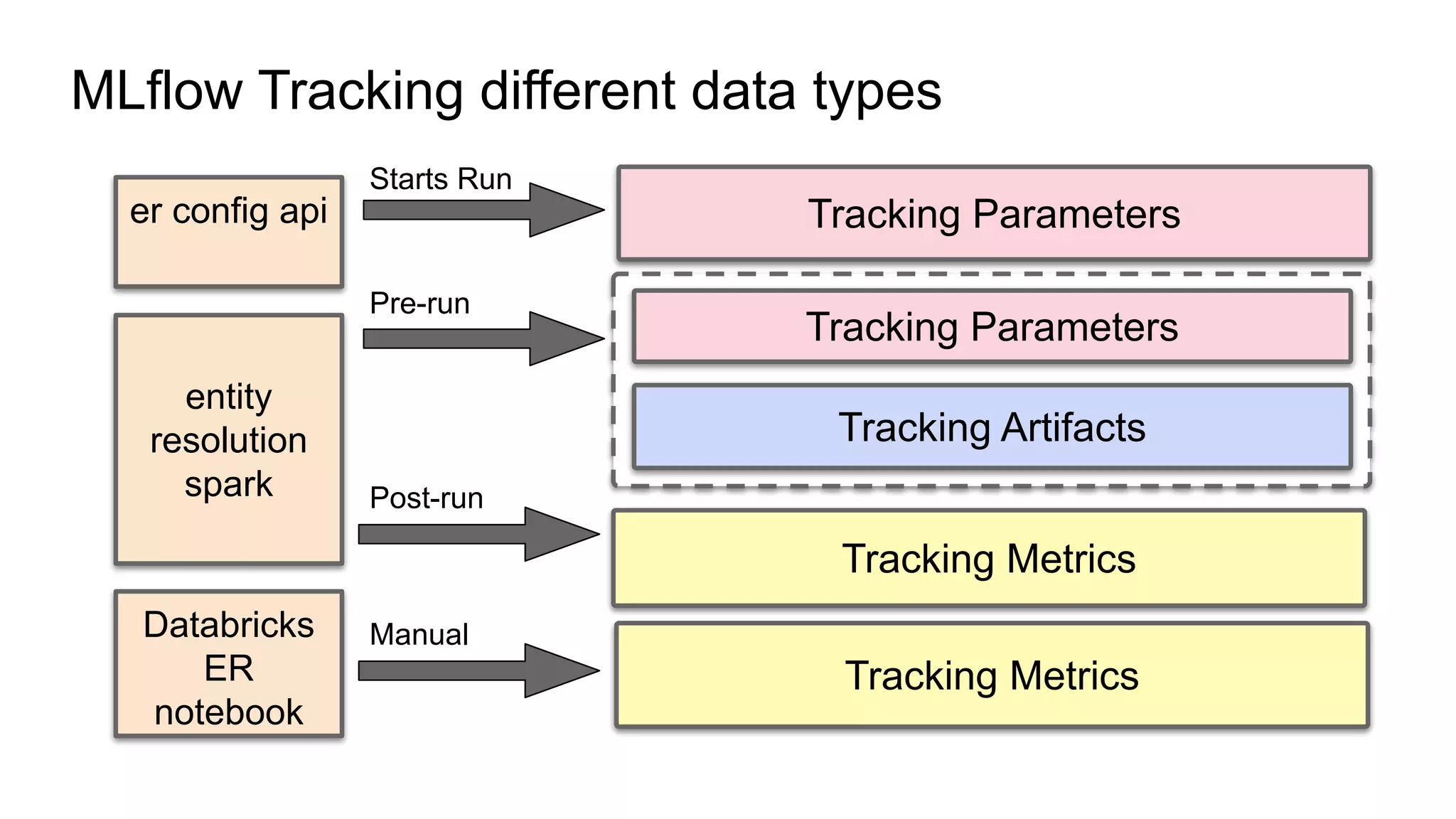
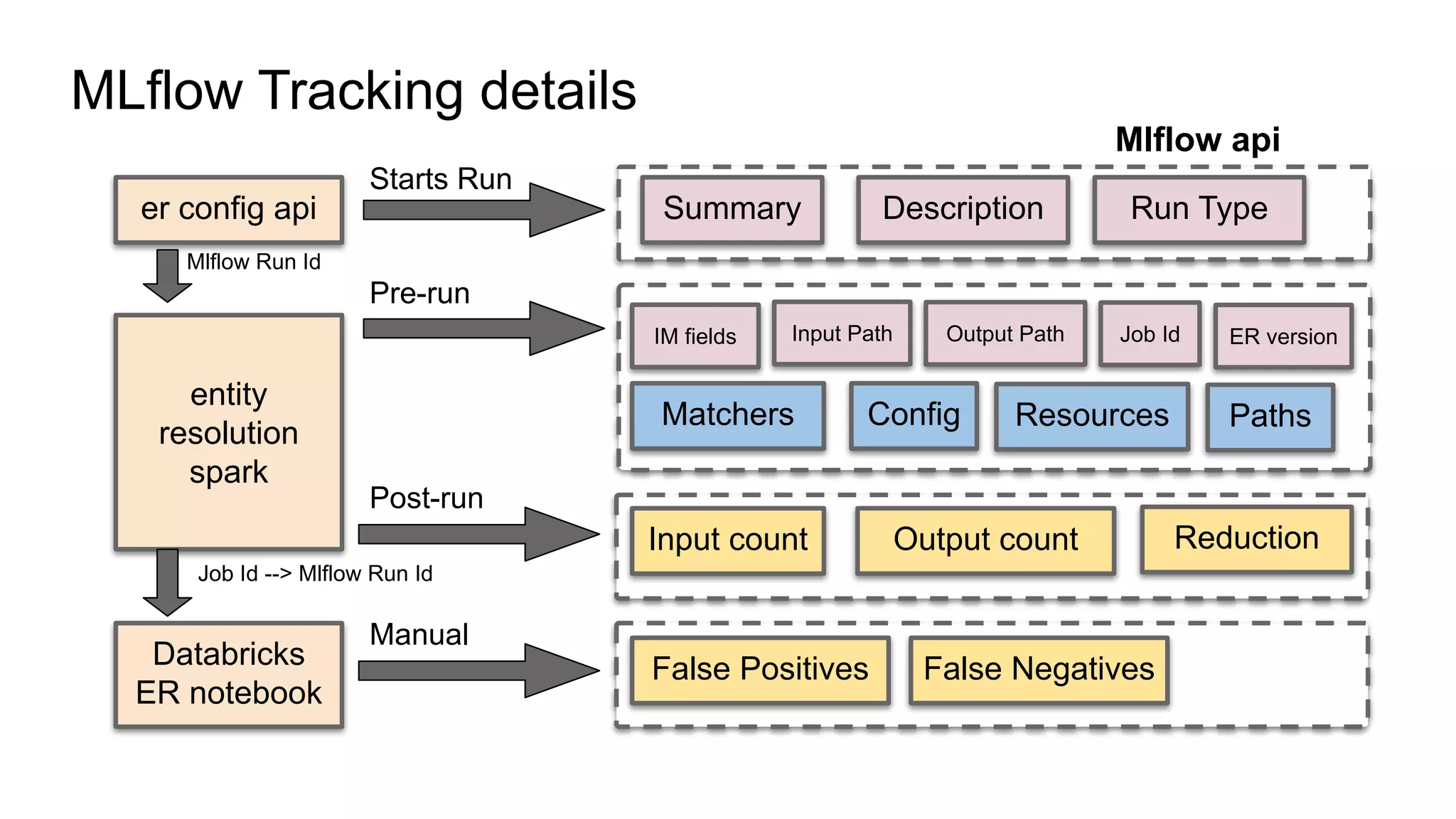
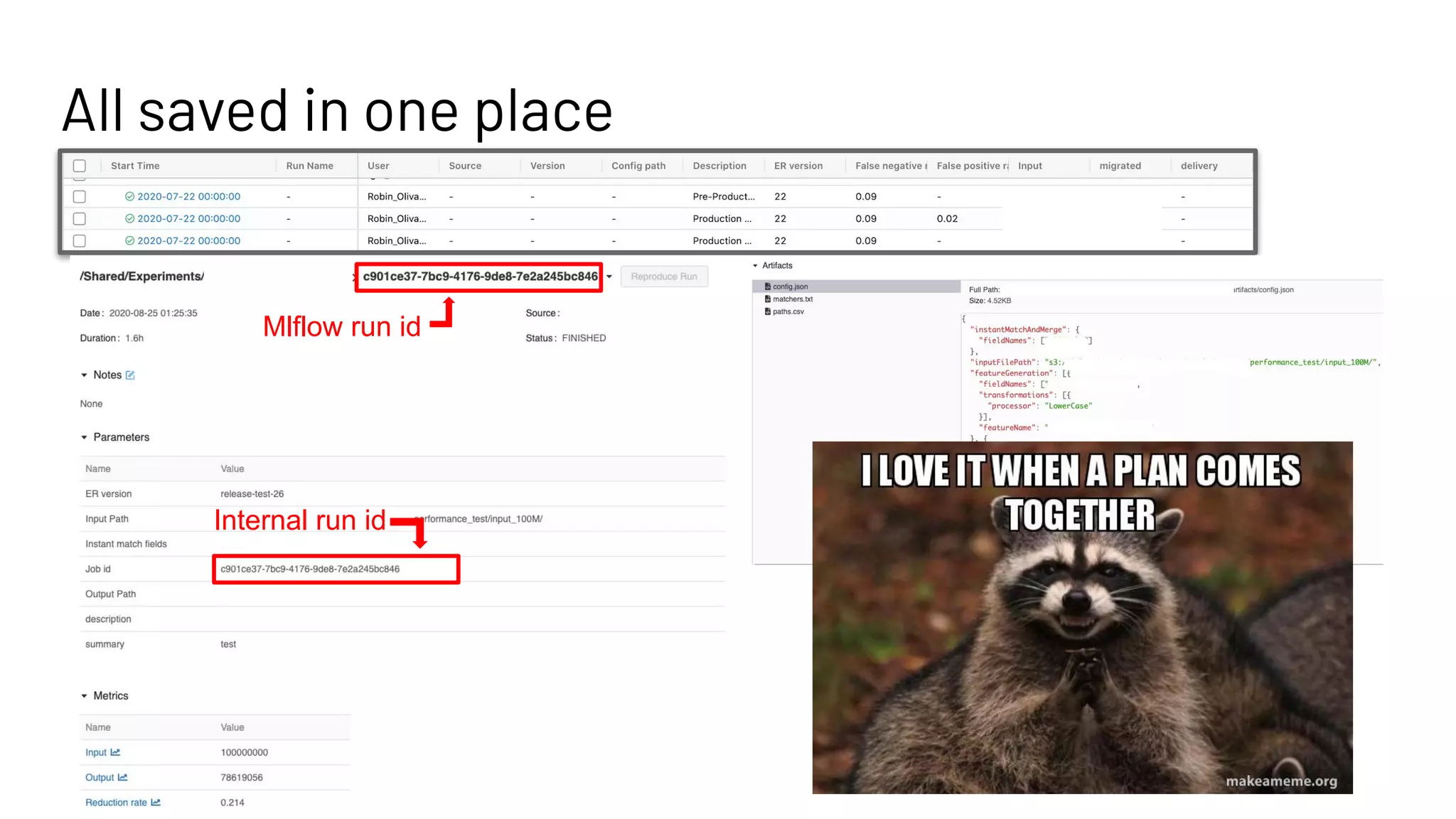




The document discusses the use of MLflow in simplifying the process of deduplicating data at scale, addressing the issues of duplicate records in various company contexts. It highlights the challenges faced by data analysts, such as manual tracking and inconsistent data entry, and presents auto-tracking as a solution to improve the tracking of data experiments. The authors suggest that automating the tracking process through MLflow can enhance productivity and provide clearer insights for analysts.
































![[DSC Croatia 22] Building smarter ML and AI models and making them more accur...](https://cdn.slidesharecdn.com/ss_thumbnails/buildingsmartermlandaimodelsandmakingthemmoreaccurate-auniqueandacceleratedapproachfordecisionsuppor-220608090138-b107b477-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC DACH 23] Go with the flow – Track your machine learning lifecycle using ...](https://cdn.slidesharecdn.com/ss_thumbnails/pspddscdachmlflow-230424084504-4f833f21-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)







