Event detection in urban context by using aggregated mobile activity as for example CDR data and social network data in this case geo-referenced Twitter data. The experiments show that the two datasets - CDR and social data - used, complement each other by providing better event detection results and event detscription.
The Physical Web is a generic term describes interconnection of physical objects and web. The Physical Web lets present physical objects in a web. There are different ways to do that and we will discuss them in our paper. Usually, the web presentation for a physical object could be implemented with the help of mobile devices. The basic idea behind the Physical Web is to navigate and control physical objects in the world surrounding mobile devices with the help of web technologies. Of course, there are different ways to identify and enumerate physical objects. In this paper, we describe the existing models as well as related challenges. In our analysis, we will target objects enumeration and navigation as well as data retrieving and programming for the Physical Web
The Physical Web is a generic term describes interconnection of physical objects and web. The Physical Web lets present physical objects in a web. There are different ways to do that and we will discuss them in our paper. Usually, the web presentation for a physical object could be implemented with the help of mobile devices. The basic idea behind the Physical Web is to navigate and control physical objects in the world surrounding mobile devices with the help of web technologies. Of course, there are different ways to identify and enumerate physical objects. In this paper, we describe the existing models as well as related challenges. In our analysis, we will target objects enumeration and navigation as well as data retrieving and programming for the Physical Web
TREND-BASED NETWORKING DRIVEN BY BIG DATA TELEMETRY FOR SDN AND TRADITIONAL N...ijngnjournal
Organizations face a challenge of accurately analyzing network data and providing automated action
based on the observed trend. This trend-based analytics is beneficial to minimize the downtime and
improve the performance of the network services, but organizations use different network management
tools to understand and visualize the network traffic with limited abilities to dynamically optimize the
network. This research focuses on the development of an intelligent system that leverages big data
telemetry analysis in Platform for Network Data Analytics (PNDA) to enable comprehensive trendbased networking decisions. The results include a graphical user interface (GUI) done via a web
application for effortless management of all subsystems, and the system and application developed in
this research demonstrate the true potential for a scalable system capable of effectively benchmarking
the network to set the expected behavior for comparison and trend analysis. Moreover, this research
provides a proof of concept of how trend analysis results are actioned in both a traditional network and
a software-defined network (SDN) to achieve dynamic, automated load balancing.
This paper is devoted to the crowd sensing applications. Crowd sensing (mobile crowd sensing in our case) is a new sensing paradigm based on the power of the crowd with the sensing capabilities of mobile devices, such as smartphones or wearable devices. This power is based on the smartphones, usually equipped with multiple sensors. So, it enables to collect local information from the individual’s surrounding environment with the help of sensing features of the mobile devices. In this paper, we provide the review of the back-end systems (data stores, etc.) for mobile crowd sensing systems. The main goal of this review is to propose the software architecture for mobile crowd sensing in Smart City environment. We discuss also the deployment of cloud-back-ends in Russia.
9th International Conference on Database and Data Mining (DBDM 2021)albert ca
9th International Conference on Database and Data Mining (DBDM 2021) Conference provides a forum for researchers who address this issue and to present their work in a peer-reviewed forum.
Authors are solicited to contribute to the conference by submitting articles that illustrate research results, projects, surveying works and industrial experiences that describe significant advances in the following areas, but are not limited to these topics only.
Understanding mobile service usage and user behavior pattern for mec resource...Sabidur Rahman
Zettabytes of data is collected every minute (which qualifies as Big Data) on mobile service usage and network status from all over the network. But the data was not actionable because Network being static hardware and lack of proper orchestration/management . With the moving trend towards Virtualization of Network and Mobile Edge Computing, we see a future where collected data can lead to actionable Resource Management.
TREND-BASED NETWORKING DRIVEN BY BIG DATA TELEMETRY FOR SDN AND TRADITIONAL N...ijngnjournal
Organizations face a challenge of accurately analyzing network data and providing automated action
based on the observed trend. This trend-based analytics is beneficial to minimize the downtime and
improve the performance of the network services, but organizations use different network management
tools to understand and visualize the network traffic with limited abilities to dynamically optimize the
network. This research focuses on the development of an intelligent system that leverages big data
telemetry analysis in Platform for Network Data Analytics (PNDA) to enable comprehensive trendbased networking decisions. The results include a graphical user interface (GUI) done via a web
application for effortless management of all subsystems, and the system and application developed in
this research demonstrate the true potential for a scalable system capable of effectively benchmarking
the network to set the expected behavior for comparison and trend analysis. Moreover, this research
provides a proof of concept of how trend analysis results are actioned in both a traditional network and
a software-defined network (SDN) to achieve dynamic, automated load balancing.
This paper is devoted to the crowd sensing applications. Crowd sensing (mobile crowd sensing in our case) is a new sensing paradigm based on the power of the crowd with the sensing capabilities of mobile devices, such as smartphones or wearable devices. This power is based on the smartphones, usually equipped with multiple sensors. So, it enables to collect local information from the individual’s surrounding environment with the help of sensing features of the mobile devices. In this paper, we provide the review of the back-end systems (data stores, etc.) for mobile crowd sensing systems. The main goal of this review is to propose the software architecture for mobile crowd sensing in Smart City environment. We discuss also the deployment of cloud-back-ends in Russia.
9th International Conference on Database and Data Mining (DBDM 2021)albert ca
9th International Conference on Database and Data Mining (DBDM 2021) Conference provides a forum for researchers who address this issue and to present their work in a peer-reviewed forum.
Authors are solicited to contribute to the conference by submitting articles that illustrate research results, projects, surveying works and industrial experiences that describe significant advances in the following areas, but are not limited to these topics only.
Understanding mobile service usage and user behavior pattern for mec resource...Sabidur Rahman
Zettabytes of data is collected every minute (which qualifies as Big Data) on mobile service usage and network status from all over the network. But the data was not actionable because Network being static hardware and lack of proper orchestration/management . With the moving trend towards Virtualization of Network and Mobile Edge Computing, we see a future where collected data can lead to actionable Resource Management.
Many technical communities are vigorously pursuing
research topics that contribute to the Internet of Things (IoT).
Nowadays, as sensing, actuation, communication, and control become
even more sophisticated and ubiquitous, there is a significant
overlap in these communities, sometimes from slightly different
perspectives. More cooperation between communities is encouraged.
To provide a basis for discussing open research problems in
IoT, a vision for how IoT could change the world in the
distant future is first presented. Then, eight key research topics
are enumerated and research problems within these topics are
discussed.
Show and Tell - Data and Digitalisation, Digital Twins.pdfSIFOfgem
This is the third in a series of 'Show and Tell' webinars from the Ofgem Strategic Innovation Fund Discovery phase, covering the Digital Twin projects.
As the move towards a net zero energy system accelerates, network customers and consumers will require simplified and accessible digital products, processes and services that can improve their user experience. Data and digital initiatives are already beginning to show the potential to improve the efficiency of energy networks whilst making it easier for third parties to interact with and innovate for the energy system. Digitalisation of energy network activities will contribute to better coordination, planning and network optimisation.
You will hear from SIF projects which are investigating new digital products and services such as digital twins.
The Strategic Innovation Fund (SIF) is an Ofgem programme managed in partnership with Innovate UK, part of UKRI. The SIF aims to fund network innovation that will contribute to achieving Net Zero rapidly and at lowest cost to consumers, and help transform the UK into the ‘Silicon Valley’ of energy, making it the best place for high-potential businesses to grow and scale in the energy market.
For more information on the SIF visit: www.ofgem.gov.uk/sif
Or sign-up for our newsletter here: https://ukri.innovateuk.org/ofgem-sif-subscription-sign-up
Scientific Knowledge from Geospatial Observations George Percivall
Presentation to IGARSS 2015 Conference, July 205, Milan Italy.
Part of invited session: Why Data Matters: Value of Stewardship and Knowledge Augmentation Services
In Drazen talk, you will get a chance to listen to how Data Science Master 4.0 on Belgrade University was created, and what are the benefits of the program.
EarthCube Monthly Community Webinar- Nov. 22, 2013EarthCube
This webinar features project overviews of all EarthCube Awards (Building Blocks, Research Coordination Networks, Conceptual Designs, and Test Governance), followed by a call for involvement, and a Q&A session.
Agenda:
EarthCube Awards – Project Overviews
1.. EarthCube Web Services (Building Block)
2. EC3: Earth-Centered Community for Cyberinfrastructure (RCN)
3. GeoSoft (Building Block)
4. Specifying and Implementing ODSIP (Building Block)
5. A Broker Framework for Next Generation Geoscience (BCube) (Building Block)
6. Integrating Discrete and Continuous Data (Building Block)
7. EAGER: Collaborative Research (Building Block)
8. A Cognitive Computer Infrastructure for Geoscience (Building Block)
9. Earth System Bridge (Building Block)
10. CINERGI – Community Inventory of EC Resources for Geoscience Interoperability (BB)
11. Building a Sediment Experimentalist Network (RCN)
12. C4P: Collaboration and Cyberinfrastructure for Paleogeosciences (RCN)
13. Developing a Data-Oriented Human-centric Enterprise for Architecture (CD)
14. Enterprise Architecture for Transformative Research and Collaboration (CD)
15. EC Test Enterprise Governance: An Agile Approach (Test Governance)
A Call for Involvement!
Building a semantic-based decision support system to optimize the energy use ...Gonçal Costa Jutglar
The reduction of carbon emissions in cities is a systemic problem which involves multiple scales and domains and the collaboration of experts from various fields. The smart cities approach can contribute to improve the energy efficiency of urban areas provided that there is reliable data –from the different domains concerned with carbon emission reduction– to assess their energy performance and to make decisions to improve it. In the SEMANCO project, we applied Semantic Web technologies to solve the interoperability among data, systems, tools, and users in applications cases dealing with carbon emission reduction in urban areas. In the OPTIMUS project, the tools and methods developed in SEMANCO are being further enhanced and applied to the development of a decision support system (DSS) to help local administrations to optimize the energy use of public buildings.
Location Data - Finding the needle in the haystackLucy Woods
Here are a few sample sllides following Cambridge Wireless's (CW) Location Based Systems/Services Special Interest Group (SIG) event. Entitled 'location data - finding the needle in the haystack' we had speakers from Crossrail, GeoSpock, Autodesk and Advanced Laser Imaging. For more information about CW, head over to our website or email admin@cambridgewireless.co.uk
International Journal of Engineering Research and Applications (IJERA) is an open access online peer reviewed international journal that publishes research and review articles in the fields of Computer Science, Neural Networks, Electrical Engineering, Software Engineering, Information Technology, Mechanical Engineering, Chemical Engineering, Plastic Engineering, Food Technology, Textile Engineering, Nano Technology & science, Power Electronics, Electronics & Communication Engineering, Computational mathematics, Image processing, Civil Engineering, Structural Engineering, Environmental Engineering, VLSI Testing & Low Power VLSI Design etc.
SEMANCO - Integrating multiple data sources, domains and tools in urban ener...Álvaro Sicilia
Semantic-based interoperability based on ontologies provide an alternative to centralized stand-ard data models. They help to integrate heterogeneous data produced by loose coupled information systems and to interlink these data with different tools in ad hoc situations. In the SEMANCO project (www.semanco-project.eu) we have used semantic technologies to create energy models of urban areas encompassing a variety of data sources and do-mains (building, geospatial, energy, climate, socioeconomic). The semantically modelled data has been made accessible to a set of simulation and analysis tools. The interoperability among the data sources and between these and the tools that interact with them is assured by a Semantic Energy Information Framework (SEIF) developed in the project. The access to the data and tools takes place in the SEMANCO integrated platform. In this paper we describe the work carried out to integrate an existing simulation software –URSOS– with the semantic data model. The functionalities of the tool and the integrated platform have been demonstrated in an application case carried out in the city of Manresa, in Spain
Capella Days 2021 | An example of model-centric engineering environment with ...Obeo
Today a number of EU railway operators are on a journey to define what the future of railway operations should look like. In Germany, DB AG works within the sector initiative Digitale Schiene Deutschland. Next to the implementation of ETCS/DSTW technology in the first stage, the initiatives aims in the second stage to improve the performance, quality and efficiency of the railway system by higher degrees of automation in traffic management, train driving and infrastructure operation. This requires implementation of new technologies like artificial intelligence, localization and perception sensors, cloud computing and 5G connectivity.
Data Harvesting, Curation and Fusion Model to Support Public Service Recommen...Citadelh2020
CITADEL is a H2020 European project that is creating an ecosystem of best practices, tools, and recommendations to transform Public Administrations (PAs) via an inclusive approach in order to provide stakeholders with more efficient, inclusive and citizen-centric services. The CITADEL ecosystem will allow PAs to use what they already know plus new data to implement what really matters to citizens in order to shape and co-create more efficient and inclusive public services. CITADEL innovates by using ICTs to find out why citizens stop using public services, and use this information to re-adjust provision to bring them back in. Also, it identifies why citizens are not using a given public service (due to affordability, accessibility, lack of knowledge, embarrassment, lack of interest, etc.) and, where appropriate, use this information to make public services more attractive, so they start using the services.
The DataTank, a tool designed and developed by IMEC’s IDLab, will be extended to provide the Data Harvesting/Curation/Fusion (DHCF) component of the platform. The DataTank provides an open source, open data platform which not only allows publishing datasets according to standardised guidelines and taxonomies (DCAT-AP), but also transforms the data into a variety of reusable formats. The extension will include an intelligent way of harvesting and fusion of different data sources using semantics and Linked Data mapping technologies developed by IDLab. In the context of CITADEL the new HCF component will enable the visualization and analysis of trends for the usage of public services in European cities, playing a key role in generating personalized recommendations to the citizens as well as to PAs in terms of suggesting improvements to the current suite of public services.
https://twitter.com/Citadelh2020
https://twitter.com/gayane_sedraky
https://twitter.com/imec_int
https://twitter.com/IDLabResearch
Data Harvesting, Curation and Fusion Model to Support Public Service Recommen...Gayane Sedrakyan
CITADEL is a H2020 European project that is creating an ecosystem of best practices, tools, and recommendations to transform Public Administrations (PAs) via an inclusive approach in order to provide stakeholders with more efficient, inclusive and citizen-centric services. The CITADEL ecosystem will allow PAs to use what they already know plus new data to implement what really matters to citizens in order to shape and co-create more efficient and inclusive public services. CITADEL innovates by using ICTs to find out why citizens stop using public services, and use this information to re-adjust provision to bring them back in. Also, it identifies why citizens are not using a given public service (due to affordability, accessibility, lack of knowledge, embarrassment, lack of interest, etc.) and, where appropriate, use this information to make public services more attractive, so they start using the services.
The DataTank, a tool designed and developed by IMEC’s IDLab, will be extended to provide the Data Harvesting/Curation/Fusion (DHCF) component of the platform. The DataTank provides an open source, open data platform which not only allows publishing datasets according to standardised guidelines and taxonomies (DCAT-AP), but also transforms the data into a variety of reusable formats. The extension will include an intelligent way of harvesting and fusion of different data sources using semantics and Linked Data mapping technologies developed by IDLab. In the context of CITADEL the new HCF component will enable the visualization and analysis of trends for the usage of public services in European cities, playing a key role in generating personalized recommendations to the citizens as well as to PAs in terms of suggesting improvements to the current suite of public services.
Distributed systems and blockchain technologyAlket Cecaj
An introduction to blockchain technology starting from the distributed systems and the CAP theorem. Consensus mechanisms explained on the bitcoin blockchain.
Richard's entangled aventures in wonderlandRichard Gill
Since the loophole-free Bell experiments of 2020 and the Nobel prizes in physics of 2022, critics of Bell's work have retreated to the fortress of super-determinism. Now, super-determinism is a derogatory word - it just means "determinism". Palmer, Hance and Hossenfelder argue that quantum mechanics and determinism are not incompatible, using a sophisticated mathematical construction based on a subtle thinning of allowed states and measurements in quantum mechanics, such that what is left appears to make Bell's argument fail, without altering the empirical predictions of quantum mechanics. I think however that it is a smoke screen, and the slogan "lost in math" comes to my mind. I will discuss some other recent disproofs of Bell's theorem using the language of causality based on causal graphs. Causal thinking is also central to law and justice. I will mention surprising connections to my work on serial killer nurse cases, in particular the Dutch case of Lucia de Berk and the current UK case of Lucy Letby.
The increased availability of biomedical data, particularly in the public domain, offers the opportunity to better understand human health and to develop effective therapeutics for a wide range of unmet medical needs. However, data scientists remain stymied by the fact that data remain hard to find and to productively reuse because data and their metadata i) are wholly inaccessible, ii) are in non-standard or incompatible representations, iii) do not conform to community standards, and iv) have unclear or highly restricted terms and conditions that preclude legitimate reuse. These limitations require a rethink on data can be made machine and AI-ready - the key motivation behind the FAIR Guiding Principles. Concurrently, while recent efforts have explored the use of deep learning to fuse disparate data into predictive models for a wide range of biomedical applications, these models often fail even when the correct answer is already known, and fail to explain individual predictions in terms that data scientists can appreciate. These limitations suggest that new methods to produce practical artificial intelligence are still needed.
In this talk, I will discuss our work in (1) building an integrative knowledge infrastructure to prepare FAIR and "AI-ready" data and services along with (2) neurosymbolic AI methods to improve the quality of predictions and to generate plausible explanations. Attention is given to standards, platforms, and methods to wrangle knowledge into simple, but effective semantic and latent representations, and to make these available into standards-compliant and discoverable interfaces that can be used in model building, validation, and explanation. Our work, and those of others in the field, creates a baseline for building trustworthy and easy to deploy AI models in biomedicine.
Bio
Dr. Michel Dumontier is the Distinguished Professor of Data Science at Maastricht University, founder and executive director of the Institute of Data Science, and co-founder of the FAIR (Findable, Accessible, Interoperable and Reusable) data principles. His research explores socio-technological approaches for responsible discovery science, which includes collaborative multi-modal knowledge graphs, privacy-preserving distributed data mining, and AI methods for drug discovery and personalized medicine. His work is supported through the Dutch National Research Agenda, the Netherlands Organisation for Scientific Research, Horizon Europe, the European Open Science Cloud, the US National Institutes of Health, and a Marie-Curie Innovative Training Network. He is the editor-in-chief for the journal Data Science and is internationally recognized for his contributions in bioinformatics, biomedical informatics, and semantic technologies including ontologies and linked data.
Earliest Galaxies in the JADES Origins Field: Luminosity Function and Cosmic ...Sérgio Sacani
We characterize the earliest galaxy population in the JADES Origins Field (JOF), the deepest
imaging field observed with JWST. We make use of the ancillary Hubble optical images (5 filters
spanning 0.4−0.9µm) and novel JWST images with 14 filters spanning 0.8−5µm, including 7 mediumband filters, and reaching total exposure times of up to 46 hours per filter. We combine all our data
at > 2.3µm to construct an ultradeep image, reaching as deep as ≈ 31.4 AB mag in the stack and
30.3-31.0 AB mag (5σ, r = 0.1” circular aperture) in individual filters. We measure photometric
redshifts and use robust selection criteria to identify a sample of eight galaxy candidates at redshifts
z = 11.5 − 15. These objects show compact half-light radii of R1/2 ∼ 50 − 200pc, stellar masses of
M⋆ ∼ 107−108M⊙, and star-formation rates of SFR ∼ 0.1−1 M⊙ yr−1
. Our search finds no candidates
at 15 < z < 20, placing upper limits at these redshifts. We develop a forward modeling approach to
infer the properties of the evolving luminosity function without binning in redshift or luminosity that
marginalizes over the photometric redshift uncertainty of our candidate galaxies and incorporates the
impact of non-detections. We find a z = 12 luminosity function in good agreement with prior results,
and that the luminosity function normalization and UV luminosity density decline by a factor of ∼ 2.5
from z = 12 to z = 14. We discuss the possible implications of our results in the context of theoretical
models for evolution of the dark matter halo mass function.
Slide 1: Title Slide
Extrachromosomal Inheritance
Slide 2: Introduction to Extrachromosomal Inheritance
Definition: Extrachromosomal inheritance refers to the transmission of genetic material that is not found within the nucleus.
Key Components: Involves genes located in mitochondria, chloroplasts, and plasmids.
Slide 3: Mitochondrial Inheritance
Mitochondria: Organelles responsible for energy production.
Mitochondrial DNA (mtDNA): Circular DNA molecule found in mitochondria.
Inheritance Pattern: Maternally inherited, meaning it is passed from mothers to all their offspring.
Diseases: Examples include Leber’s hereditary optic neuropathy (LHON) and mitochondrial myopathy.
Slide 4: Chloroplast Inheritance
Chloroplasts: Organelles responsible for photosynthesis in plants.
Chloroplast DNA (cpDNA): Circular DNA molecule found in chloroplasts.
Inheritance Pattern: Often maternally inherited in most plants, but can vary in some species.
Examples: Variegation in plants, where leaf color patterns are determined by chloroplast DNA.
Slide 5: Plasmid Inheritance
Plasmids: Small, circular DNA molecules found in bacteria and some eukaryotes.
Features: Can carry antibiotic resistance genes and can be transferred between cells through processes like conjugation.
Significance: Important in biotechnology for gene cloning and genetic engineering.
Slide 6: Mechanisms of Extrachromosomal Inheritance
Non-Mendelian Patterns: Do not follow Mendel’s laws of inheritance.
Cytoplasmic Segregation: During cell division, organelles like mitochondria and chloroplasts are randomly distributed to daughter cells.
Heteroplasmy: Presence of more than one type of organellar genome within a cell, leading to variation in expression.
Slide 7: Examples of Extrachromosomal Inheritance
Four O’clock Plant (Mirabilis jalapa): Shows variegated leaves due to different cpDNA in leaf cells.
Petite Mutants in Yeast: Result from mutations in mitochondrial DNA affecting respiration.
Slide 8: Importance of Extrachromosomal Inheritance
Evolution: Provides insight into the evolution of eukaryotic cells.
Medicine: Understanding mitochondrial inheritance helps in diagnosing and treating mitochondrial diseases.
Agriculture: Chloroplast inheritance can be used in plant breeding and genetic modification.
Slide 9: Recent Research and Advances
Gene Editing: Techniques like CRISPR-Cas9 are being used to edit mitochondrial and chloroplast DNA.
Therapies: Development of mitochondrial replacement therapy (MRT) for preventing mitochondrial diseases.
Slide 10: Conclusion
Summary: Extrachromosomal inheritance involves the transmission of genetic material outside the nucleus and plays a crucial role in genetics, medicine, and biotechnology.
Future Directions: Continued research and technological advancements hold promise for new treatments and applications.
Slide 11: Questions and Discussion
Invite Audience: Open the floor for any questions or further discussion on the topic.
THE IMPORTANCE OF MARTIAN ATMOSPHERE SAMPLE RETURN.Sérgio Sacani
The return of a sample of near-surface atmosphere from Mars would facilitate answers to several first-order science questions surrounding the formation and evolution of the planet. One of the important aspects of terrestrial planet formation in general is the role that primary atmospheres played in influencing the chemistry and structure of the planets and their antecedents. Studies of the martian atmosphere can be used to investigate the role of a primary atmosphere in its history. Atmosphere samples would also inform our understanding of the near-surface chemistry of the planet, and ultimately the prospects for life. High-precision isotopic analyses of constituent gases are needed to address these questions, requiring that the analyses are made on returned samples rather than in situ.
Cancer cell metabolism: special Reference to Lactate PathwayAADYARAJPANDEY1
Normal Cell Metabolism:
Cellular respiration describes the series of steps that cells use to break down sugar and other chemicals to get the energy we need to function.
Energy is stored in the bonds of glucose and when glucose is broken down, much of that energy is released.
Cell utilize energy in the form of ATP.
The first step of respiration is called glycolysis. In a series of steps, glycolysis breaks glucose into two smaller molecules - a chemical called pyruvate. A small amount of ATP is formed during this process.
Most healthy cells continue the breakdown in a second process, called the Kreb's cycle. The Kreb's cycle allows cells to “burn” the pyruvates made in glycolysis to get more ATP.
The last step in the breakdown of glucose is called oxidative phosphorylation (Ox-Phos).
It takes place in specialized cell structures called mitochondria. This process produces a large amount of ATP. Importantly, cells need oxygen to complete oxidative phosphorylation.
If a cell completes only glycolysis, only 2 molecules of ATP are made per glucose. However, if the cell completes the entire respiration process (glycolysis - Kreb's - oxidative phosphorylation), about 36 molecules of ATP are created, giving it much more energy to use.
IN CANCER CELL:
Unlike healthy cells that "burn" the entire molecule of sugar to capture a large amount of energy as ATP, cancer cells are wasteful.
Cancer cells only partially break down sugar molecules. They overuse the first step of respiration, glycolysis. They frequently do not complete the second step, oxidative phosphorylation.
This results in only 2 molecules of ATP per each glucose molecule instead of the 36 or so ATPs healthy cells gain. As a result, cancer cells need to use a lot more sugar molecules to get enough energy to survive.
Unlike healthy cells that "burn" the entire molecule of sugar to capture a large amount of energy as ATP, cancer cells are wasteful.
Cancer cells only partially break down sugar molecules. They overuse the first step of respiration, glycolysis. They frequently do not complete the second step, oxidative phosphorylation.
This results in only 2 molecules of ATP per each glucose molecule instead of the 36 or so ATPs healthy cells gain. As a result, cancer cells need to use a lot more sugar molecules to get enough energy to survive.
introduction to WARBERG PHENOMENA:
WARBURG EFFECT Usually, cancer cells are highly glycolytic (glucose addiction) and take up more glucose than do normal cells from outside.
Otto Heinrich Warburg (; 8 October 1883 – 1 August 1970) In 1931 was awarded the Nobel Prize in Physiology for his "discovery of the nature and mode of action of the respiratory enzyme.
WARNBURG EFFECT : cancer cells under aerobic (well-oxygenated) conditions to metabolize glucose to lactate (aerobic glycolysis) is known as the Warburg effect. Warburg made the observation that tumor slices consume glucose and secrete lactate at a higher rate than normal tissues.
Seminar of U.V. Spectroscopy by SAMIR PANDASAMIR PANDA
Spectroscopy is a branch of science dealing the study of interaction of electromagnetic radiation with matter.
Ultraviolet-visible spectroscopy refers to absorption spectroscopy or reflect spectroscopy in the UV-VIS spectral region.
Ultraviolet-visible spectroscopy is an analytical method that can measure the amount of light received by the analyte.
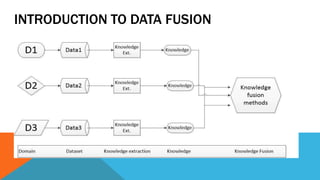
2. INTRODUCTION TO DATA FUSION METHODS
• Stage based methods.
• Feature level-based.
• Semantic meaning-based data fusion methods
3. LOCATION DATA FUSION : SIDE EFFECT
• Data fusion enables a huge number of applications
• Privacy risks for individual data
4. DATA FUSION FOR EVENT DETECTION /
DESCRIPTION BY USING AGGREGATED CDR DATA
AND GEO-TAGGED SOCIAL NETWORK DATA
Detecting and describing events happening in urban
areas by analysing spatio – temporal data
Detecting and describing events happening in urban areas
by analysing spatio – temporal data
Riferimento all’articolo
16. IMPROVING EVENT DETECTION RESULTS BY DATA
FUSION
By combining the results from
the two datasets
• Improvement of precision – recall
performance of the method
• The improvement is limited in the
long run by the main dataset.
• The same improvement can be
observed also by joining the results
of the other datasets.
17. DATA FUSION FOR EVENT DESCRIPTION
By using the CDR the events
can be detected but not
described:
• By joining the results the data
can complement and enrich
each other.
• In this case the social dataset
can be used to describe
semantically the events
18. CONFRONTING THE RESULTS WITH OTHER WORKS ON
EVENT DETECTION
• Two other similar works
• Using much more sophisticated algorithms
• Comparable results
19. CHALLENGES
• One of the main challenges is the lack of common engineering standards for data fusion
systems. It has been one of the main impediments to integration and data fusion.
• As different methods of data fusion behave differently in different applications, it is not trivial
to choose the best method for a specific task.
• Challenges during the data fusion design phase. At which level of abstraction, reduction and
simplification the data should be fused ?
• The lack of a unified framework that could orient the process of data fusion towards a
“structured data fusion” vision.
20. CONCLUSIONS AND FUTURE WORK
• Information fusion as a an enabling process for novel applications
- Future work oriented towards the “structured data fusion” idea
• Privacy
- Assesment of variations of existing privacy preserving techniques (D.P.)
21. PUBLICATIONS
• Nicola Bicocchi, Alket Cecaj, Damiano Fontana, Marco Mamei, Andrea Sassi, Franco Zambonelli: “ Collective Awareness for
Human ICT Collaboration in Smart Cities”. IEEE WETICE International conference on state-of-the art research in enabling
technologies for collaboration 17-20 2013.
• Alket Cecaj, Marco Mamei, Nicola Bicocchi : “ Re-identification of Anonymized CDR datasets Using Social Network Data ”. IEEE
Percom International conference on Pervasive Computing and Communications. Budapest, Hungary 24-28, 2014.
• Cecaj Alket, Marco Mamei (2016) : “Data Fusion for City Life Event Detection” In: Journal of Ambient Intelligence and
Humanized Computing, pp 1– 15.
• Nicola Bicocchi, Alket Cecaj, Damiano Fontana, Marco Mamei, Andrea Sassi, Franco Zambonelli.(2014) “ Social Collective
Awareness in Socio-Technical Urban Superorganisms ”. Social Collective Intelligence Combining the Powers Of Humans and
Machines to Build a Smarter Society,Part III, Applications and Case studies, page 227.
• Cecaj, Alket, Marco Mamei, and Franco Zambonelli (2015). “Re-identification and Information Fusion Between Anonymized
CDR and Social Network Data”. In: Journal of Ambient Intelligence and Humanized Computing, pp. 1–14.
Editor's Notes
This process integrates knowledge not just data.
Record matching vs knowledge fusion.
This is a category that uses different data sets that are in different stages of the process of data mining. Following this category, the data sets are loosely coupled without any requirements on their consistency.
This method treats features extracted from different data sets and creates an array by concatenating them. This array can then be used in clustering and classification methods.
3. These methods take in consideration the relations between features in different data sets.
This implies that the data miner knows what each data set represents, and why they can be fused
or why they re-inforce each other in terms of enrichment of information.
Data such as anonimyzed CDR or social network datasets
By following the diagram in the first chapter we present the steps for applying the data – fusion methods.
Milano Grid and time series of the activity levels of one of the cells during the two months period
Big data challenge 2014 : aggregated CDR data and geo-tagged social network data tables .