Downloaded 156 times


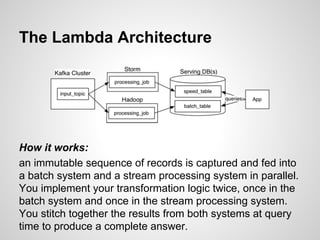


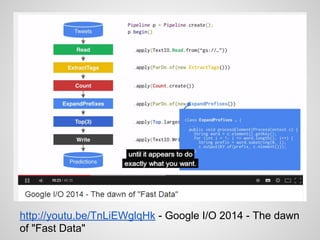

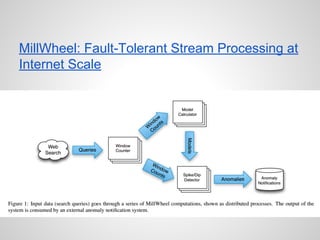

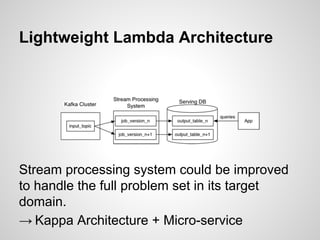

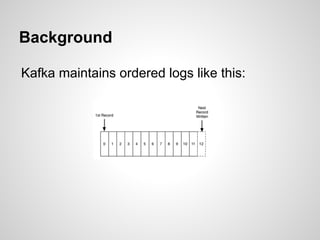
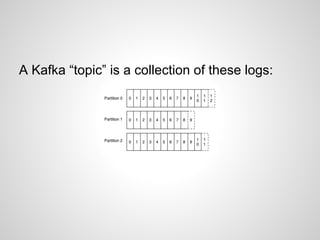
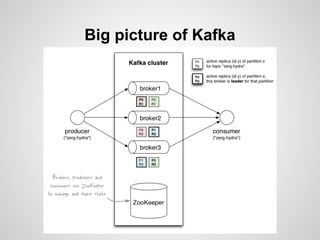


Google Cloud Dataflow is Google's successor to MapReduce, based on their internal Flume and MillWheel technologies. It aims to make building flexible analytics pipelines easier. The Lambda Architecture proposes processing data in batch and stream systems with the same logic, but maintaining code across different frameworks is difficult. While stream processing improves, the Kappa Architecture and microservices may provide a better approach through retaining event streams and reprocessing when needed.































![[Strata] Sparkta](https://cdn.slidesharecdn.com/ss_thumbnails/stratasparktav3-150507092440-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)































![[Notes] Customer 360 Analytics with LEO CDP](https://cdn.slidesharecdn.com/ss_thumbnails/notescustomer360analyticswithleocdp-220126053232-thumbnail.jpg?width=640&height=640&fit=bounds)





















![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)












