Download as PDF, PPTX






























![Similarity
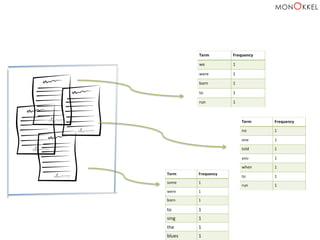
1. “We were born to
run ”
2. “No one told you
when to run”
3. “Some were born to
sing the blues”
[2,
0]
[0,
0]
[2,
5]
0
0
1
2
3
4
5
1
2
3
“blues”
“born”
query:
[2,5]
doc
3:
[2,5]
doc
2:
[0,0]
doc
1:
[2,0]](https://image.slidesharecdn.com/elasticsearchmeetuppresentationfeb2015-150220021050-conversion-gate02/85/Data-Exploration-with-Elasticsearch-34-320.jpg)












![hcp://localhost:9200/<index>/<type>/[<id>]](https://image.slidesharecdn.com/elasticsearchmeetuppresentationfeb2015-150220021050-conversion-gate02/85/Data-Exploration-with-Elasticsearch-48-320.jpg)












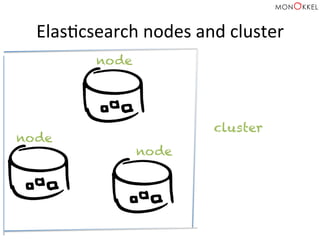
![MulH
Match
Query
{
"query":
{
"mulM_match":
{
"query":
"romeo",
"fields":
[
"text_entry",
"speaker"
]
}
}
}](https://image.slidesharecdn.com/elasticsearchmeetuppresentationfeb2015-150220021050-conversion-gate02/85/Data-Exploration-with-Elasticsearch-61-320.jpg)
![Bool
Query
{
"query":
{
"bool":
{
"must":
[
],
"must_not":
[
],
"should":
[
]
}
}
}](https://image.slidesharecdn.com/elasticsearchmeetuppresentationfeb2015-150220021050-conversion-gate02/85/Data-Exploration-with-Elasticsearch-62-320.jpg)
![Bool
Query
{
"query":
{
"bool":
{
"must":
{
"match":
{"text_entry":
"romeo"
}},
"must_not":
{
"match":
{"speaker":
"ROMEO"
}},
"should":
[
{
"match":
{"speaker":
"JULIET"
}},
{
"match":
{"speaker":
"FRIAR
LAURENCE"
}}
]
}
}
}](https://image.slidesharecdn.com/elasticsearchmeetuppresentationfeb2015-150220021050-conversion-gate02/85/Data-Exploration-with-Elasticsearch-63-320.jpg)





![Terms
Filter
{
"query":
{
"filtered":
{
"filter":
{
"terms":
{
"speaker":
["ROMEO",
"JULIET"]
}
}
}
}
}](https://image.slidesharecdn.com/elasticsearchmeetuppresentationfeb2015-150220021050-conversion-gate02/85/Data-Exploration-with-Elasticsearch-69-320.jpg)
![Bool
Filter
{
"query":
{
"filtered":
{
"filter":
{
"bool"
:
{
"must"
:
[],
"should"
:
[],
"must_not"
:
[]
}
}
}
}
}](https://image.slidesharecdn.com/elasticsearchmeetuppresentationfeb2015-150220021050-conversion-gate02/85/Data-Exploration-with-Elasticsearch-70-320.jpg)















The document provides an overview of data exploration using Elasticsearch, detailing its fundamentals, architecture, and operations such as indexing, querying, and filtering. It outlines how to implement searches and aggregations within the Elasticsearch environment while providing practical demos for installation and usage. Additional topics covered include relevancy ranking, tokenization, and advanced querying techniques.



























![Elasticsearch And Ruby [RuPy2012]](https://cdn.slidesharecdn.com/ss_thumbnails/elasticsearchandruby-karelminarik-rupy2012-121118065224-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

















































