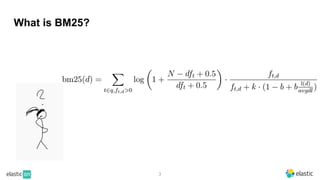
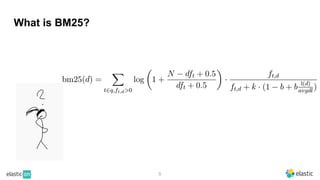
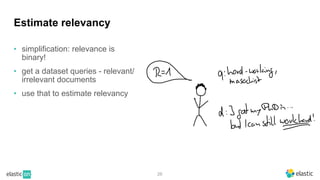
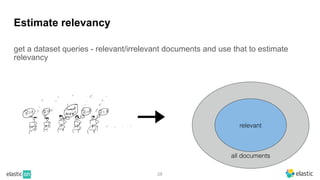
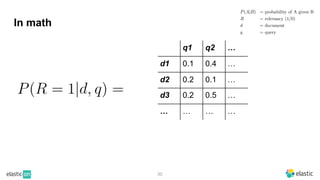
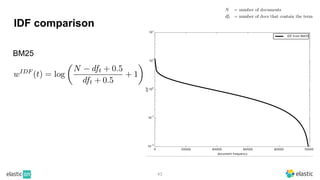
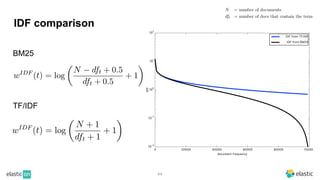
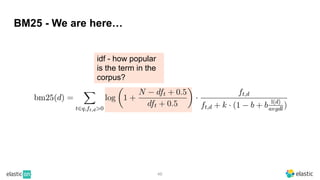
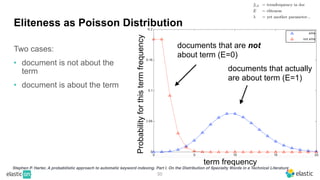
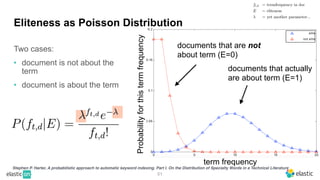
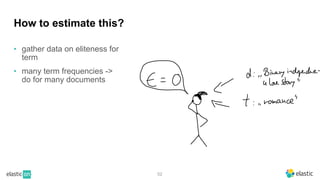
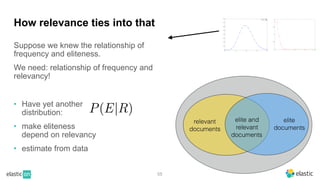
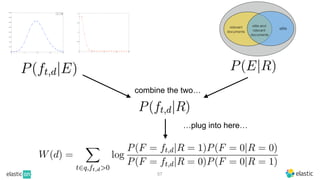
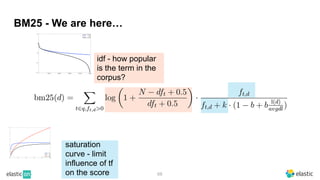
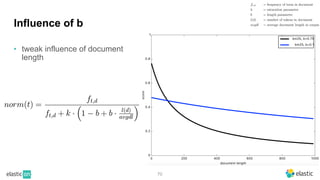
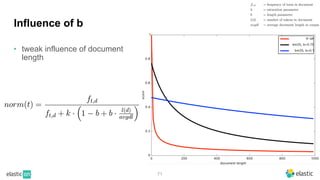
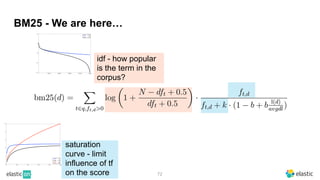
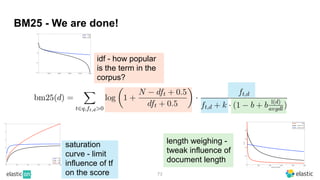
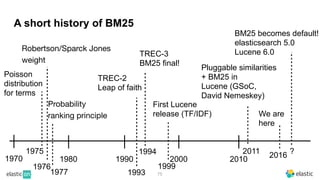
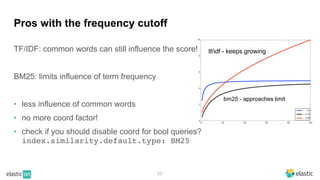
BM25 is a probabilistic scoring model used in information retrieval systems like search engines. It aims to estimate the probability of a document being relevant to a given search query by examining the terms in the document and query. BM25 improves on previous scoring models like TF-IDF by incorporating assumptions about how term frequencies are likely to vary between relevant and irrelevant documents based on the topic of the document. However, precisely estimating the parameters of the BM25 model requires data on term frequencies, document relevance, and other factors that is difficult to obtain in practice. As a result, BM25 involves approximations and "leaps of faith" in how it models these probabilities.




![Usually when you use elasticsearch
you will have clear search criteria
• categories
• timestamps
• age
• ids …
7
Searching in natural language text
"_source": {
"oder-nr": 1234,
"items": [3,5,7],
"price": 30.85,
"customer": "Jon Doe",
"date": "2015-01-01"
}](https://image.slidesharecdn.com/bm25final-230223071551-135e4051/85/bm25-demystified-7-320.jpg)
![Tweets mails, articles,… are fuzzy
• language is ambivalent, verbose
and many topics in one doc
• no clear way to formulate your
query
8
Searching in natural language text
"_source": {
"titles": "guru of everything",
"programming_languages": [
"java",
"python",
"FORTRAN"
],
"age": 32,
"name": "Jon Doe",
"date": "2015-01-01",
"self-description": "I am a
hard-working self-motivated expert
in everything. High performance is
not just an empty word for me..."
}](https://image.slidesharecdn.com/bm25final-230223071551-135e4051/85/bm25-demystified-8-320.jpg)
![9
A free text search is a very inaccurate description of
our information need
What you want:
• quick learner
• works hard
• reliable
• enduring
• …
"_source": {
"titles": "guru of everything",
"programming_languages": [
"java",
"python",
"FORTRAN"
],
"age": 32,
"name": "Jon Doe",
"date": "2015-01-01",
"self-description": "I am a
hard-working self-motivated expert
in everything. High performance is
not just an empty word for me..."
}](https://image.slidesharecdn.com/bm25final-230223071551-135e4051/85/bm25-demystified-9-320.jpg)
![10
A free text search is a very inaccurate description of
our information need
What you want:
• quick learner
• works hard
• reliable
• enduring
• …
But you type :
“hard-working, self-motivated, masochist”
"_source": {
"titles": "guru of everything",
"programming_languages": [
"java",
"python",
"FORTRAN"
],
"age": 32,
"name": "Jon Doe",
"date": "2015-01-01",
"self-description": "I am a
hard-working self-motivated expert
in everything. High performance is
not just an empty word for me..."
}](https://image.slidesharecdn.com/bm25final-230223071551-135e4051/85/bm25-demystified-10-320.jpg)




















































































![[Vancouver] part 2 understanding the relevance of your search with elasticse...](https://cdn.slidesharecdn.com/ss_thumbnails/vancouverpart2understandingtherelevanceofyoursearchwithelasticsearchandkibana-210218165954-thumbnail.jpg?width=640&height=640&fit=bounds)














