Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
TI
Uploaded by
Teppei Ishii
PDF, PPTX
8,638 views
Azure サポート チームの現場からお届けする落ちないサービスのために
Azure の VM は落ちる?受け入れがたい真実を知ることから始まる。Azure の様々なサービスを使い本当に落ちないサービスを目指すノウハウを説明します。
Software
◦
Related topics:
Cloud Computing Insights
•
Disaster Recovery Solutions
•
Read more
14
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 65
2
/ 65
3
/ 65
4
/ 65
5
/ 65
6
/ 65
7
/ 65
8
/ 65
Most read
9
/ 65
10
/ 65
11
/ 65
12
/ 65
13
/ 65
14
/ 65
15
/ 65
16
/ 65
17
/ 65
18
/ 65
19
/ 65
20
/ 65
21
/ 65
22
/ 65
23
/ 65
24
/ 65
25
/ 65
26
/ 65
27
/ 65
28
/ 65
29
/ 65
30
/ 65
31
/ 65
32
/ 65
33
/ 65
34
/ 65
35
/ 65
36
/ 65
37
/ 65
38
/ 65
39
/ 65
40
/ 65
41
/ 65
42
/ 65
43
/ 65
44
/ 65
45
/ 65
46
/ 65
47
/ 65
48
/ 65
49
/ 65
50
/ 65
51
/ 65
52
/ 65
53
/ 65
54
/ 65
55
/ 65
56
/ 65
57
/ 65
58
/ 65
59
/ 65
60
/ 65
61
/ 65
62
/ 65
63
/ 65
64
/ 65
65
/ 65
More Related Content
PDF
今改めて学ぶ Microsoft Azure 基礎知識
by
Minoru Naito
PPTX
Awsでのsql高可用構成 Always On
by
ShinodaYukihiro
PDF
Microsoft Azure Storage 概要
by
Takeshi Fukuhara
PPTX
Data Factory V2 新機能徹底活用入門
by
Keisuke Fujikawa
PDF
シンプルでシステマチックな Oracle Database, Exadata 性能分析
by
Yohei Azekatsu
PPTX
AlloyDBを触ってみた!(第33回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
Kubernetes 疲れに Azure Container Apps はいかがでしょうか?(江東区合同ライトニングトーク 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Sql server のバックアップとリストアの基礎
by
Masayuki Ozawa
今改めて学ぶ Microsoft Azure 基礎知識
by
Minoru Naito
Awsでのsql高可用構成 Always On
by
ShinodaYukihiro
Microsoft Azure Storage 概要
by
Takeshi Fukuhara
Data Factory V2 新機能徹底活用入門
by
Keisuke Fujikawa
シンプルでシステマチックな Oracle Database, Exadata 性能分析
by
Yohei Azekatsu
AlloyDBを触ってみた!(第33回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Kubernetes 疲れに Azure Container Apps はいかがでしょうか?(江東区合同ライトニングトーク 発表資料)
by
NTT DATA Technology & Innovation
Sql server のバックアップとリストアの基礎
by
Masayuki Ozawa
What's hot
PDF
【de:code 2020】 Azure Synapse Analytics 技術編 ~ 最新の統合分析プラットフォームによる新しい価値の創出(後編)
by
日本マイクロソフト株式会社
PDF
Azure App Service Overview
by
Takeshi Fukuhara
PDF
S04_Microsoft XDR によるセキュアなハイブリッドクラウド環境の実現 [Microsoft Japan Digital Days]
by
日本マイクロソフト株式会社
PDF
【de:code 2020】 Azure Synapse Analytics 技術編 ~ 最新の統合分析プラットフォームによる新しい価値の創出(前編)
by
日本マイクロソフト株式会社
PDF
Azure Data Box Family Overview and Microsoft Intelligent Edge Strategy
by
Takeshi Fukuhara
PPTX
サポート エンジニアが語る、トラブルを未然に防ぐための Azure インフラ設計
by
ShuheiUda
PPTX
BigData Architecture for Azure
by
Ryoma Nagata
PPTX
Oracleからamazon auroraへの移行にむけて
by
Yoichi Sai
PPTX
Azure AD とアプリケーションを SAML 連携する際に陥る事例と対処方法について
by
Shinya Yamaguchi
PPTX
JAZUG12周年 俺の Azure Cosmos DB
by
Daiyu Hatakeyama
PPTX
Azure Service Fabric 概要
by
Daiyu Hatakeyama
PDF
【de:code 2020】 今すぐはじめたい SQL Database のかしこい使い分け術 後編
by
日本マイクロソフト株式会社
PDF
現場からみた Azure リファレンスアーキテクチャ答え合わせ
by
Kuniteru Asami
PDF
Insight into Azure Active Directory #02 - Azure AD B2B Collaboration New Feat...
by
Kazuki Takai
PPTX
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス...
by
NTT DATA Technology & Innovation
PDF
Oracle GoldenGate入門
by
オラクルエンジニア通信
PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PPTX
AKS と ACI を組み合わせて使ってみた
by
Hideaki Aoyagi
PPTX
PostgreSQLの統計情報について(第26回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
超実践 Cloud Spanner 設計講座
by
Samir Hammoudi
【de:code 2020】 Azure Synapse Analytics 技術編 ~ 最新の統合分析プラットフォームによる新しい価値の創出(後編)
by
日本マイクロソフト株式会社
Azure App Service Overview
by
Takeshi Fukuhara
S04_Microsoft XDR によるセキュアなハイブリッドクラウド環境の実現 [Microsoft Japan Digital Days]
by
日本マイクロソフト株式会社
【de:code 2020】 Azure Synapse Analytics 技術編 ~ 最新の統合分析プラットフォームによる新しい価値の創出(前編)
by
日本マイクロソフト株式会社
Azure Data Box Family Overview and Microsoft Intelligent Edge Strategy
by
Takeshi Fukuhara
サポート エンジニアが語る、トラブルを未然に防ぐための Azure インフラ設計
by
ShuheiUda
BigData Architecture for Azure
by
Ryoma Nagata
Oracleからamazon auroraへの移行にむけて
by
Yoichi Sai
Azure AD とアプリケーションを SAML 連携する際に陥る事例と対処方法について
by
Shinya Yamaguchi
JAZUG12周年 俺の Azure Cosmos DB
by
Daiyu Hatakeyama
Azure Service Fabric 概要
by
Daiyu Hatakeyama
【de:code 2020】 今すぐはじめたい SQL Database のかしこい使い分け術 後編
by
日本マイクロソフト株式会社
現場からみた Azure リファレンスアーキテクチャ答え合わせ
by
Kuniteru Asami
Insight into Azure Active Directory #02 - Azure AD B2B Collaboration New Feat...
by
Kazuki Takai
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス...
by
NTT DATA Technology & Innovation
Oracle GoldenGate入門
by
オラクルエンジニア通信
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
AKS と ACI を組み合わせて使ってみた
by
Hideaki Aoyagi
PostgreSQLの統計情報について(第26回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
超実践 Cloud Spanner 設計講座
by
Samir Hammoudi
Similar to Azure サポート チームの現場からお届けする落ちないサービスのために
PDF
Azure reliability v0.2.21.0630
by
Ayumu Inaba
PDF
今こそ知りたい!Microsoft Azureの基礎
by
Trainocate Japan, Ltd.
PPTX
サポート エンジニアが語る、Microsoft Azure を支えるインフラの秘密
by
ShuheiUda
PPTX
Azure 仮想マシンにおける運用管理・高可用性設計のベストプラクティス
by
Yusuke Oi
PDF
帰ってきた インフラ野郎 Azureチーム ~Azure データセンターテクノロジー解体新書2018春~ - de:code2018
by
Toru Makabe
PDF
SAP on Azure Cloud Workshop Material Japanese 20190221
by
Hitoshi Ikemoto
PPTX
Azure vm の可用性を見直そう
by
ShuheiUda
PPTX
Azure 運用管理入門 ~ クラウドを安全・安心に使うために
by
Yusuke Oi
PPTX
Azureの運用に欠かせないサービスたち一挙解説
by
Shingo Kawahara
PPTX
99999999 azure iaas_newportal版
by
Osamu Takazoe
PPTX
[簡易提案書]Azure overview 2017_april_v1.00
by
Toshihiko Sawaki
PPTX
[簡易提案書]Azure overview 2017_sep_v0.9
by
Toshihiko Sawaki
PDF
[Japan Tech summit 2017] CLD 016
by
Microsoft Tech Summit 2017
PDF
20180918_ops on azure-main
by
Jun Misawa
PDF
Azure保護の必要性とそのリスク、『Veeam』で保護する理由とは
by
株式会社クライム
PDF
Azure reliability v0.1.21.0422
by
Ayumu Inaba
PDF
Azure IaaS update (2018年6月~8月 発表版)
by
Takamasa Maejima
PDF
[CTO Night & Day 2019] 高可用性アーキテクチャについて考える #ctonight
by
Amazon Web Services Japan
PDF
Enterprise Cloud Design Pattern 前編:クラウドアーキテクチャ-の3要素
by
Arichika TANIGUCHI
PPTX
Real World Cloud Architectures ~CDPの概念と実装~
by
statemachine
Azure reliability v0.2.21.0630
by
Ayumu Inaba
今こそ知りたい!Microsoft Azureの基礎
by
Trainocate Japan, Ltd.
サポート エンジニアが語る、Microsoft Azure を支えるインフラの秘密
by
ShuheiUda
Azure 仮想マシンにおける運用管理・高可用性設計のベストプラクティス
by
Yusuke Oi
帰ってきた インフラ野郎 Azureチーム ~Azure データセンターテクノロジー解体新書2018春~ - de:code2018
by
Toru Makabe
SAP on Azure Cloud Workshop Material Japanese 20190221
by
Hitoshi Ikemoto
Azure vm の可用性を見直そう
by
ShuheiUda
Azure 運用管理入門 ~ クラウドを安全・安心に使うために
by
Yusuke Oi
Azureの運用に欠かせないサービスたち一挙解説
by
Shingo Kawahara
99999999 azure iaas_newportal版
by
Osamu Takazoe
[簡易提案書]Azure overview 2017_april_v1.00
by
Toshihiko Sawaki
[簡易提案書]Azure overview 2017_sep_v0.9
by
Toshihiko Sawaki
[Japan Tech summit 2017] CLD 016
by
Microsoft Tech Summit 2017
20180918_ops on azure-main
by
Jun Misawa
Azure保護の必要性とそのリスク、『Veeam』で保護する理由とは
by
株式会社クライム
Azure reliability v0.1.21.0422
by
Ayumu Inaba
Azure IaaS update (2018年6月~8月 発表版)
by
Takamasa Maejima
[CTO Night & Day 2019] 高可用性アーキテクチャについて考える #ctonight
by
Amazon Web Services Japan
Enterprise Cloud Design Pattern 前編:クラウドアーキテクチャ-の3要素
by
Arichika TANIGUCHI
Real World Cloud Architectures ~CDPの概念と実装~
by
statemachine
Azure サポート チームの現場からお届けする落ちないサービスのために
3.
「バグが生まれないように頑張ります」 「壊れないハードウェアを作ります」 「ミスをしないように頑張ります」
4.
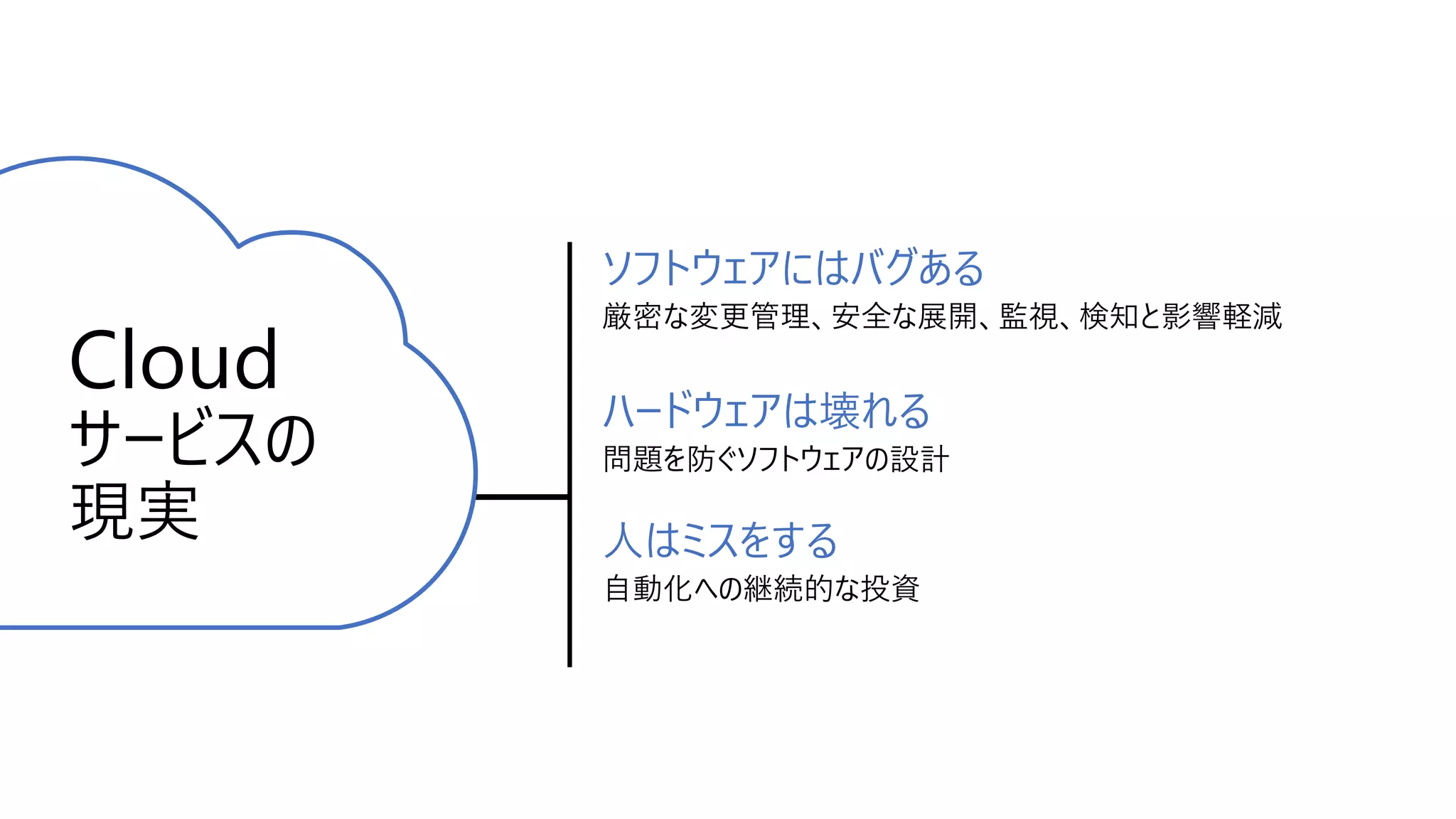
ソフトウェアにはバグある 厳密な変更管理、安全な展開、監視、検知と影響軽減 ハードウェアは壊れる 問題を防ぐソフトウェアの設計 人はミスをする 自動化への継続的な投資 Cloud サービスの 現実
5.
「バグがある前提でシステムを構成する」 「壊れる前提でシステムを構成する」 「ミスが発生する前提でシステムを構成する」
6.
では今の Azure でのソリューションは何か
7.
◇高可用性 (High Availability) ハードウェアやソフトウェアでトラブルが発生しても 業務を継続できるようにする ◇バックアップ データが消失または破損したとき、それを復旧できるようにする ◇災害対策
(Disaster Recovery) 大規模災害でデーターセンターが稼働できなくなったとき 早期に業務を再開できるようにする 高可用性・バックアップ・災害対策 の違い
8.
これらを理解しないことで生じる悲劇 リストアしても丸1日かかりますが・・・ 壊れるとは聞いていなかった(怒) 誰が直すんだ!? 夜間の障害で災対フェールオーバーすべきか判断できず・・・
11.
仮想マシンはそれ自体が高可用性 ある程度は
12.
12
13.
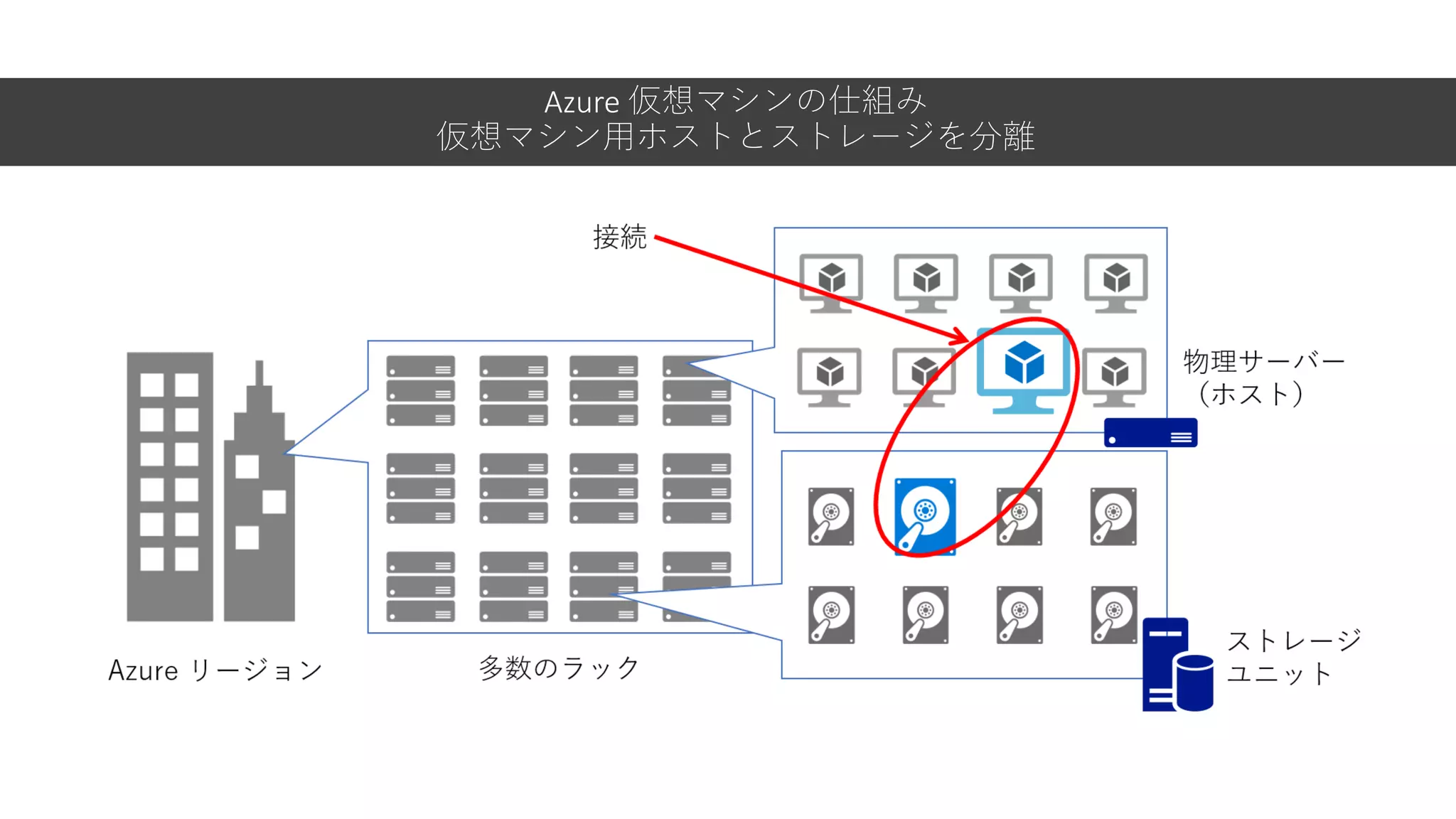
Azure 仮想マシンの仕組み 仮想マシン用ホストとストレージを分離
14.
物理マシンは使い捨て – ホスト障害の例
15.
ストレージは標準で三重化
16.
ホストが故障した場合
17.
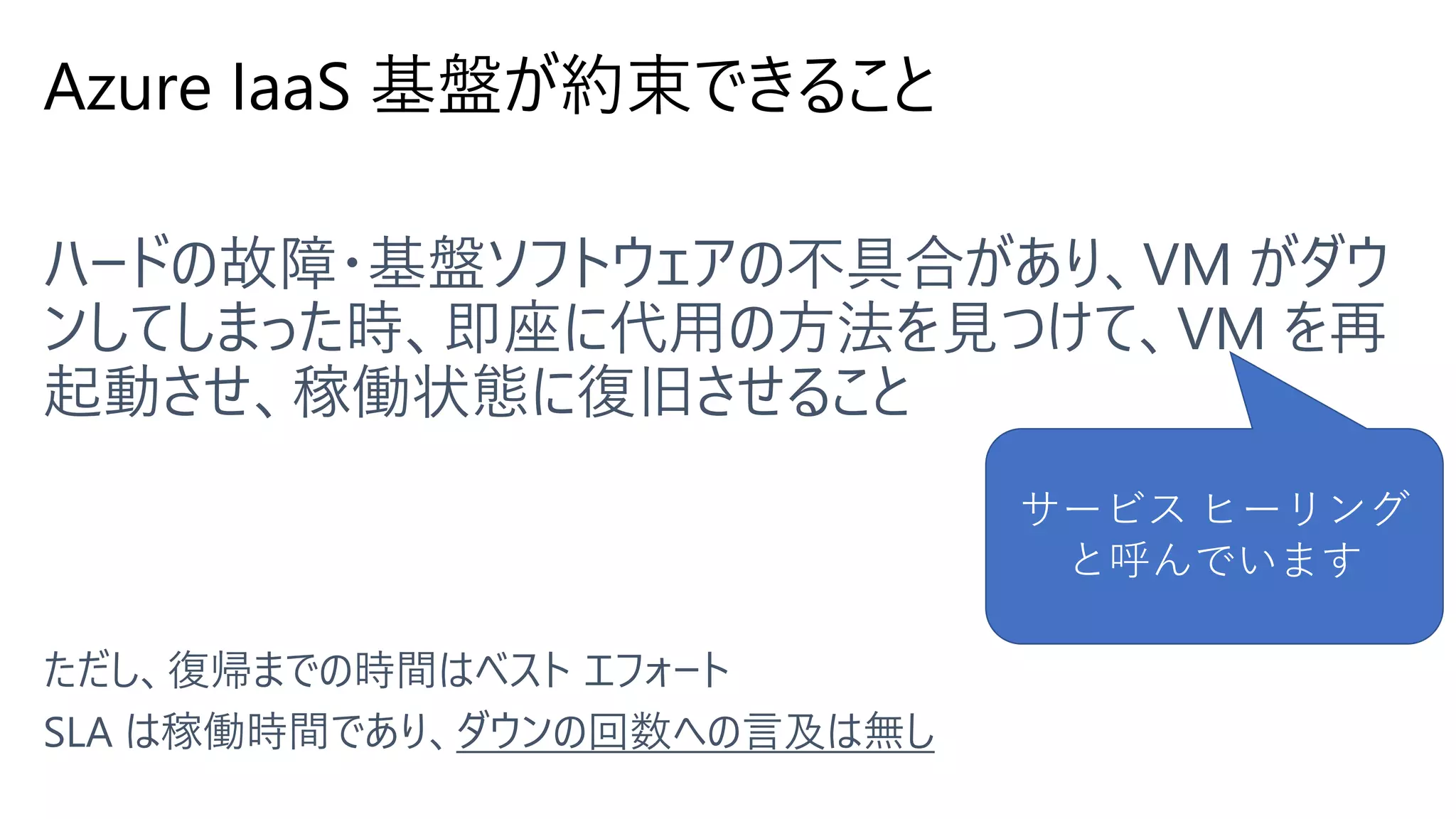
Azure IaaS 基盤が約束できること サービス
ヒーリング と呼んでいます
18.
突然のVMダウンで困ること
19.
ユーザーができること
20.
お客様「Azure の基盤の不具合に対応するためだけにコストがかかるの は嫌だ」 システムが止まる理由は 基盤側だけでは無いんです!!
21.
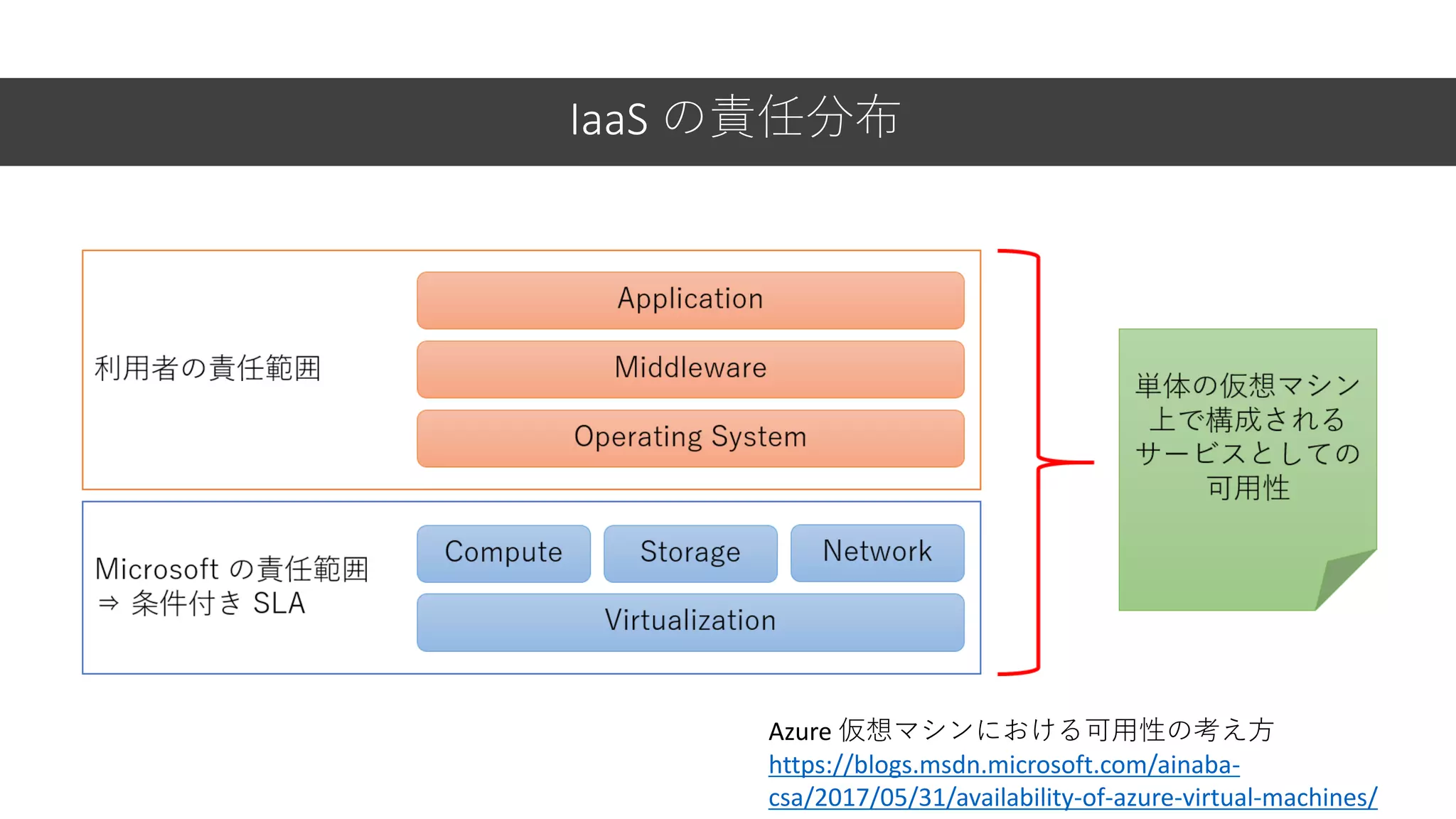
IaaS の責任分布 Azure 仮想マシンにおける可用性の考え方 https://blogs.msdn.microsoft.com/ainaba- csa/2017/05/31/availability-of-azure-virtual-machines/
22.
IaaS の責任分布 どの部分が落ちてもシステムは 止まる! Azure 仮想マシンにおける可用性の考え方 https://blogs.msdn.microsoft.com/ainaba- csa/2017/05/31/availability-of-azure-virtual-machines/
23.
放っておいても動き続けるというのは神話
24.
仮想マシンやサービスが止まる理由 ※ “想定外” ではない!
25.
余談ですが、ここで再起動に慣れてしまっては? https://www.slideshare.net/ToruMakabe/ss-74056379
26.
Azure Virtual Machine
の SLA
27.
よくある誤解 A. それって SLA
100% ですよねえ 事実: VM はいつ落ちるかわからない
28.
Azure の可用性セット +
管理ディスクを使う
29.
可用性セット・可用性ゾーン + 管理ディスク 構成自体は比較的簡単 リージョンの大規模障害に弱い アプリケーションが対応していなければならない 構成は可用性セットと似たレベルで簡単 リージョンの大規模障害にも強い 自然災害
(地震)など、リージョン全体が脅かされる場合はダウンに繋がる
31.
複数の VM で高可用構成を 高可用性のロール 可用性セットを構成したデザインパターン
32.
可用性セットの注意点 https://blogs.msdn.microsoft.com/ainaba-csa/2017/05/31/availability-of-azure- virtual-machines/
33.
Azure の可用性セット +
管理ディスクを使う
34.
いざという時に頼りになる「管理ディスク」とは
35.
Azure 仮想マシンの仕組み 仮想マシン用ホストとストレージを分離 ストレージの障害はスケールユニット単位で起きる
36.
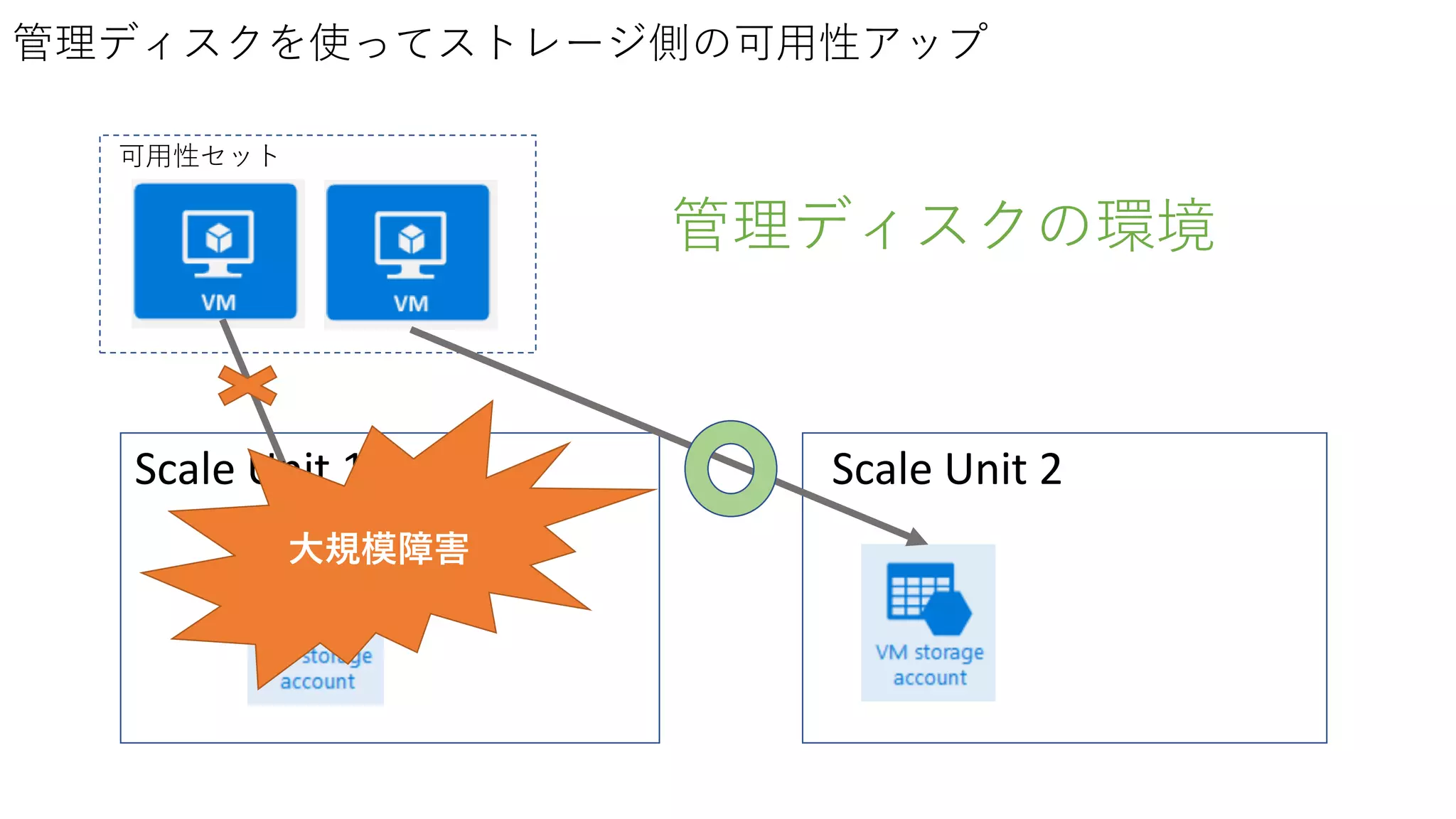
Scale Unit 2 可用性セット 管理ディスクを使ってストレージ側の可用性アップ Scale
Unit 1 管理ディスク無しの環境
37.
Scale Unit 2 可用性セット 管理ディスクを使ってストレージ側の可用性アップ Scale
Unit 1 管理ディスク無しの環境 大規模障害
38.
Scale Unit 2 可用性セット 管理ディスクを使ってストレージ側の可用性アップ Scale
Unit 1 管理ディスクの環境
39.
Scale Unit 2 可用性セット 管理ディスクを使ってストレージ側の可用性アップ Scale
Unit 1 管理ディスクの環境 大規模障害
40.
Scale Unit 2 可用性セット 可用性ゾーンで建屋が別れる
(近い将来に実装予定) Scale Unit 1 ゾーン1 ゾーン2
41.
高可用性 <マイクロソフトとユーザー>
43.
よくある誤解 「データ プライバシー、お客様のデータはお客様が管理する」 無断で Azure
側からお客様のバックアップを複製するということはない。 お客様が複製していないデータは複製されていないし、消したデータはすぐに消されることを保証する。 消えた・壊れたデータは戻らない。
44.
泣き寝入りをしないためにバックアップを
45.
Azure Backup 設定が簡単 VM が稼働状態のままバックアップ可能 「過去の正常な時点」に戻す事ができる唯一の方法 バックアップ・リストアともに時間がかかる RA-GRS
に非対応であるため、Azure Backup の保存先に障害が起き たときに即時のリストアができない
47.
アプリケーション別のバックアップも捨てたものではない アプリケーションのバックアップは任意のタイミングで行える。 任意の場所に保存できる。(別リージョンも選択肢)
48.
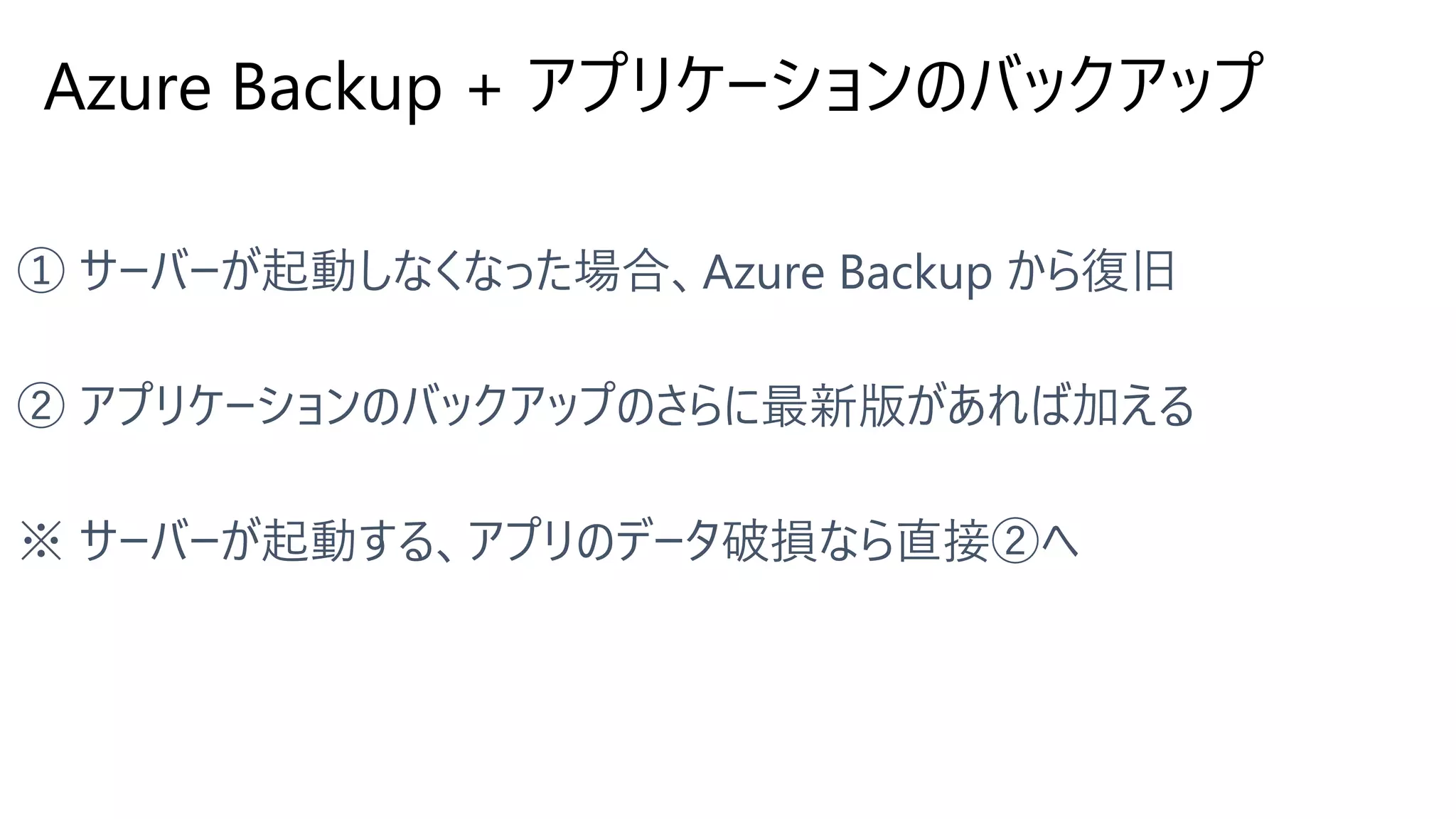
Azure Backup +
アプリケーションのバックアップ
49.
バックアップ <マイクロソフトとユーザー>
51.
大規模障害は何故おきるか
52.
大規模障害を想定した構成
53.
Azure Site Recovery
(Azure to Azure) 設定が簡単、フェールオーバーも高速 直近複数世代の確保が行える
56.
ストレージ GRS/RA-GRS 設定が簡単、メンテナンス不要 VM のディスク、つまり
VHD には向いていない フェールオーバーのタイミングは自分で決められない
57.
GRS で注意すべきこと ① VM
の VHD (ディスク) の複製には不向き。 GRS はストレージ上のデータのバックアップに過ぎず、秒間何回も変更されている VHD のどこからどこまでが複製されて いるのか全く分からない。書き込み途中で障害がおきた時点のデータは破損している可能性が・・・ VM の複製には必ず Site Recovery を使う。 ② GRS のフェールオーバーはお客様のタイミングでは決められない。 障害の状況によっては何日も判断されない場合も・・・ ストレージサービスの地理冗長 (GRS) の障害時の挙動について https://blogs.technet.microsoft.com/jpaztech/2016/08/09/storage-service-grs-failover/ → 過信は禁物、保険的な考えとしておくことがベター
59.
自前でリージョン冗長を構成 RTO/RPO の定義についてお客様がコントロール可能 お客様のタイミングでフェールオーバーが可能 場合によるがハイコスト アプリケーション自体が複製やフェールオーバーに対応している必要がある
60.
災対のフローを確立しておく!
61.
PaaS を利用する
62.
IaaS か PaaS
か
63.
災害対策のまとめ
64.
まとめ: スケール別のソリューション シングル VM クラスタ構成 マルチリージョン構成 マルチ
AZ 構成 Azure VM の Service Healing ストレージ + Azure Backup 可用性セット 各種 PaaS 化 ペアリージョン Traffic Manager Site Recovery ストレージ GRS 可用性ゾーン Geo Region Primary Region Secondary Region
65.
冗長化構成 可用性セット Azure Backup Azure Site
Recovery まとめ: Azure を安心・安全に使うために
Download



































































![S04_Microsoft XDR によるセキュアなハイブリッドクラウド環境の実現 [Microsoft Japan Digital Days]](https://cdn.slidesharecdn.com/ss_thumbnails/s04microsoftxdr-211028134250-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[簡易提案書]Azure overview 2017_april_v1.00](https://cdn.slidesharecdn.com/ss_thumbnails/azureoverview2017aprilv1-170528100957-thumbnail.jpg?width=640&height=640&fit=bounds)
![[簡易提案書]Azure overview 2017_sep_v0.9](https://cdn.slidesharecdn.com/ss_thumbnails/azureoverview2017sepv0-170904135653-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Japan Tech summit 2017] CLD 016](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfcld016-171115032128-thumbnail.jpg?width=640&height=640&fit=bounds)




![[CTO Night & Day 2019] 高可用性アーキテクチャについて考える #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessionhaonaws-191027185900-thumbnail.jpg?width=640&height=640&fit=bounds)

