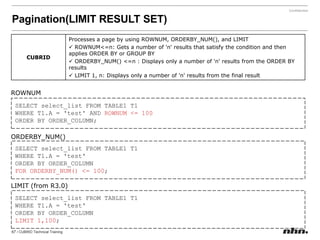
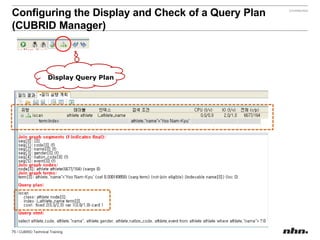
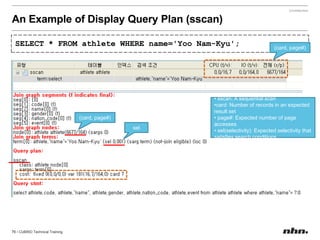
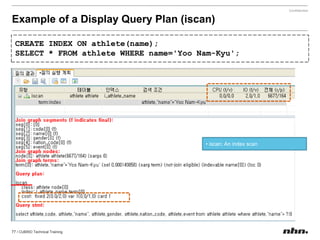
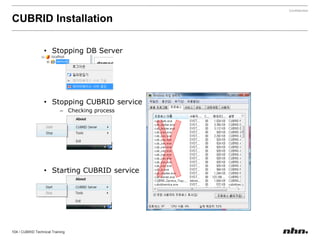
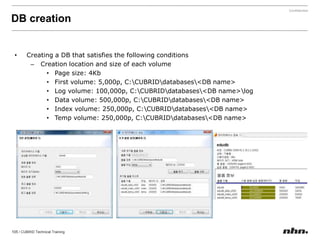
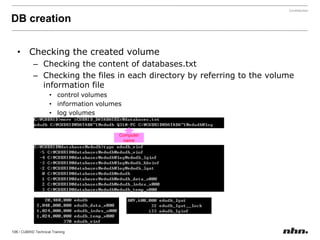
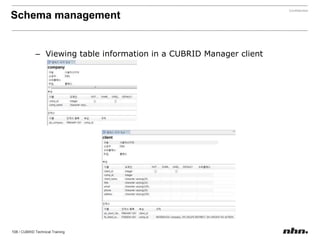
Downloaded 79 times



























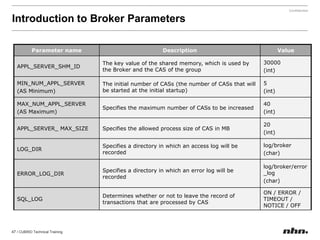




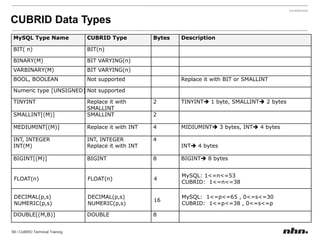













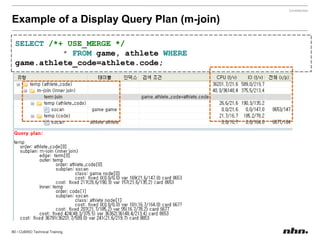






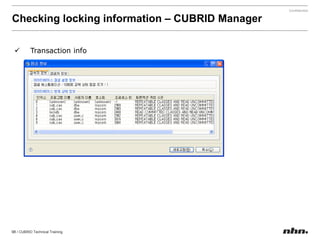
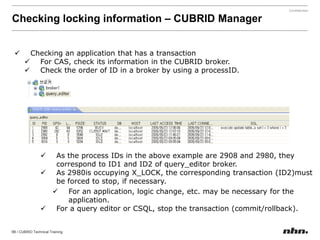


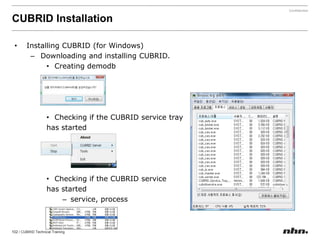
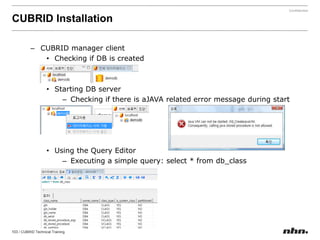


![If the value of a parameter is a string, insertthe string without quotation marks. If a blank character is included in the string, encase it with quotation marks. [commom]data_buffer_pages=250000[demodb]data_buffer_pages=500000](https://image.slidesharecdn.com/ee-1012-cubridadvanceeduv1-101223030601-phpapp02/85/CUBRID-Developer-s-Course-110-320.jpg)



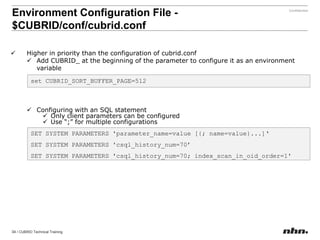
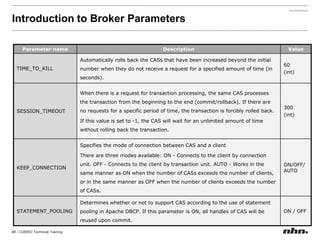
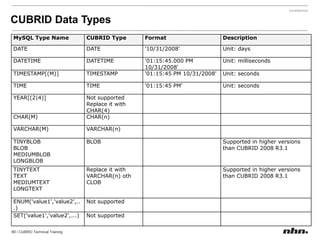
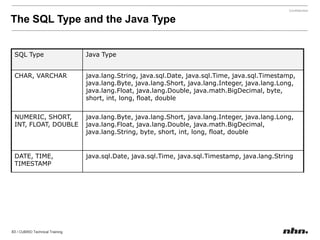
![Use “;” for multiple configurationsEnvironment Configuration File- $CUBRID/conf/cubrid.confset CUBRID_SORT_BUFFER_PAGE=512SET SYSTEM PARAMETERS 'parameter_name=value [{; name=value}...]‘SET SYSTEM PARAMETERS 'csql_history_num=70’SET SYSTEM PARAMETERS 'csql_history_num=70; index_scan_in_oid_order=1'](https://image.slidesharecdn.com/ee-1012-cubridadvanceeduv1-101223030601-phpapp02/85/CUBRID-Developer-s-Course-115-320.jpg)






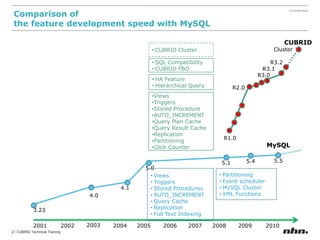
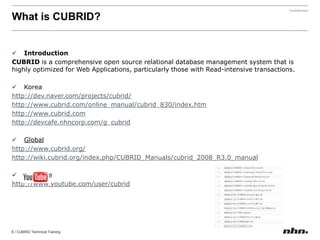
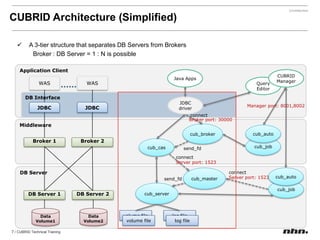
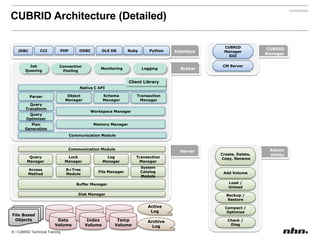
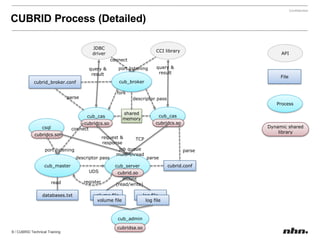
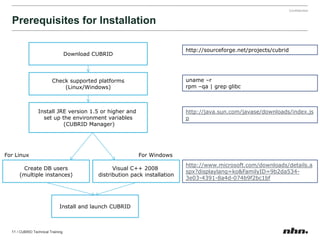
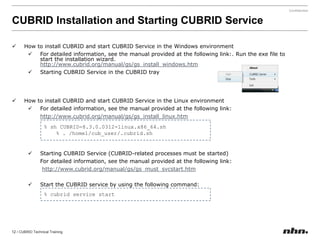
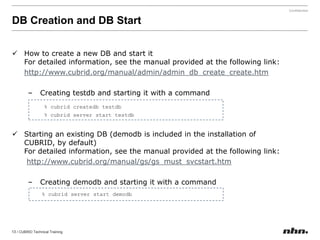
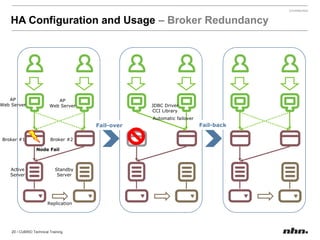
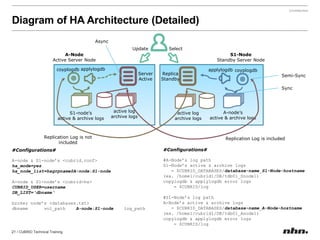
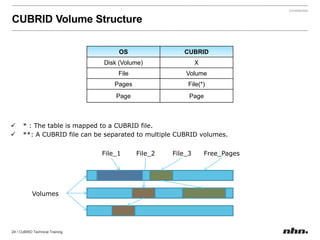
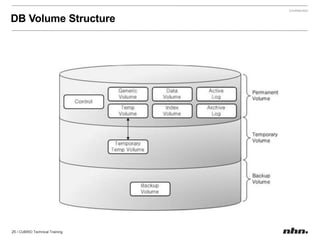
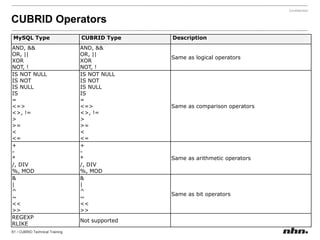
Cubrid is an open-source relational database management system optimized for web applications with a focus on read-intensive transactions. The document provides extensive information on its architecture, installation, high availability configurations, and features compared to MySQL, including database volume structures and management parameters. Users can find links to additional resources, installation manuals, and the requirements for configuring Cubrid services on various platforms.







![[db tech showcase Tokyo 2014] B15: Scalability with MariaDB and MaxScale by ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b15mariadbcorporationcolincharlesscalabilitywithmariadbandmaxscale-141208020836-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)















































