Downloaded 42 times







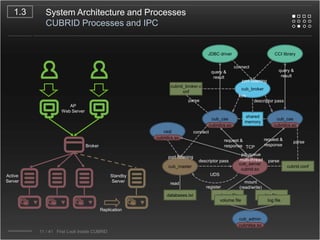
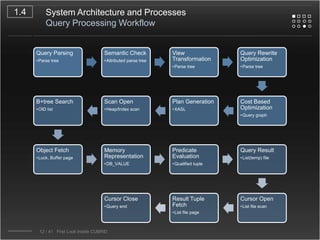
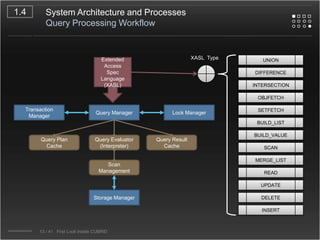

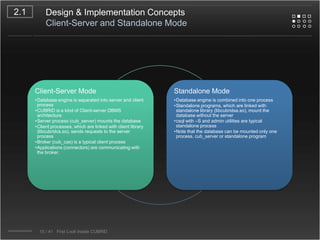

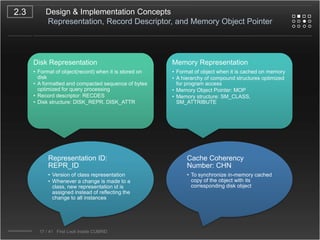
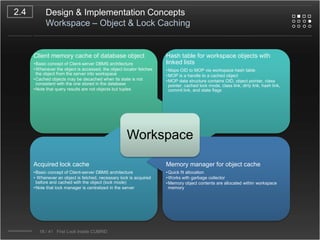

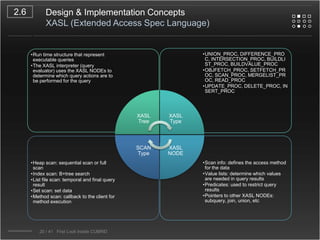
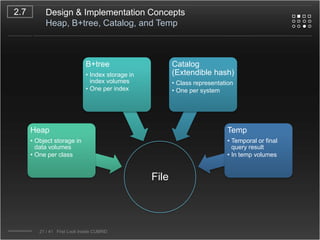
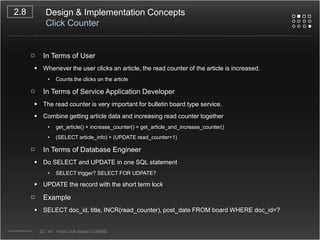
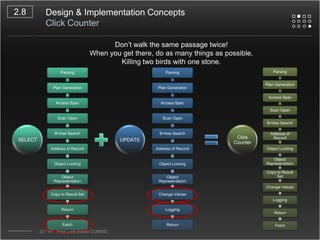

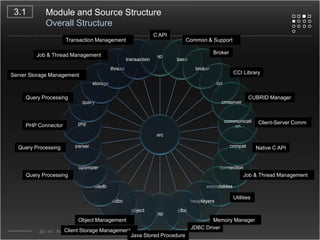
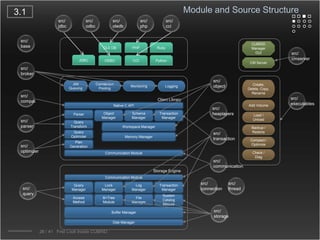

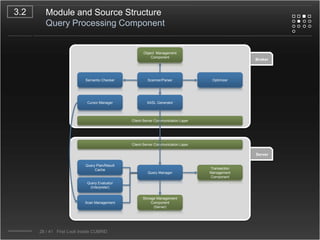

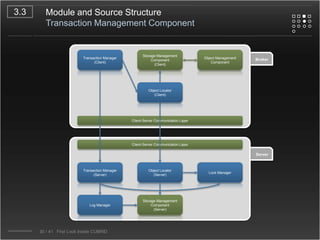

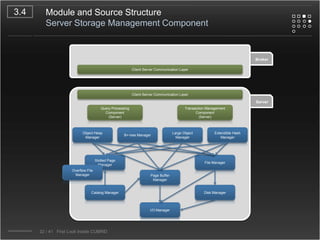

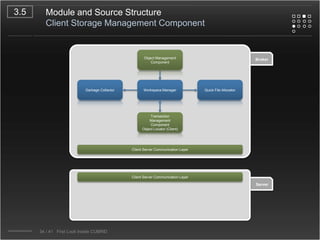

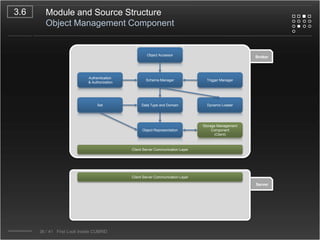






CUBRID is an open-source relational database management system designed for internet portal services, offering features like a multi-threaded architecture, various APIs, and a graphical interface for management. The document details CUBRID's system architecture, including its server, client, and broker subsystems, as well as its processes for query handling and transaction management. It also emphasizes the importance of following Creative Commons attribution and licensing conditions when reusing or modifying the work.








![[2A5]하둡 보안 어떻게 해야 할까](https://cdn.slidesharecdn.com/ss_thumbnails/2a5-140929211558-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































































