Download to read offline








![19
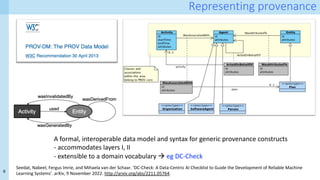
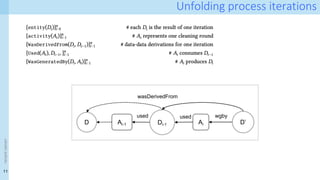
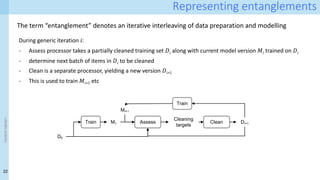
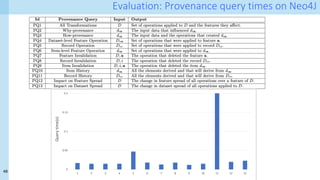
Provenance layer I specification
xnj xi
j
CS
wasGeneratedBy
used
C
wasAssociatedWith
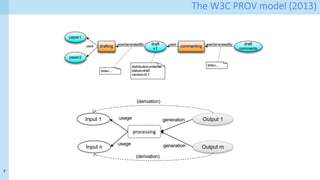
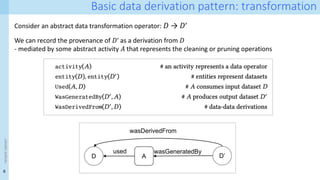
wasDerivedFrom
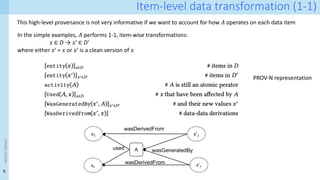
entity(D_noisy, [ prov:type=”training-set’])
entity(D_clean, [ prov:type=”training-set’])
entity(e1, [ prov:type=”training-data”, inSet=‘D_noisy’, index=j, val=V])
entity(e2, [ prov:type=”training-data”, inset=‘D_clean, index=j, val=W])
entity(C, [ prov:type=”prov:agent”, prov:type=“CS-creator”])
activity(CS, [ prov:type=”cleaning-strategy”, version=”v1.0”, desc=‘…’])
wasDerivedFrom(e2, e1)
used(CS,e1)
wasGeneratedBy(e2, CS)
wasAssociatedWith(CS,C)
IDEAL
2023
Surface representation: PROV-N
Internal representation:
Property-value graphs! Hint:
Neo4J works well…](https://image.slidesharecdn.com/dcai-dpds-240416172712-c65ba97e/85/Towards-explanations-for-Data-Centric-AI-using-provenance-records-19-320.jpg)

![24
Use case 2: training set optimisation
Motivation: training efficiency
à model performance (test loss) correlates with training data size D according to a power law [11]
However, “Since scalings with N (model size), D (training tokens), Cmin (compute budget) are power-laws,
there are diminishing returns with increasing scale.” [11]
[11] J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language
models. arXiv preprint arXiv:2001.08361, 2020.
This motivates trying to optimize D:
1- Redundancy in D leads to wasted training time
2- Not all training examples are equally important for
training:
Ø which ones should be kept / removed?
IDEAL
2023](https://image.slidesharecdn.com/dcai-dpds-240416172712-c65ba97e/85/Towards-explanations-for-Data-Centric-AI-using-provenance-records-24-320.jpg)
![25
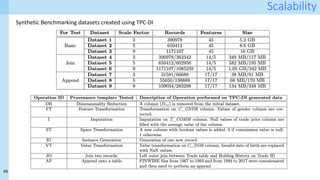
Training set optimization Task 1: reducing redundancy
[12] Abbas, Amro, Kushal Tirumala, Dániel Simig, Surya Ganguli, and Ari S. Morcos. ‘SemDeDup: Data-Efficient Learning at Web-Scale through
Semantic Deduplication’. arXiv, 22 March 2023. http://arxiv.org/abs/2303.09540.
Approach [12]:
1. Map the training set D to an embedded space – using pre-trained foundation models
2. Cluster all data points in embedded space using k-means
3. Using cosine similarity, identify similar points within each cluster. Threshold and select
IDEAL
2023](https://image.slidesharecdn.com/dcai-dpds-240416172712-c65ba97e/85/Towards-explanations-for-Data-Centric-AI-using-provenance-records-25-320.jpg)
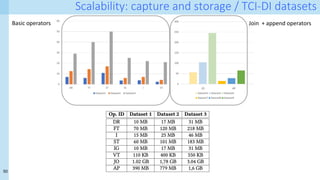
![26
Training set optimization Task 2: pruning easy/hard examples
Main findings from [13]:
1. Not all training examples are created equal
• Hard vs easy
2. The best pruning strategy depends on the
amount of initial data
• Small TS à keep the easy examples
• Large TS à keep the hard examples
[13] Sorscher, Ben, et al. Beyond neural scaling laws: beating power law scaling via data pruning, Advances in Neural Information Processing
Systems 35 (2022): 19523-19536.
Repr from [13]
A real simple pruning method – very similar to Task 1
"To compute a self-supervised pruning metric for ImageNet, we perform k-means clustering
in the embedding space of an ImageNet pre-trained self-supervised model and define the
difficulty of each data point by the Euclidean distance to its nearest cluster centroid, or
prototype"
Caveat: only tested on ImageNet!
IDEAL
2023](https://image.slidesharecdn.com/dcai-dpds-240416172712-c65ba97e/85/Towards-explanations-for-Data-Centric-AI-using-provenance-records-26-320.jpg)

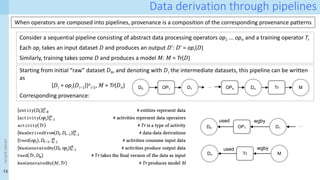
![29
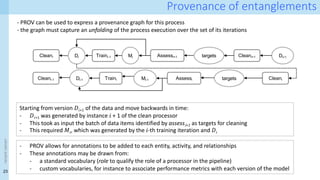
How can we generate these provenance graphs?
Key idea for Layer II (data-granular): Interpreter-level observer
- Requires observer at the boundaries of CS, i.e. to tell which x.label have changed
- Observer has access to individual dataframe elements
- But it is unaware of data transformation semantics
[14] A. Chapman, P. Missier, G. Simonelli, and R. Torlone. 2020. Capturing and querying fine-grained provenance of preprocessing
pipelines in data science. Proc. VLDB Endow. 14, 4 (December 2020), 507–520. https://doi.org/10.14778/3436905.3436911
[15] A. Chapman, L. Lauro, P. Missier, and R. Torlone. 2022. DPDS: assisting data science with data provenance. Proc. VLDB Endow. 15, 12
(2022), 3614–3617. https://doi.org/10.14778/3554821.3554857
Adriane Chapman, Luca Lauro, Paolo Missier, and Riccardo Torlone. 2024. Supporting Better Insights of Data Science Pipelines with Fine-
grained Provenance. ACM Trans. Database Syst. Just Accepted (February 2024). https://doi.org/10.1145/3644385
xnj xi
j
CSi
wasGeneratedBy
used
C
wasAssociatedWith
wasDerivedFrom
A starting point:
Data Provenance for Data Science (DPDS)
IDEAL
2023](https://image.slidesharecdn.com/dcai-dpds-240416172712-c65ba97e/85/Towards-explanations-for-Data-Centric-AI-using-provenance-records-29-320.jpg)
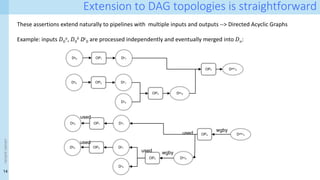
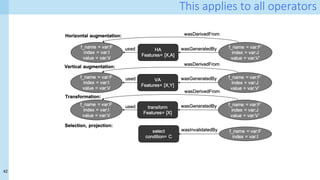
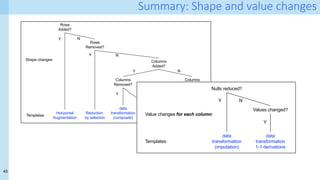
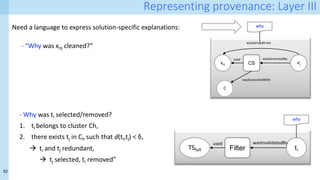
![31
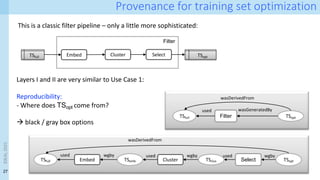
Running example: A simple pipeline
D1 D2 D3
Add
‘E4,’ ‘Ex’, ‘E1’
Remove ‘E’
D4 D6
Da
Db
Left join
(K1,K2)
Impute
all missing
Dc
Left join
(K1,K2)
Impute E,F
D5
One-hot encoding
df = pd.merge(df_A, df_B, on=['key1', 'key2'], how='left’) # join
df = df.fillna('imputed’) # Imputation
df = pd.merge(df, df_C, on=['key1', 'key2'], how='left’) #join
df = df.fillna(value={'E':'Ex', 'F':'Fx’}) # Imputation
# one-hot encoding
c = 'E'
dummies = []
dummies.append(pd.get_dummies(df[c]))
df_dummies = pd.concat(dummies, axis=1)
df = pd.concat((df, df_dummies), axis=1)
df = df_A.drop([c], axis=1)](https://image.slidesharecdn.com/dcai-dpds-240416172712-c65ba97e/85/Towards-explanations-for-Data-Centric-AI-using-provenance-records-31-320.jpg)




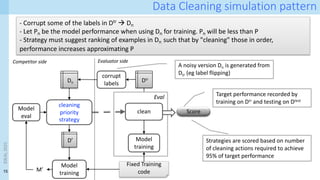
![39
Data fusion: join and append
<latexit sha1_base64="uo1XC2O2rrqRH/7jgx2X/lPakP4=">AAADKHicbZLNbtNAFIUn5q+Ev5Qu2YyIkFhFNqoKy6rtggWLgkhbKXai68k4HjKesWbuNESWn4Ut8DTsULe8BxLjNALi9EqWju75rmd8fdJSCotheNUJbt2+c/fezv3ug4ePHj/p7T49s9oZxodMS20uUrBcCsWHKFDyi9JwKFLJz9P5ceOfX3JjhVYfcVnypICZEplggL416e2djN/R+JMWaoyT6rimJ+MPk14/HISrotsiWos+WdfpZLfzO55q5gqukEmwdhSFJSYVGBRM8robO8tLYHOY8ZGXCgpuk2p1+5q+8J0pzbTxj0K66v4/UUFh7bJIPVkA5rbtNc2bvJHD7E1SCVU65IpdH5Q5SVHTZhV0KgxnKJdeADPC35WyHAww9AvbOCXVeo6Q2rrbjRVfMF0UoKZVrHVdxcg/Y5pVuq43zQzrUZRUf4F+VG8h/8ah7enSm1xZZ3jzaTROM6pbTK4NuJnnQJY5jKvYiFmOYIxetF/nQ7CJ+r1J6X/bQt3IN5HwdKoXKHjLc8pnx5uulK7ZiQ9M1I7Htjh7NYgOBvvv9/uHR+vo7JBn5Dl5SSLymhySt+SUDAkjS/KFfCXfgu/Bj+BncHWNBp31zB7ZqODXH8rzDh4=</latexit>
DL
./t
C DR
<latexit sha1_base64="fiWoK5ivN8nYSDBQRhG2qdf4NTc=">AAADIXicbZJNbxMxEIad5auErxaOXCwiJE7RLqoKxwp64MChINJWym6qsePNmnjtlT0mRKv9H1yBX8MNcUP8FiS8aQRk05EsvZr3GX+Mh1VKOozjn73oytVr12/s3Ozfun3n7r3dvfsnznjLxYgbZewZAyeU1GKEEpU4q6yAkilxyuYvW//0g7BOGv0Ol5XISphpmUsOGFKTo8lrmnodJD2avD3fHcTDeBV0WyRrMSDrOD7f6/1Op4b7UmjkCpwbJ3GFWQ0WJVei6afeiQr4HGZiHKSGUrisXl27oY9DZkpzY8PSSFfZ/ytqKJ1bliyQJWDhul6bvMwbe8yfZ7XUlUeh+cVBuVcUDW17QKfSCo5qGQRwK8NdKS/AAsfQqY1TmDFzBOaafj/VYsFNWYKe1qkxTZ2i+Igsr03TbJo5NuMkq/8Cg6TZQv6VQ9czVTCFdt6K9mk0ZTk1HaYwFvwscKCqAiZ1auWsQLDWLLrbhd/fREPflArfttCX8u+N1IFmZoFSdLzVpATTV8q3PQkDk3THY1ucPB0mB8P9N/uDwxfr0dkhD8kj8oQk5Bk5JK/IMRkRTiz5RD6TL9HX6Fv0PfpxgUa9dc0DshHRrz8U/gvI</latexit>
DL
] DR
<latexit sha1_base64="ZSc/aIuuYda02WJ0QVQW8PzBr8E=">AAADIHicbZJNbxMxEIad5auErxaOXCwiJE7RLqqAYwU9cOBQEGkrZTfV2PFmTbz2Yo8J0Wp/B1fg13BDHOG/IOFNIyCbjmTp1bzP+GM8rFLSYRz/7EWXLl+5em3nev/GzVu37+zu3T12xlsuRtwoY08ZOKGkFiOUqMRpZQWUTIkTNn/R+icfhHXS6Le4rERWwkzLXHLAkMoOJ69Sr4Oih5M3Z7uDeBivgm6LZC0GZB1HZ3u93+nUcF8KjVyBc+MkrjCrwaLkSjT91DtRAZ/DTIyD1FAKl9WrWzf0YchMaW5sWBrpKvt/RQ2lc8uSBbIELFzXa5MXeWOP+bOslrryKDQ/Pyj3iqKhbQvoVFrBUS2DAG5luCvlBVjgGBq1cQozZo7AXNPvp1osuClL0NM6NaapUxQfkeW1aZpNM8dmnGT1X2CQNFvIv3LoeqYKptDOW9E+jaYsp6bDFMaCnwUOVFXApE6tnBUI1ppFd7vw+Zto6JtS4dsW+kL+nZE60MwsUIqOt5qUYPpK+bYnYWCS7nhsi+PHw+TJcP/1/uDg+Xp0dsh98oA8Igl5Sg7IS3JERoST9+QT+Uy+RF+jb9H36Mc5GvXWNffIRkS//gCWmQue</latexit>
DL
] DR
<latexit sha1_base64="Tf7s3qEix3yKzKbh9vcpsGLm1tk=">AAADSXicbVLdihMxGE2n/qz1r6uX3gSL4FWZkaLeCIu7FwperGJ3FzrTkkkzbWwmGZIv1hLyIj6Nt+oT+BjeiSCY6ZbVTveDgZNzzpdMvpy8EtxAHP9oRe0rV69d37vRuXnr9p273f17J0ZZTdmQKqH0WU4ME1yyIXAQ7KzSjJS5YKf54rDWTz8ybbiS72FVsawkM8kLTgkEatIdHI3fpB8Ul2OXmgJzKZn2ExfYflqAO3w99S+Oxu8uFh6H1aTbi/vxuvAuSDaghzZ1PNlv/UmnitqSSaCCGDNK4goyRzRwKpjvpNawitAFmbFRgJKUzGRufT2PHwVmigulwycBr9n/OxwpjVmVeXCWBOamqdXkZdrIQvE8c1xWFpik5wcVVmBQuJ4VnnLNKIhVAIRqHv4V0znRhEKY6NYpuVILILnxnU4q2ZKqsiRy6lKlvEuBfYK8cMr7bbEAP0oyd2HoJX7H8q+dNDVVBZFJYzWrr4bTvMCq4ZkrTews+Iio5iS8seazORCt1bK5XUjJtjXMTYjwbEt5qb8OTXDnagmcNTQrQ7iCaCth65mEwCTNeOyCkyf95Gl/8HbQO3i5ic4eeoAeoscoQc/QAXqFjtEQUfQZfUFf0bfoe/Qz+hX9PrdGrU3PfbRV7fZfdvcasg==</latexit>
DL
./inner
DL.CId=DR.CId DR](https://image.slidesharecdn.com/dcai-dpds-240416172712-c65ba97e/85/Towards-explanations-for-Data-Centric-AI-using-provenance-records-39-320.jpg)
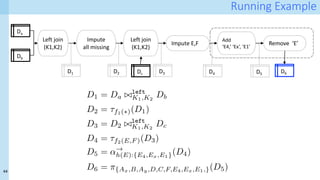
![41
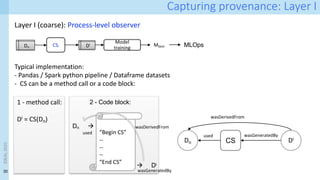
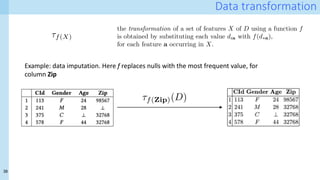
Capturing provenance: bindings
At runtime, when operator o of type 𝜏 is executed, the appropriate template pt𝜏 for 𝜏 is selected
Data items from the inputs and outputs of the operator are used to bind the variables in the template
14/03/2021 03_ b _c .
:///U / 65/D a /03_ b _c . 1/1
14/03/2021 03_ b _c .
:///U / 65/D a /03_ b _c . 1/1
op
{old values: F, I, V} à {new values: F’, J, V’}
+
Binding rules
<latexit sha1_base64="icVdmbcCfxxYOiITpBtlS3uqwUQ=">AAAD+HicdZNdb9MwFIaTlY8RPtbBJTdHVJQhVVWDJkCTKk2AJsbVkOjWqQ6V4zqtmWNHtrOuBP8X7hC3/Buu+R1IOGkFbTccKTo672O/yTnHccaZNp3OT3+jdu36jZubt4Lbd+7e26pv3z/WMleE9ojkUvVjrClngvYMM5z2M0VxGnN6Ep+9LvWTc6o0k+KDmWU0SvFYsIQRbFxqWP8VNAEZemGKA6nAAtsLAY2k0SD2mggFTQTVUyHVm5ki13RkgQrT3rMwQByLMadwAF3oD9MWHHZZC467b4YFa7mEBaTmxBcoAUBMQB8i+N/xYyqowmbJY8nkiXM5HU5a8K50Oe8mO3Mf+3TZxhGVzSlEQTCsNzrtTrXgchAugoa3WEfDbf+3qwHJU2dPONZ6EHYyExVYGUY4tQFyFcgwOcNjOnChwCnVUVF1w8LjsjyQuHImUhiosss7CpxqPUtjR6bYTPS6Viav0ga5SV5GBRNZbqggc6Mk52AklK2FEVOUGD5zASaKuW8FMsEKE+MGYMUllvLM4FjbIECCTolMUyxGBZLSzrsQJ4W0dlVMjB2EUfEXaIT2EvJvO17XZOZEKnSuaPlrgOIE5BozkQrnY8dhnk3wxwIpNp4YrJScrh/nhnoVdXXj3LVtKq7kP0kmHB3LqWF0TcuFuwtOzDOelzVxAxOuj8fl4PhZO3ze3n2/29h/tRidTe+h98jb8ULvhbfvvfWOvJ5H/ENf+hf+rPa59rX2rfZ9jm74iz0PvJVV+/EHk+tPwQ==</latexit>
For i : 1 . . . n :
used ent.:[hF = Xm, I = i, V = Di,Xm
i|Xm 2 X]
generated ent.:[hF0
= Yh, J = i, v = f(Di,X )i|Yh 2 Y ]](https://image.slidesharecdn.com/dcai-dpds-240416172712-c65ba97e/85/Towards-explanations-for-Data-Centric-AI-using-provenance-records-41-320.jpg)




![59
<event
name>
A possible vocabulary / library: DC-Check
[4] Seedat, Nabeel, Fergus Imrie, and Mihaela van der Schaar. ‘DC-Check: A Data-Centric AI Checklist to Guide the Development of
Reliable Machine Learning Systems’. arXiv, 9 November 2022. http://arxiv.org/abs/2211.05764.](https://image.slidesharecdn.com/dcai-dpds-240416172712-c65ba97e/85/Towards-explanations-for-Data-Centric-AI-using-provenance-records-57-320.jpg)
![63
Summary of references
[1] Seedat, Nabeel, Fergus Imrie, and Mihaela van der Schaar. ‘DC-Check: A Data-Centric AI Checklist to Guide the Development of Reliable
Machine Learning Systems’. arXiv, 9 November 2022. http://arxiv.org/abs/2211.05764.
[2] Mohammad Hossein Jarrahi, Ali Memariani, and Shion Guha. 2023. The Principles of Data-Centric AI. Commun. ACM 66, 8 (August 2023), 84–92.
https://doi.org/10.1145/3571724
[3] Zha, Daochen, Zaid Pervaiz Bhat, Kwei-Herng Lai, Fan Yang, and Xia Hu. ‘Data-Centric AI: Perspectives and Challenges’. arXiv, 2 April 2023.
http://arxiv.org/abs/2301.04819.
[4] Zha, Daochen, Zaid Pervaiz Bhat, Kwei-Herng Lai, Fan Yang, Zhimeng Jiang, Shaochen Zhong, and Xia Hu. ‘Data-Centric Artificial Intelligence: A
Survey’. arXiv, 11 June 2023. https://doi.org/10.48550/arXiv.2303.10158.
[5] Singh, Prerna. ‘Systematic Review of Data-Centric Approaches in Artificial Intelligence and Machine Learning’. Data Science and Management 6,
no. 3 (1 September 2023): 144–57. https://doi.org/10.1016/j.dsm.2023.06.001.
[6] Neutatz, Felix, et al. "From Cleaning before ML to Cleaning for ML." IEEE Data Eng. Bull. 44.1 (2021): 24-41.
[7] Mazumder, Mark, Colby Banbury, Xiaozhe Yao, Bojan Karlaš, William Gaviria Rojas, Sudnya Diamos, Greg Diamos, et al. ‘DataPerf: Benchmarks for
Data-Centric AI Development’. arXiv, 13 October 2023. https://doi.org/10.48550/arXiv.2207.10062.
[8] J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language
models. arXiv preprint arXiv:2001.08361, 2020.
[9] Abbas, Amro, Kushal Tirumala, Dániel Simig, Surya Ganguli, and Ari S. Morcos. ‘SemDeDup: Data-Efficient Learning at Web-Scale through Semantic
Deduplication’. arXiv, 22 March 2023. http://arxiv.org/abs/2303.09540.
[10] Sorscher, Ben, et al., Advances in Neural Information Processing Systems 35 (2022): 19523-19536. Beyond neural scaling laws: beating power
law scaling via data pruning
[11] A. Chapman, P. Missier, G. Simonelli, and R. Torlone. 2020. Capturing and querying fine-grained provenance of preprocessing pipelines in data
science. Proc. VLDB Endow. 14, 4 (December 2020), 507–520. https://doi.org/10.14778/3436905.3436911
[12] A. Chapman, L. Lauro, P. Missier, and R. Torlone. 2022. DPDS: assisting data science with data provenance. Proc. VLDB Endow. 15, 12 (2022),
3614–3617. https://doi.org/10.14778/3554821.3554857
IDEAL
2023](https://image.slidesharecdn.com/dcai-dpds-240416172712-c65ba97e/85/Towards-explanations-for-Data-Centric-AI-using-provenance-records-59-320.jpg)

The document discusses the role of data provenance in optimizing training sets for data-centric AI, detailing methods like data cleaning and optimization strategies that use provenance records. It highlights complex data transformations and the need for explainability and reproducibility in data science workflows. The document also provides insights into item-level transformation and the representation of provenance within data pipelines, emphasizing the importance of documentation and versioning for effective AI model training and evaluation.

































































