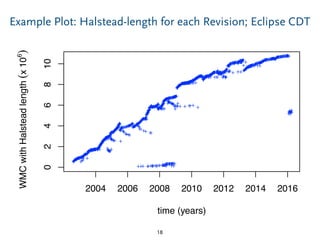
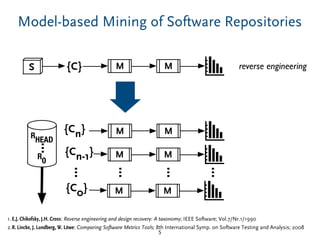
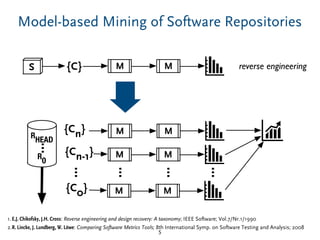
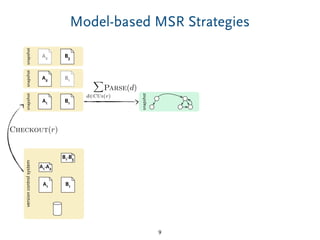
The document discusses a model-based approach to analyzing software repositories, particularly focusing on software evolution, reverse engineering, and mining software repositories. It introduces the 'srcrepo' framework, emphasizing the integration of existing meta-models and tools to enhance interoperability and scalability in software analysis. Experiments conducted with Eclipse's software repositories reveal insights into modeling strategies and performance metrics in code analysis.


![Mining Software Repositories – In General
▶ The term mining software repositories (MSR) has been coined
to describe a broad class of investigations into the examination
of software repositories.
▶ The premise of MSR is that empirical and systematic
investigations of repositories will shed new light on the process
of software evolution. [1]
▶ Different scopes, e.g. single software projects vs. many
software projects
▶ Different goals, e.g. quality assessments and implicit
dependencies vs. generalizations about software evolution
4
1.H. Kagdi, M.L. Collard, J.I. Maletic: A survey and taxonomy of approaches for mining software repositories in the context of software
evolution; Journal of Software Maintenance and Evolution: Research and Practice; Vol.19/Nr.2/2007](https://image.slidesharecdn.com/srcrepo-modelsward-170323115433/85/Creating-and-Analyzing-Source-Code-Repository-Models-A-Model-based-Approach-to-Mining-Software-Repositories-4-320.jpg)


























![“OCL” to Calculate Metrics of AST-Models
16
// Weighted number of methods per class.
def wmc(AbstractTypeDeclaration type,(Block) int weight) {
type.bodyDeclarations.sum[if (body != null) weight.apply(it.body) else 1]
}](https://image.slidesharecdn.com/srcrepo-modelsward-170323115433/85/Creating-and-Analyzing-Source-Code-Repository-Models-A-Model-based-Approach-to-Mining-Software-Repositories-36-320.jpg)