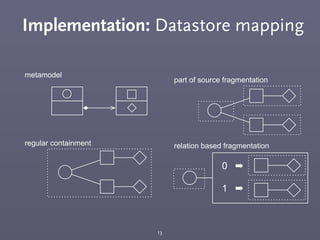
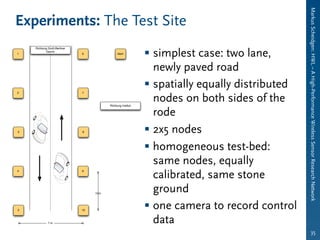
This document discusses different model representations for large meta-model based datasets. It compares object-by-object representation to fragmentation strategies. Fragmentation breaks models into multiple fragments stored separately. The document evaluates different fragmentation strategies through theoretical analysis and implementation tests. It also compares part-of-source and relational representations and discusses applications of model fragmentation including software engineering and scientific data analysis.





![Representation: Object-by-object vs. Fragmentation
(considering traversal, theoretical results)
6
10
0
10
1
10
2
10
3
10
4
10
5
10
6
10
0
10
1
10
2
10
3
10
4
10
5
Number of loaded objects [l]
no fragmentation [f=m]
optimal fragmentation
total fragmentation [f=1]
Executiontime[t](inms)
1e+00
1e+01
1e+02
1e+03
1e+04
1e+05
1e+06
Fragment size [f]](https://image.slidesharecdn.com/2013-06-17bigmde-130709052936-phpapp02/85/Reference-Representation-in-Large-Metamodel-based-Datasets-6-320.jpg)
![Representation: Object-by-object vs. Fragmentation
(considering traversal, theoretical results vs. implementation)
7
10
0
10
1
10
2
10
3
10
4
10
5
10
6
10
0
10
1
10
2
10
3
10
4
10
5
Number of loaded objects [l]
no fragmentation [f=m]
optimal fragmentation
total fragmentation [f=1]
Executiontime[t](inms)
1e+00
1e+01
1e+02
1e+03
1e+04
1e+05
1e+06
Fragment size [f]
10
0
10
1
10
2
10
3
10
4
10
5
10
6
10
0
10
1
10
2
10
3
10
4
10
5
Number of loaded objects [l]
Executiontime[t](inms)
1e+01
1e+02
1e+03
1e+04
1e+05
Fragment size [f]
optimal fragmentation](https://image.slidesharecdn.com/2013-06-17bigmde-130709052936-phpapp02/85/Reference-Representation-in-Large-Metamodel-based-Datasets-7-320.jpg)






























![Complex Data Types: Meta-Modeling
47
This [ ] happens all the time in software modeling
state charts class diagrams MSCsOCL
context Foo
self.properties->
foreach(a|a.x != a.y)
eclipse modeling framework (EMF)
➡ Distributed storage and links between different types of data is only a simple
extension of existing technology: multi resource persistence is already implemented](https://image.slidesharecdn.com/2013-06-17bigmde-130709052936-phpapp02/85/Reference-Representation-in-Large-Metamodel-based-Datasets-47-320.jpg)





































































