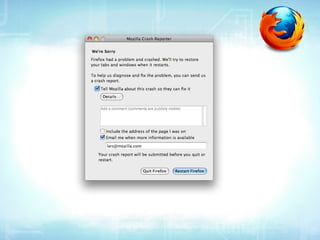
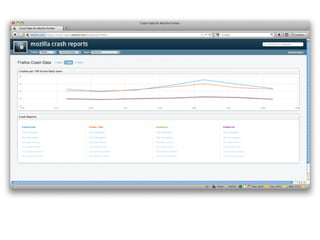
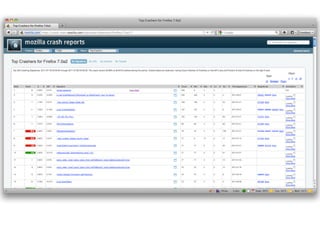
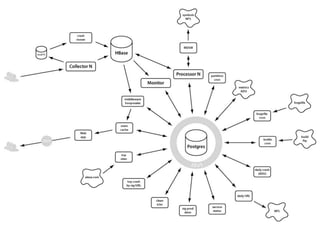
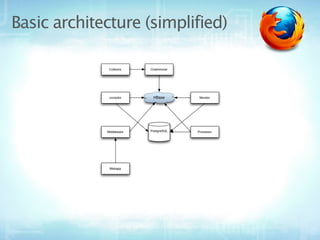
This document provides an overview of Socorro, Mozilla's system for processing Firefox crash reports with Python. It describes the basic architecture, how a crash report moves through the system from collection to processing to storage in databases. It also discusses the scale of Socorro, currently processing over 2.5 million crash reports per day and storing over 110 terabytes of crash data. The document outlines Socorro's implementation including the various components, tools, and techniques used to manage complexity at this large scale.