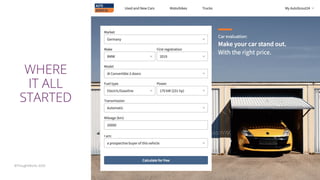
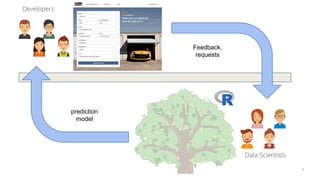
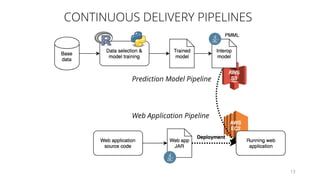
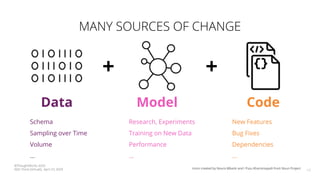
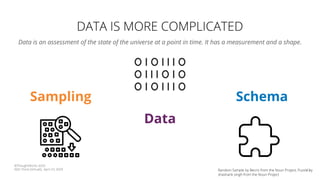
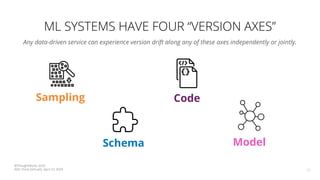
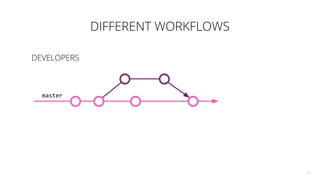
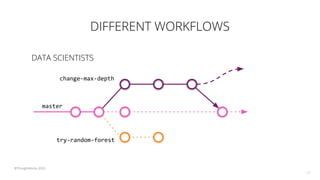
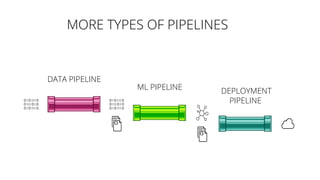
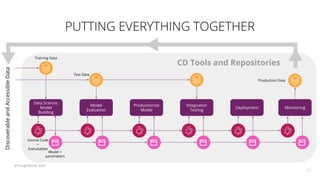
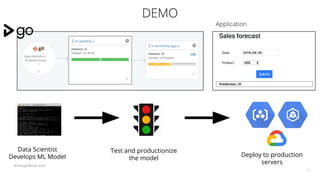
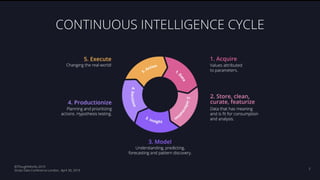
The document discusses the challenges and techniques associated with continuous delivery for machine learning (CD4ML), emphasizing the complexities of version control for training data, models, and schemas. It outlines the importance of maintaining model performance while managing multiple evolving data aspects through various pipelines. Additionally, it highlights the need for effective orchestration and monitoring in machine learning environments to ensure successful deployment and integration.