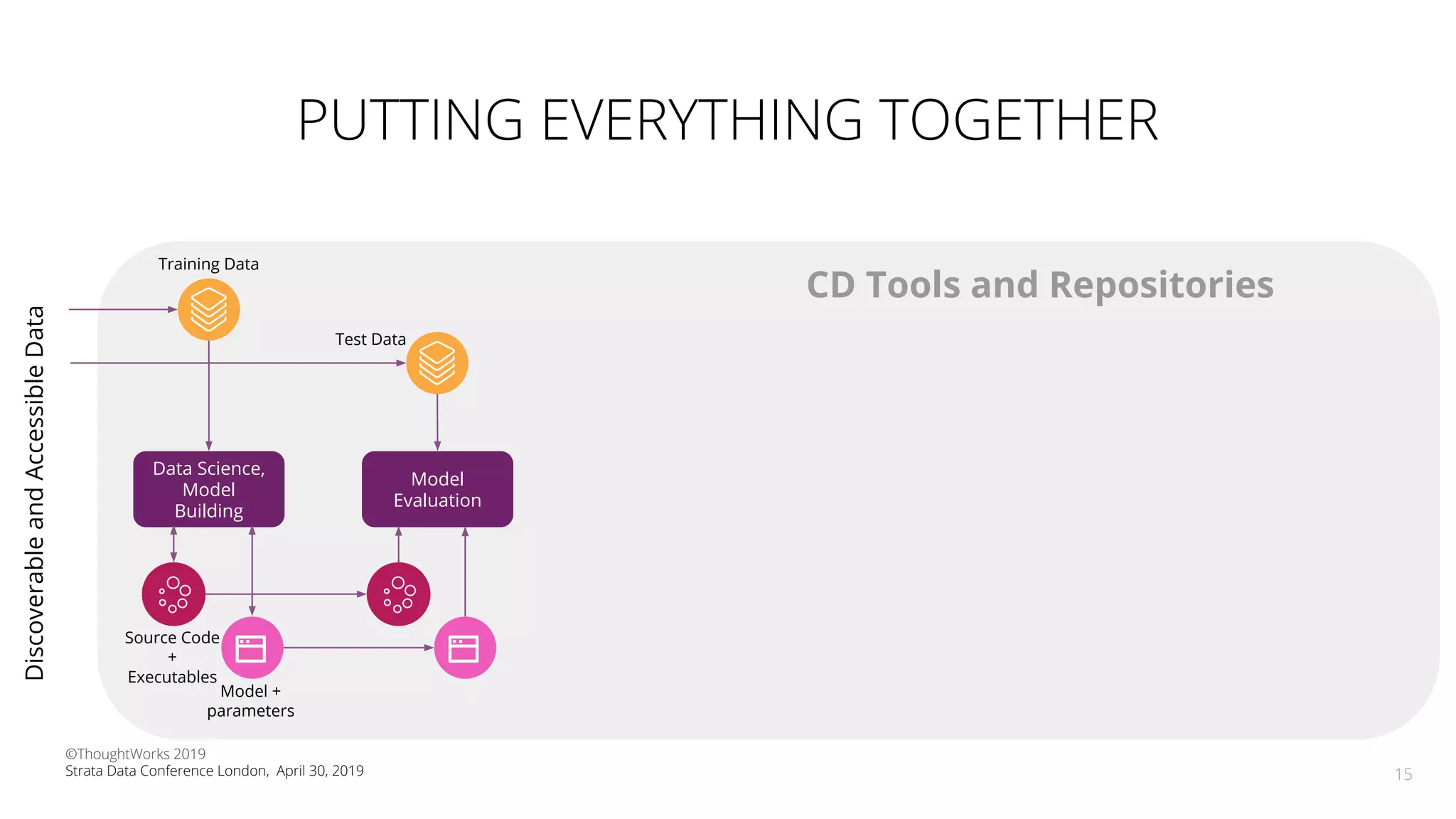
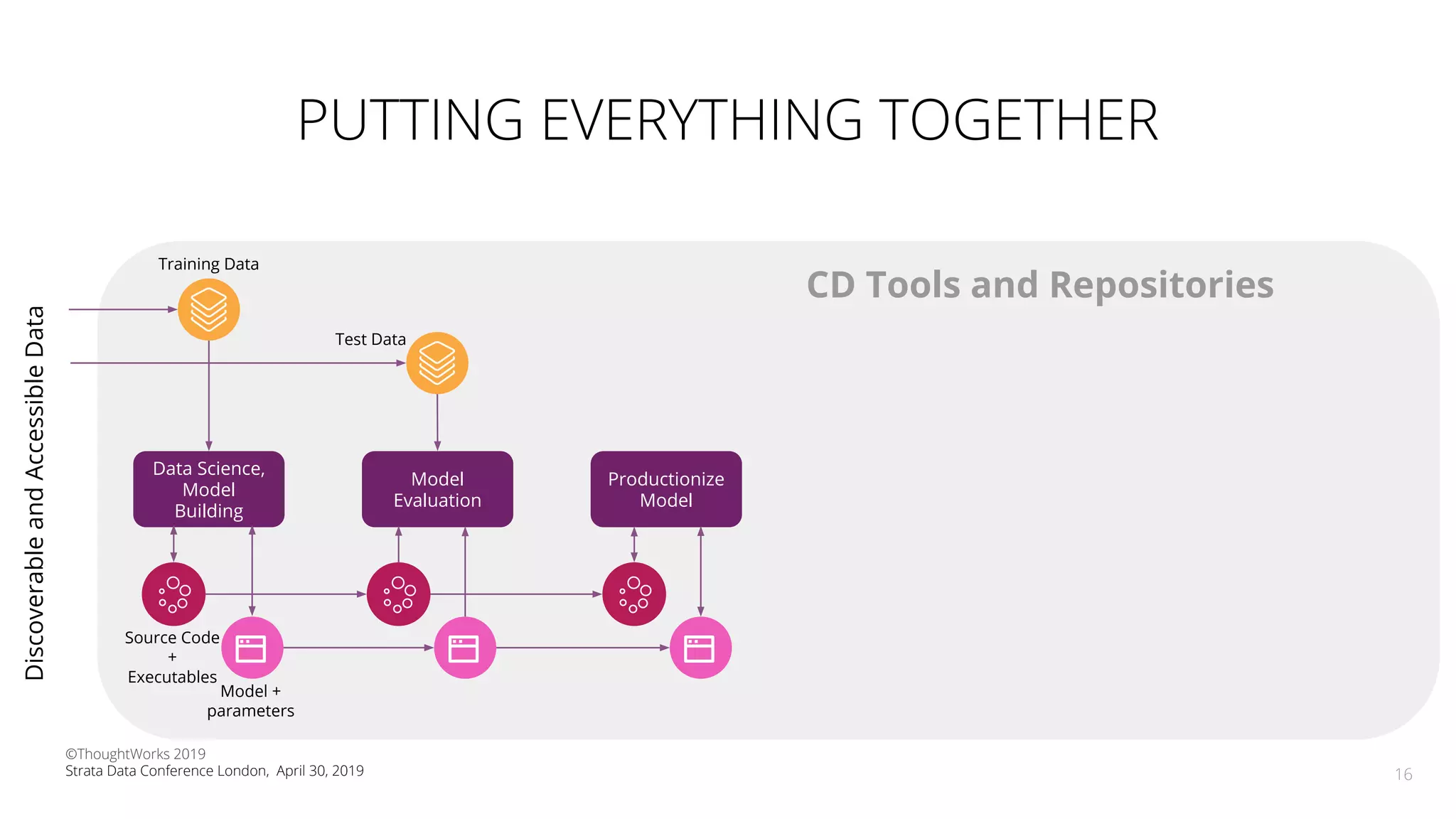
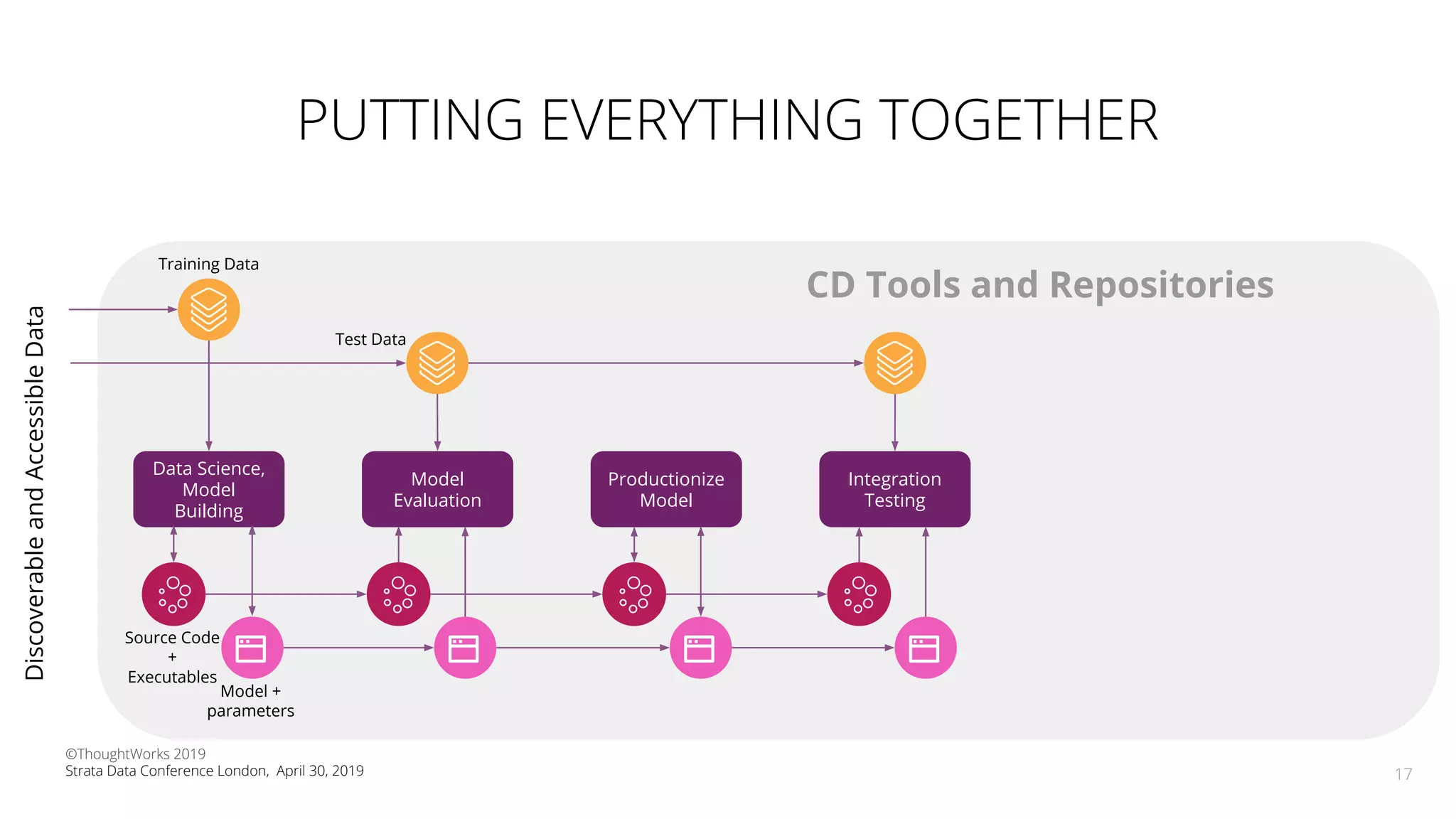
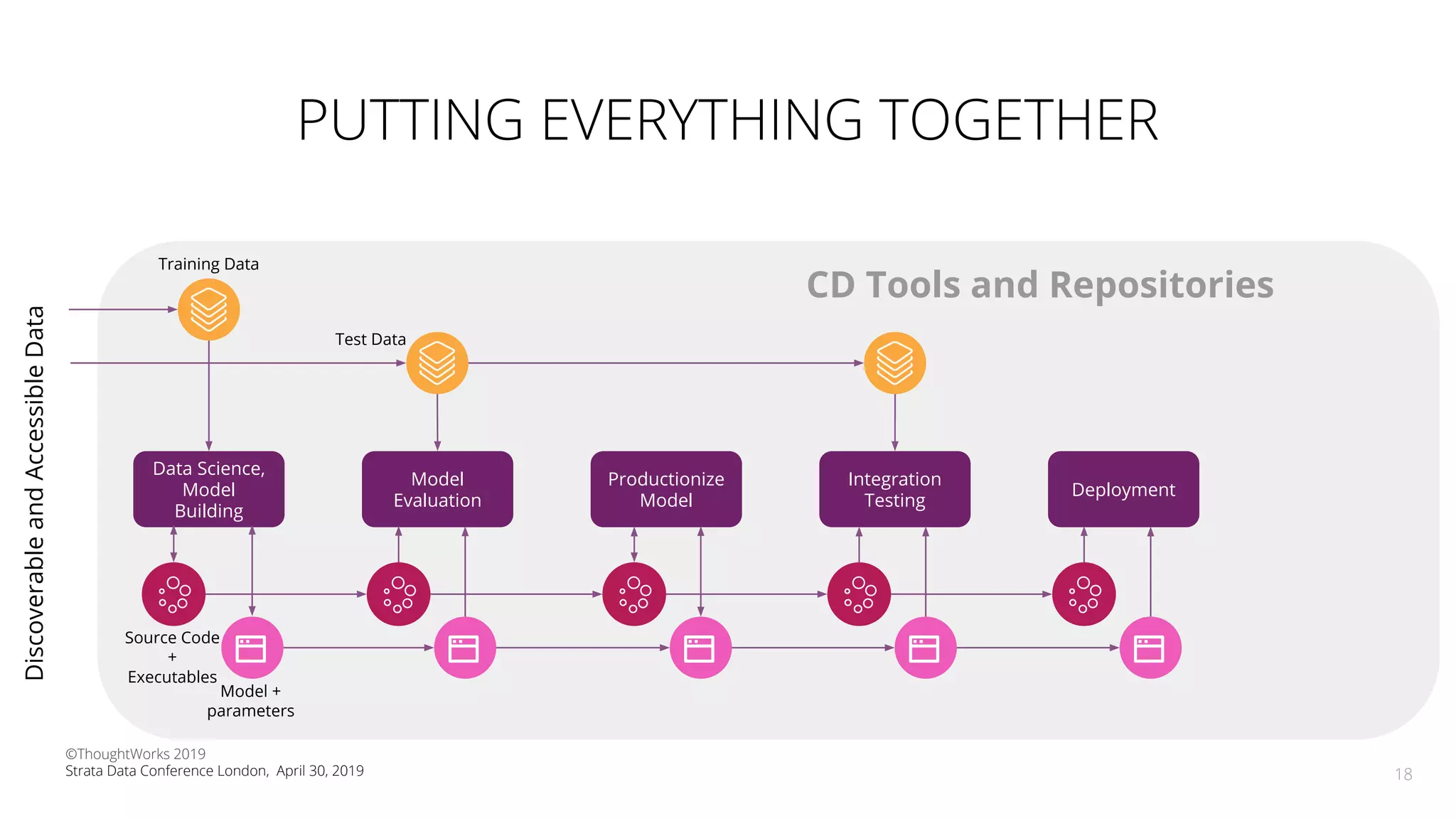
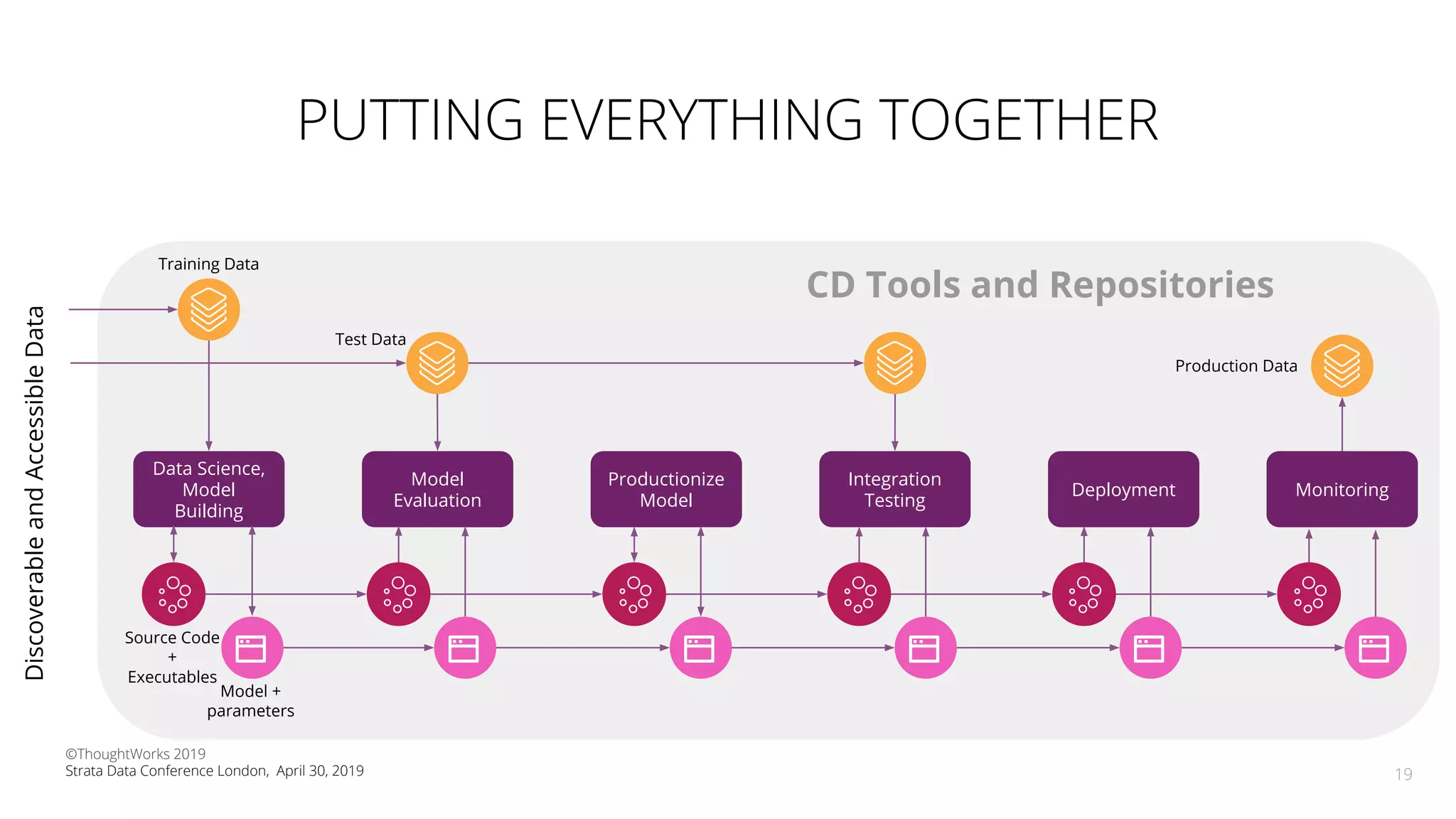
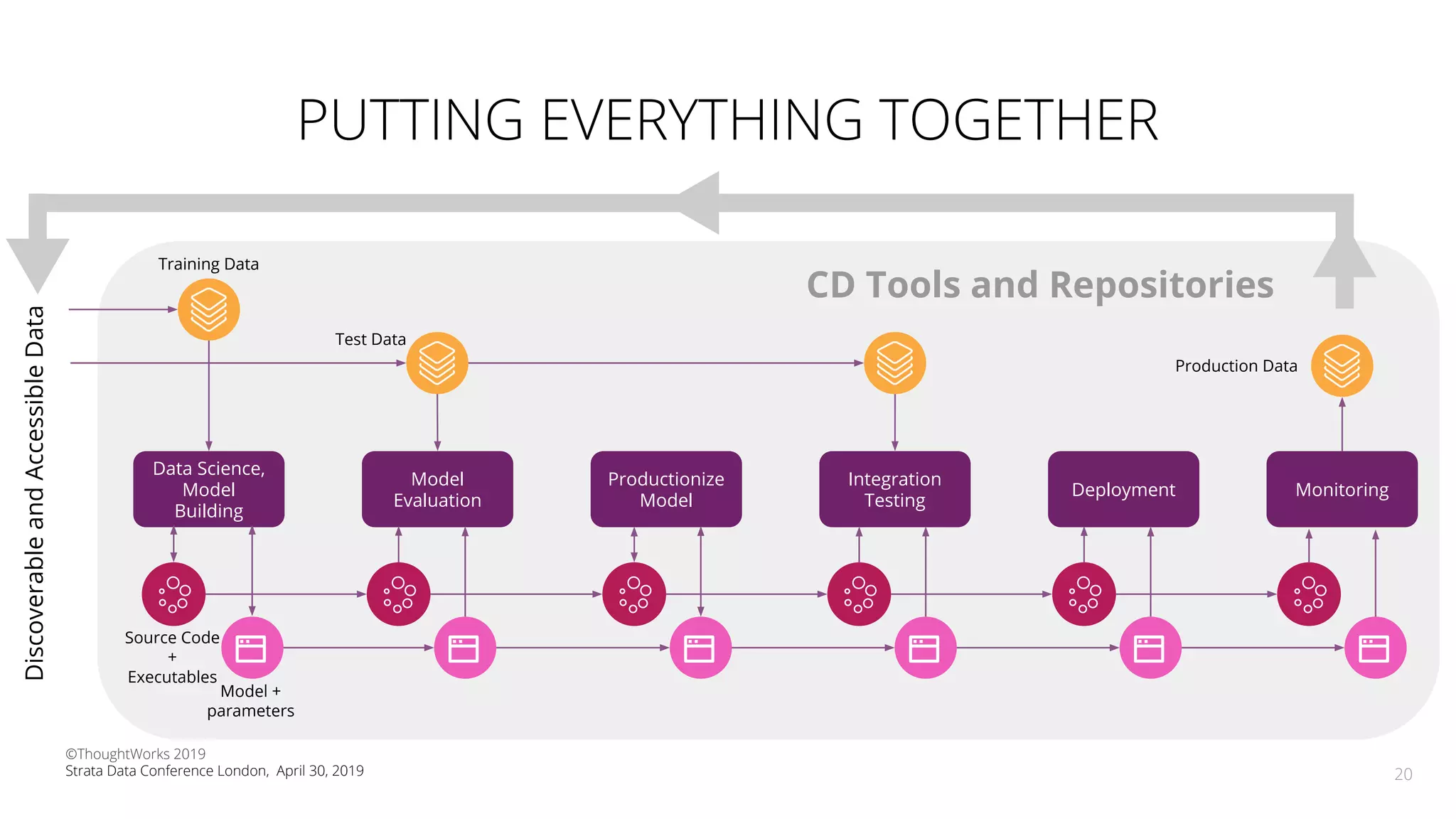
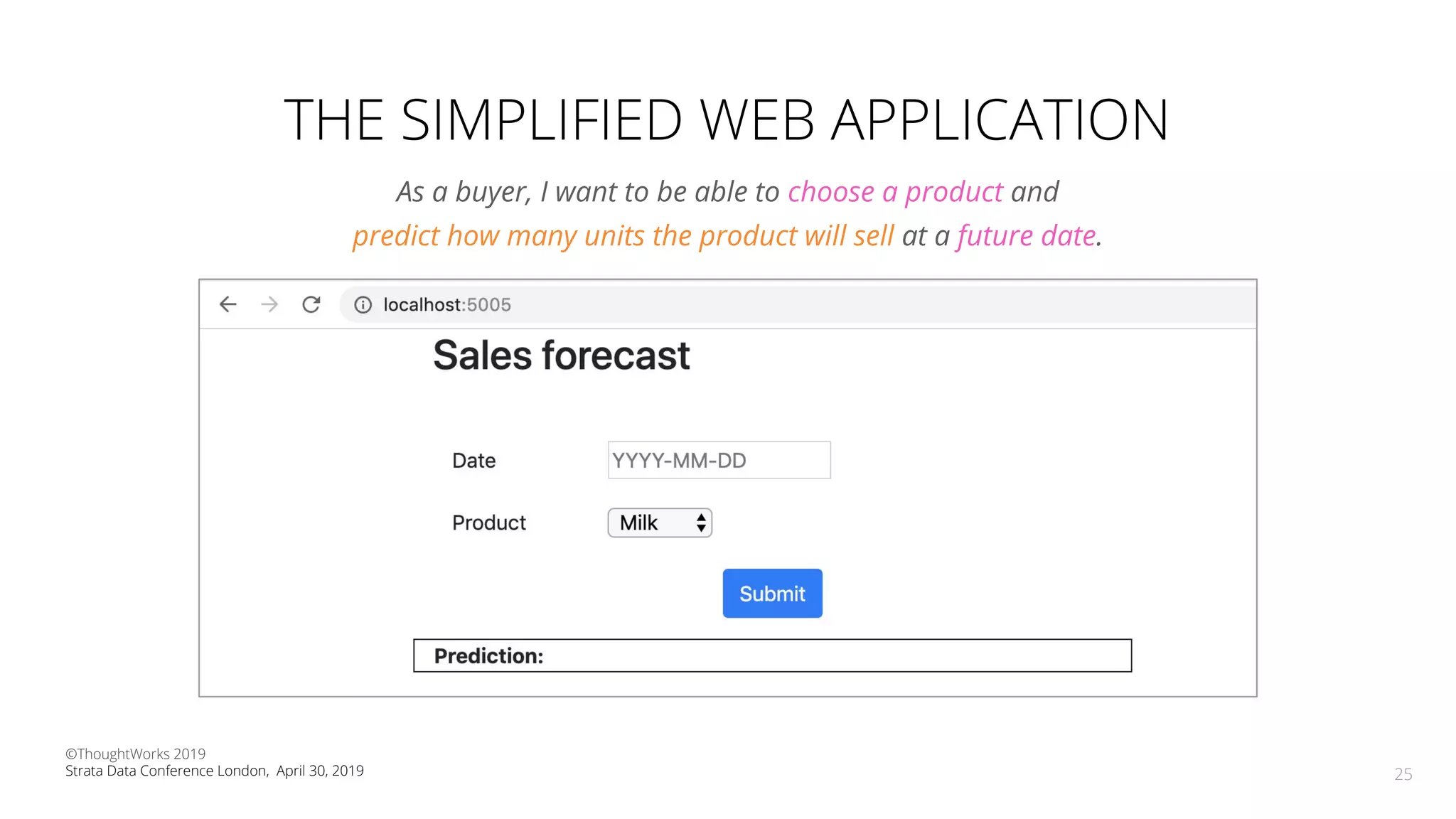
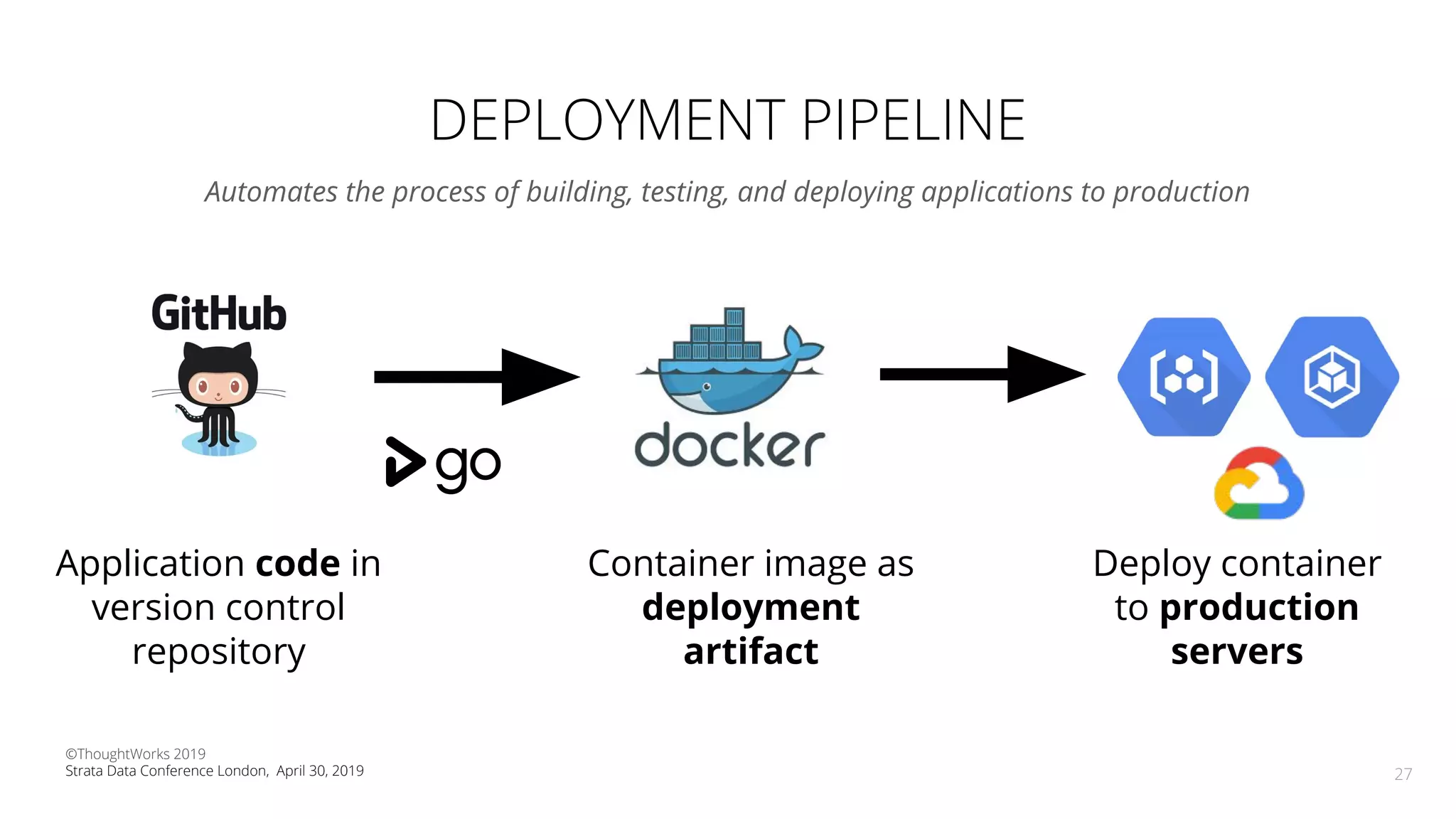
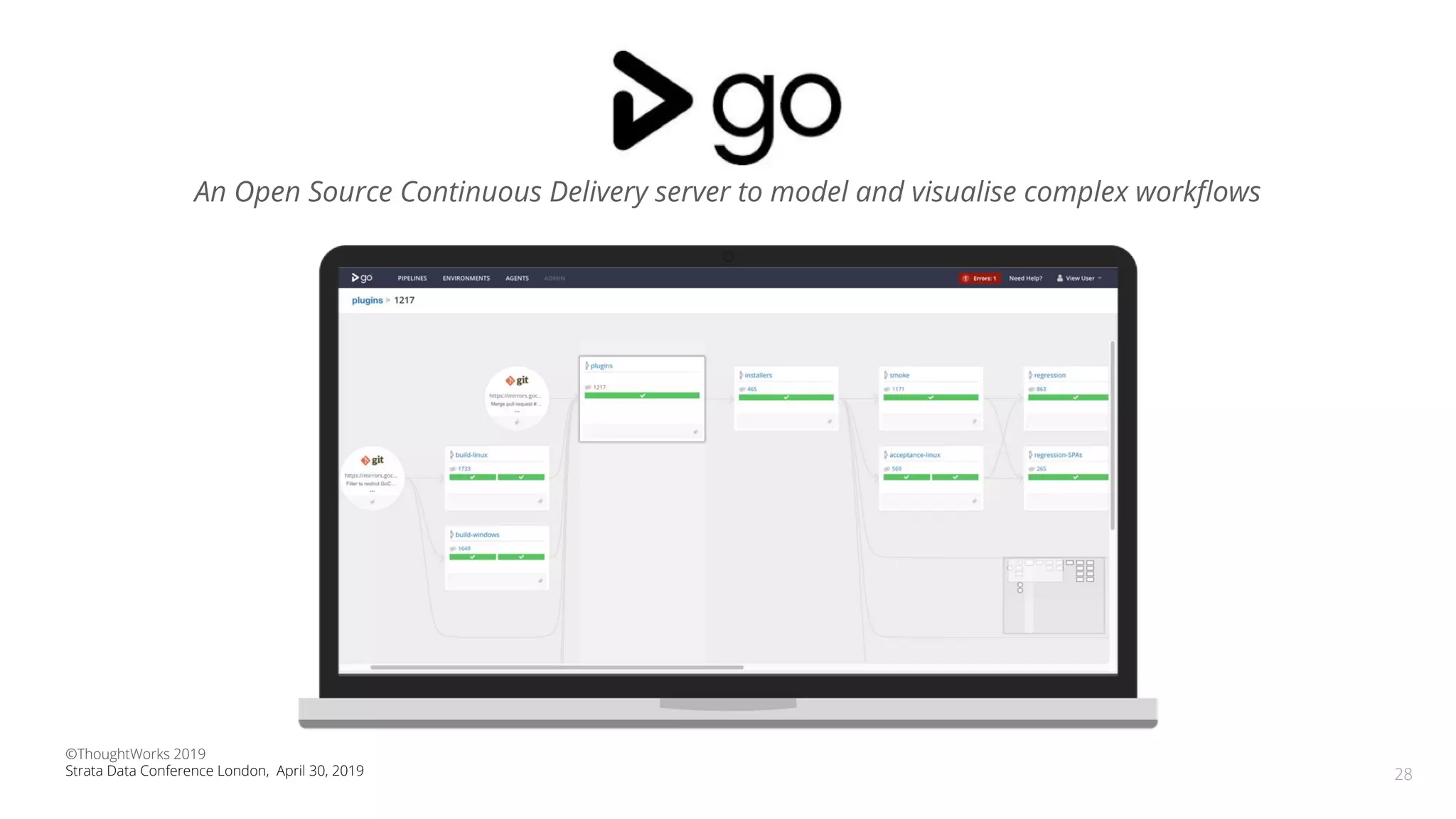
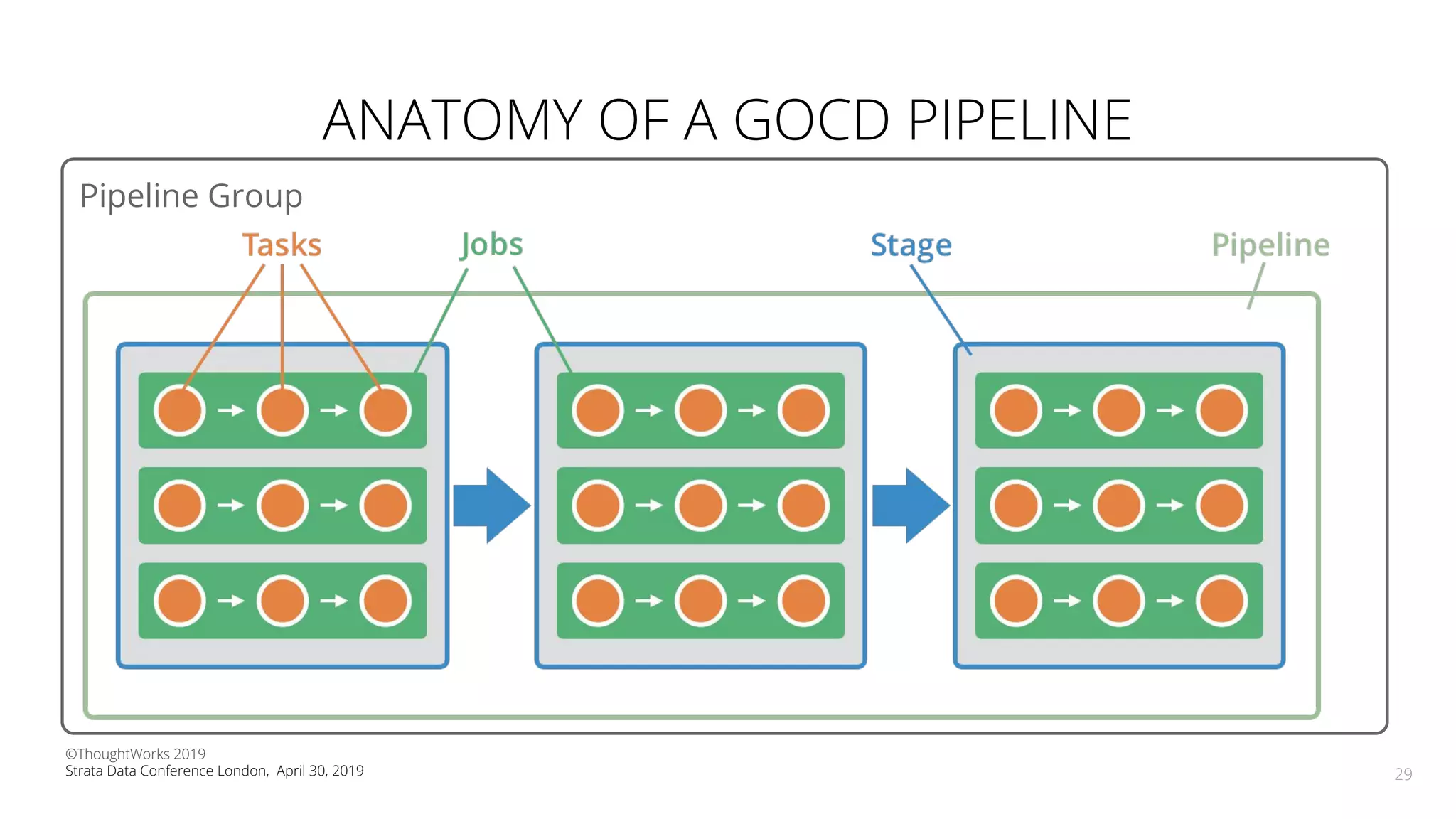
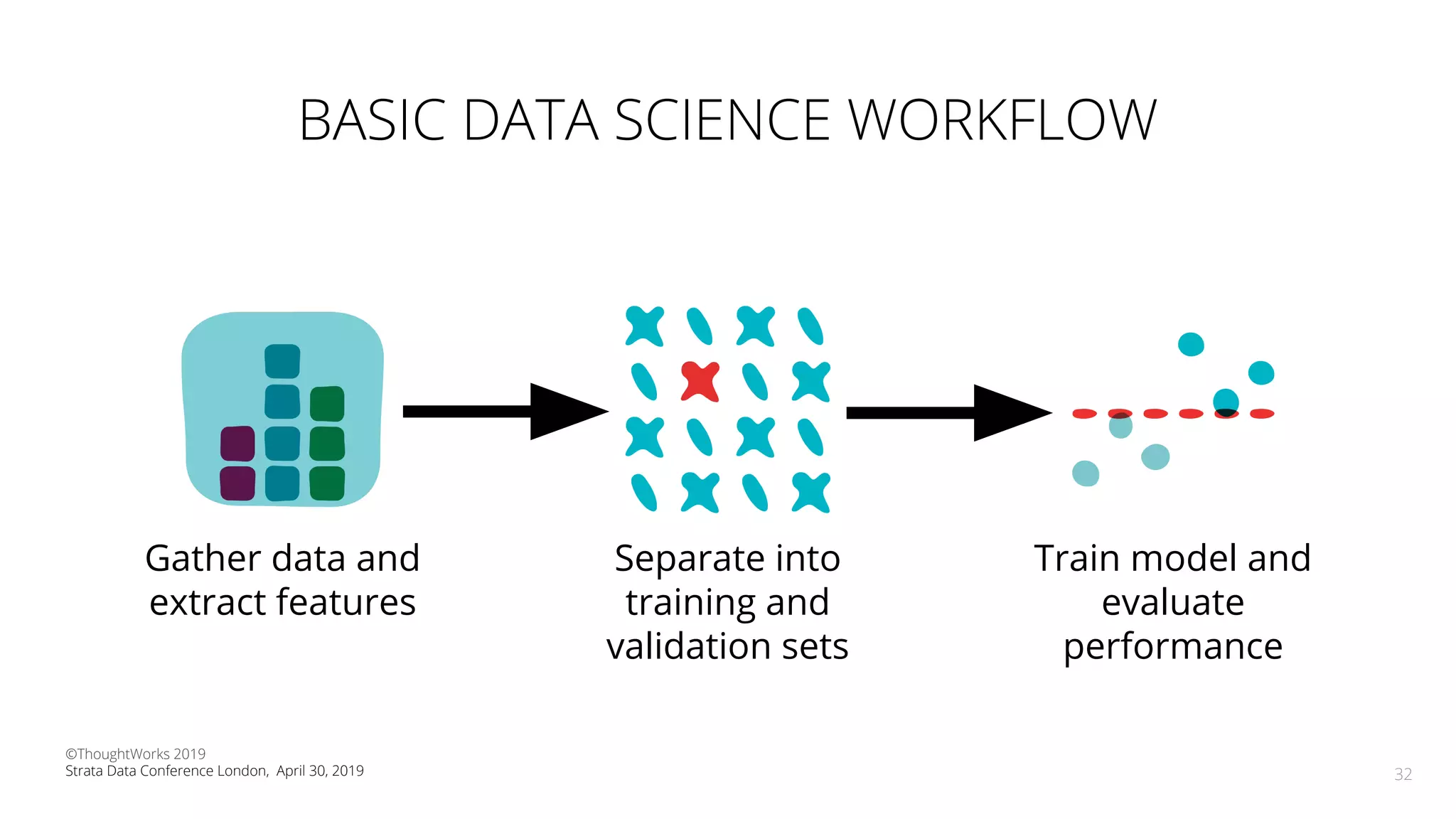
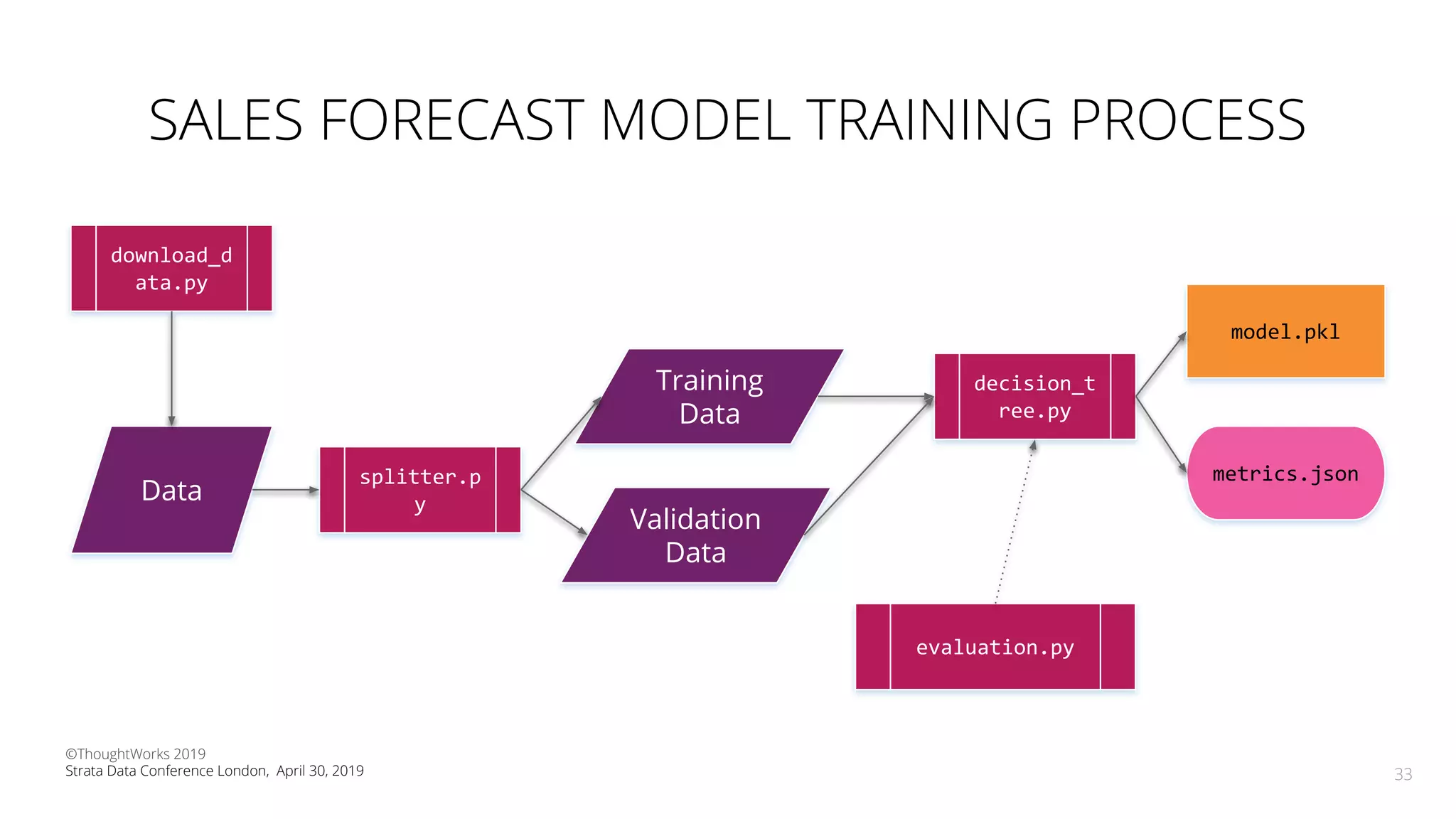
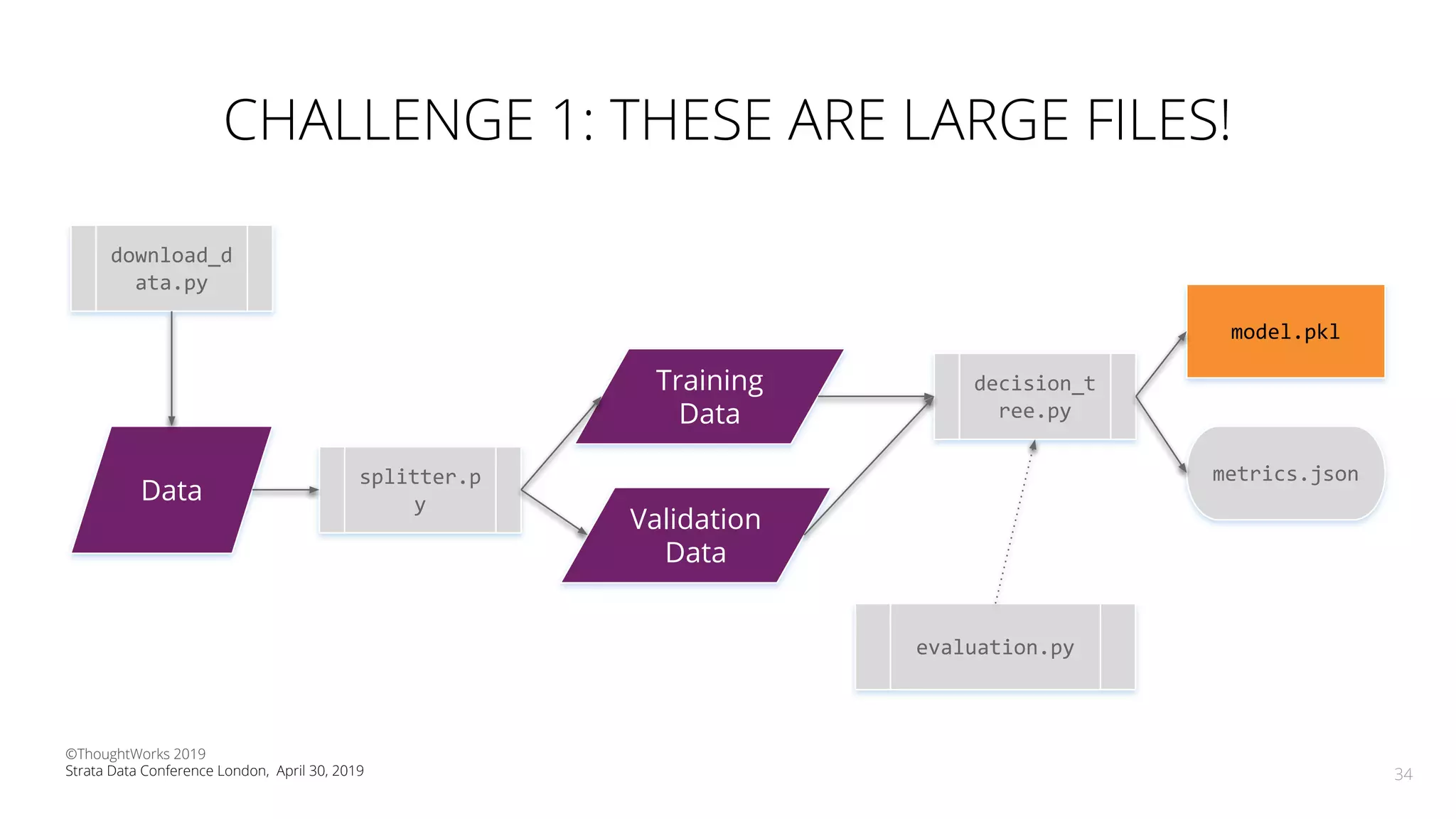
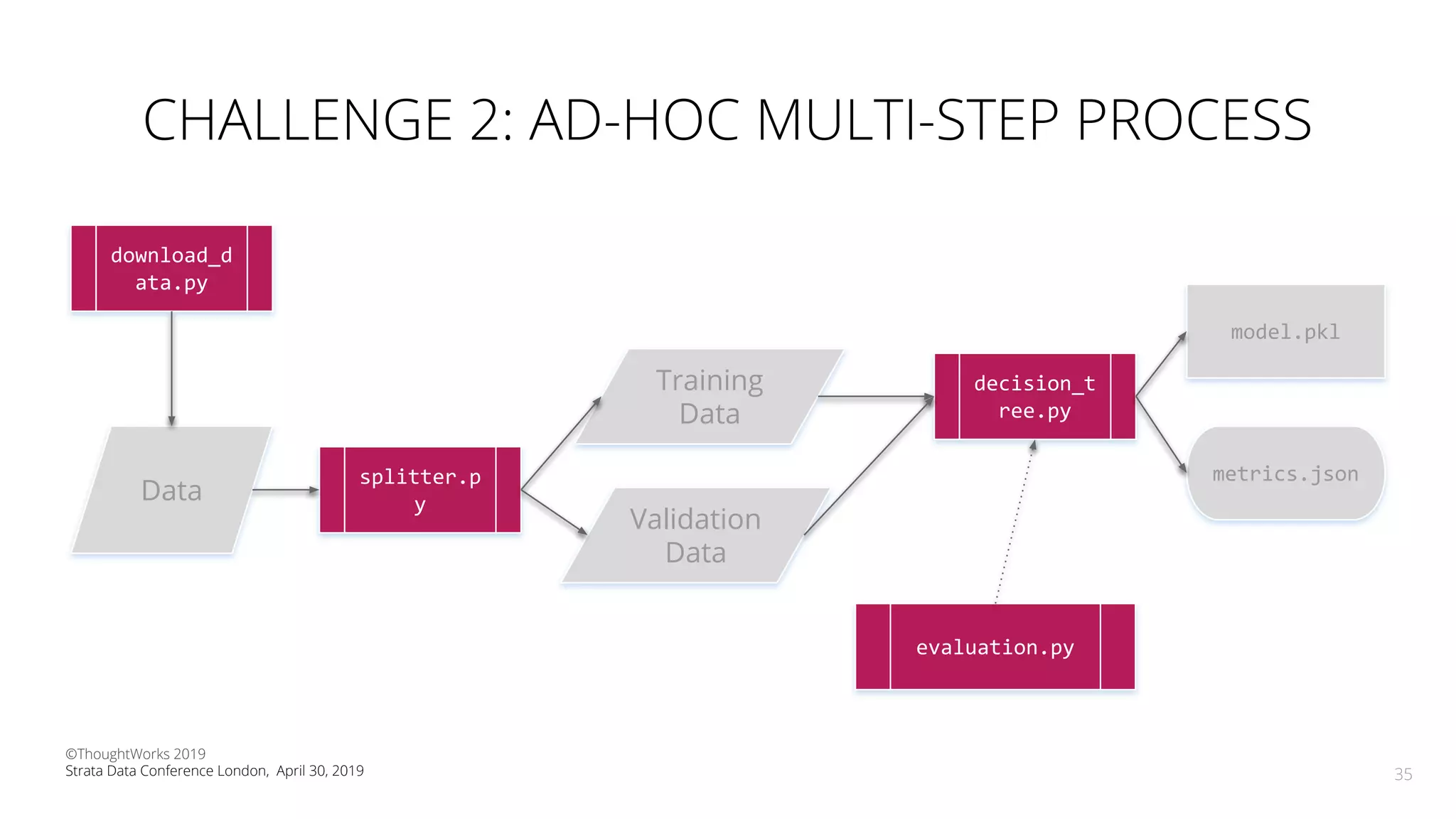
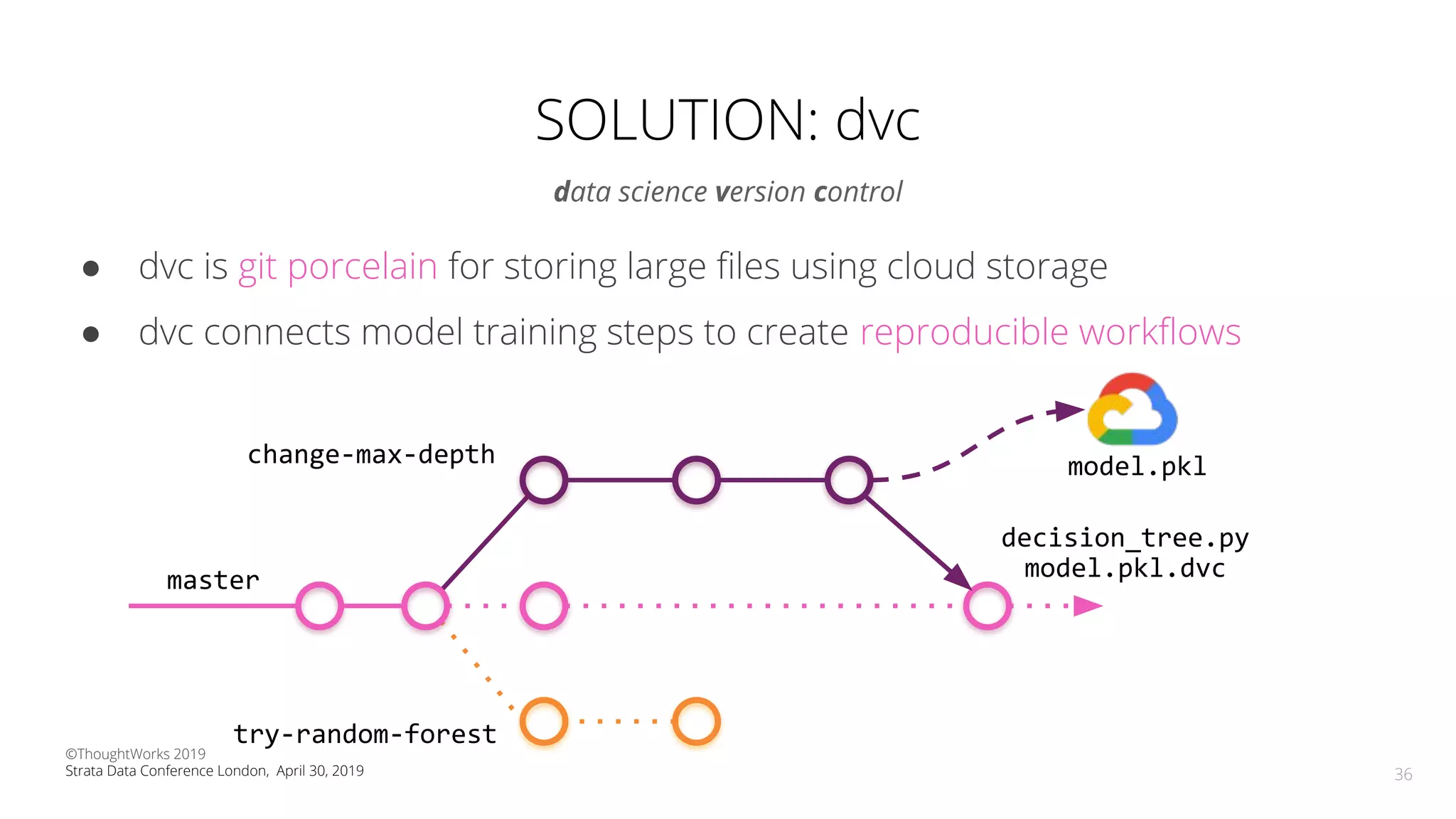
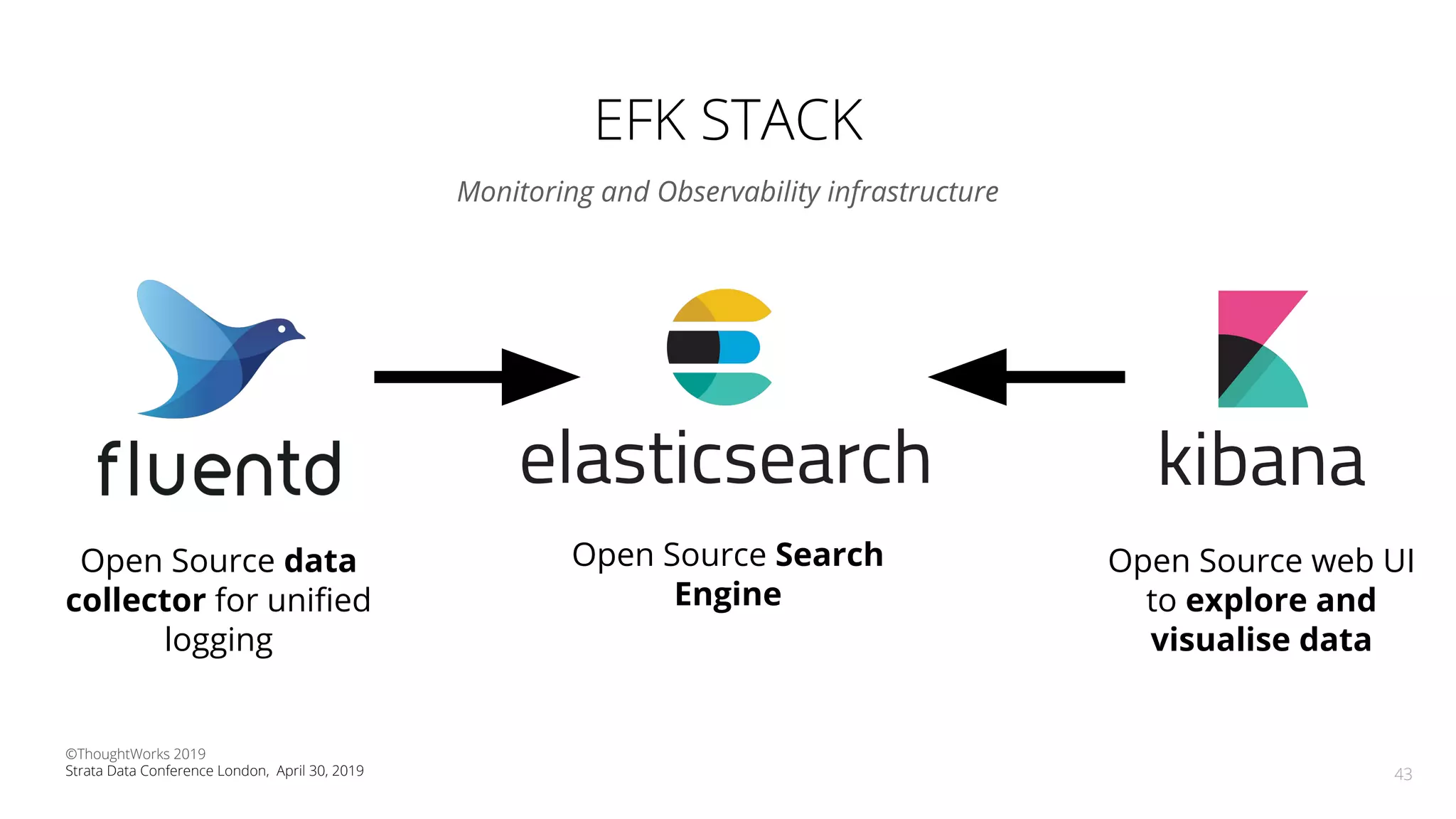
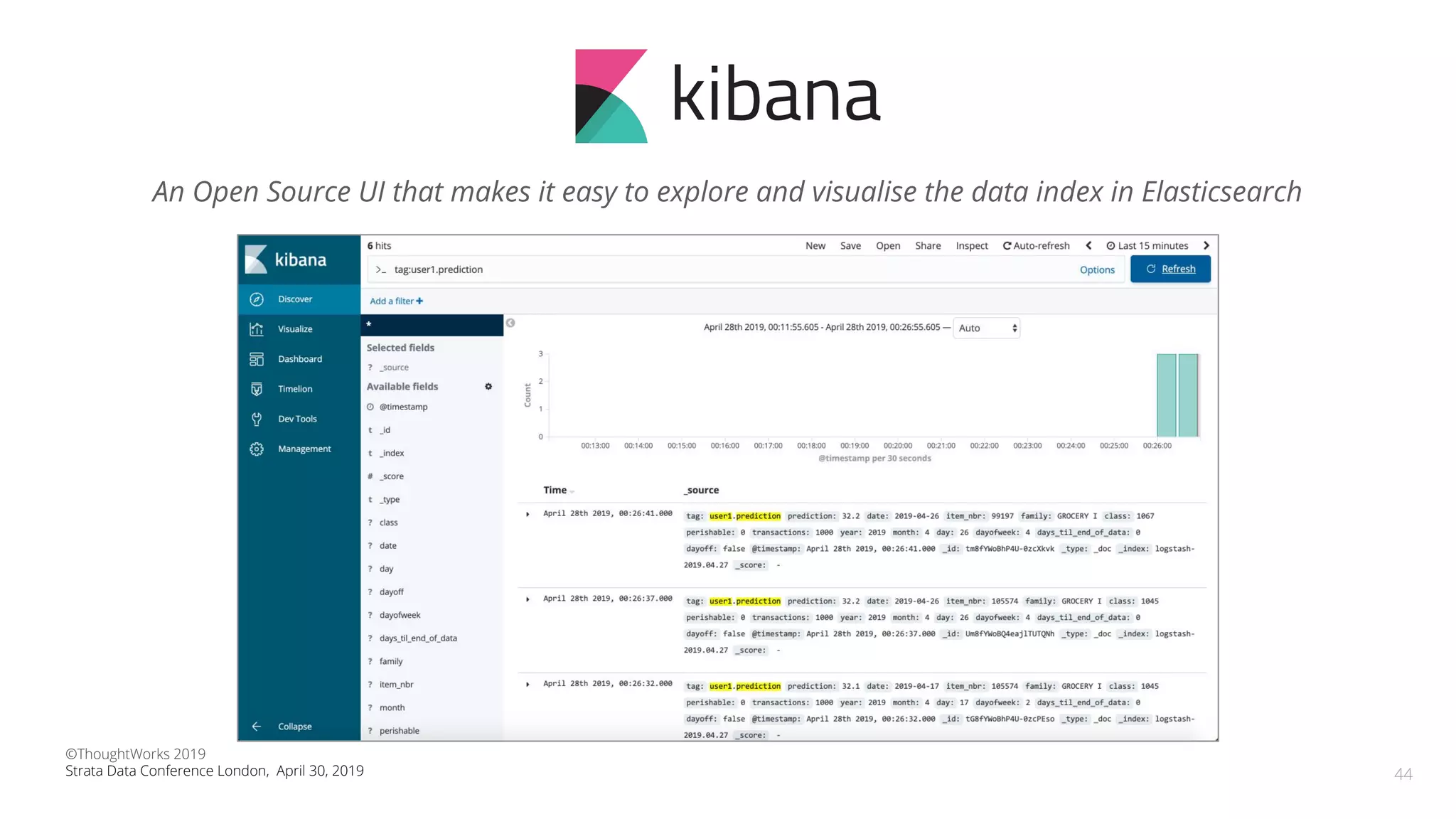
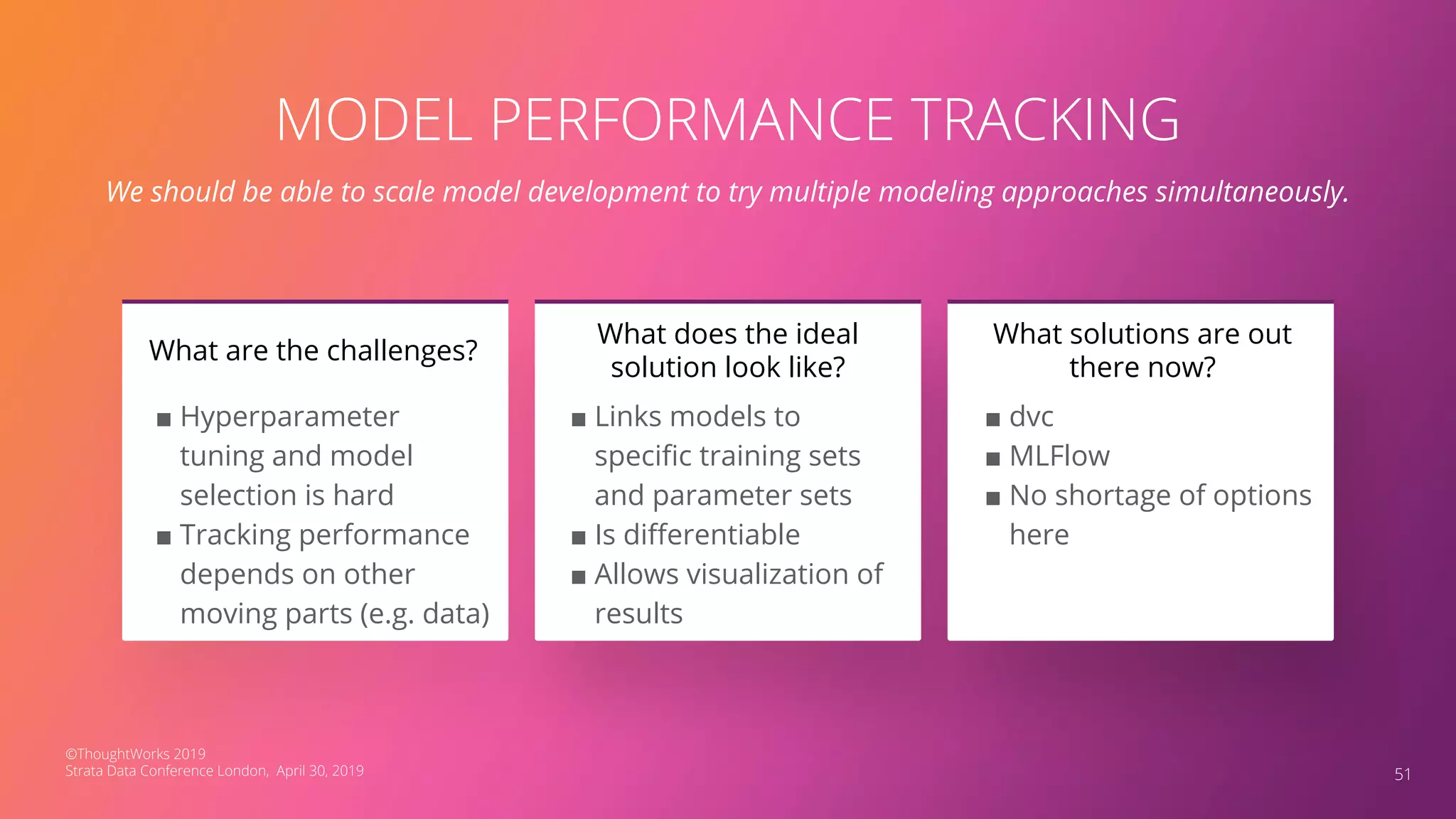
The document discusses the application of Continuous Delivery for Machine Learning (CD4ML) to enhance the production process of machine learning models, emphasizing the need for reproducibility, testability, and monitoring. It outlines workshops' exercises focused on setting up pipelines, tracking experiments, and deploying ML models, while addressing the unique challenges posed by non-deterministic systems. Overall, the document highlights best practices and tools for streamlining machine learning workflows and ensuring continuous improvement in production AI systems.