Download as PDF, PPTX







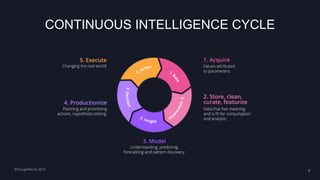









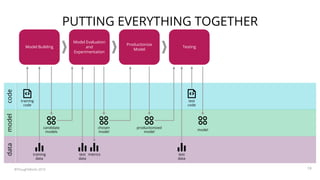
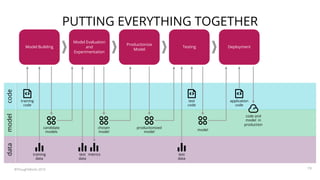
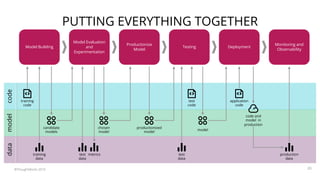









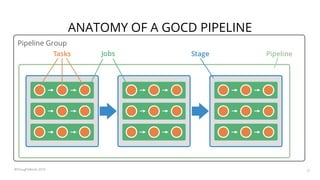




















The document summarizes a workshop on continuous delivery for machine learning models. It discusses the challenges of deploying machine learning systems according to continuous delivery principles due to the non-deterministic and unpredictable nature of ML models. The workshop covers exercises to set up ML pipelines using tools like DVC for version control and MLflow for experiment tracking to enable continuous delivery of ML models from development to production. It also demonstrates how to monitor models in production using the EFK stack.





















































































