Download as PDF, PPTX





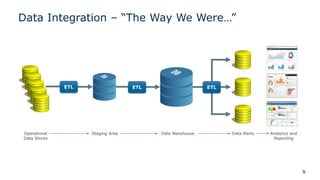
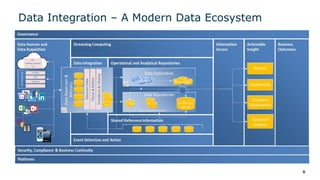
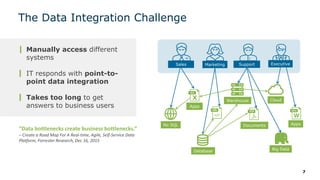

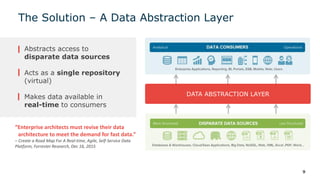

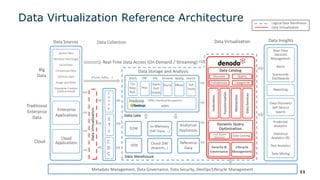




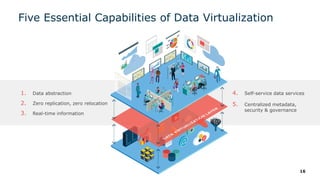

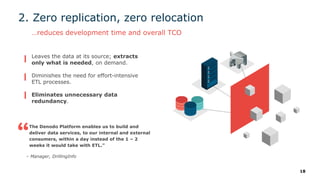


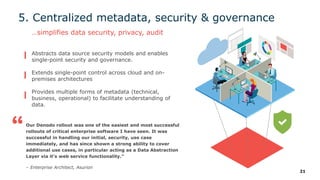
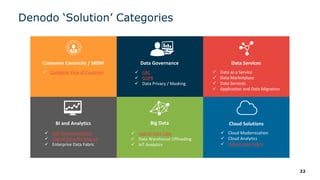




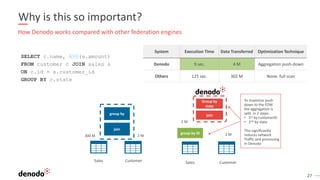
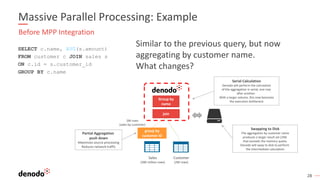
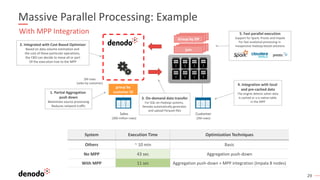

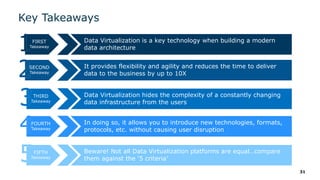





The webinar series on data virtualization, presented by Denodo experts, addresses key data integration challenges and introduces how data virtualization can streamline accessing disparate data sources in real-time. It emphasizes essential capabilities such as data abstraction, zero replication, and self-service data services to enhance analytics and decision-making. The session outlines the advantages of adopting data virtualization for modern data architecture, and the importance of considering different platforms based on specific criteria.









































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)


![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










