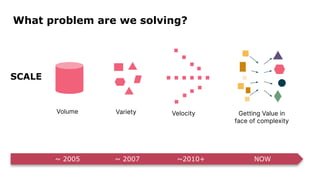
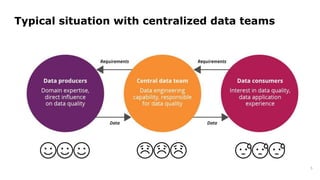
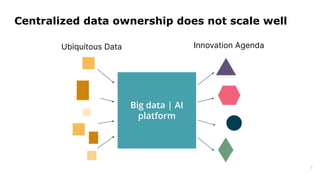
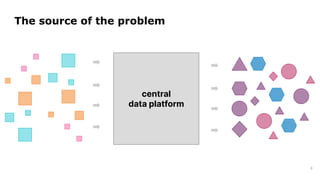
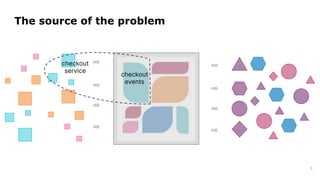
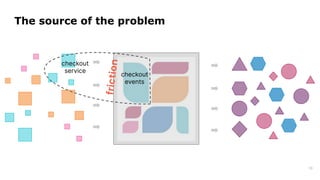
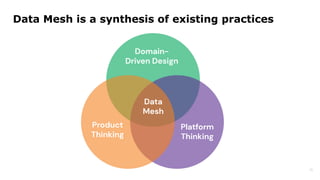
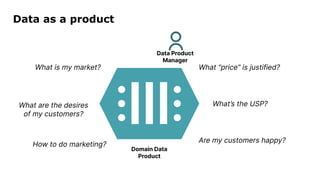
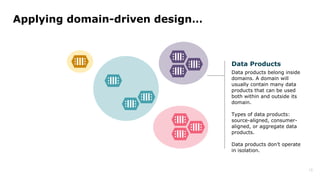
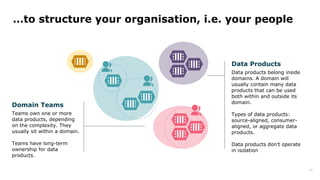
Dr. Arif Wider discusses the concept of data mesh at the Data Innovation Summit 2022, emphasizing that it focuses on people rather than technology. He highlights the limitations of centralized data ownership and suggests that data products should be organized within domains led by cross-functional teams. The approach fosters a mindset shift in organizations, enabling more scalable and interconnected data products over time.












![[DSC Europe 23] Ivan Dundovic - How To Treat Your Data As A Product.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ewangp91sryz0b4shlxd-ivan-dundovic-howtotreatyourdataasaproduct-231129143902-dd1541cf-thumbnail.jpg?width=640&height=640&fit=bounds)
























































