Download to read offline







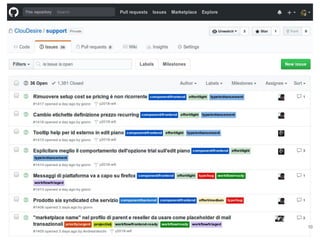





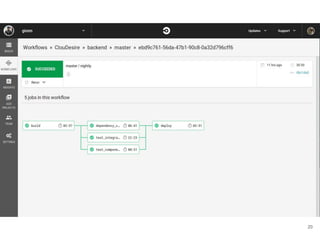
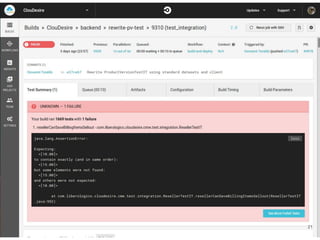
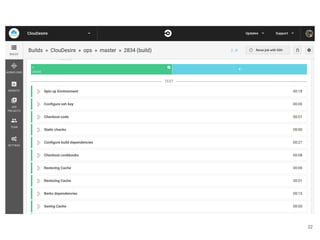
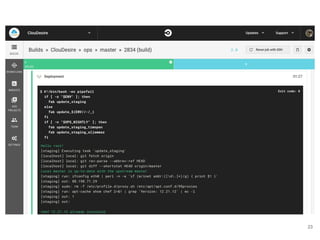

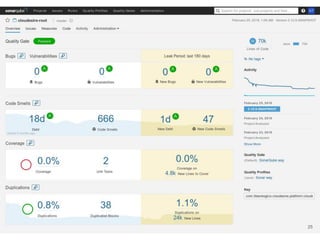
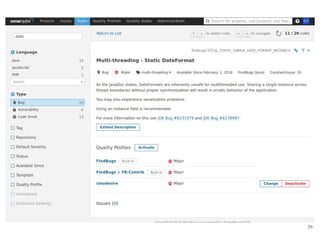
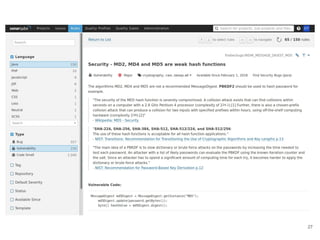
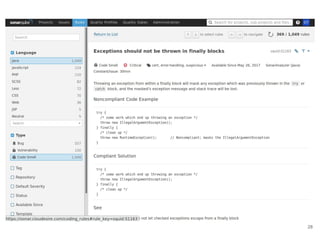



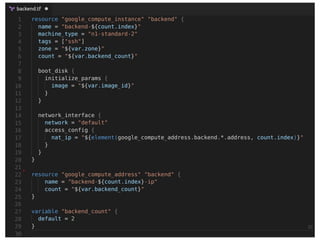


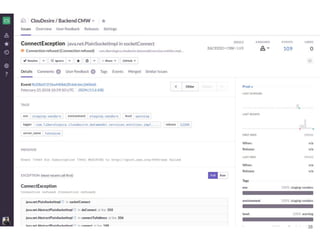
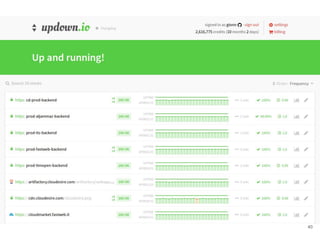
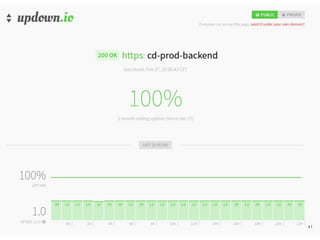
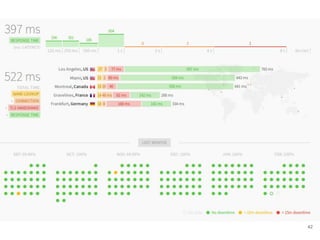

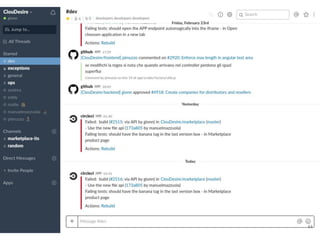
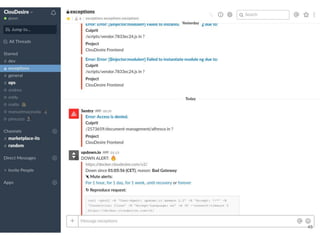
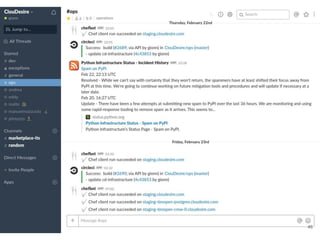
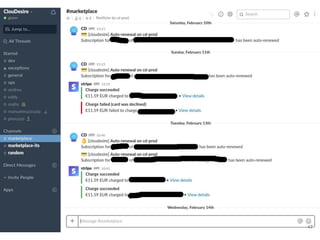
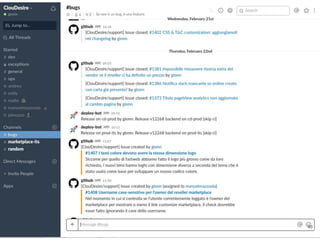

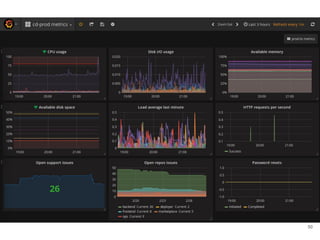
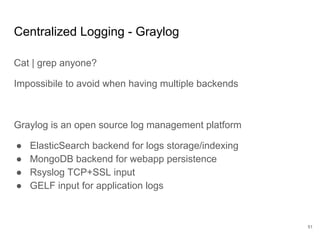



Continuous delivery is a software engineering approach where teams produce software in short cycles to ensure the software can be reliably released at any time. This allows for more incremental updates to applications in production. The document discusses the tools and processes used by Cloudesire to implement continuous delivery practices, including GitHub for issue tracking, CircleCI for continuous integration, Docker for packaging, Chef for configuration management, and various other tools for monitoring, logging, and metrics.






































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)








