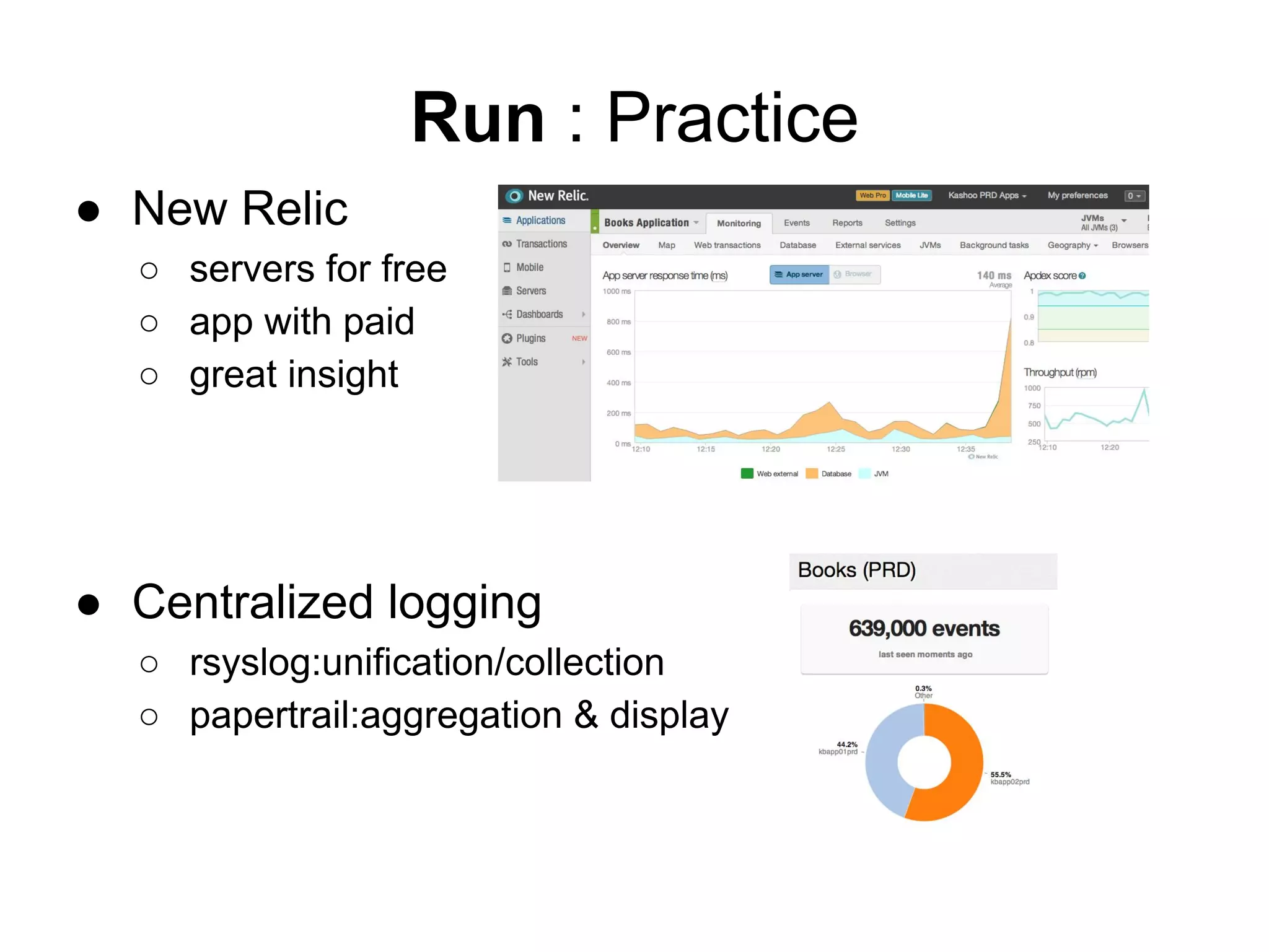
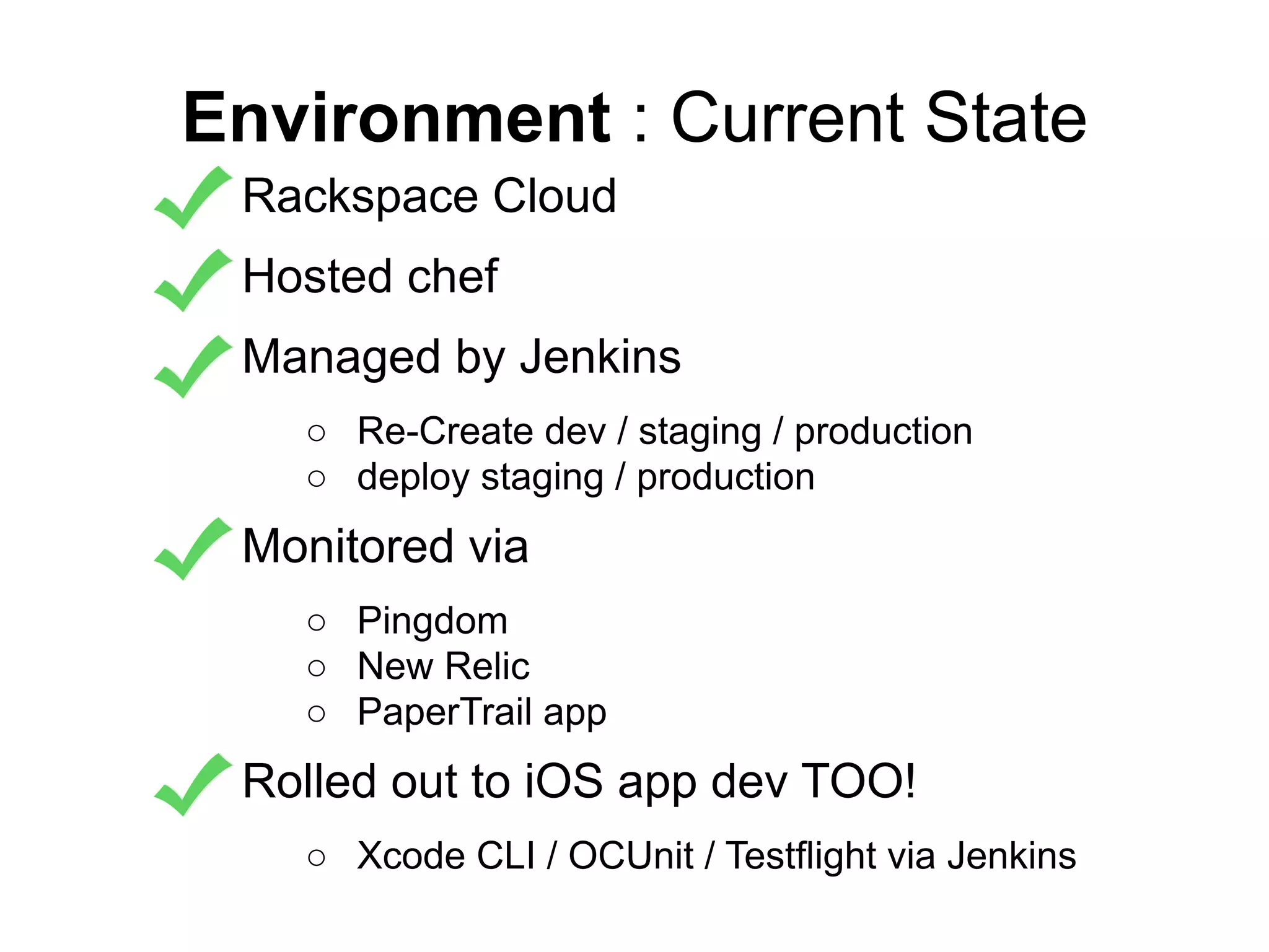
The document provides an overview of the theory, reality, and practical steps involved in implementing continuous delivery for an existing codebase and systems. It discusses improving the build process to make it reproducible and automated. It also covers deploying code in a zero-downtime manner, monitoring applications, and setting up development, staging, and production environments using tools like Chef and Jenkins for automation and reproducibility. The goal is to iteratively refine processes to make them more continuous and reduce issues during code deployment.








![Deploy : Reality
● GOOD
○ Scripted (somewhat)
● NOT SO GOOD
○ Only from developers machine [FAIL!]
○ Ignored errors (FULL STEAM AHEAD)
○ Rsync of build outcome
○ Manual stop / start
○ Customers may see errors during rollout](https://image.slidesharecdn.com/2013-10-25devopsdays-190620170306/75/2013-10-25-dev-opsdays-9-2048.jpg)