
Download to read offline


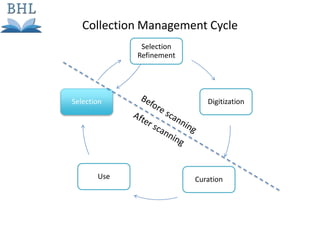


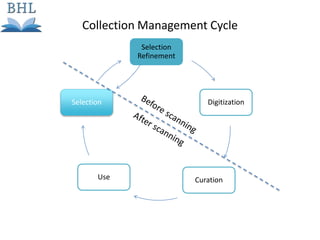


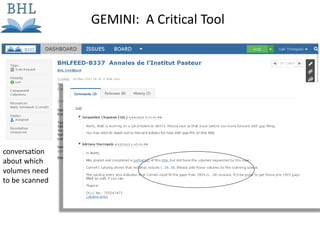
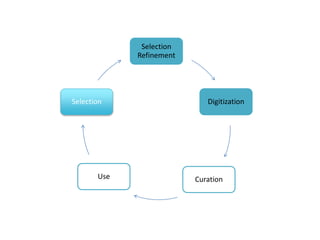


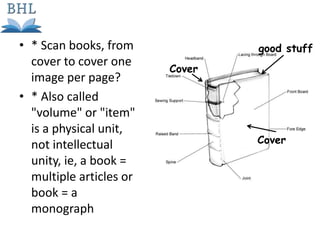


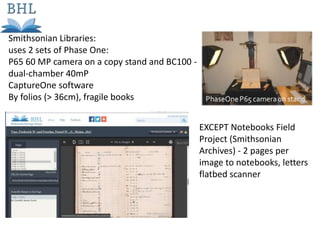

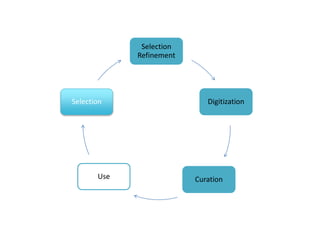
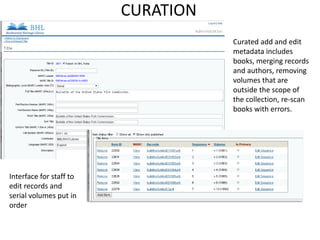
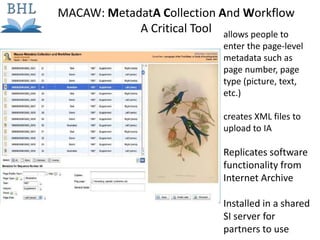



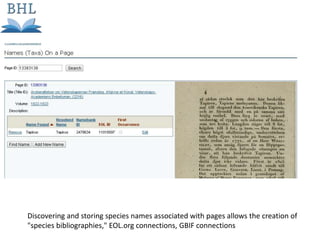
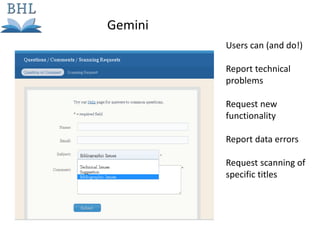
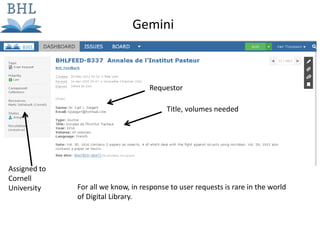
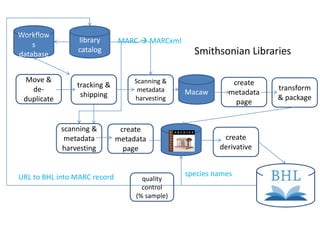

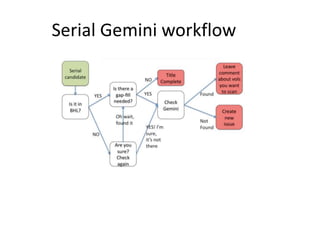
The document outlines the complexities of the digitization workflow for libraries, highlighting challenges such as the selection of scan-friendly books, metadata management, and the importance of accurate digital representations. It discusses the use of tools like Gemini and Macaw for curation and metadata collection, emphasizing their role in enhancing library processes. Additionally, it mentions collaborative efforts through shared resources like the Internet Archive to facilitate the scanning and preservation of library materials.
































![Gettingstartedwithdigitalcollectionsweb[1]](https://cdn.slidesharecdn.com/ss_thumbnails/gettingstartedwithdigitalcollectionsweb1-1227107163937370-9-thumbnail.jpg?width=640&height=640&fit=bounds)







































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)












