Downloaded 19 times


















![Ranking
Ranking by Similarity
each short text 𝑠𝑡𝑖 assigned to 𝐶𝐿𝑙 has a similarity score, we can rank
them directly by their scores
Ranking with Diversity
diversify the short texts by subtopic Proportionality(PM-2) [12]
26](https://image.slidesharecdn.com/concept-basedshorttextclassificationandranking-150520180231-lva1-app6892/75/Concept-based-short-text-classification-and-ranking-26-2048.jpg)



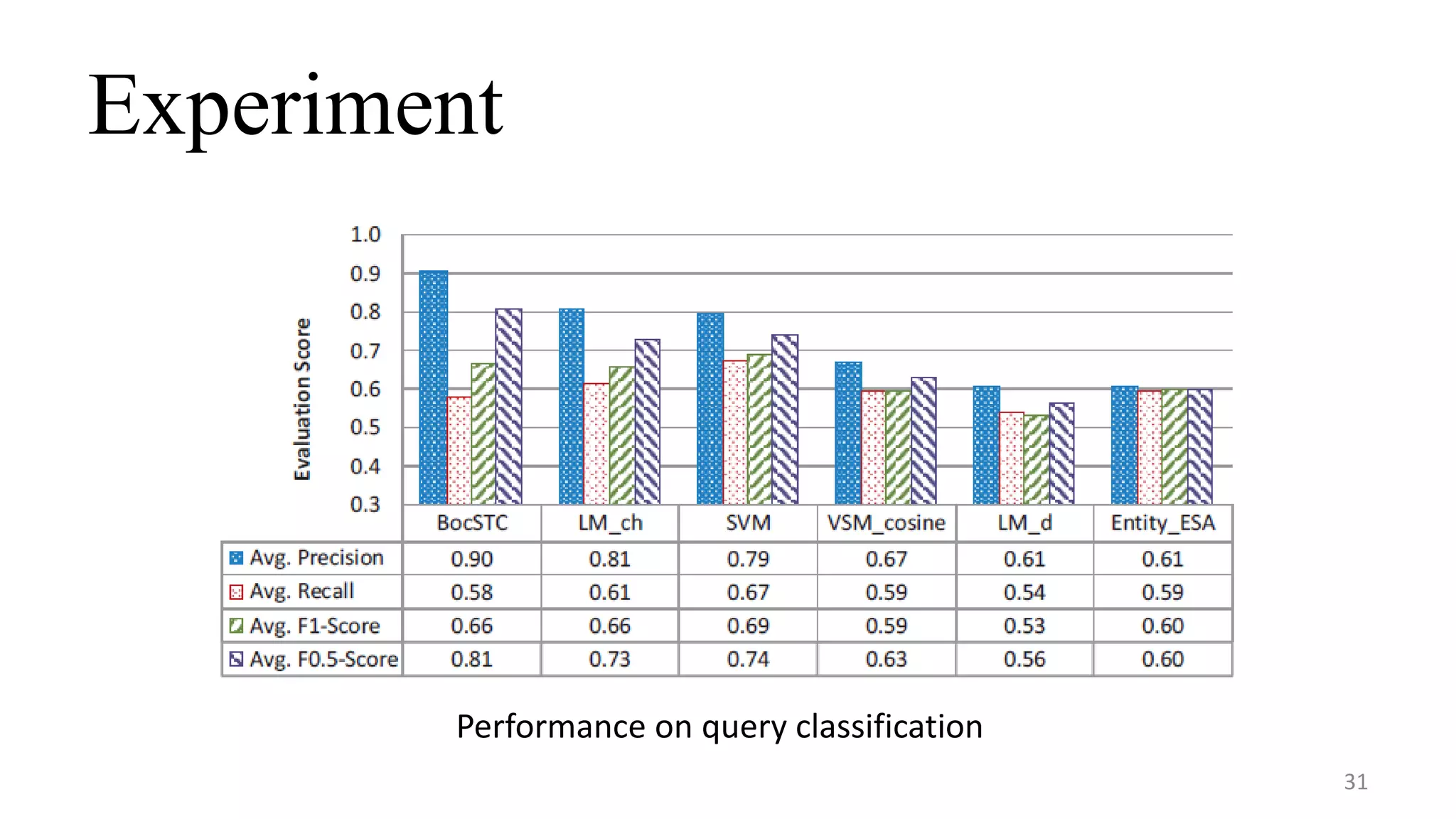
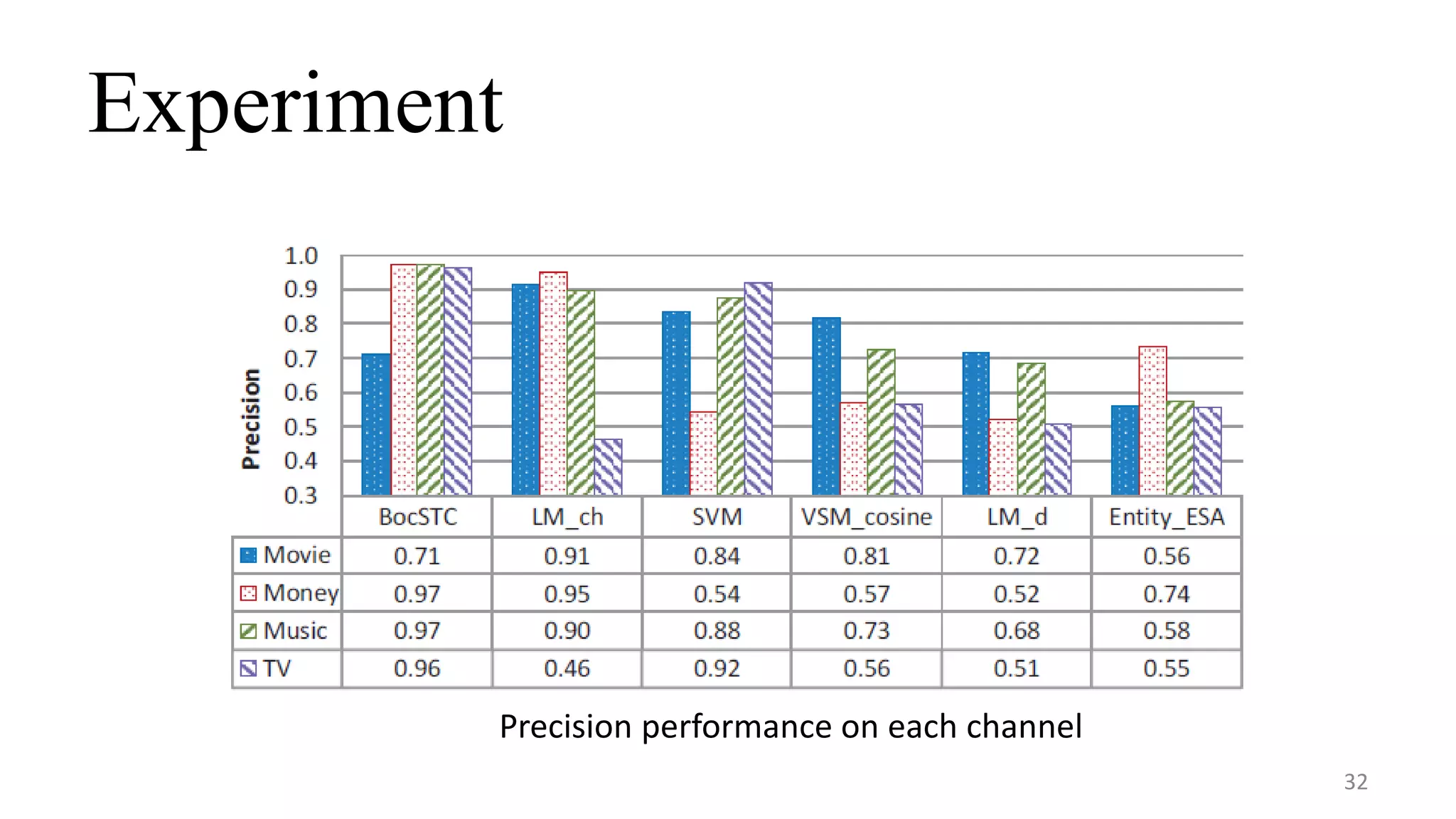
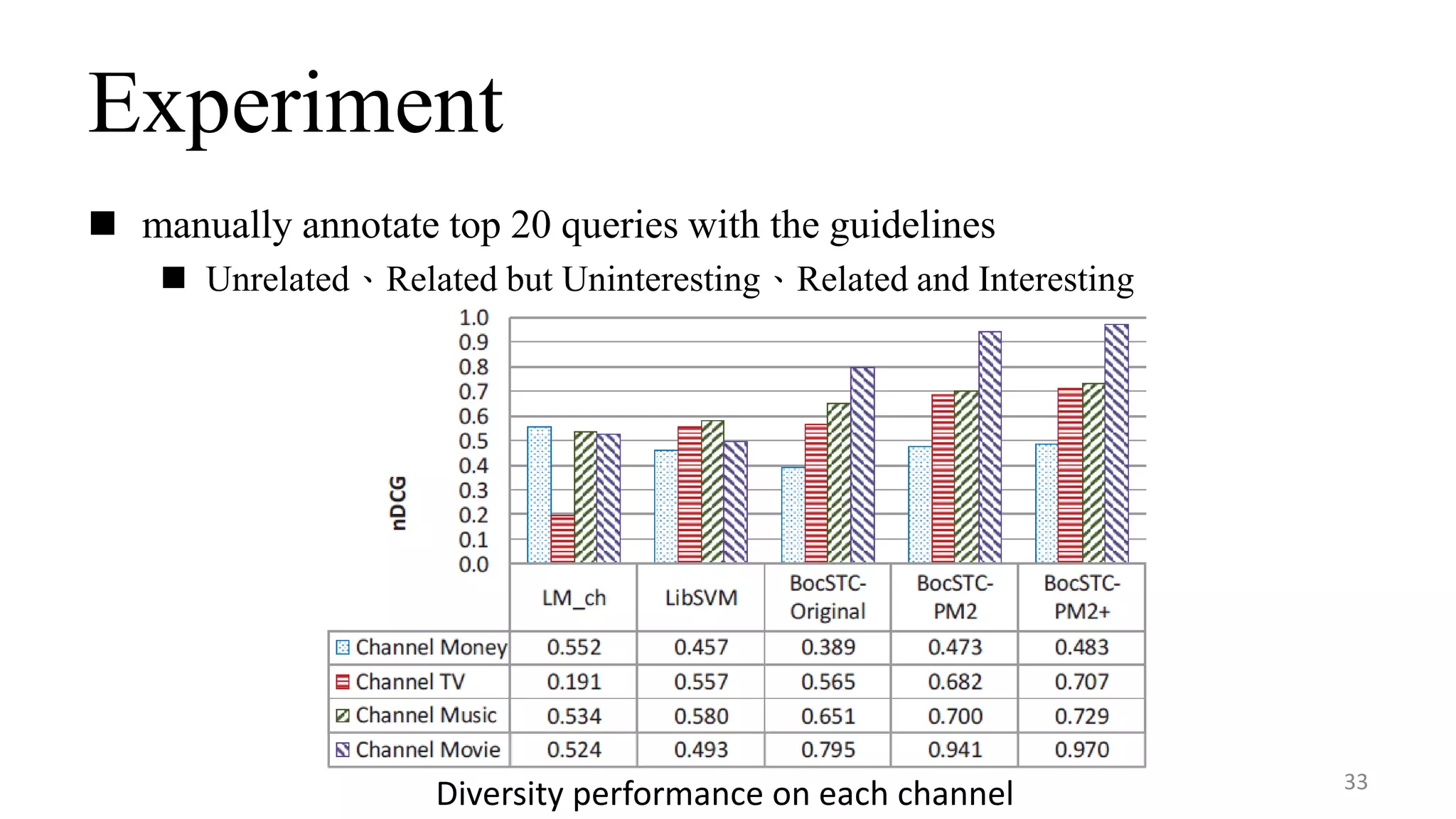




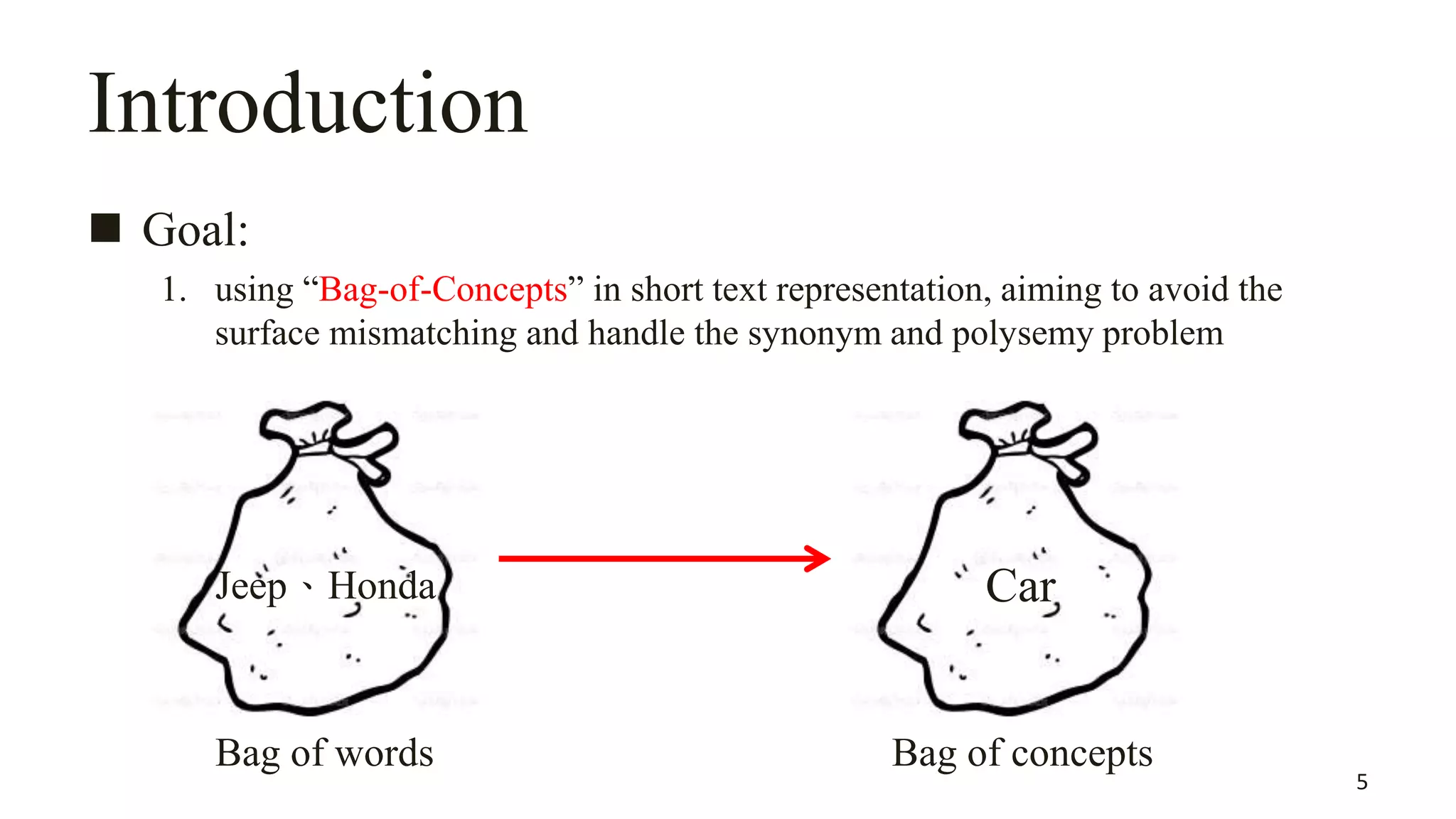
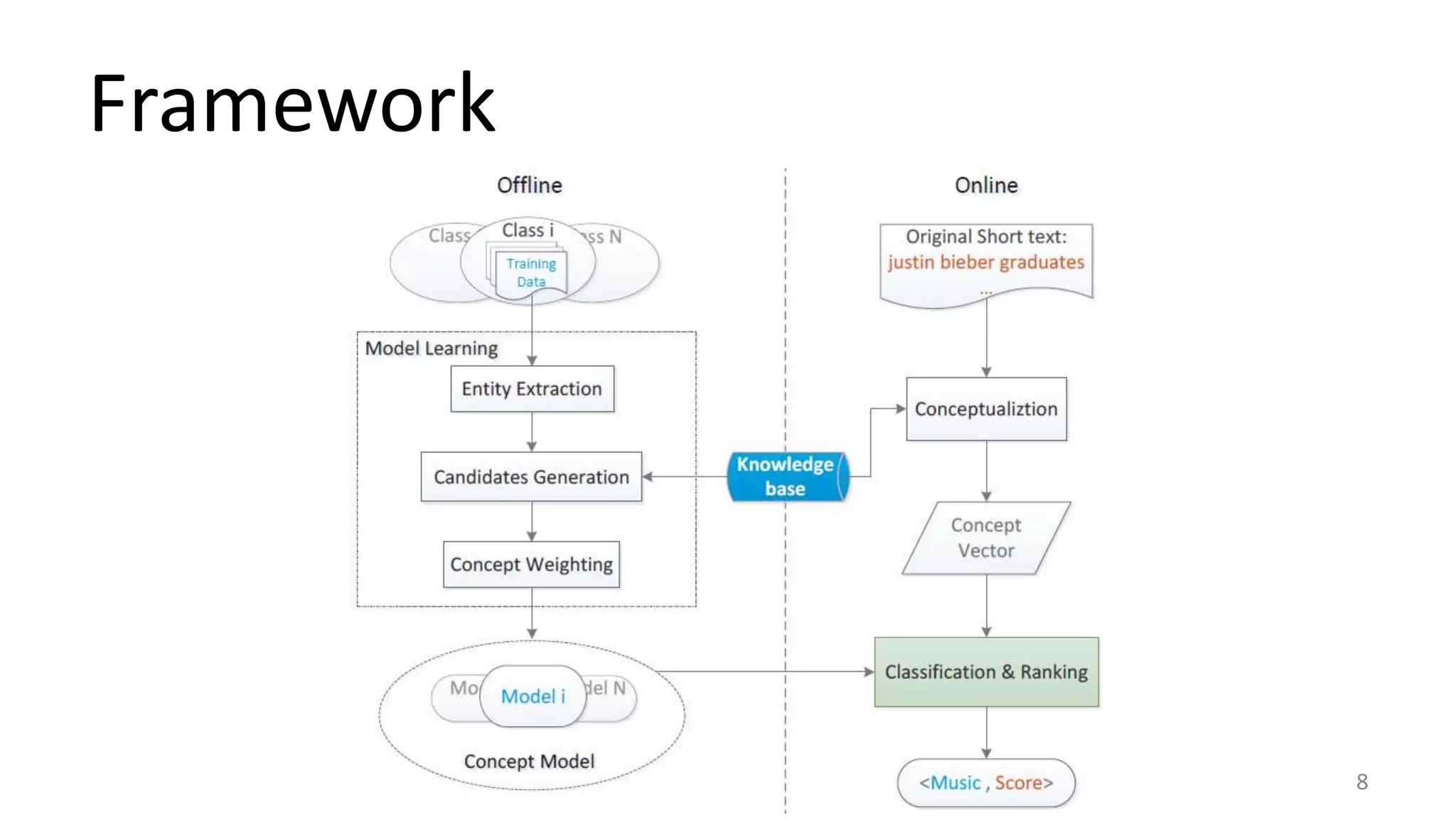
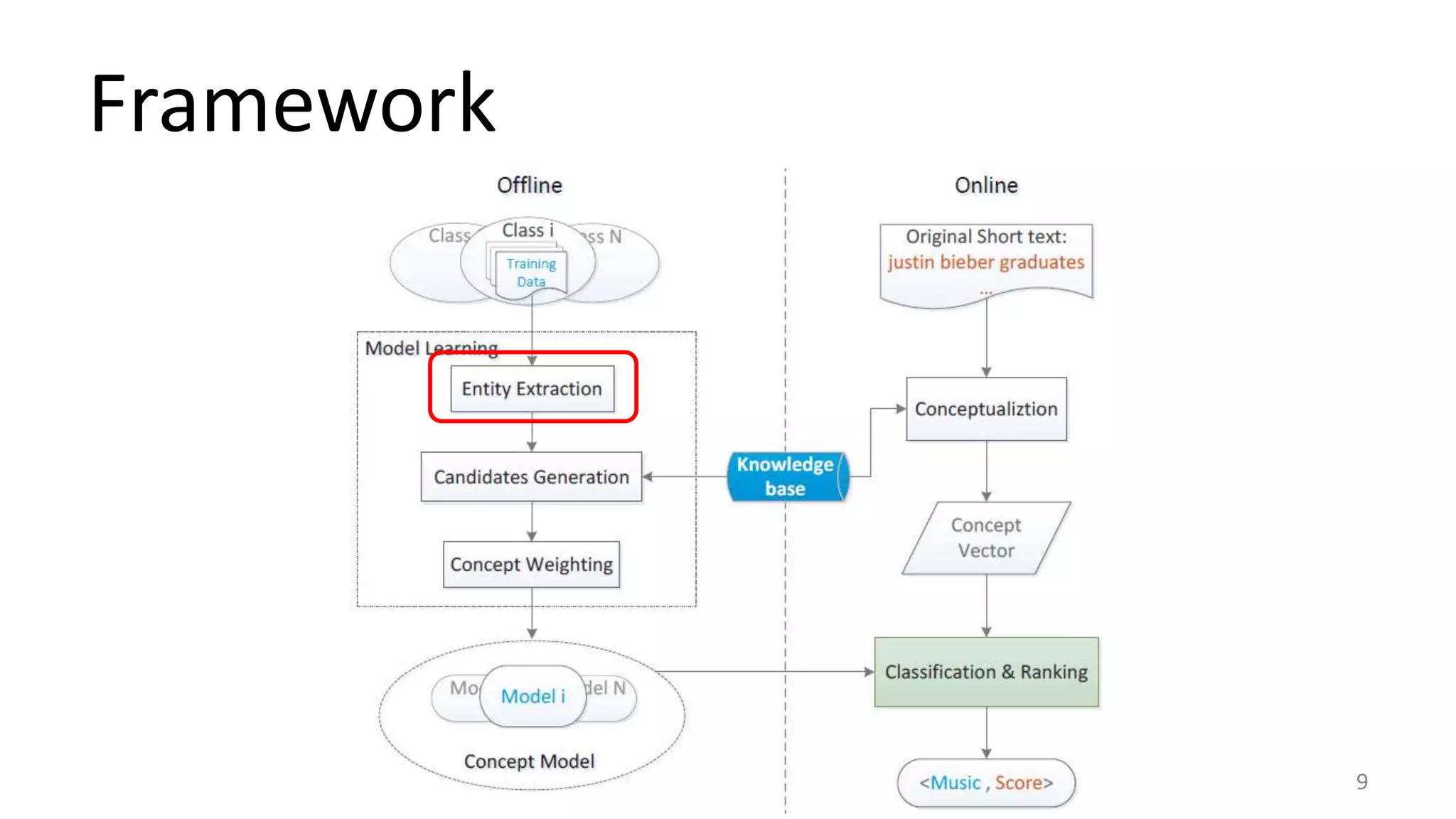
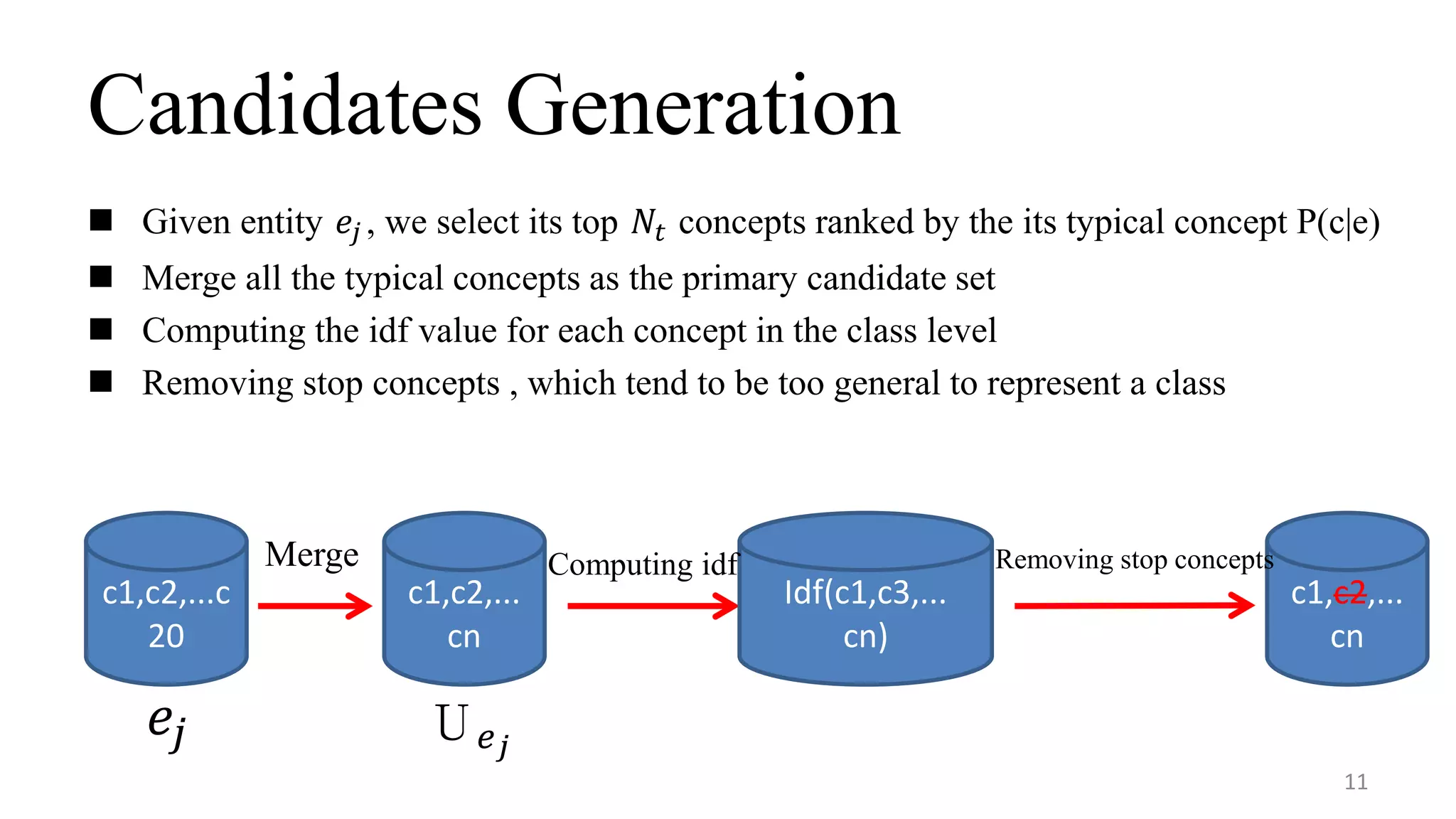
This document summarizes a research paper on concept-based short text classification and ranking. It presents a framework that represents short texts as bags of concepts rather than bags of words to address issues of surface mismatching. The method involves entity recognition in texts, generating candidate concepts, weighting concepts, disambiguating ambiguous entities using unambiguous contexts, classifying texts based on conceptual similarity, and ranking texts. An experiment applies the framework to query recommendation for different channels, achieving good performance on classification precision and diversity ranking.







































































