Download to read offline










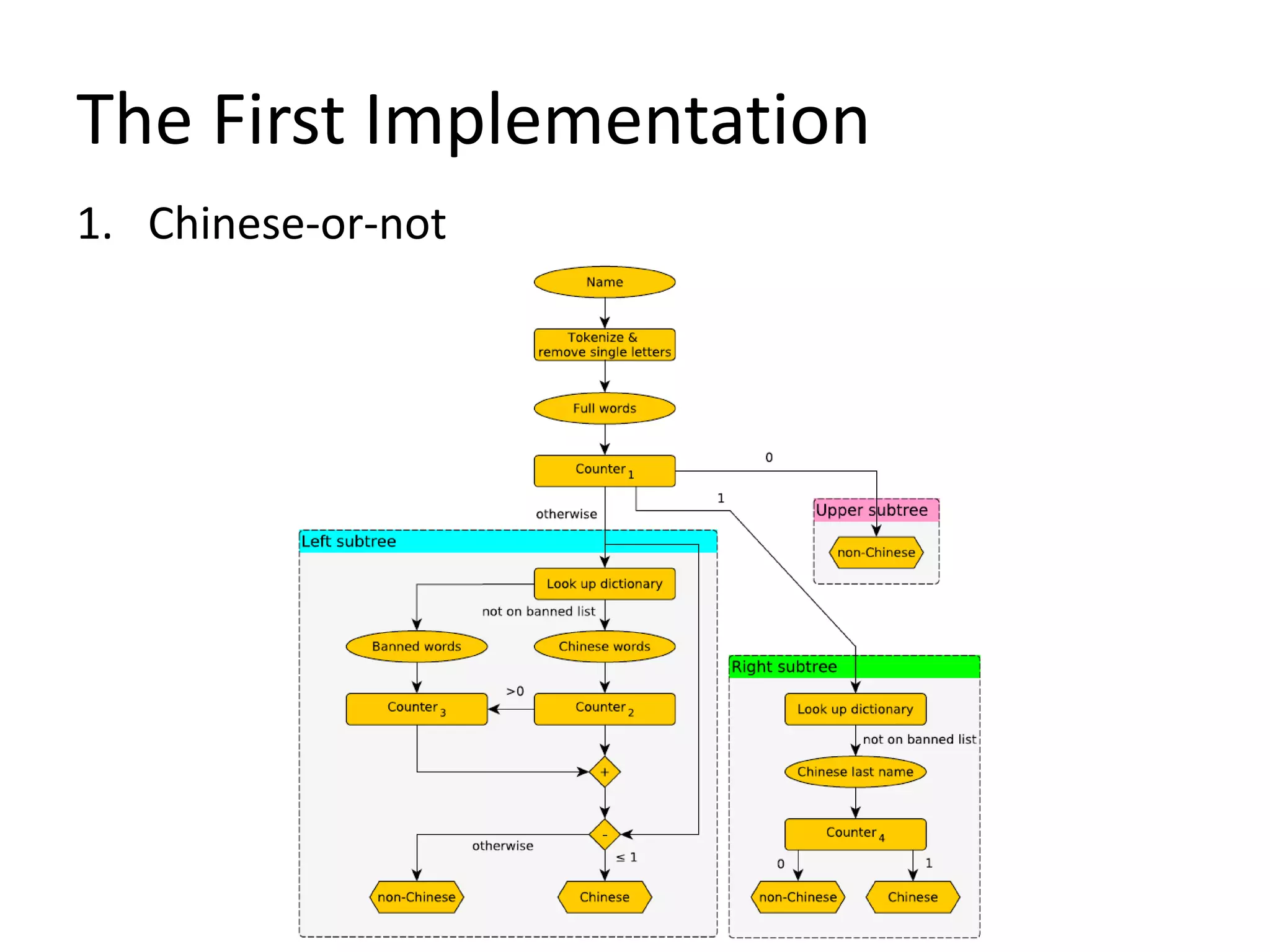






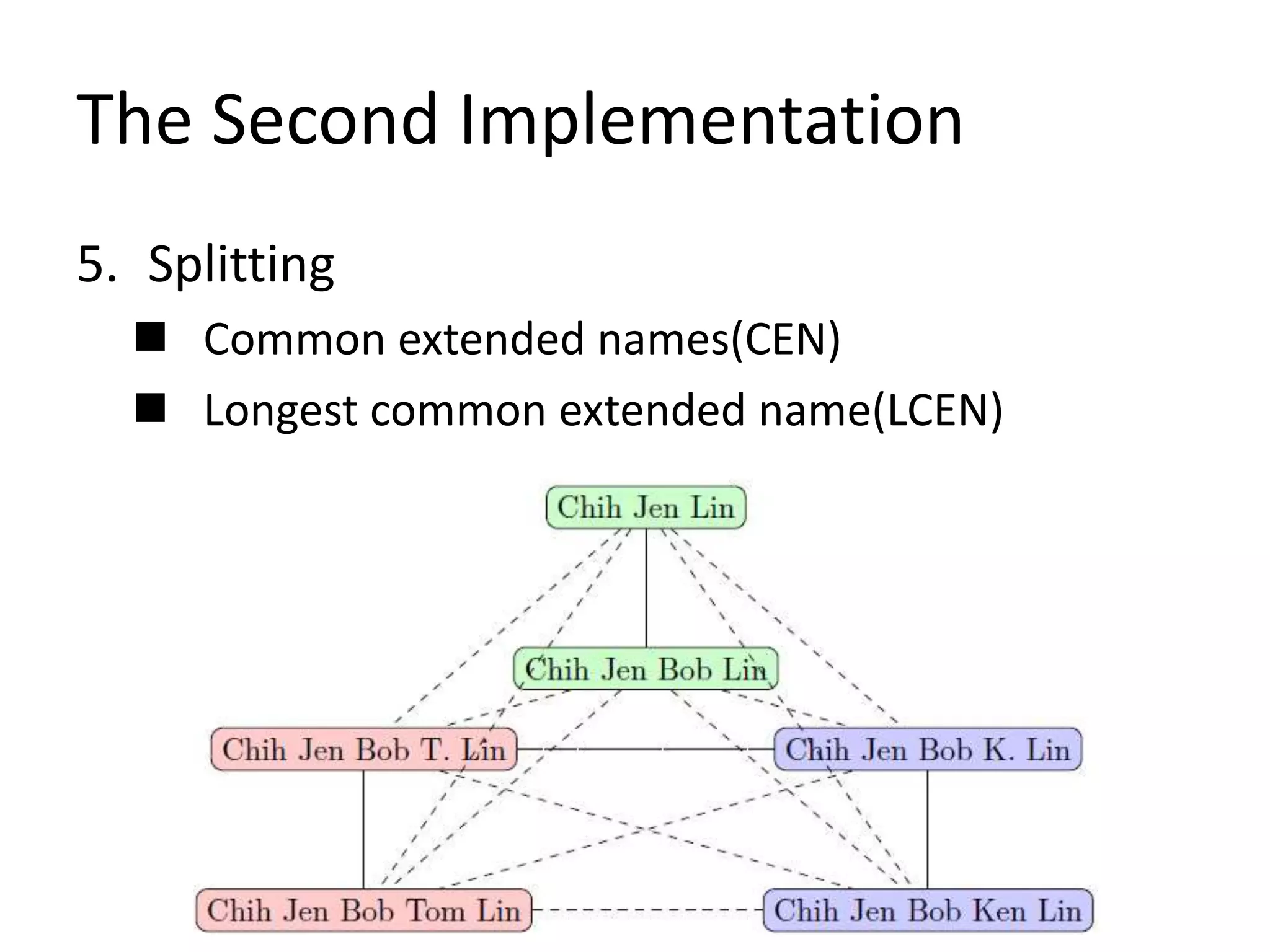




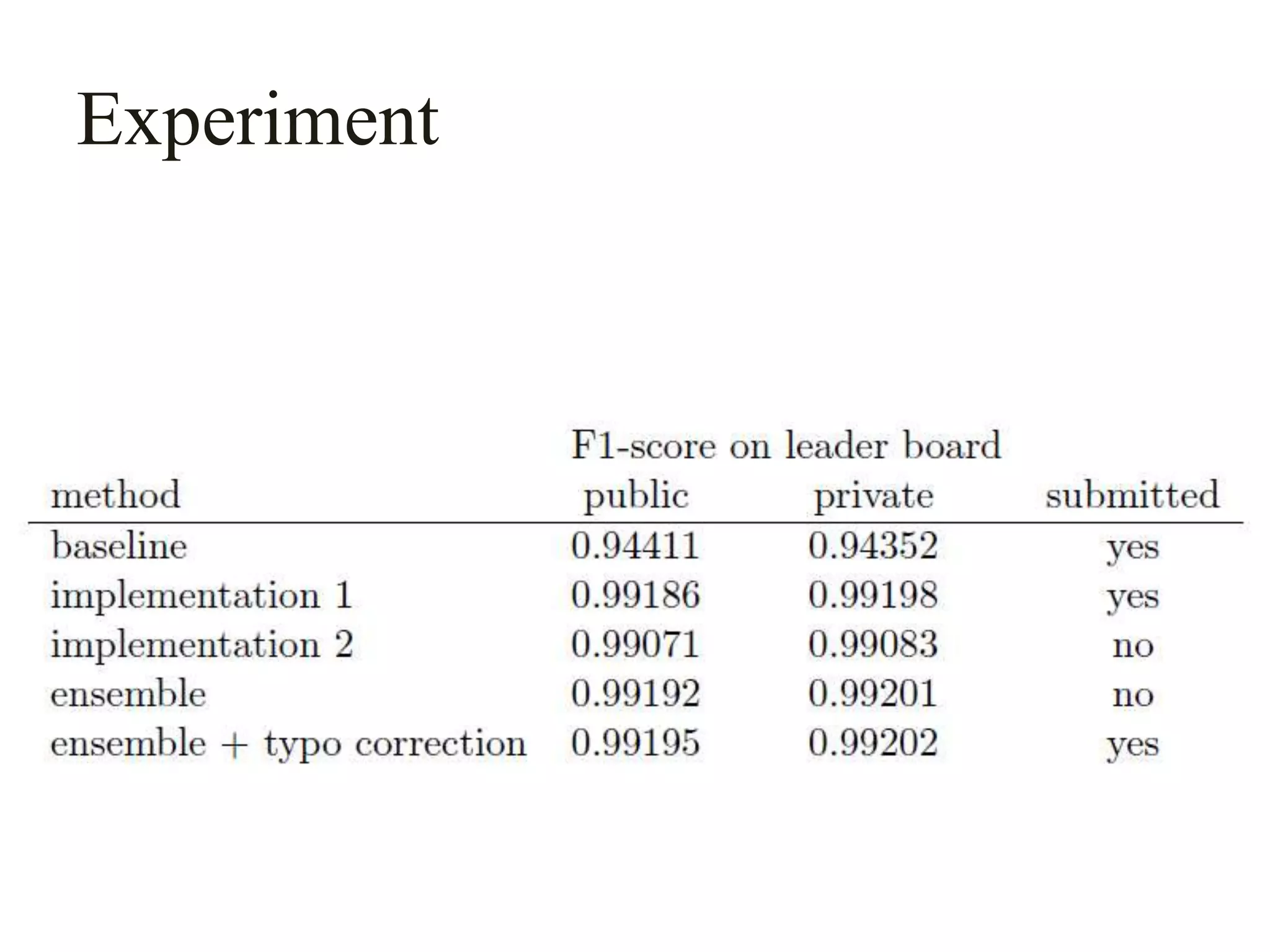
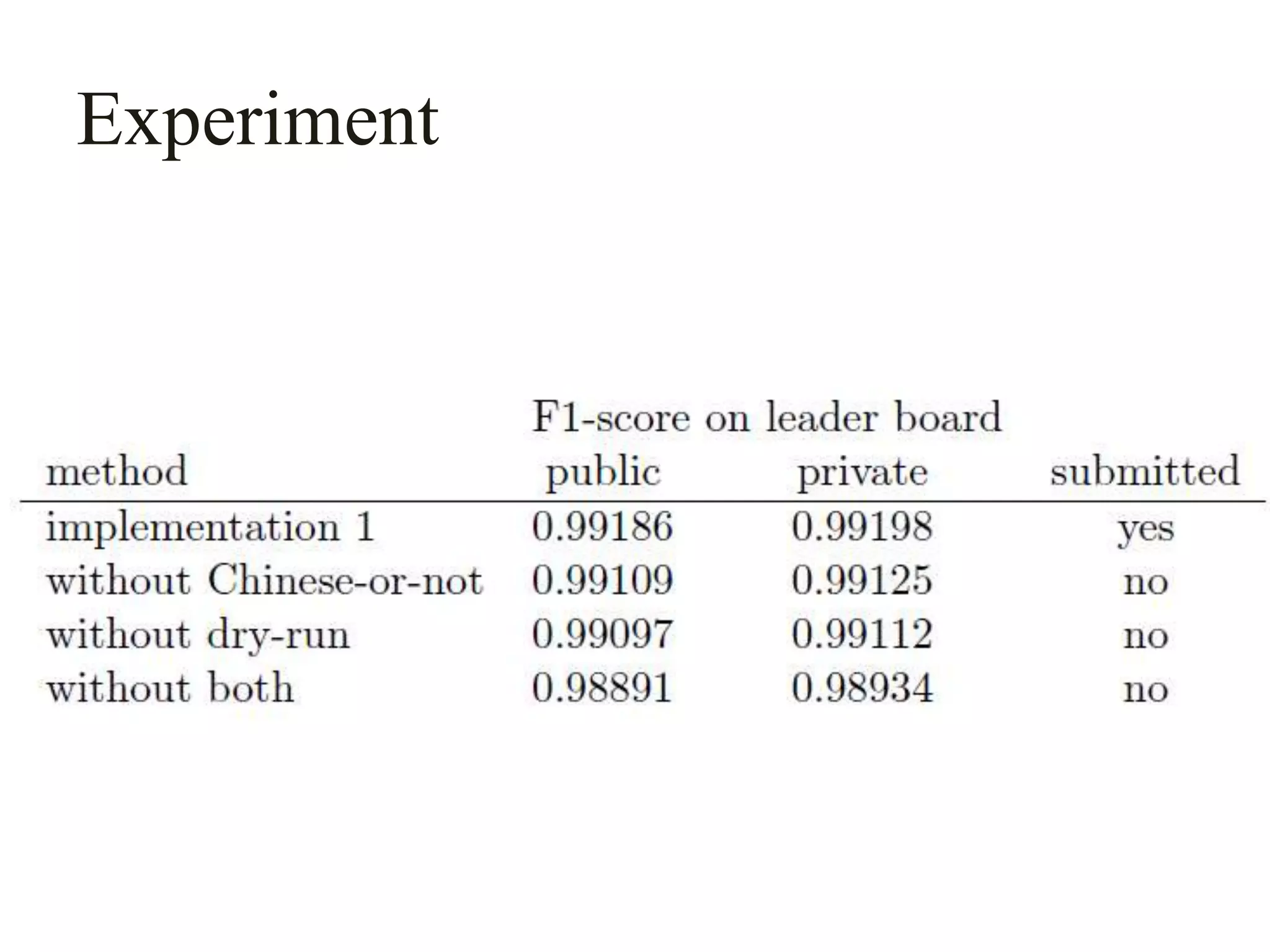



This document describes a method for author disambiguation that uses effective string processing and matching. It presents strategies like identifying duplicates based on string matching and classifying authors as Chinese or non-Chinese. It also describes a framework involving cleaning names, selecting authors, identifying duplicates, splitting groups, and linking identifiers. Two implementations of the framework are discussed in detail, and an ensemble approach is presented to improve performance.
























