Download to read offline







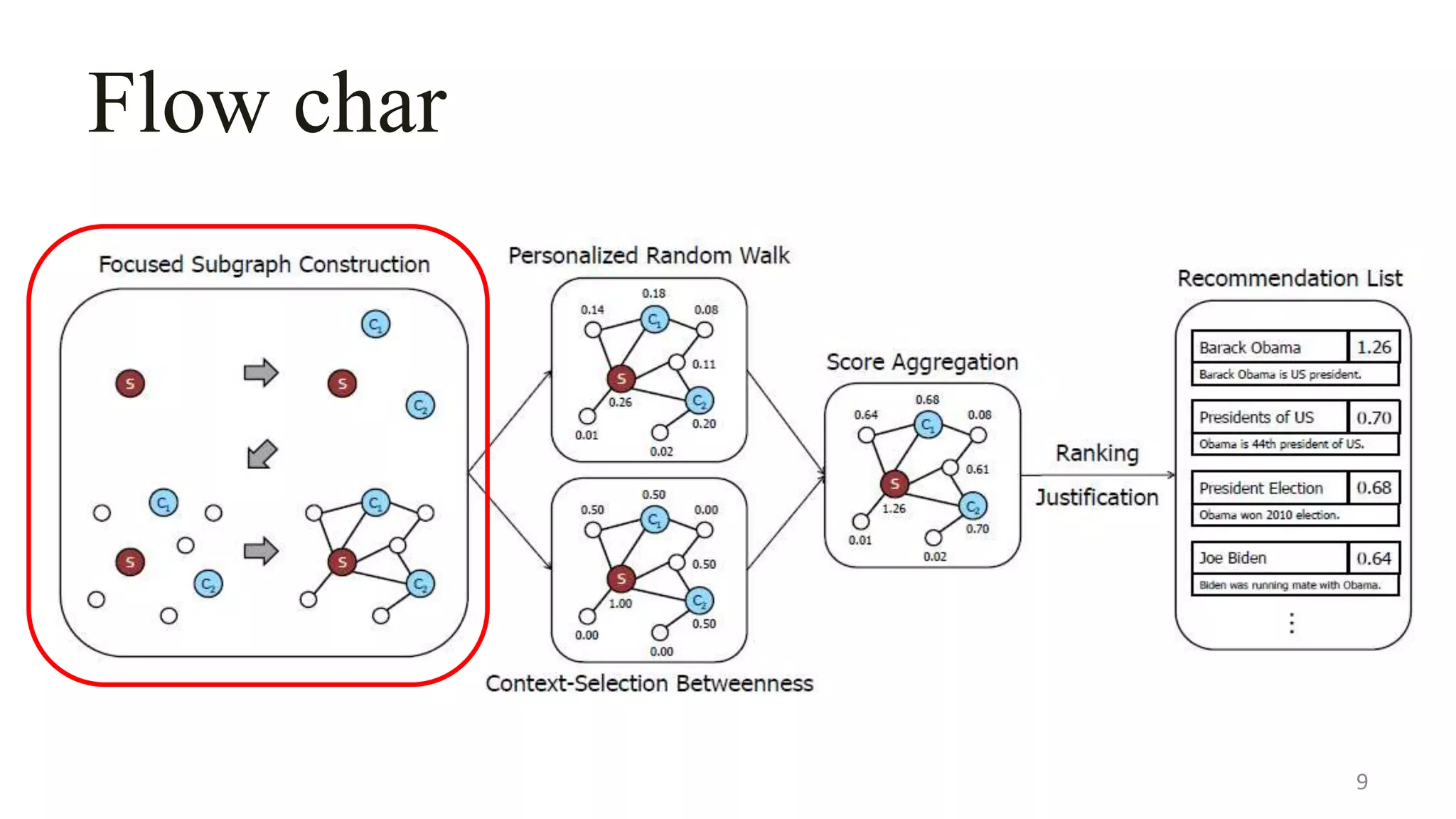
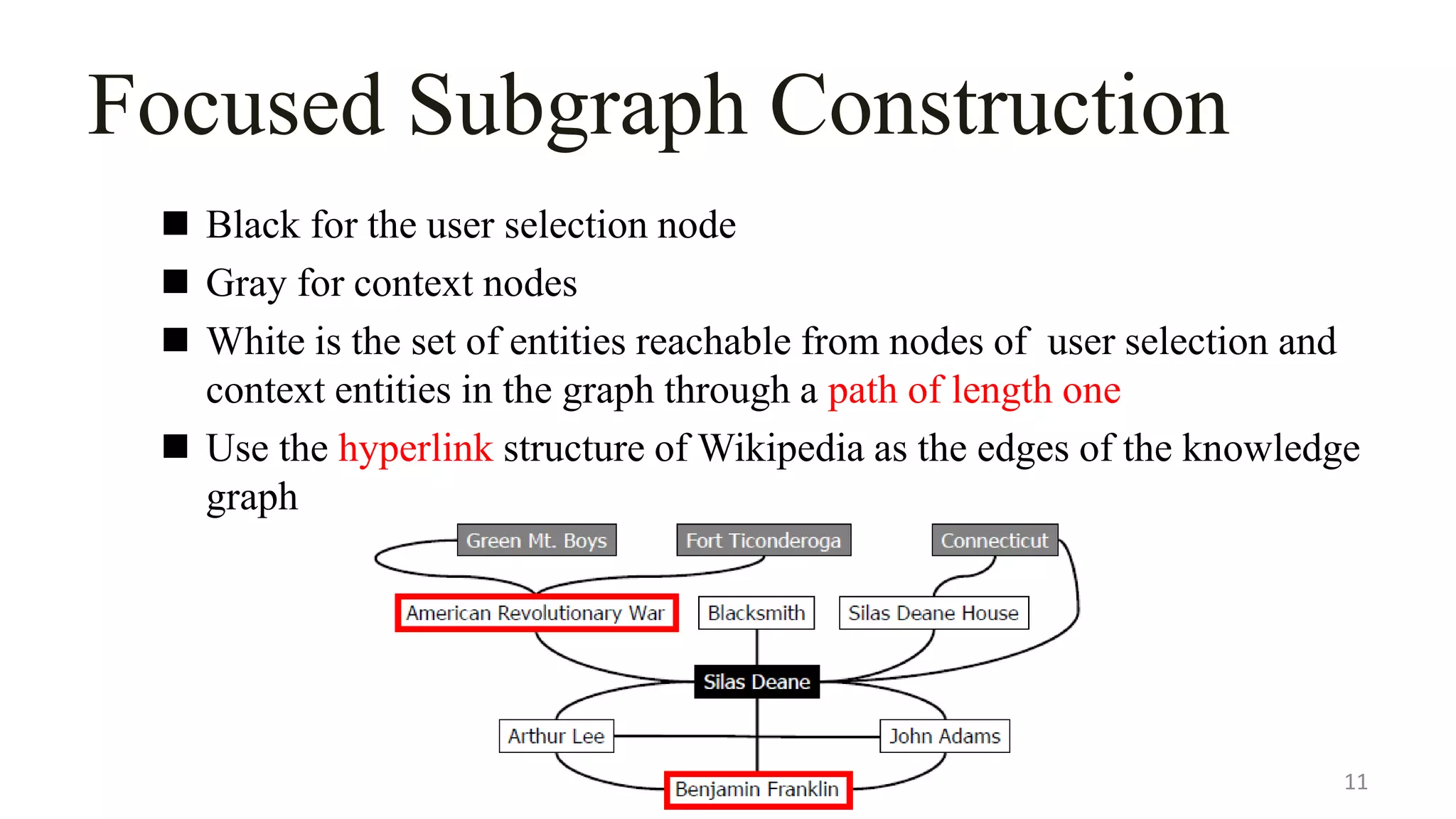
![Focused Subgraph Construction
Mapping the user selection S and the context C to nodes in the
knowledge graph
Any off-the-shelf entity linking system[9]
10](https://image.slidesharecdn.com/leveragingknowledgebases-150905174826-lva1-app6891/75/Leveraging-Knowledge-Bases-for-Contextual-Entity-Exploration-Categories-10-2048.jpg)
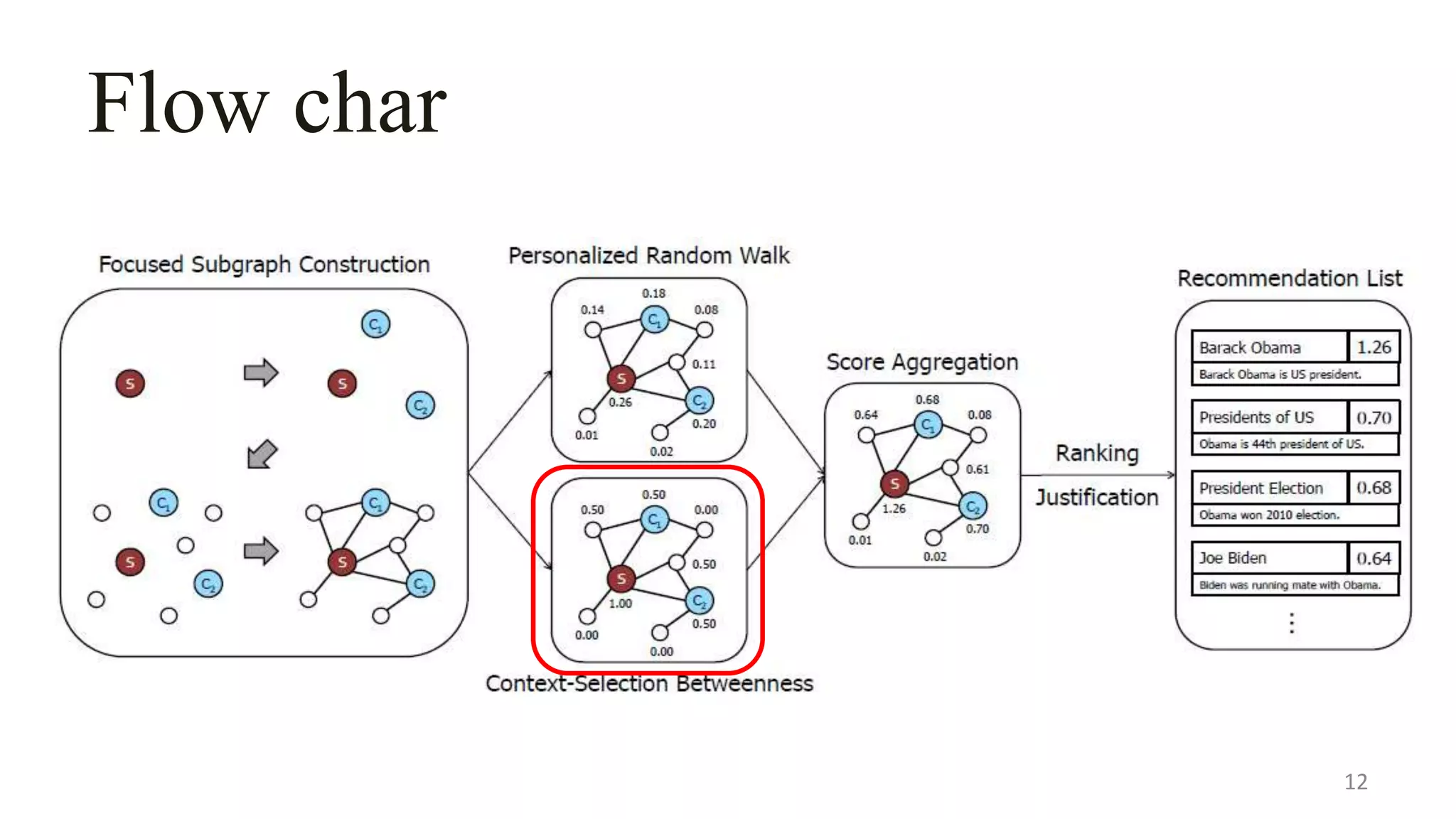


![Personalized Random Walk
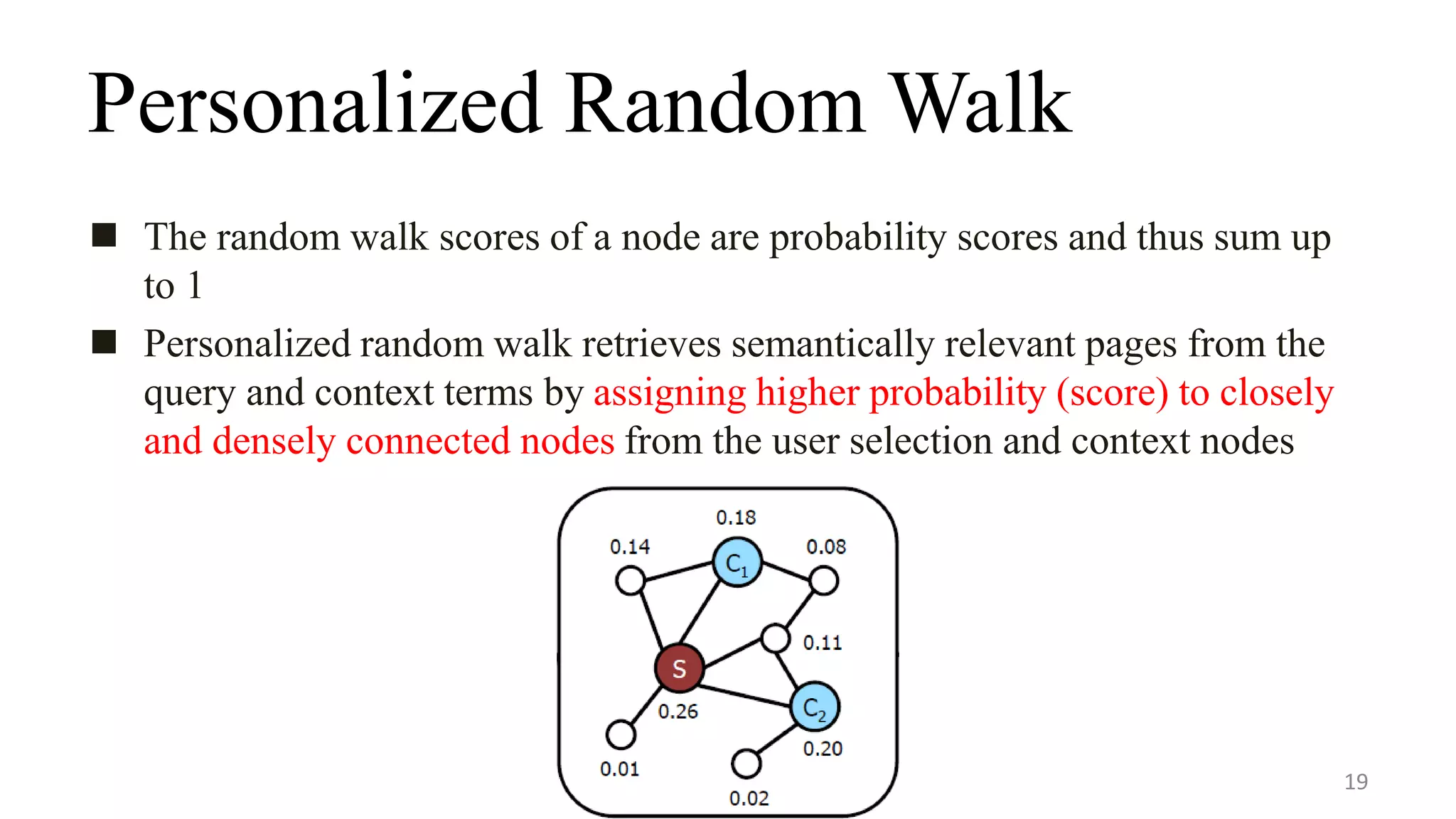
The random walk[41] is simulating the behavior of a user
reading articles
18](https://image.slidesharecdn.com/leveragingknowledgebases-150905174826-lva1-app6891/75/Leveraging-Knowledge-Bases-for-Contextual-Entity-Exploration-Categories-18-2048.jpg)
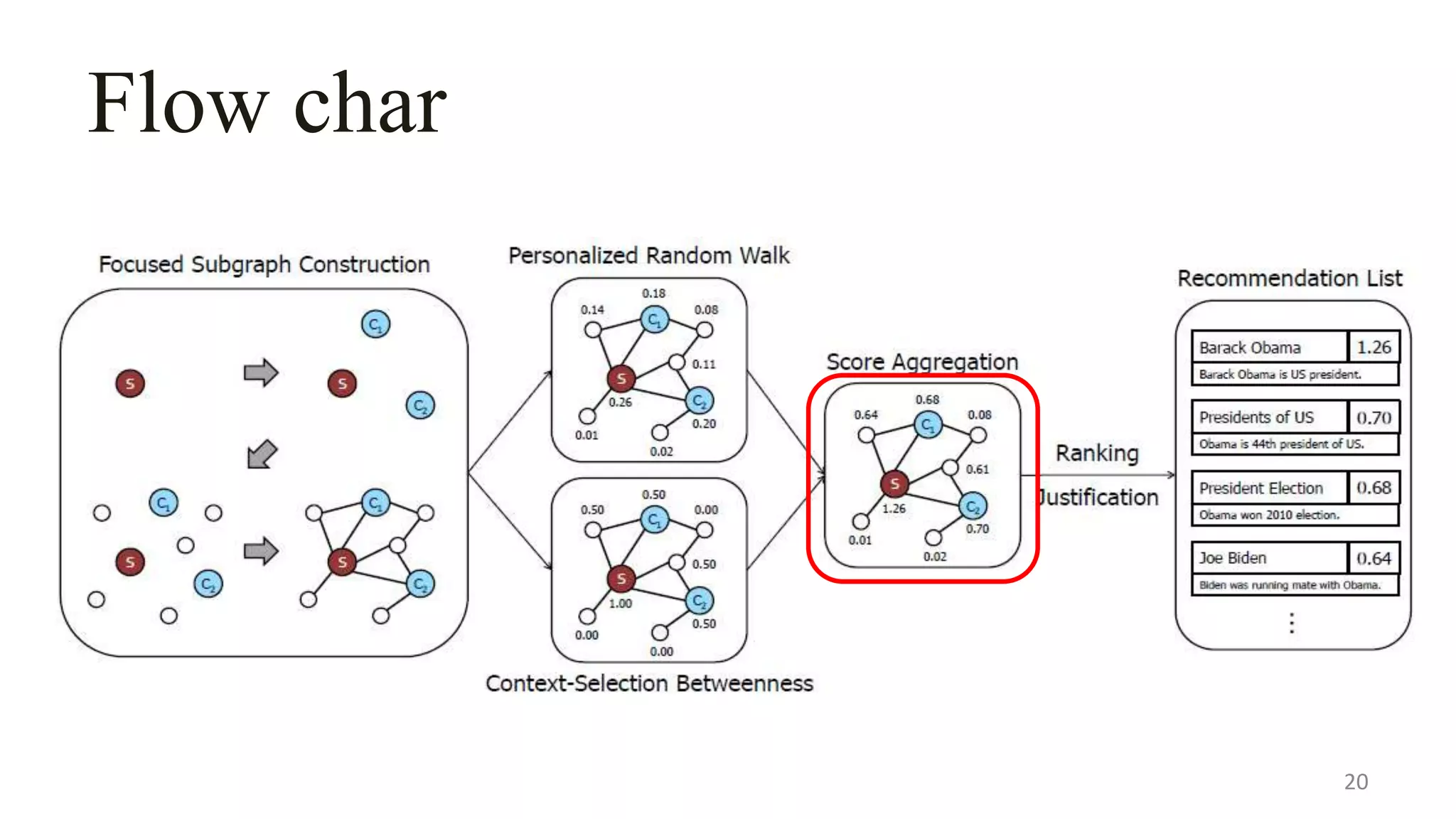


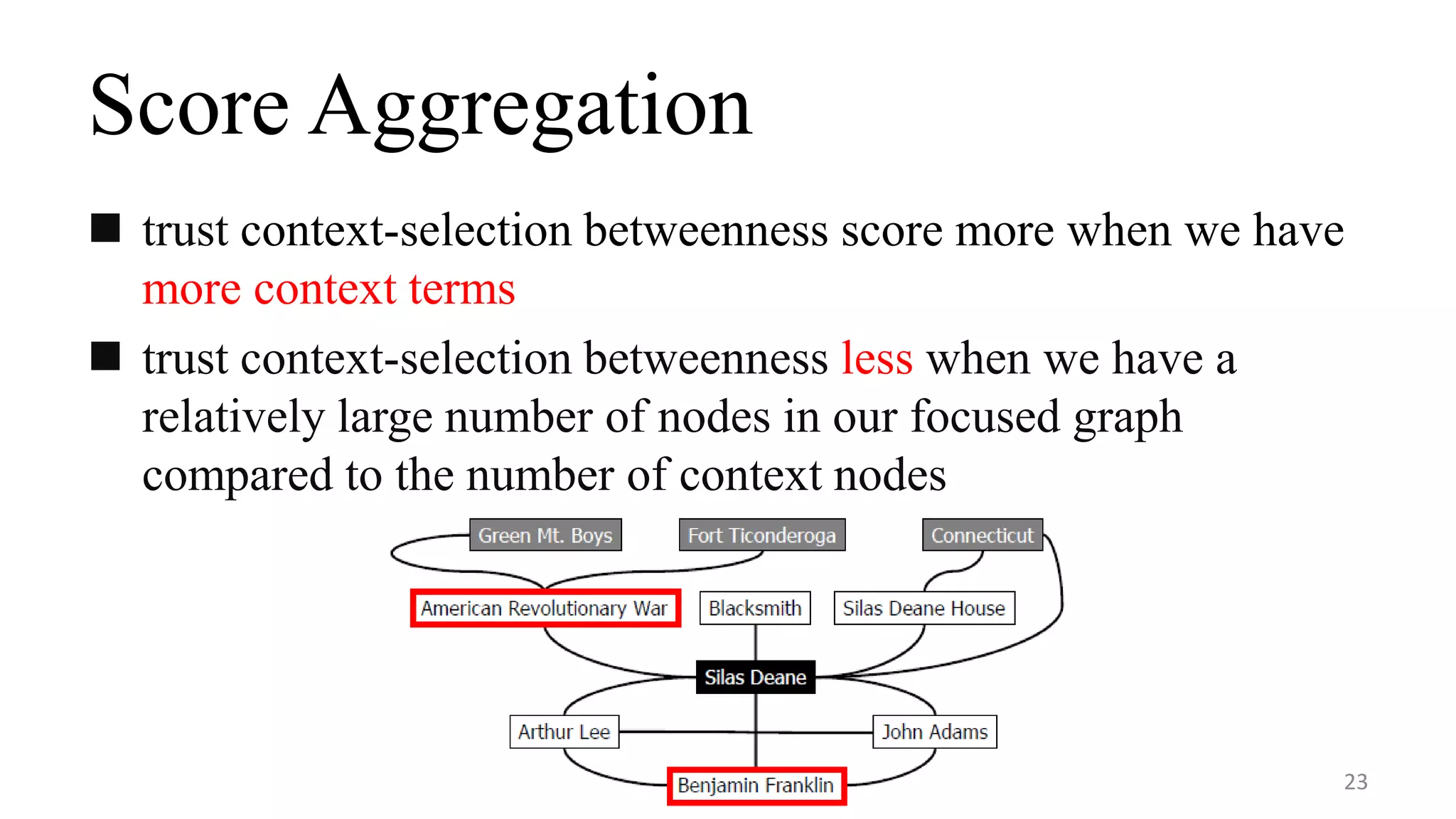





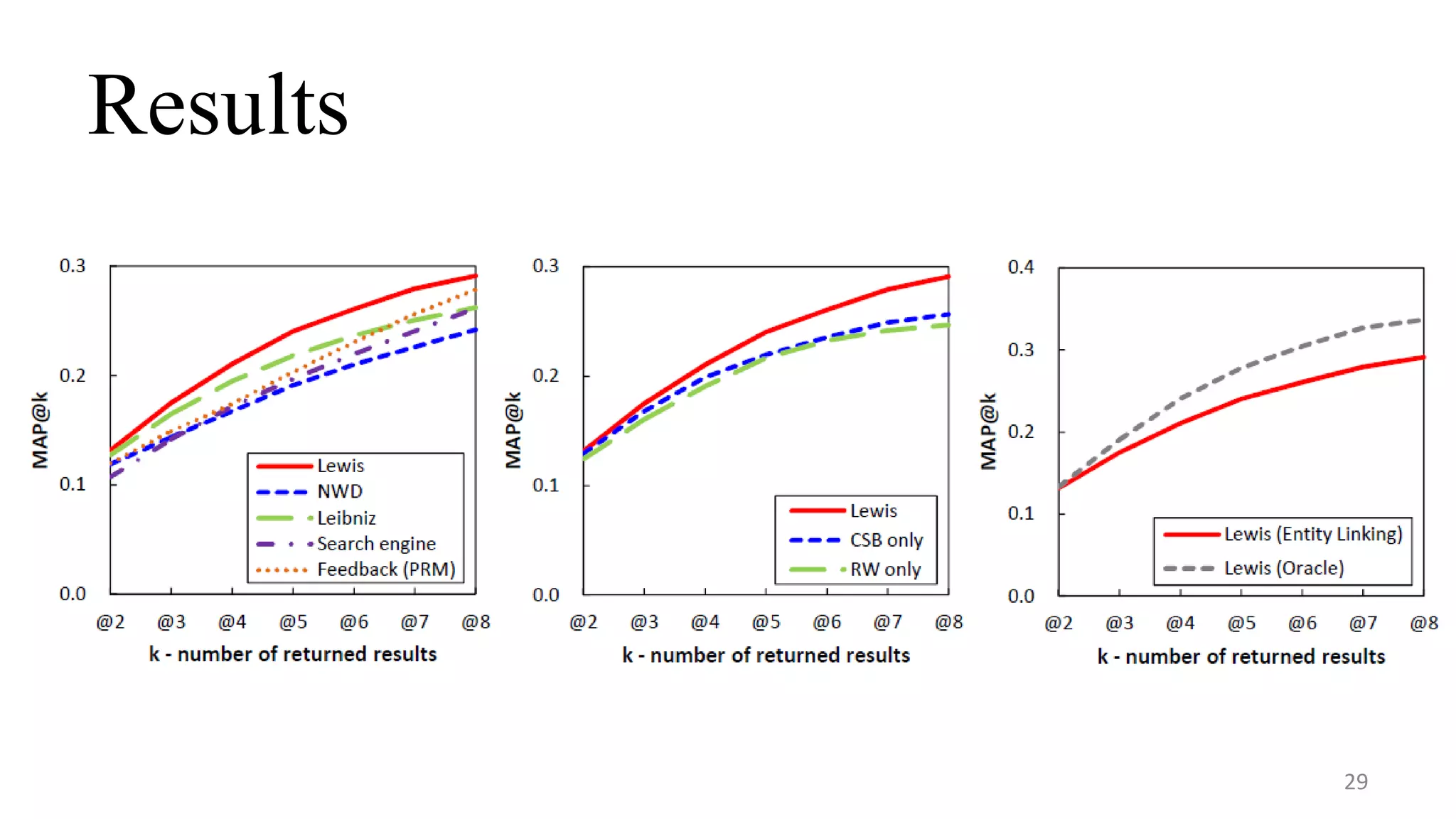

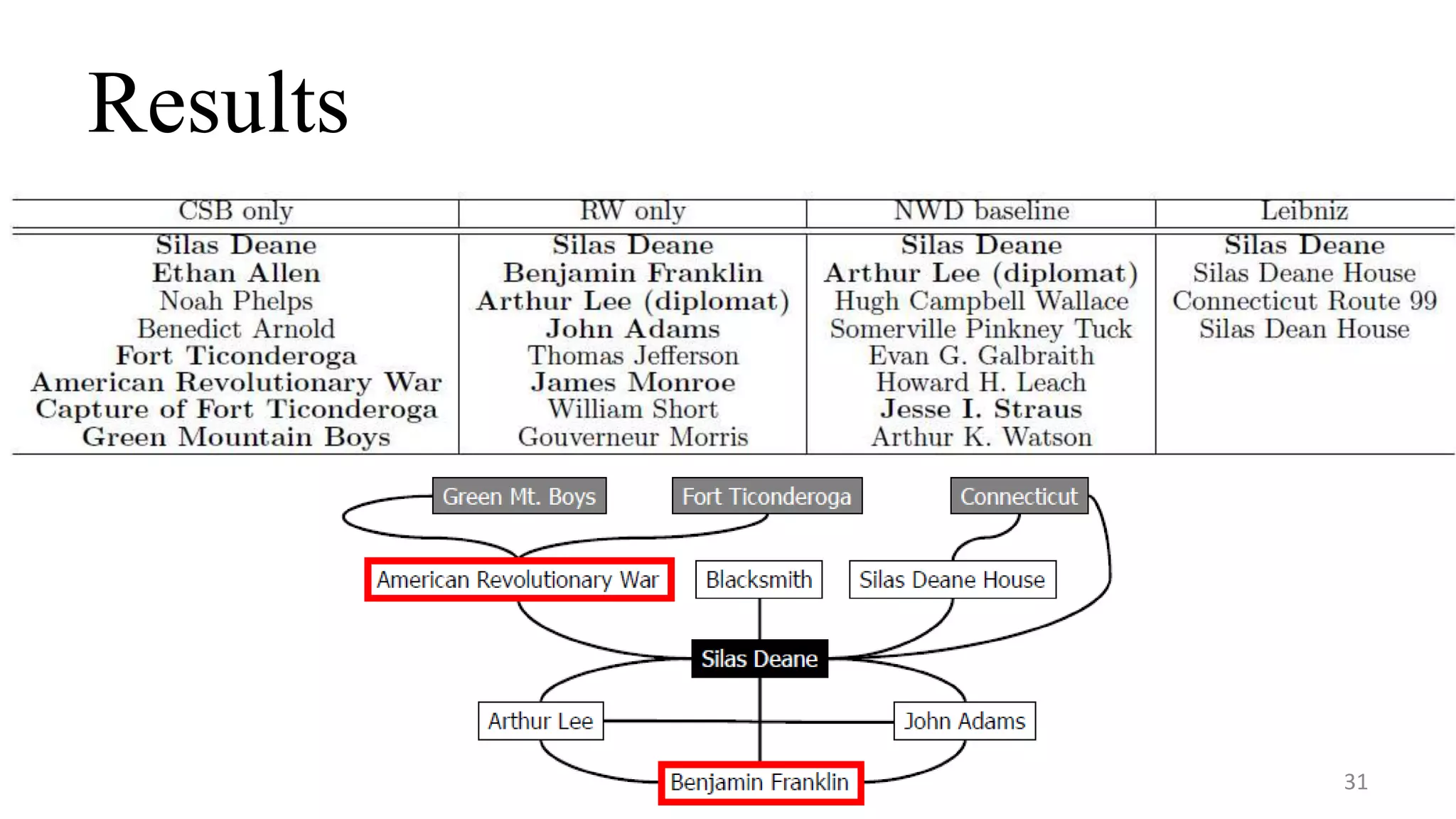





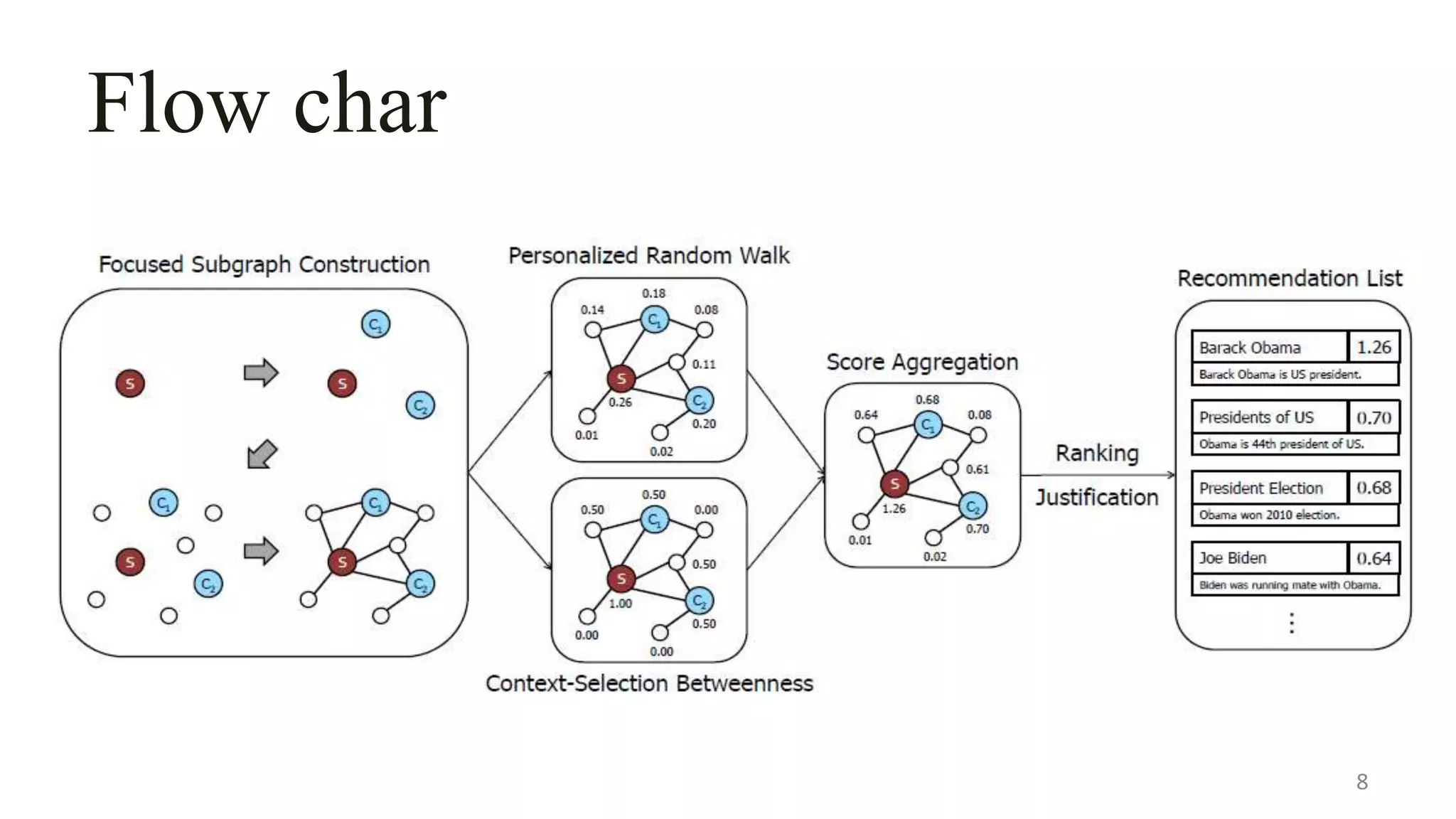
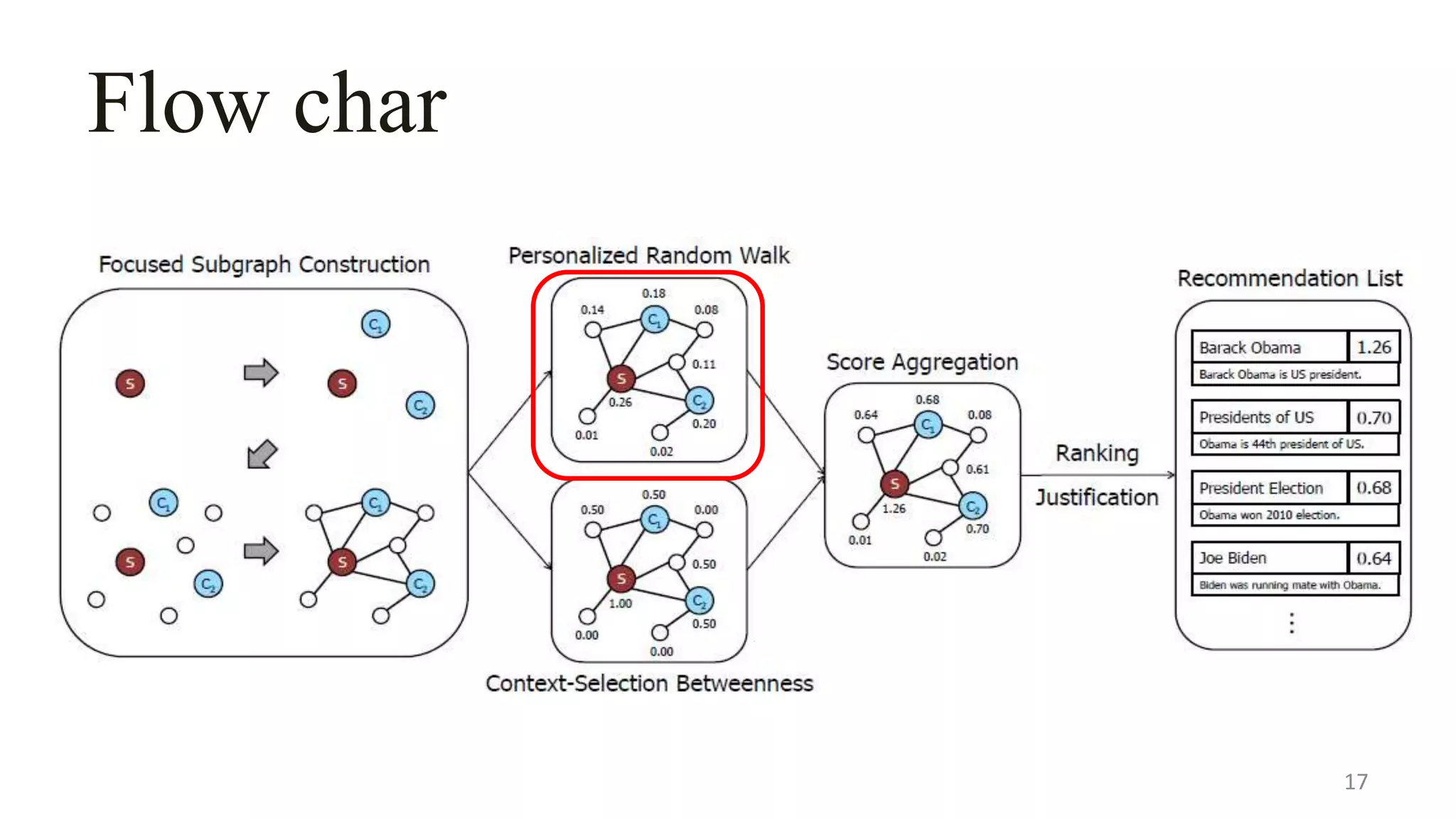
This document describes a system called Lewis for retrieving contextually relevant entity results from knowledge bases. It introduces three methods: (1) focused subgraph construction to identify relevant entities from the knowledge graph; (2) context-selection betweenness to measure how entities bridge the user selection and context; and (3) personalized random walks to score entities based on their connections. An experiment on 2600 textbooks showed Lewis significantly outperformed baselines by providing more relevant results to users based on their selections and contexts.













































![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
