Download to read offline




























![Stress Rules Main Stress Rule (cyclic) 1. V -> [1-stress] / X – C 0 {[short v] C 0 1 / V} {[short V] C 0 / V} where X contains all prefixes and the symbol ‘-’ indicates the position of the vowel to be stressed C 0 1 matches zero or one consonant C 0 matches any number of consonants (including none) {..} denotes a list of alternative patterns separated by slashes /. Assign 1-stress (primary stress) to the vowel in a syllable which precedes a weak syllable followed by a morph-final syllable containing a short vowel and zero or more consonants. e.g. difficult - > d ” i f i k a l t X – C 0 {..} {…}](https://image.slidesharecdn.com/coms30123synthesis3projector-1225480518935081-9/75/Coms30123-Synthesis-3-Projector-38-2048.jpg)
![V -> [1-stress] / X – C 0 {[short v] C 0 1 / V} {[short V] C 0 / V} where X contains all prefixes and the symbol ‘-’ indicates the position of the vowel to be stressed Assign 1-stress to the vowel in a syllable preceding a vowel followed by a morph-final syllable containing a short vowel and zero or more consonants. e.g. secretariat -> sekret“eir ee aat X – C 0 {..} {..} Assign 1-stress to the vowel in a syllable preceding a vowel followed by a morph-final vowel. e.g. oratorio -> orat“oar ee oa X – C 0 {..} {..}](https://image.slidesharecdn.com/coms30123synthesis3projector-1225480518935081-9/75/Coms30123-Synthesis-3-Projector-39-2048.jpg)
![2. V -> [1-stress] / X – C 0 {[short V] C 0 / V} where X contains all prefixes Assign 1-stress to the vowel in a syllable preceding a short vowel and zero or more consonants e.g. edit -> “ed it bitumen -> bity”uum en agenda -> aj”en da 3. V -> [1-stress] / X – C 0 where X contains all prefixes Assign 1-stress to the vowel in the last syllable e.g. stand -> st”aand parole -> paar”oal](https://image.slidesharecdn.com/coms30123synthesis3projector-1225480518935081-9/75/Coms30123-Synthesis-3-Projector-40-2048.jpg)














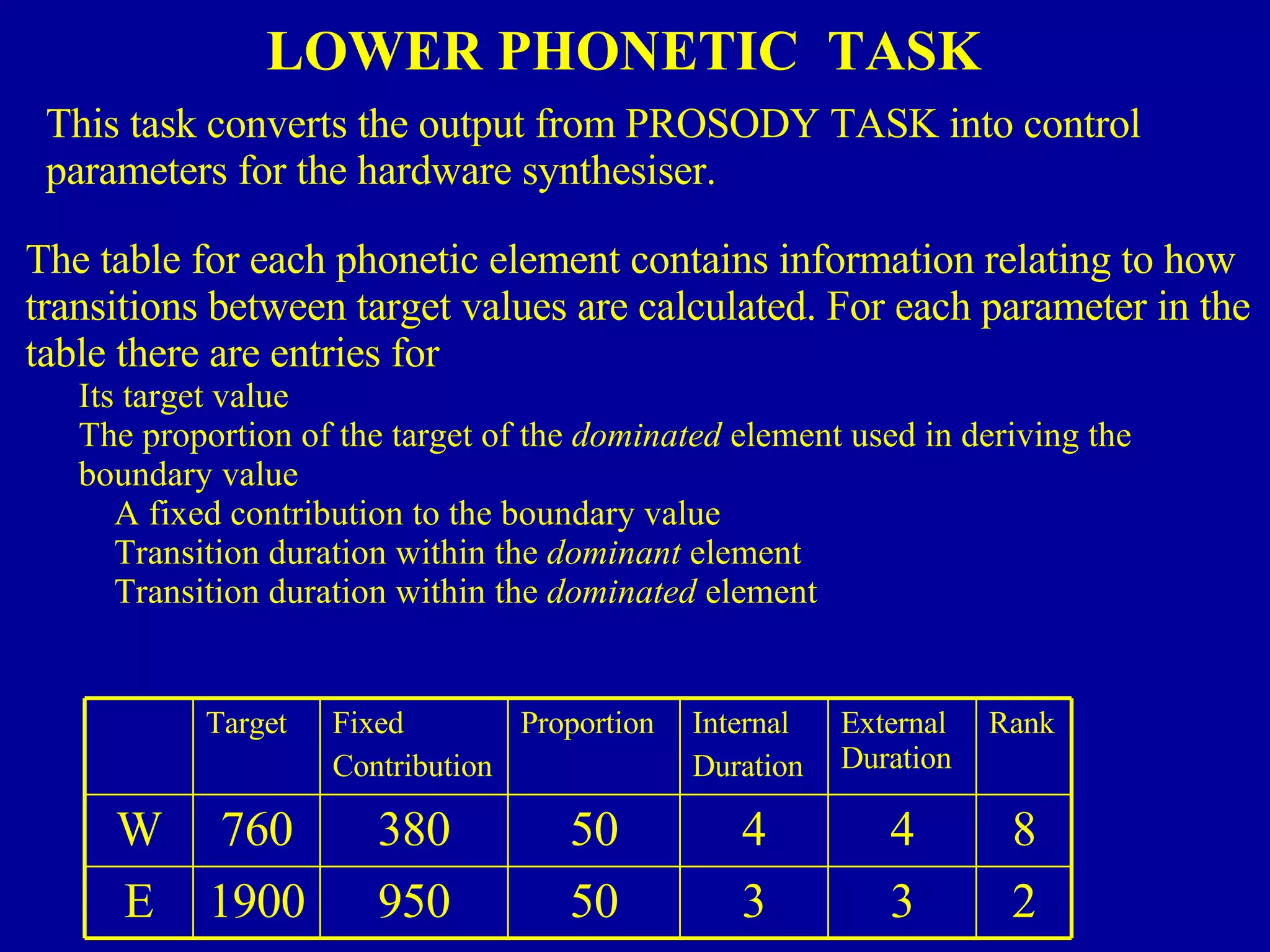
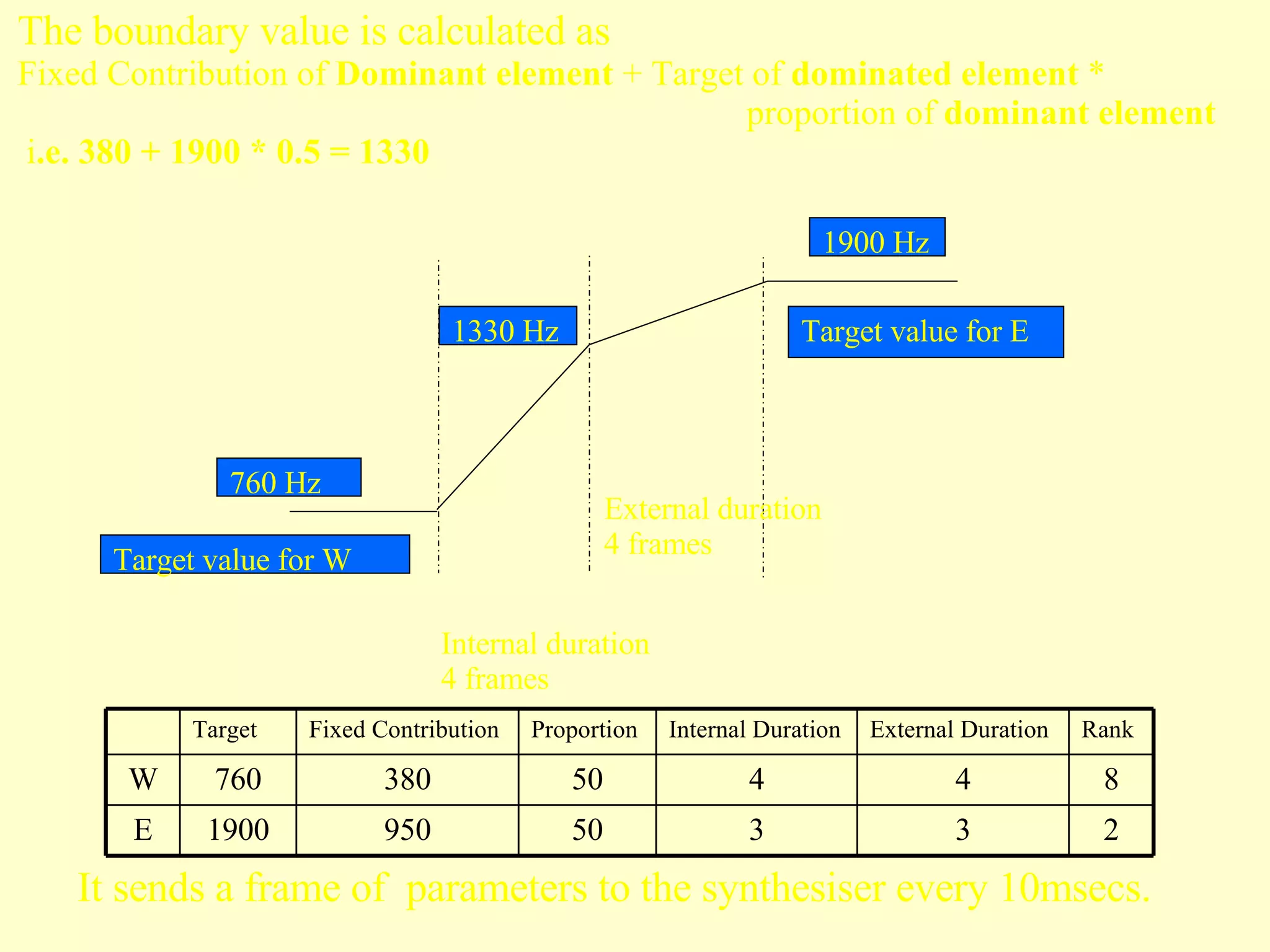
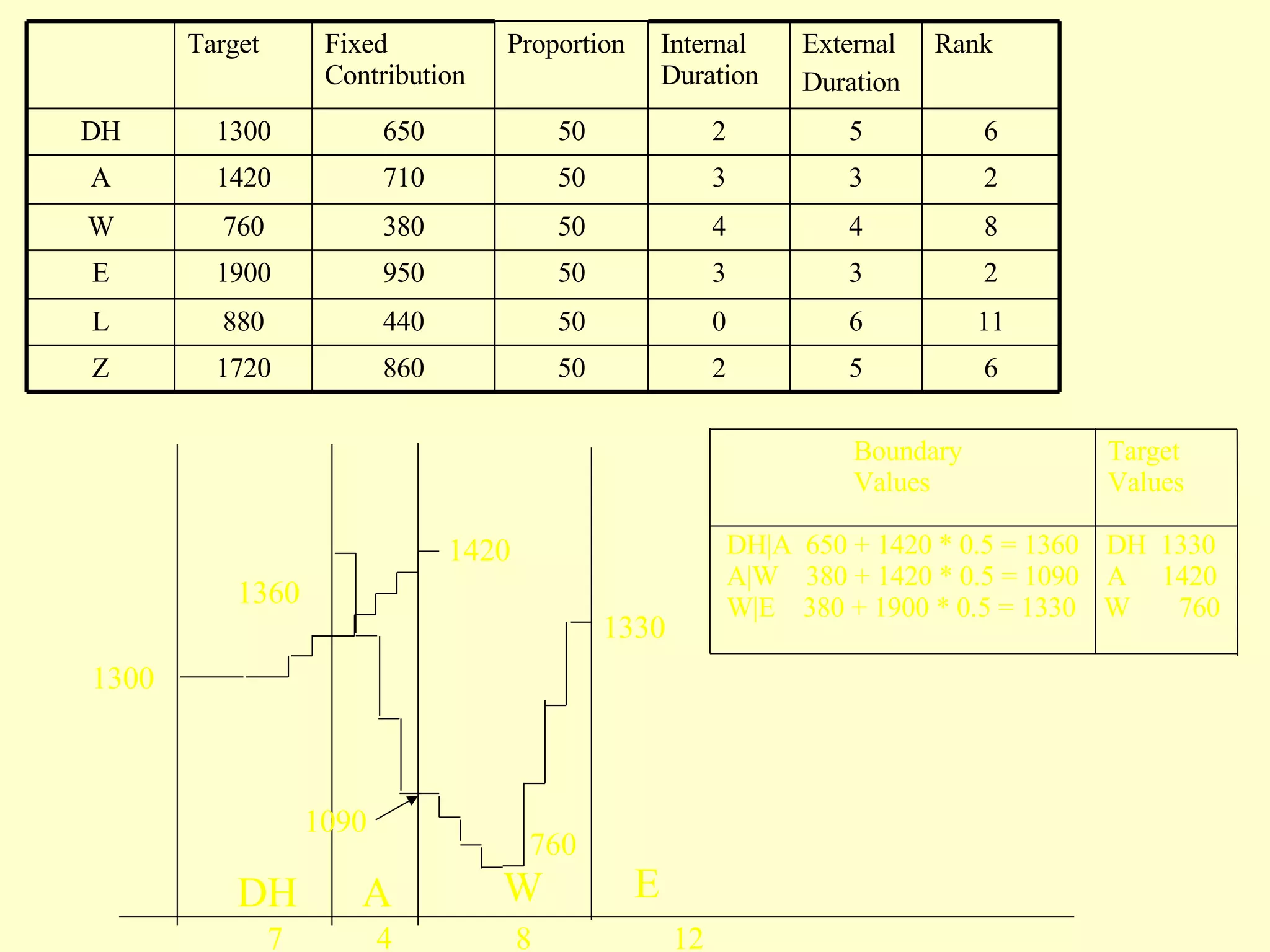

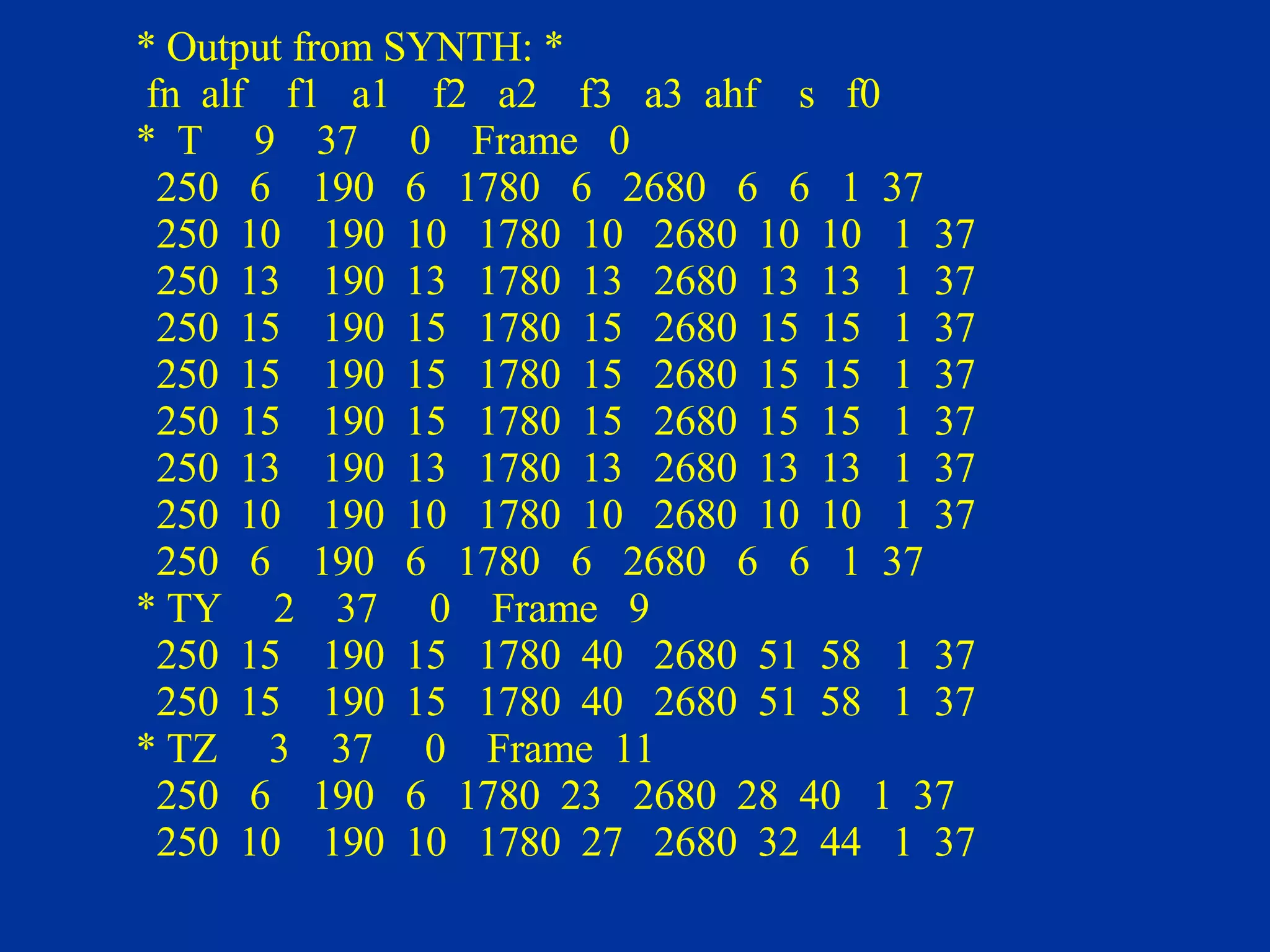


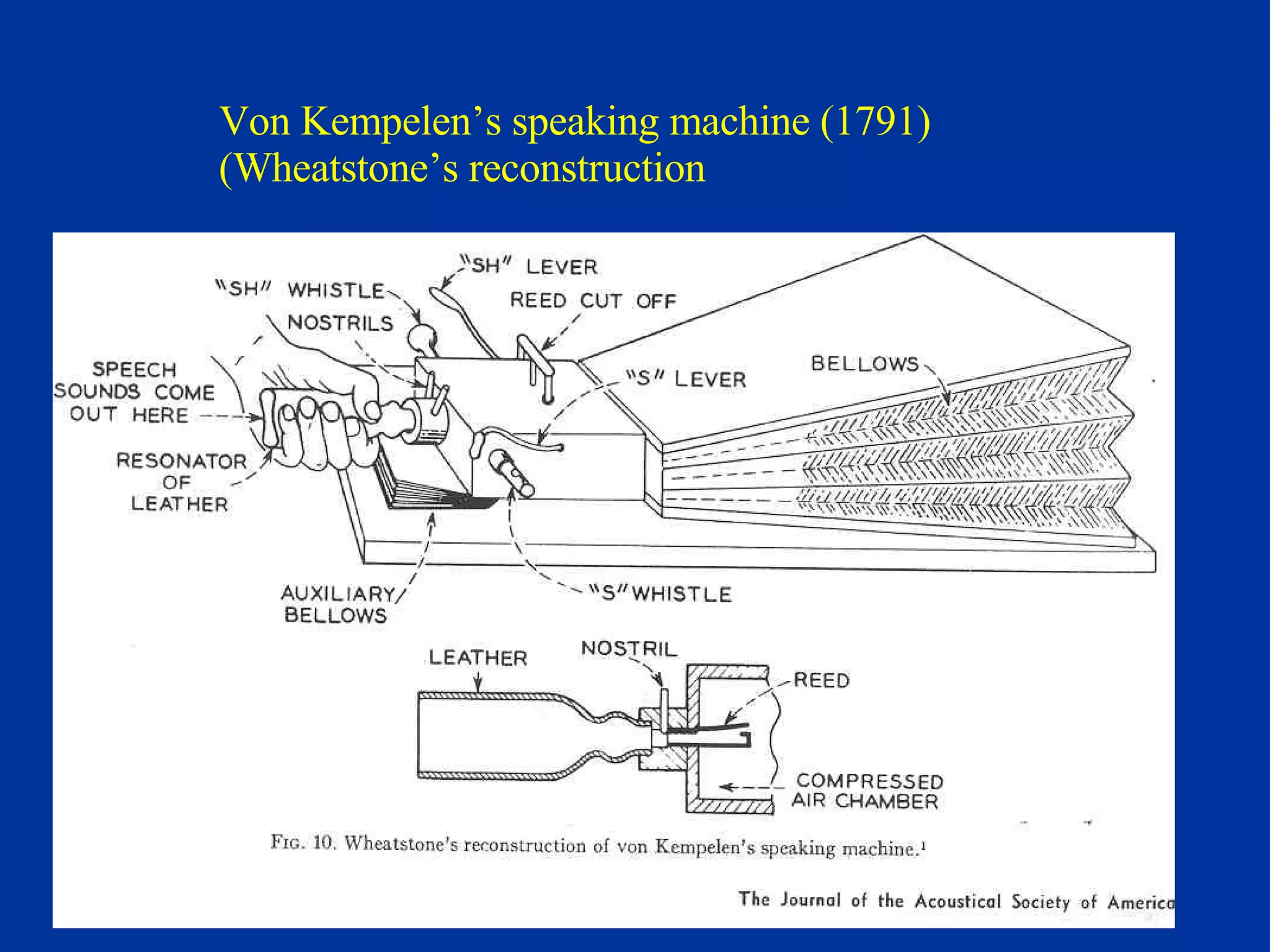
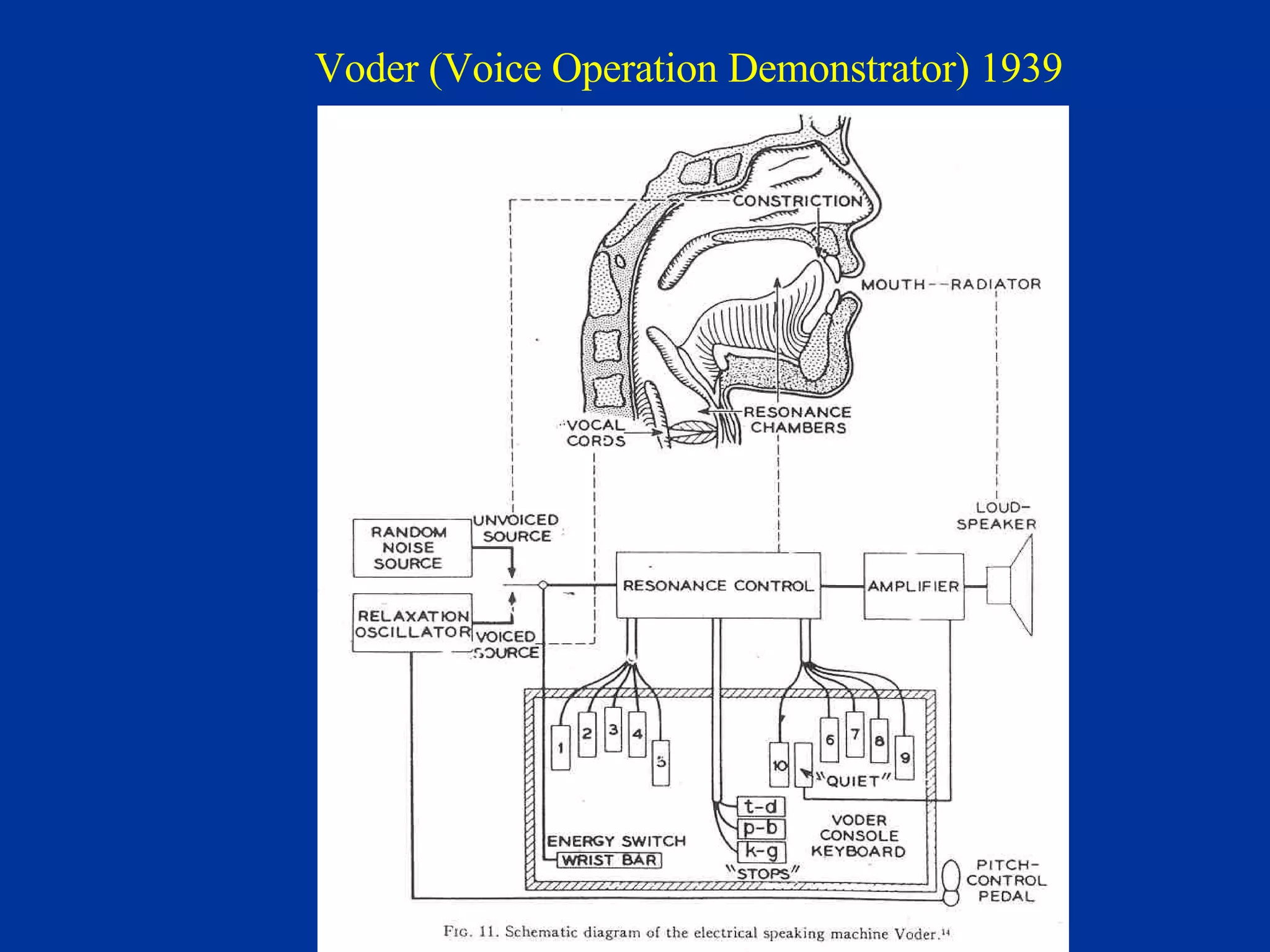
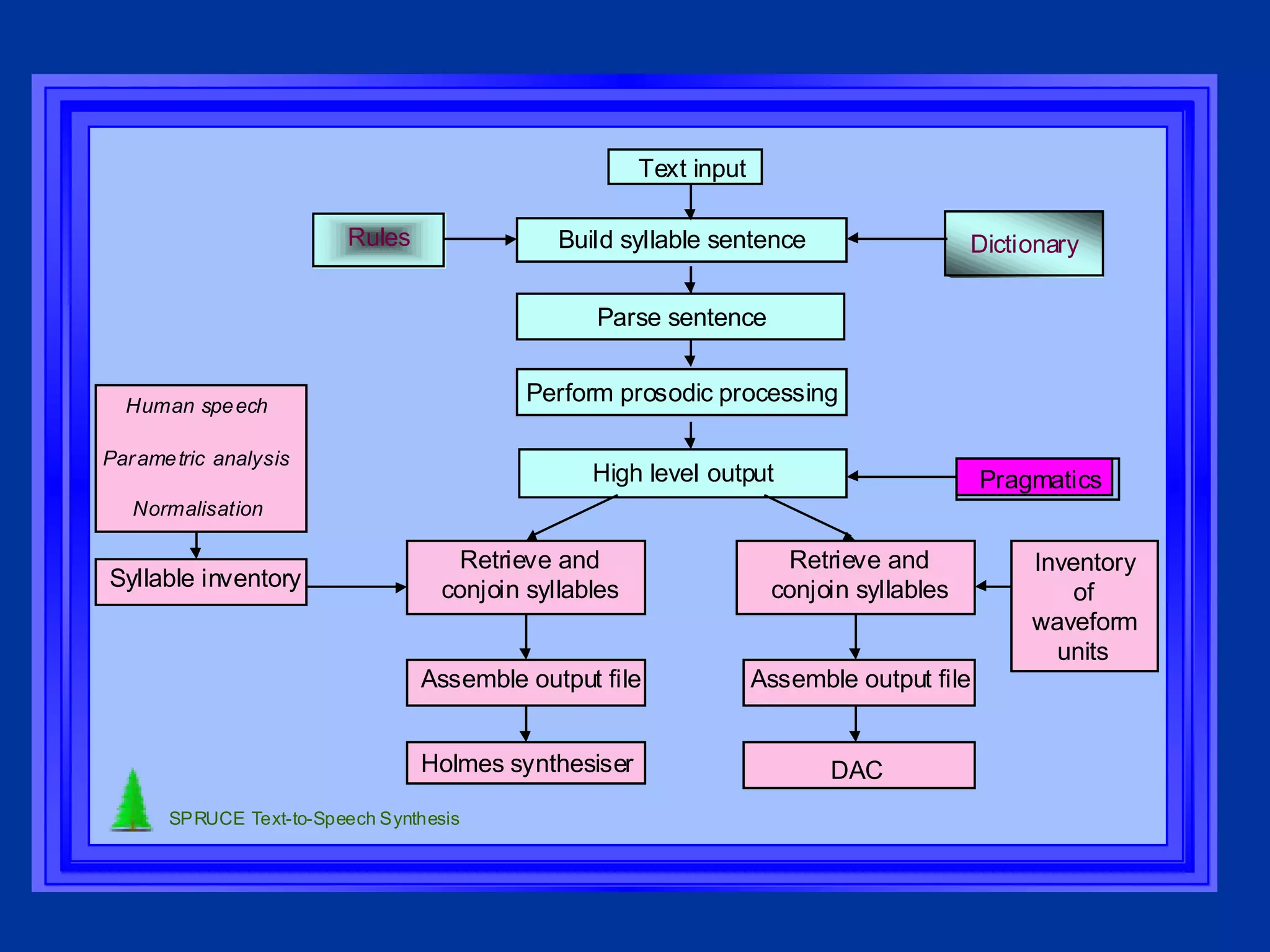
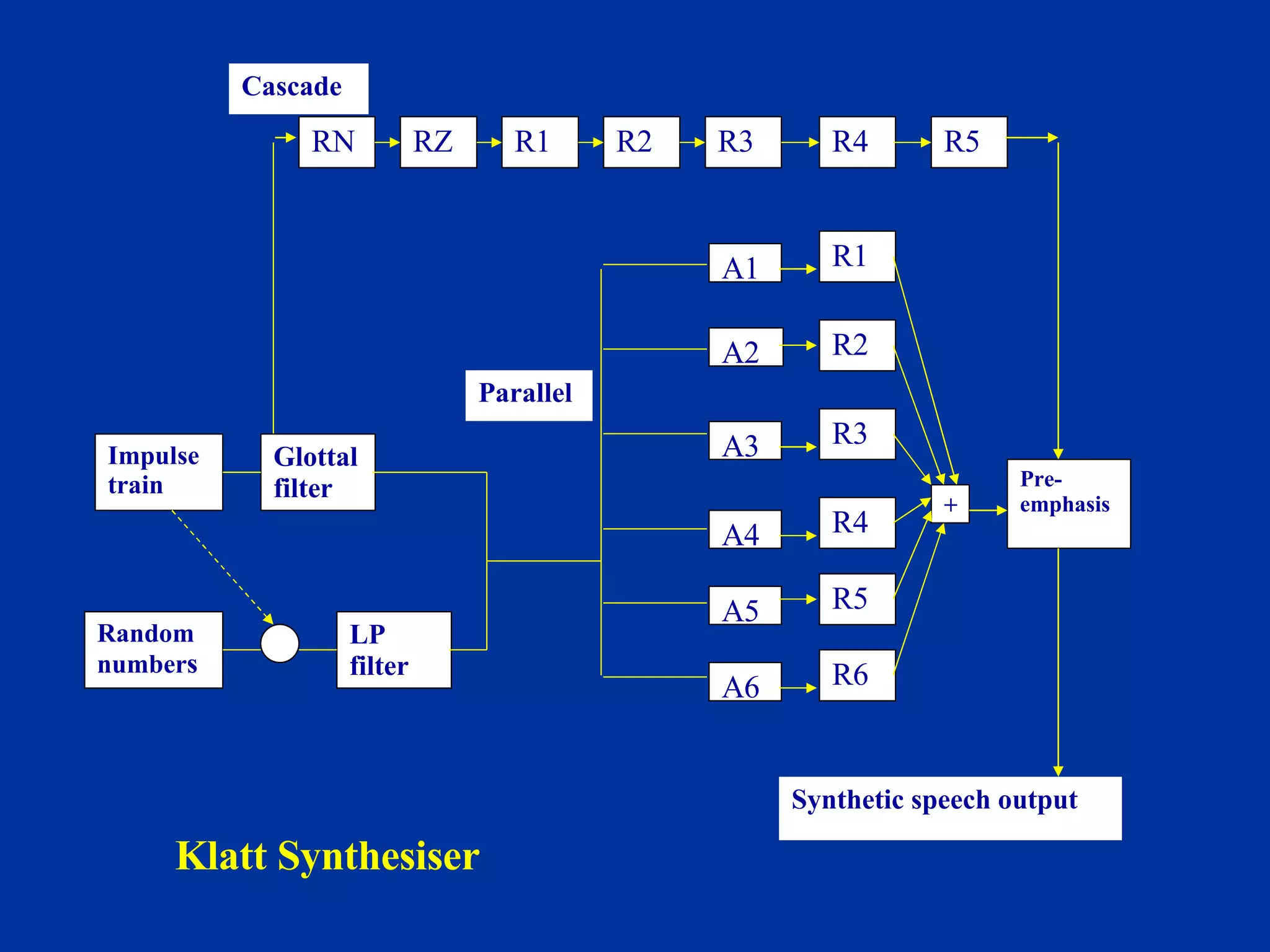
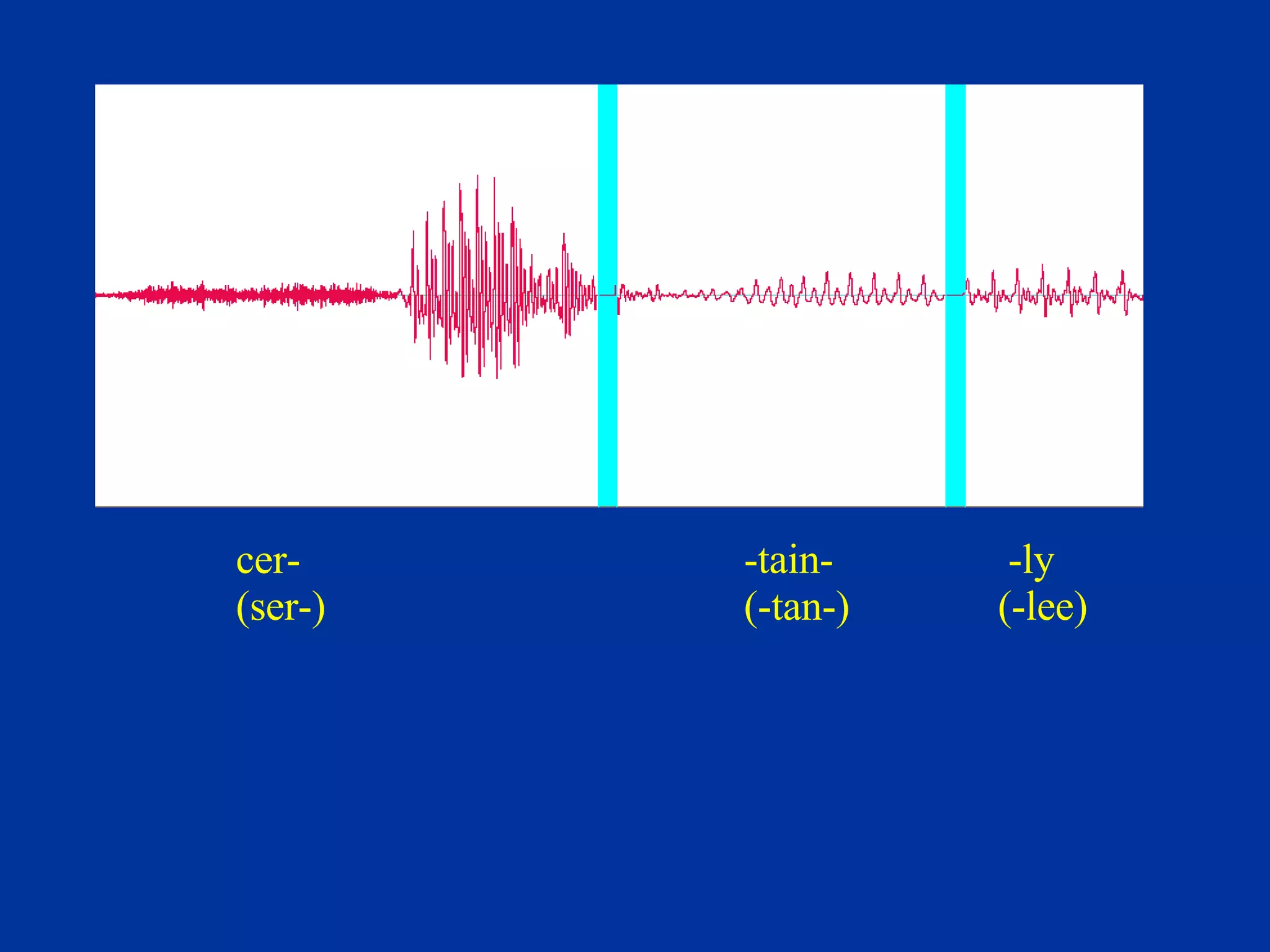
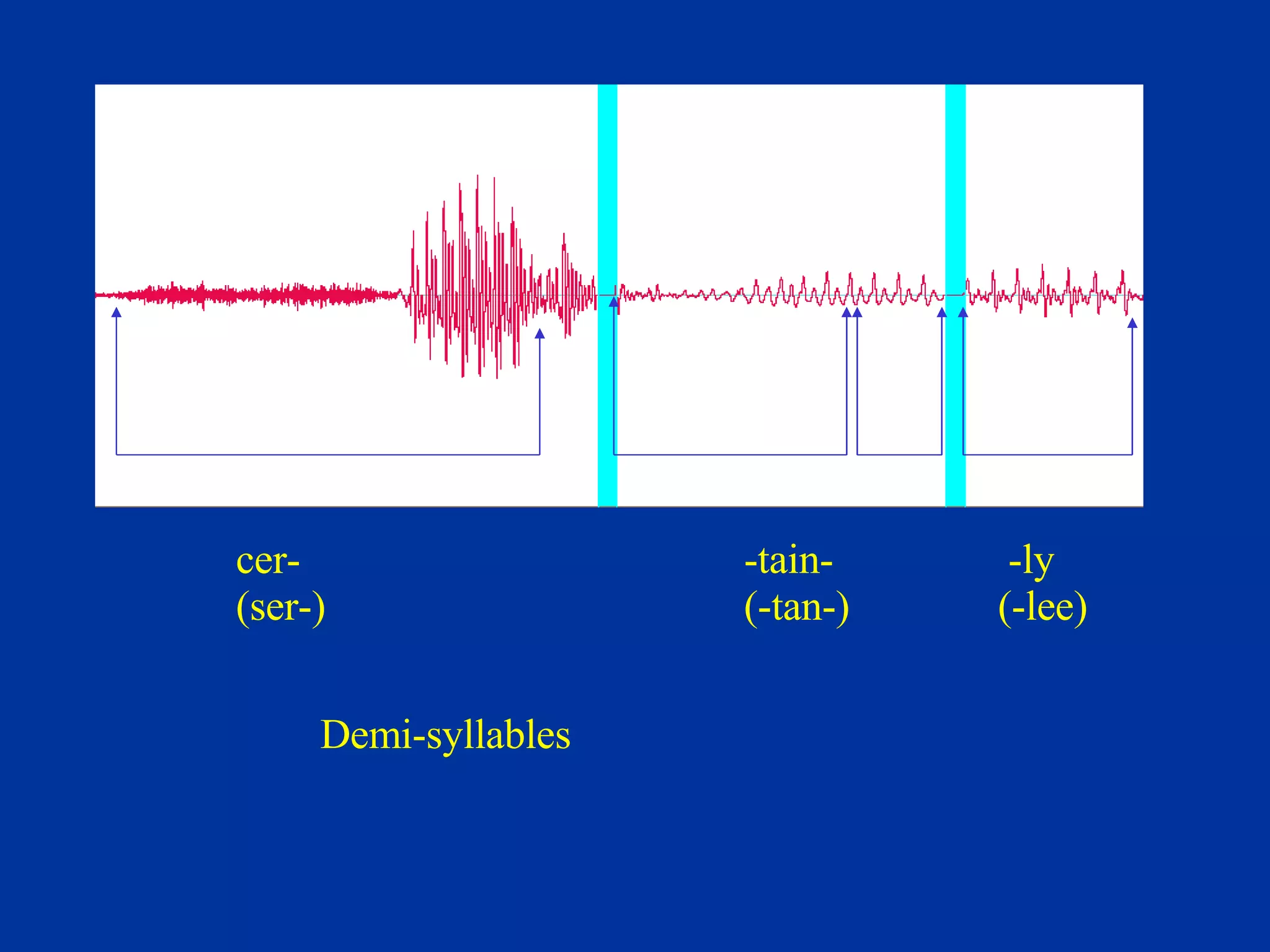
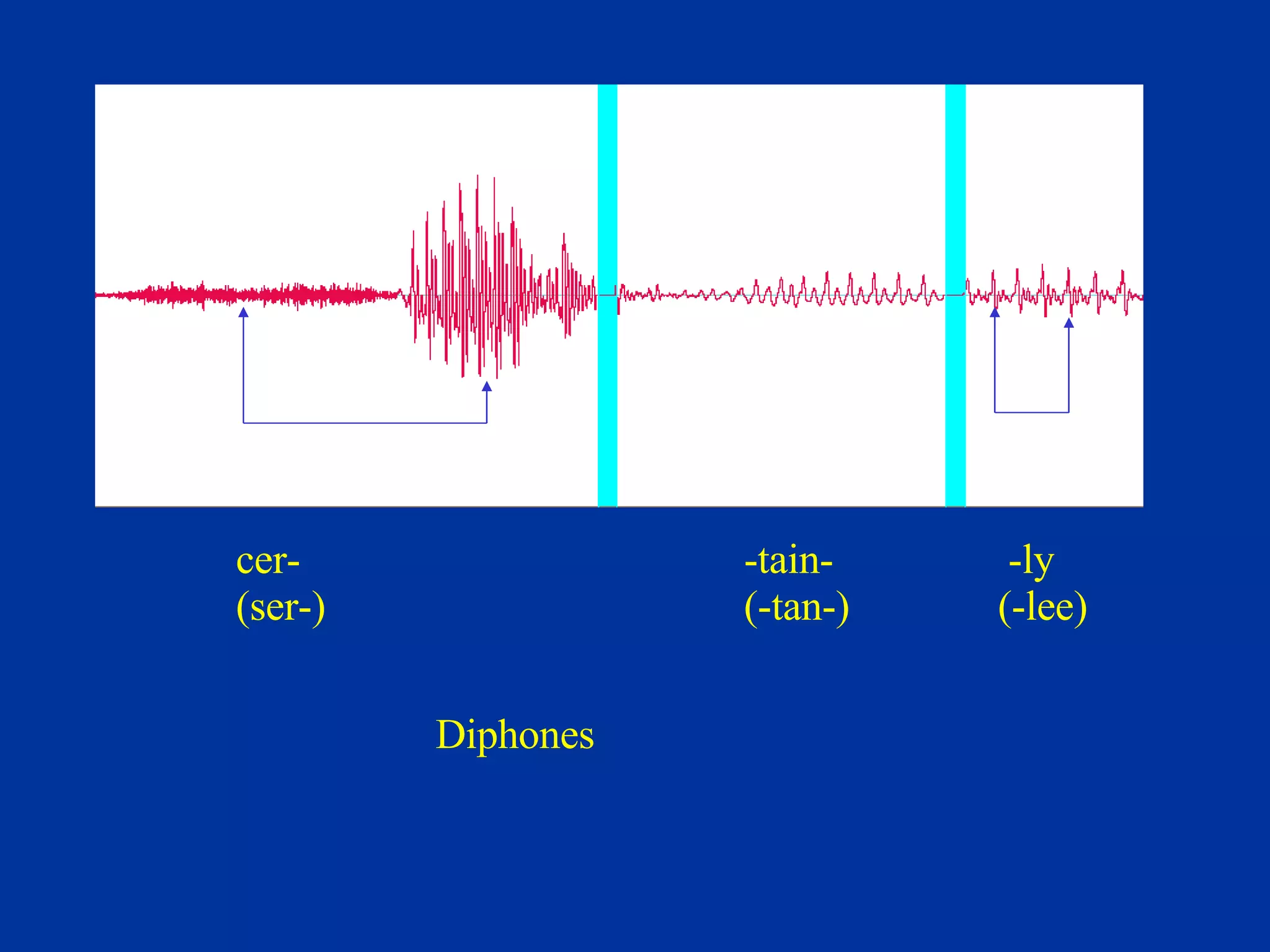
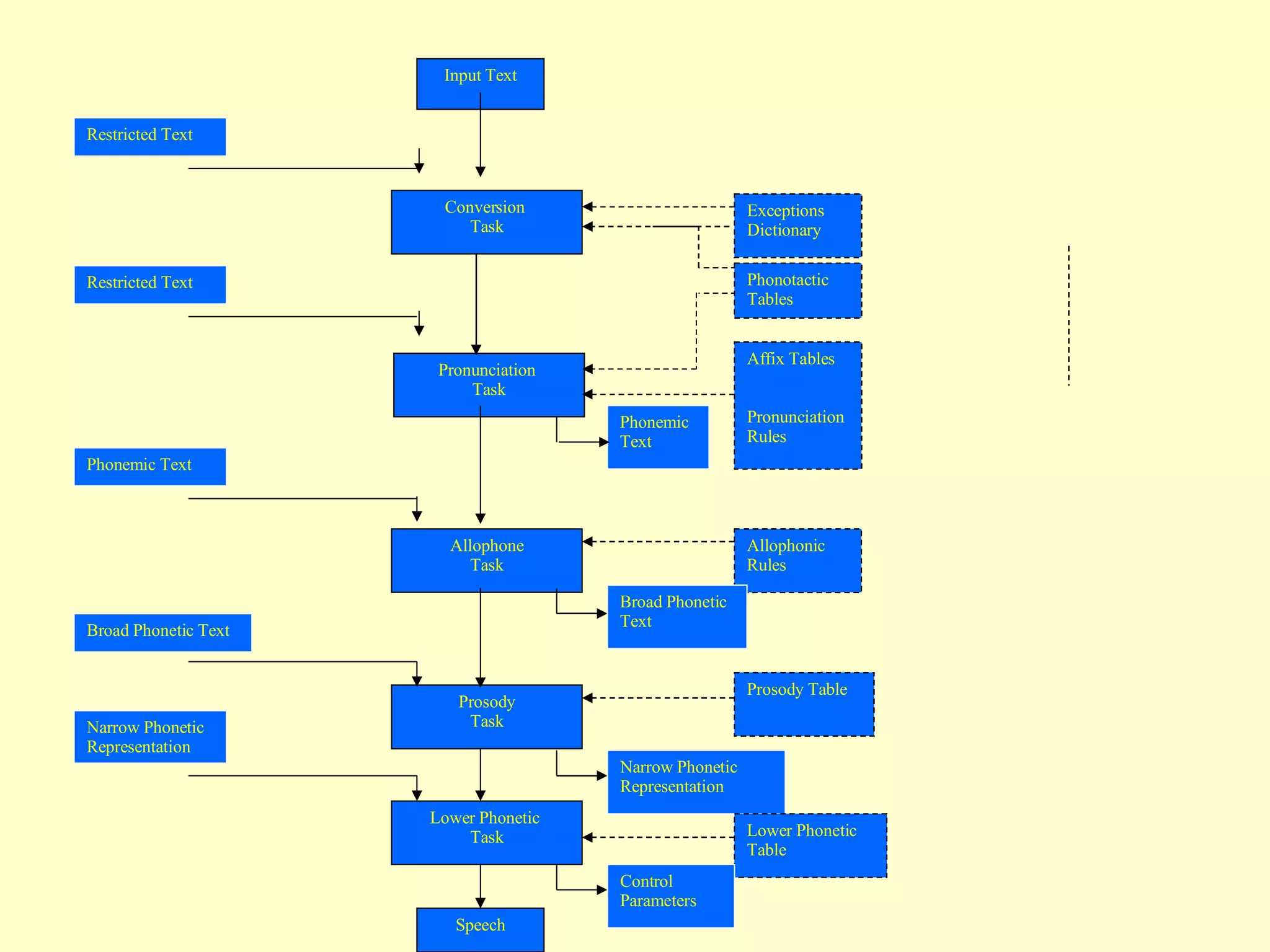
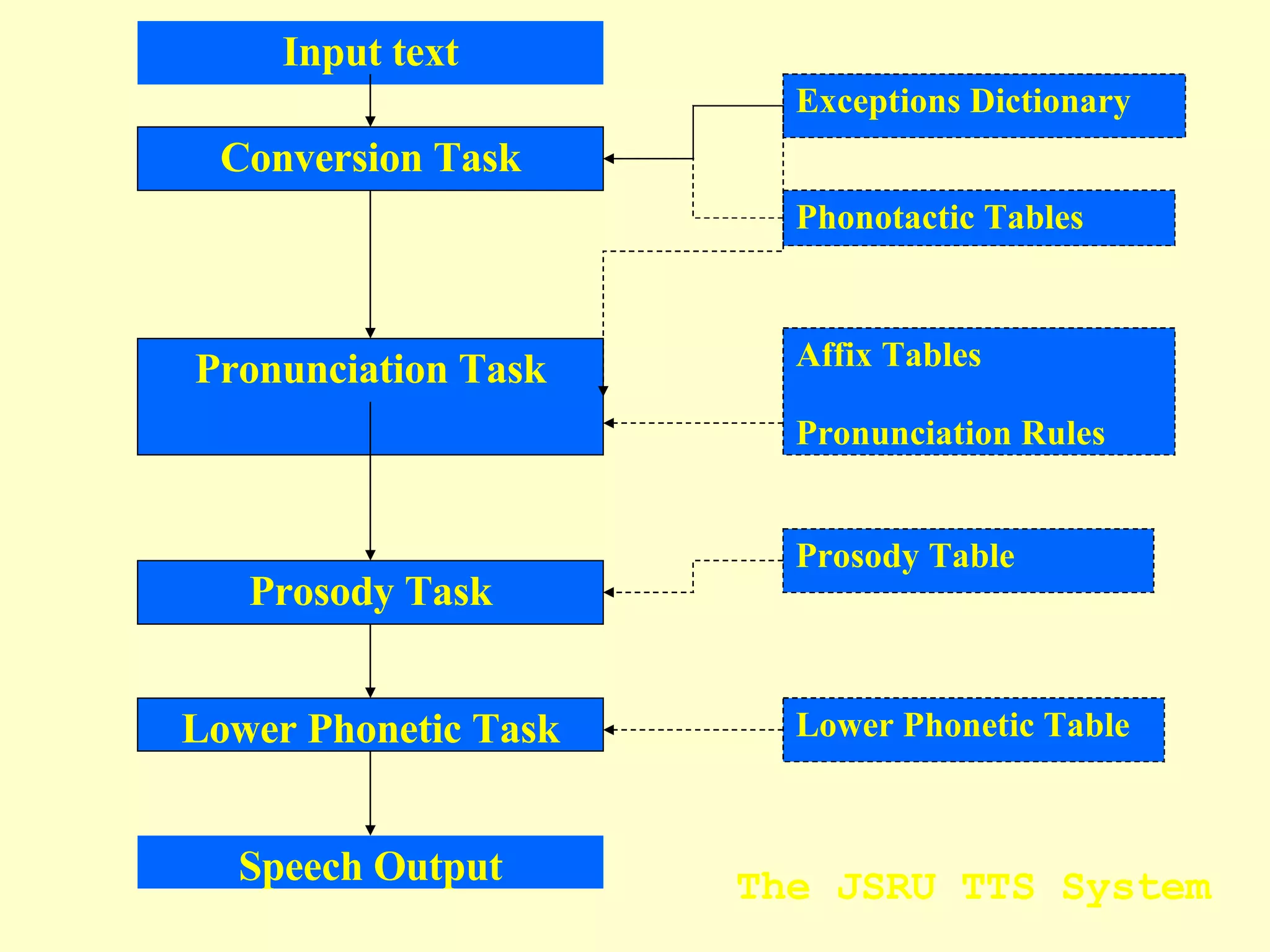
The document discusses different components and methods of text-to-speech (TTS) synthesis systems. It describes a typical TTS system as having a high-level component that converts input text to a phonetic representation and a low-level component that generates the audio output. The low-level component can use either formant synthesis, which generates parameters for vocal tract filters, or waveform concatenation, which joins prerecorded speech units. The document also examines choices for the size of the stored speech units used in concatenation systems, such as words, phones, and diphones.










































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

