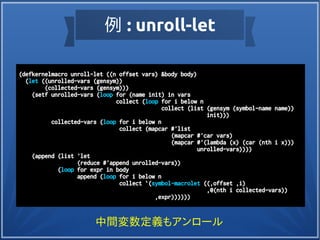
例 : unroll-let
(defkernelmacrounroll-let ((n offset vars) &body body)
(let ((unrolled-vars (gensym))
(collected-vars (gensym)))
(setf unrolled-vars (loop for (name init) in vars
collect (loop for i below n
collect (list (gensym (symbol-name name))
init)))
collected-vars (loop for i below n
collect (mapcar #'list
(mapcar #'car vars)
(mapcar #'(lambda (x) (car (nth i x)))
unrolled-vars))))
(append (list 'let
(reduce #'append unrolled-vars))
(loop for expr in body
append (loop for i below n
collect `(symbol-macrolet ((,offset ,i)
,@(nth i collected-vars))
,expr))))))
中間変数定義もアンロール
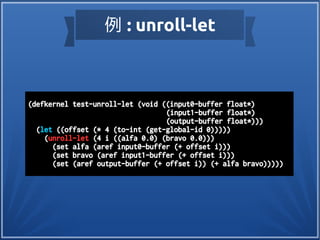
例 : unroll-sphere
(defkernelmacrounroll-sphere ((r vx vy vz) &body body)
`(progn
,@(loop for z from (- r) to r
append (loop for y from (- r) to r
append (loop for x from (- r) to r
when (>= r (sqrt (+ (* z z)
(* y y)
(* x x))))
collect `(symbol-macrolet ((,vz ,z)
(,vy ,y)
(,vx ,x))
,@body))))))
半径rの球へのアクセスを展開















![例 : unroll
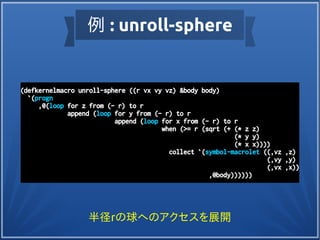
(defkernelmacro unroll ((n offset) &body body)
`(progn
,@(loop for i below n
collect `(symbol-macrolet ((,offset ,i))
,@body))))
(defkernel test-unroll (void ((input-buffer float*)
(output-buffer float*)))
(let ((offset (* 4 (to-int (get-global-id 0)))))
(unroll (4 i)
(set (aref output-buffer (+ offset i))
(aref input-buffer (+ offset i))))))
int offset = (4 * (int)(get_global_id(0)));
output_buffer[(offset + 0)] = input_buffer[(offset + 0)];
output_buffer[(offset + 1)] = input_buffer[(offset + 1)];
output_buffer[(offset + 2)] = input_buffer[(offset + 2)];
output_buffer[(offset + 3)] = input_buffer[(offset + 3)];](https://image.slidesharecdn.com/common-lisp-and-gpgpu-2016-08-mod-160904075923/85/Common-Lisp-GPGPU-15-320.jpg)
![例 : unroll-let
int offset = (4 * (int)(get_global_id(0)));
{
float alfa898 = 0.0f;
float alfa899 = 0.0f;
float alfa900 = 0.0f;
float alfa901 = 0.0f;
float bravo902 = 0.0f;
float bravo903 = 0.0f;
float bravo904 = 0.0f;
float bravo905 = 0.0f;
alfa898 = input0_buffer[(offset + 0)];
alfa899 = input0_buffer[(offset + 1)];
alfa900 = input0_buffer[(offset + 2)];
alfa901 = input0_buffer[(offset + 3)];
bravo902 = input1_buffer[(offset + 0)];
bravo903 = input1_buffer[(offset + 1)];
bravo904 = input1_buffer[(offset + 2)];
bravo905 = input1_buffer[(offset + 3)];
output_buffer[(offset + 0)] = (alfa898 + bravo902);
output_buffer[(offset + 1)] = (alfa899 + bravo903);
output_buffer[(offset + 2)] = (alfa900 + bravo904);
output_buffer[(offset + 3)] = (alfa901 + bravo905);
}](https://image.slidesharecdn.com/common-lisp-and-gpgpu-2016-08-mod-160904075923/85/Common-Lisp-GPGPU-18-320.jpg)
![例 : unroll-let
int gx = (int)(get_global_id(0));
int gy = (int)(get_global_id(1));
int gz = (int)(get_global_id(2));
int sx = (int)(get_global_size(0));
int sy = (int)(get_global_size(1));
float total = 0.0f;
total = (total + input_buffer[(((((gz + -2) * sy) * sx) + ((gy + 0) * sx)) + (gx + 0))]);
total = (total + input_buffer[(((((gz + -1) * sy) * sx) + ((gy + -1) * sx)) + (gx + -1))]);
total = (total + input_buffer[(((((gz + -1) * sy) * sx) + ((gy + -1) * sx)) + (gx + 0))]);
… (中略) ...
total = (total + input_buffer[(((((gz + 1) * sy) * sx) + ((gy + 1) * sx)) + (gx + 0))]);
total = (total + input_buffer[(((((gz + 1) * sy) * sx) + ((gy + 1) * sx)) + (gx + 1))]);
total = (total + input_buffer[(((((gz + 2) * sy) * sx) + ((gy + 0) * sx)) + (gx + 0))]);
output_buffer[((((gz * sy) * sx) + (gy * sx)) + gx)] = total;](https://image.slidesharecdn.com/common-lisp-and-gpgpu-2016-08-mod-160904075923/85/Common-Lisp-GPGPU-21-320.jpg)










































![[関東GPGPU勉強会#2] ライブラリを使って大規模疎行列線形方程式を解いてみよう](https://cdn.slidesharecdn.com/ss_thumbnails/kantogpgpu2-130608041648-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





