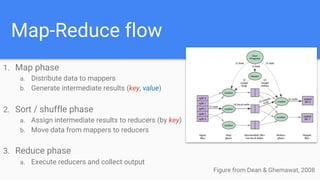
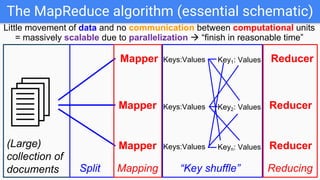
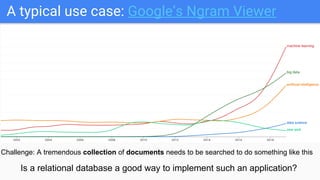
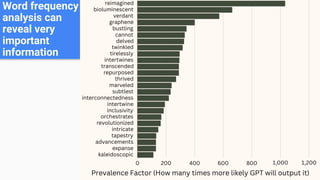
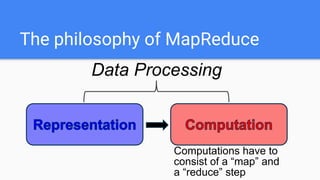
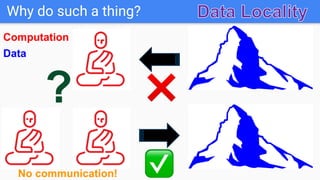
The document outlines a lecture on Big Data focusing on MapReduce, including key concepts like normalization, index building, and practical considerations for using MapReduce effectively. It discusses the framework's ability to handle large-scale data analysis, critiques its limitations, and highlights its historical importance in distributed computing. Upcoming assignments and lab work related to the topic are also mentioned.












![Why “map” and “reduce”, specifically?
● These are common operations in functional programming
○ E.g.: LISP, Haskell, Scala…
● map(function f, values [x1, x2, …, xn]) → [f(x1), f(x2), … f(xn)]
○ map : function, list → list
○ f is applied element-wise
○ This allows for parallelism, if list elements are independent
● reduce(function g, values [x1, x2, …, xn]) → g(x1, reduce(g, [x2, …, xn]))
○ reduce : function, list → item
○ g is applied recursively to pairs of items](https://image.slidesharecdn.com/bigd3mapreduce-250128191646-9d4c1aac/85/bigD3_mapReducebigD3_mapReducebigD3_mapReduce-pdf-22-320.jpg)