Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
cyberagent
18,893 views
Amebaにおけるログ解析基盤Patriotの活用事例
2013年11月7日開催 「Cloudera World Tokyo 2013」 セッション発表資料 (株式会社サイバーエージェント)
Technology
◦
Read more
18
Save
Share
Embed
Embed presentation
Download
Downloaded 88 times
1
/ 46
2
/ 46
3
/ 46
4
/ 46
5
/ 46
6
/ 46
7
/ 46
8
/ 46
9
/ 46
10
/ 46
11
/ 46
12
/ 46
13
/ 46
14
/ 46
15
/ 46
16
/ 46
17
/ 46
18
/ 46
19
/ 46
20
/ 46
21
/ 46
22
/ 46
23
/ 46
24
/ 46
25
/ 46
26
/ 46
27
/ 46
28
/ 46
29
/ 46
30
/ 46
31
/ 46
32
/ 46
33
/ 46
34
/ 46
35
/ 46
36
/ 46
37
/ 46
38
/ 46
39
/ 46
40
/ 46
41
/ 46
42
/ 46
43
/ 46
44
/ 46
45
/ 46
46
/ 46
More Related Content
PPTX
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
PDF
Azure でサーバーレス、 Infrastructure as Code どうしてますか?
by
Kazumi OHIRA
PPTX
ネットストーカー御用達OSINTツールBlackBirdを触ってみた.pptx
by
Shota Shinogi
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
Oracle GoldenGate アーキテクチャと基本機能
by
オラクルエンジニア通信
PDF
「指標」を支えるエンジニアリング: DataOpsNight #1
by
株式会社MonotaRO Tech Team
PPTX
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
PDF
Yahoo! JAPANが持つデータ分析ソリューションの紹介 #yjdsnight
by
Yahoo!デベロッパーネットワーク
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
Azure でサーバーレス、 Infrastructure as Code どうしてますか?
by
Kazumi OHIRA
ネットストーカー御用達OSINTツールBlackBirdを触ってみた.pptx
by
Shota Shinogi
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
Oracle GoldenGate アーキテクチャと基本機能
by
オラクルエンジニア通信
「指標」を支えるエンジニアリング: DataOpsNight #1
by
株式会社MonotaRO Tech Team
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
Yahoo! JAPANが持つデータ分析ソリューションの紹介 #yjdsnight
by
Yahoo!デベロッパーネットワーク
What's hot
PDF
シリコンバレーの「何が」凄いのか
by
Atsushi Nakada
PDF
ビジネスパーソンのためのDX入門講座エッセンス版
by
Tokoroten Nakayama
PPTX
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
PPTX
え!? Power BI の画面からデータ更新なんてできるの!? ~PowerApps カスタムビジュアルの可能性~
by
Yugo Shimizu
PPTX
Power BI をアプリに埋め込みたい? ならば Power BI Embedded だ!
by
Teruchika Yamada
PDF
Kubernetesによる機械学習基盤への挑戦
by
Preferred Networks
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
by
Yahoo!デベロッパーネットワーク
PPT
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
PPTX
RDB開発者のためのApache Cassandra データモデリング入門
by
Yuki Morishita
PPTX
地理分散DBについて
by
Kumazaki Hiroki
PDF
トランザクションの並行実行制御 rev.2
by
Takashi Hoshino
PDF
MLflow + Kubeflow MLプラットフォーム事例 #sparktokyo
by
Yahoo!デベロッパーネットワーク
PPTX
技術者として抑えておきたい Power BI アーキテクチャ
by
Yugo Shimizu
PDF
Scala、DDD、Akkaで立ち向かう 〜広告配信システムに課せられた100msの制約〜
by
MicroAd, Inc.(Engineer)
PDF
Prometheus Operator 入門(Kubernetes Novice Tokyo #26 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Kafka & Kafka Connectを に使ったデータ連携パターン(改めETLの実装)
by
Keigo Suda
PDF
データベースで始める機械学習
by
オラクルエンジニア通信
PDF
オープンソースのAPIゲートウェイ Kong ご紹介
by
briscola-tokyo
PDF
Micrometer/Prometheusによる大規模システムモニタリング #jsug #sf_26
by
Yahoo!デベロッパーネットワーク
PDF
○ヶ月でできた!?さくらのクラウド開発秘話(【ヒカ☆ラボ】さくらインターネットとMilkcocoa!年末イベント:ここだけのウラ話)
by
さくらインターネット株式会社
シリコンバレーの「何が」凄いのか
by
Atsushi Nakada
ビジネスパーソンのためのDX入門講座エッセンス版
by
Tokoroten Nakayama
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
え!? Power BI の画面からデータ更新なんてできるの!? ~PowerApps カスタムビジュアルの可能性~
by
Yugo Shimizu
Power BI をアプリに埋め込みたい? ならば Power BI Embedded だ!
by
Teruchika Yamada
Kubernetesによる機械学習基盤への挑戦
by
Preferred Networks
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
by
Yahoo!デベロッパーネットワーク
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
RDB開発者のためのApache Cassandra データモデリング入門
by
Yuki Morishita
地理分散DBについて
by
Kumazaki Hiroki
トランザクションの並行実行制御 rev.2
by
Takashi Hoshino
MLflow + Kubeflow MLプラットフォーム事例 #sparktokyo
by
Yahoo!デベロッパーネットワーク
技術者として抑えておきたい Power BI アーキテクチャ
by
Yugo Shimizu
Scala、DDD、Akkaで立ち向かう 〜広告配信システムに課せられた100msの制約〜
by
MicroAd, Inc.(Engineer)
Prometheus Operator 入門(Kubernetes Novice Tokyo #26 発表資料)
by
NTT DATA Technology & Innovation
Apache Kafka & Kafka Connectを に使ったデータ連携パターン(改めETLの実装)
by
Keigo Suda
データベースで始める機械学習
by
オラクルエンジニア通信
オープンソースのAPIゲートウェイ Kong ご紹介
by
briscola-tokyo
Micrometer/Prometheusによる大規模システムモニタリング #jsug #sf_26
by
Yahoo!デベロッパーネットワーク
○ヶ月でできた!?さくらのクラウド開発秘話(【ヒカ☆ラボ】さくらインターネットとMilkcocoa!年末イベント:ここだけのウラ話)
by
さくらインターネット株式会社
Viewers also liked
PDF
DeNAの分析を支える分析基盤
by
Kenshin Yamada
PDF
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
PDF
Amebaにおけるレコメンデーションシステムの紹介
by
cyberagent
PDF
サイバーエージェントにおけるデータの品質管理について #cwt2016
by
cyberagent
PPTX
何故DeNAがverticaを選んだか?
by
Kenshin Yamada
PDF
【14-B-2】グリーを支えるデータ分析基盤の過去と現在(橋本泰一〔グリー〕)
by
Developers Summit
PDF
Presto As A Service - Treasure DataでのPresto運用事例
by
Taro L. Saito
PDF
Apache Flume 1.5を活⽤したAmebaにおけるログのシステム連携
by
cyberagent
PDF
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
PDF
リアルタイム分析サービス『たべみる』を支える高可用性アーキテクチャ
by
Hiroyuki Inoue
PDF
データファースト開発
by
Katsunori Kanda
PPTX
データドリブン企業におけるHadoop基盤とETL -niconicoでの実践例-
by
Makoto SHIMURA
PDF
STF20131030chrome
by
cyberagent
PPTX
Flumeを活用したAmebaにおける大規模ログ収集システム
by
Satoshi Iijima
PDF
Presto in my_use_case
by
wyukawa
PDF
20141106_cwt-zenmyo-naito
by
cyberagent
PDF
Classmethod awsstudy ec2rds20160114
by
Satoru Ishikawa
PDF
front_server20131218
by
cyberagent
PPTX
Dot_fes2013
by
cyberagent
PDF
Amazon Redshiftによるリアルタイム分析サービスの構築
by
Minero Aoki
DeNAの分析を支える分析基盤
by
Kenshin Yamada
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
Amebaにおけるレコメンデーションシステムの紹介
by
cyberagent
サイバーエージェントにおけるデータの品質管理について #cwt2016
by
cyberagent
何故DeNAがverticaを選んだか?
by
Kenshin Yamada
【14-B-2】グリーを支えるデータ分析基盤の過去と現在(橋本泰一〔グリー〕)
by
Developers Summit
Presto As A Service - Treasure DataでのPresto運用事例
by
Taro L. Saito
Apache Flume 1.5を活⽤したAmebaにおけるログのシステム連携
by
cyberagent
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
リアルタイム分析サービス『たべみる』を支える高可用性アーキテクチャ
by
Hiroyuki Inoue
データファースト開発
by
Katsunori Kanda
データドリブン企業におけるHadoop基盤とETL -niconicoでの実践例-
by
Makoto SHIMURA
STF20131030chrome
by
cyberagent
Flumeを活用したAmebaにおける大規模ログ収集システム
by
Satoshi Iijima
Presto in my_use_case
by
wyukawa
20141106_cwt-zenmyo-naito
by
cyberagent
Classmethod awsstudy ec2rds20160114
by
Satoru Ishikawa
front_server20131218
by
cyberagent
Dot_fes2013
by
cyberagent
Amazon Redshiftによるリアルタイム分析サービスの構築
by
Minero Aoki
Similar to Amebaにおけるログ解析基盤Patriotの活用事例
PDF
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
PDF
オススメのJavaログ管理手法 ~コンテナ編~(Open Source Conference 2022 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
PDF
Amazon Kinesis Familyを活用したストリームデータ処理
by
Amazon Web Services Japan
PDF
AWSの様々なアーキテクチャ
by
Kameda Harunobu
PDF
Data Lake ハンズオン
by
Amazon Web Services Japan
PDF
Hadoop conferencejapan2011
by
Ichiro Fukuda
PDF
スマートニュースの世界展開を支えるログ解析基盤
by
Takumi Sakamoto
PDF
Storm×couchbase serverで作るリアルタイム解析基盤
by
NTT Communications Technology Development
PDF
20131107 cwt2013-wdkz
by
cyberagent
PDF
ログ収集フレームワークの新バージョン「FlumeNG」
by
AdvancedTechNight
PPT
Flume
by
あしたのオープンソース研究所
PDF
[Sumo Logic x AWS 共催セミナー_20190829] Sumo Logic on AWS -AWS を活用したログ分析とセキュリティモニ...
by
Takanori Ohba
PDF
20130313 OSCA Hadoopセミナー
by
Ichiro Fukuda
PDF
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
PDF
内製パッケージによるHadoopデータ解析基盤の構築と運用
by
cyberagent
PDF
Facebookのリアルタイム Big Data 処理
by
maruyama097
PDF
20100930 sig startups
by
Ichiro Fukuda
PPTX
Data Stream Processing and Analysis with Akka
by
Roman Shtykh
PDF
【18-B-2】データ分析で始めるサービス改善最初の一歩
by
Developers Summit
PDF
Fluentd Meetup #2 @外道父 Fluentdを優しく見守る監視事例
by
外道 父
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
オススメのJavaログ管理手法 ~コンテナ編~(Open Source Conference 2022 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
Amazon Kinesis Familyを活用したストリームデータ処理
by
Amazon Web Services Japan
AWSの様々なアーキテクチャ
by
Kameda Harunobu
Data Lake ハンズオン
by
Amazon Web Services Japan
Hadoop conferencejapan2011
by
Ichiro Fukuda
スマートニュースの世界展開を支えるログ解析基盤
by
Takumi Sakamoto
Storm×couchbase serverで作るリアルタイム解析基盤
by
NTT Communications Technology Development
20131107 cwt2013-wdkz
by
cyberagent
ログ収集フレームワークの新バージョン「FlumeNG」
by
AdvancedTechNight
Flume
by
あしたのオープンソース研究所
[Sumo Logic x AWS 共催セミナー_20190829] Sumo Logic on AWS -AWS を活用したログ分析とセキュリティモニ...
by
Takanori Ohba
20130313 OSCA Hadoopセミナー
by
Ichiro Fukuda
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
内製パッケージによるHadoopデータ解析基盤の構築と運用
by
cyberagent
Facebookのリアルタイム Big Data 処理
by
maruyama097
20100930 sig startups
by
Ichiro Fukuda
Data Stream Processing and Analysis with Akka
by
Roman Shtykh
【18-B-2】データ分析で始めるサービス改善最初の一歩
by
Developers Summit
Fluentd Meetup #2 @外道父 Fluentdを優しく見守る監視事例
by
外道 父
More from cyberagent
PDF
AbemaTVにおける推薦システム
by
cyberagent
PDF
番組宣伝に関するAbemaTV分析事例の紹介
by
cyberagent
PDF
ログ解析基盤におけるストリーム処理パイプラインについて
by
cyberagent
PDF
Webと経済学 數見拓朗
by
cyberagent
PDF
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
PDF
「これ危ない設定じゃないでしょうか」とヒアリングするための仕組み @AWS Summit Tokyo 2018
by
cyberagent
PDF
継続的な開発スタイル AbemaTVのiOSアプリを週1でリリースしている話
by
cyberagent
PPTX
"マルチメディア機械学習" の取り組み
by
cyberagent
PDF
WWW2019で見るモバイルコンピューティングの技術と動向 山本悠ニ
by
cyberagent
PDF
WebにおけるHuman Dynamics 武内慎
by
cyberagent
PDF
サイバーエージェントの機械学習エンジニアが体験したGoogle I/O 2018
by
cyberagent
PDF
Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
by
cyberagent
PDF
WWW2018 論文読み会 Web Search and Mining
by
cyberagent
PDF
Orion an integrated multimedia content moderation system for web services
by
cyberagent
PDF
Orion an integrated multimedia content moderation system for web services
by
cyberagent
PDF
機械学習エンジニアを見せたAWSの再:発明とは? 〜re:Invent 2018 参加レポート〜
by
cyberagent
PDF
AbemaTV レコメンド開発エンジニアによる RecSys 2018 参加レポート
by
cyberagent
PDF
WWW2018 論文読み会 Webと経済学
by
cyberagent
PPTX
インターネットテレビ局「AbemaTV」プロダクトの変遷
by
cyberagent
PDF
WWW2018 論文読み会 WebにおけるHuman Dynamics
by
cyberagent
AbemaTVにおける推薦システム
by
cyberagent
番組宣伝に関するAbemaTV分析事例の紹介
by
cyberagent
ログ解析基盤におけるストリーム処理パイプラインについて
by
cyberagent
Webと経済学 數見拓朗
by
cyberagent
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
「これ危ない設定じゃないでしょうか」とヒアリングするための仕組み @AWS Summit Tokyo 2018
by
cyberagent
継続的な開発スタイル AbemaTVのiOSアプリを週1でリリースしている話
by
cyberagent
"マルチメディア機械学習" の取り組み
by
cyberagent
WWW2019で見るモバイルコンピューティングの技術と動向 山本悠ニ
by
cyberagent
WebにおけるHuman Dynamics 武内慎
by
cyberagent
サイバーエージェントの機械学習エンジニアが体験したGoogle I/O 2018
by
cyberagent
Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
by
cyberagent
WWW2018 論文読み会 Web Search and Mining
by
cyberagent
Orion an integrated multimedia content moderation system for web services
by
cyberagent
Orion an integrated multimedia content moderation system for web services
by
cyberagent
機械学習エンジニアを見せたAWSの再:発明とは? 〜re:Invent 2018 参加レポート〜
by
cyberagent
AbemaTV レコメンド開発エンジニアによる RecSys 2018 参加レポート
by
cyberagent
WWW2018 論文読み会 Webと経済学
by
cyberagent
インターネットテレビ局「AbemaTV」プロダクトの変遷
by
cyberagent
WWW2018 論文読み会 WebにおけるHuman Dynamics
by
cyberagent
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
Amebaにおけるログ解析基盤Patriotの活用事例
1.
Amebaにおけるログ解析基盤Patriotの活用事例 株式会社サイバーエージェント アメーバ事業本部 Ameba Technology Laboratory 善明晃由、飯島賢志
2.
株式会社サイバーエージェント 本日の内容 • • • • AmebaサービスとAmeba Technology Laboratoryについて ログ解析基盤Patriotの概要 データ分析のためのPatriotの活用体制 ログ転送システムとApache
Flume 2
3.
Amebaサービスと Ameba Technology Laboratory について
4.
株式会社サイバーエージェント Ameba事業 ー PC向けサービス 4
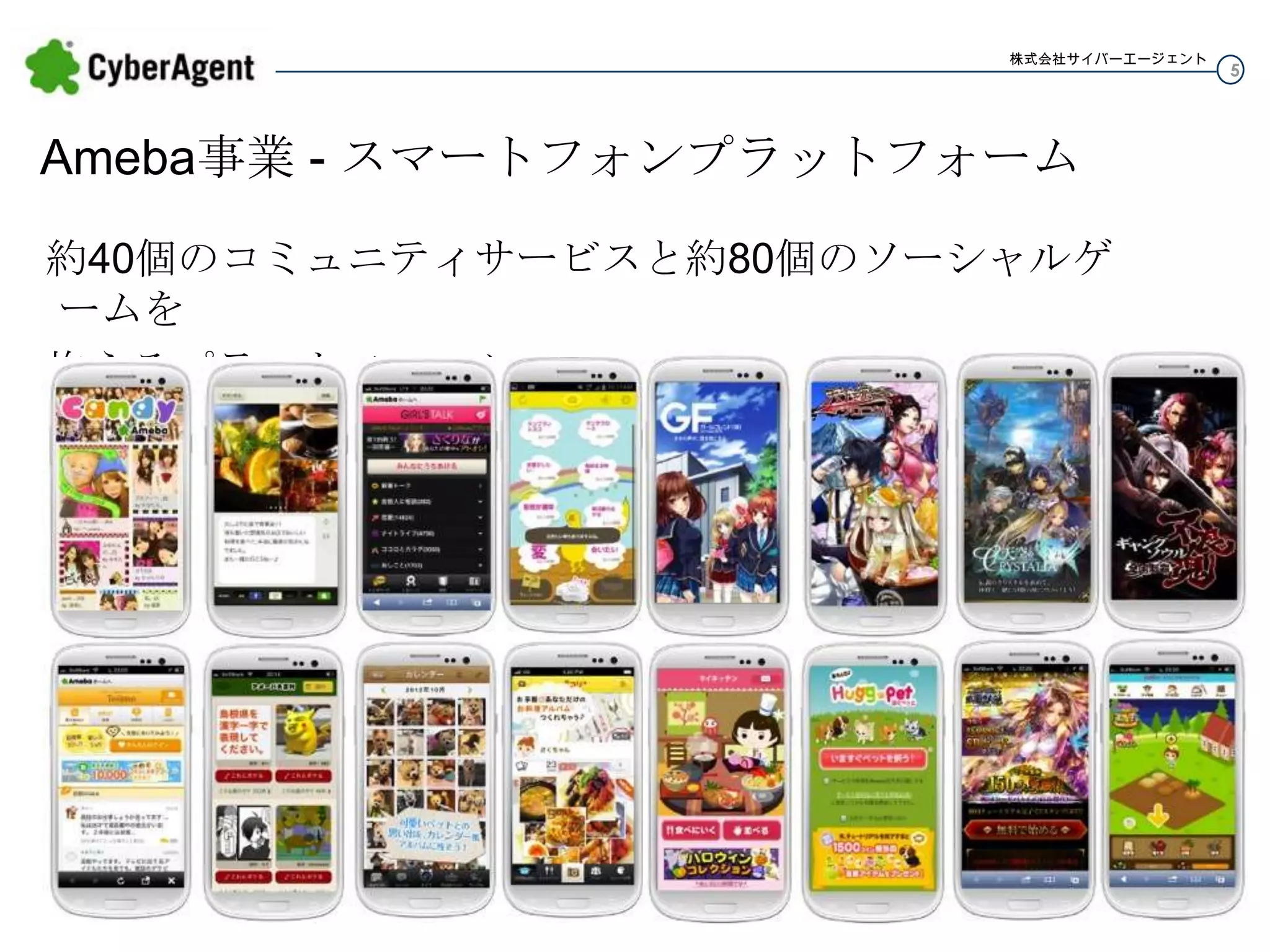
5.
株式会社サイバーエージェント Ameba事業 - スマートフォンプラットフォーム 約40個のコミュニティサービスと約80個のソーシャルゲームを 抱えるプラットフォーム 5
6.
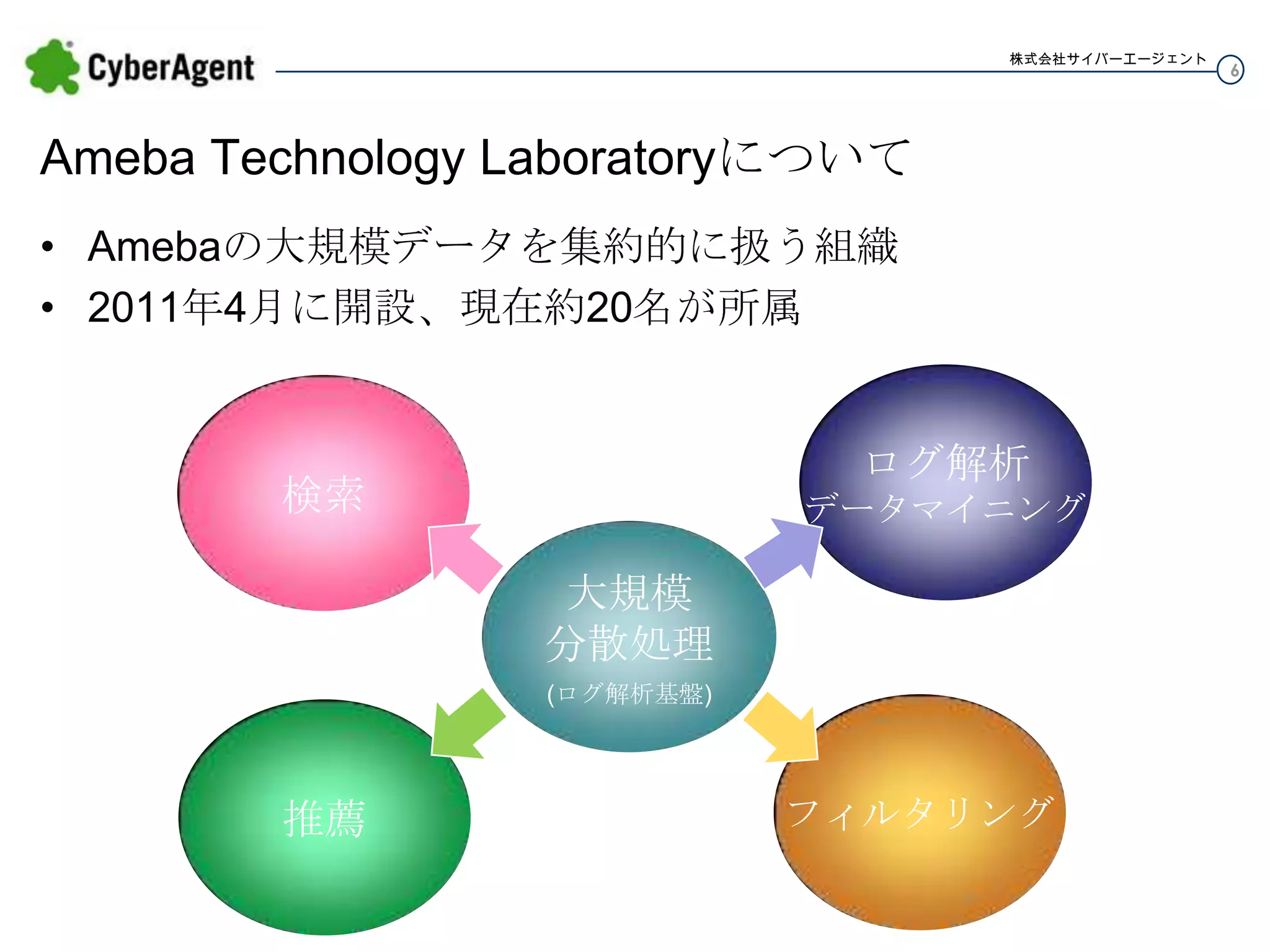
株式会社サイバーエージェント Ameba Technology Laboratoryについて •
Amebaの大規模データを集約的に扱う組織 • 2011年4月に開設、現在約20名が所属 ログ解析 検索 データマイニング 大規模 分散処理 (ログ解析基盤) 推薦 フィルタリング 6
7.
ログ解析基盤Patriotの概要
8.
8 Amebaのログ解析基盤:Patriot • Amebaのサービス共通のログ解析基盤 • Ameba
Technology Laboratoryで開発・運用 • サービスのユーザ行動の分析 • レコメンド等の大規模データ活用による機能の提供 • Hadoopクラスタ上に構築 • • • • HDFSにログデータを集約 Hive/MapReduceを用いた集計 HBaseを用いて処理結果を活用 Flumeを用いたデータ収集
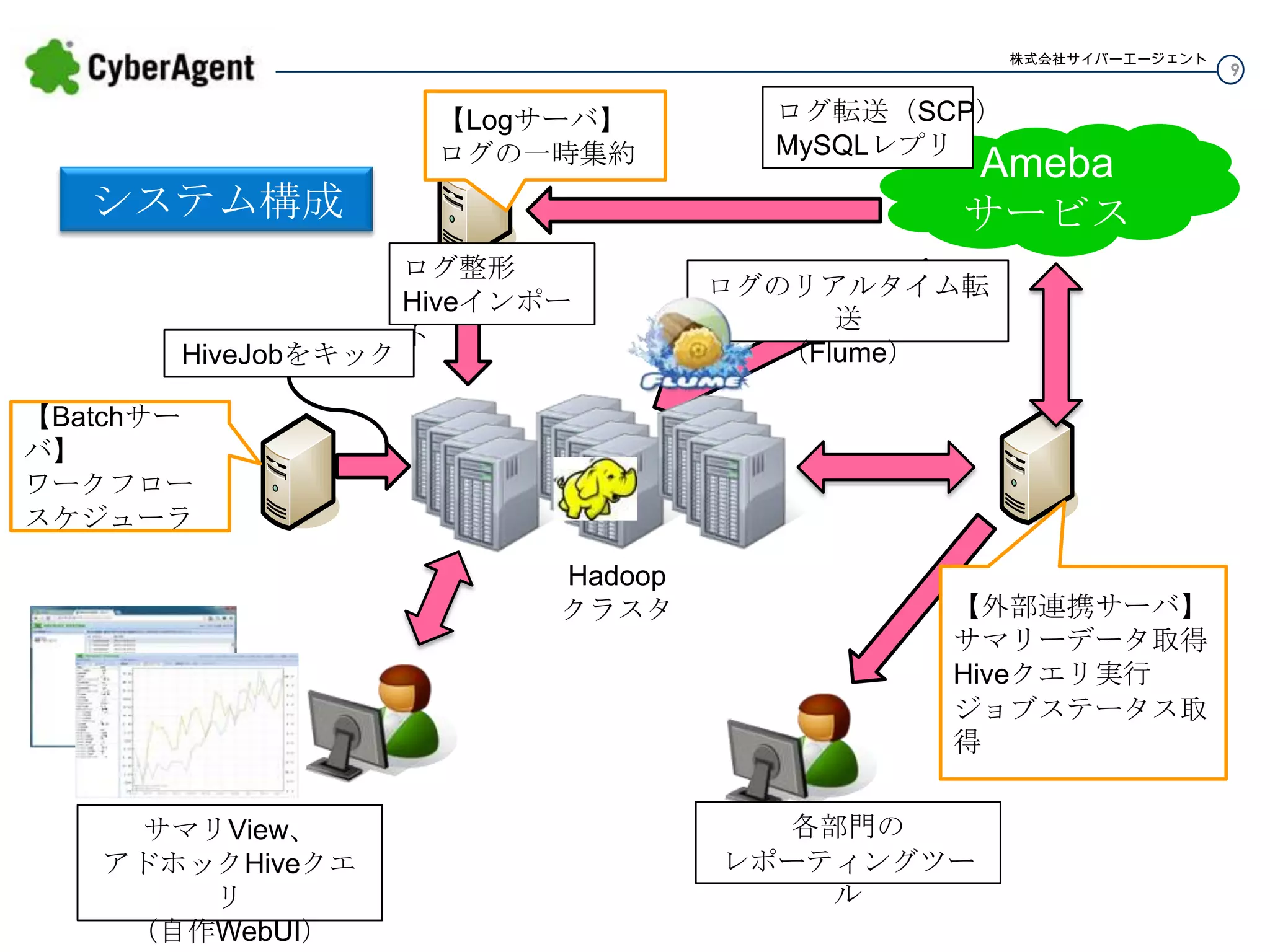
9.
株式会社サイバーエージェント 【Logサーバ】 ログの一時集約 ログ転送(SCP) MySQLレプリ システム構成 ログ整形 Hiveインポート Ameba サービス ログのリアルタイム転送 (Flume) HiveJobをキック 【Batchサーバ】 ワークフロー スケジューラ Hadoop クラスタ サマリView、 アドホックHiveクエリ (自作WebUI) 【外部連携サーバ】 サマリーデータ取得 Hiveクエリ実行 ジョブステータス取得 各部門の レポーティングツール 9
10.
株式会社サイバーエージェント これまでの経緯 • 2010年 7月: 初期リリース
(CDH3b系) • 2011年 3月: CDH3u0にアップグレード 9月: 独自開発のワークフロースケジューラ、サマリDBとしてHBaseを導入 • 2012年 5月: スマートフォンプラットフォーム向けPatriotの構築 (CDH3u3) 10月: ログ収集にFlumeを導入(Apache Flume1.3) • 2013年 3月: 外部連携サーバ(Patriot Bridge)の導入 7月: PatriotのDC移設、CDHアップグレード(CDH4.3) GHE、Jenkinsを用いた運用フローの見直し 8月: スマートフォンプラットフォーム向けPatriotを統合 10
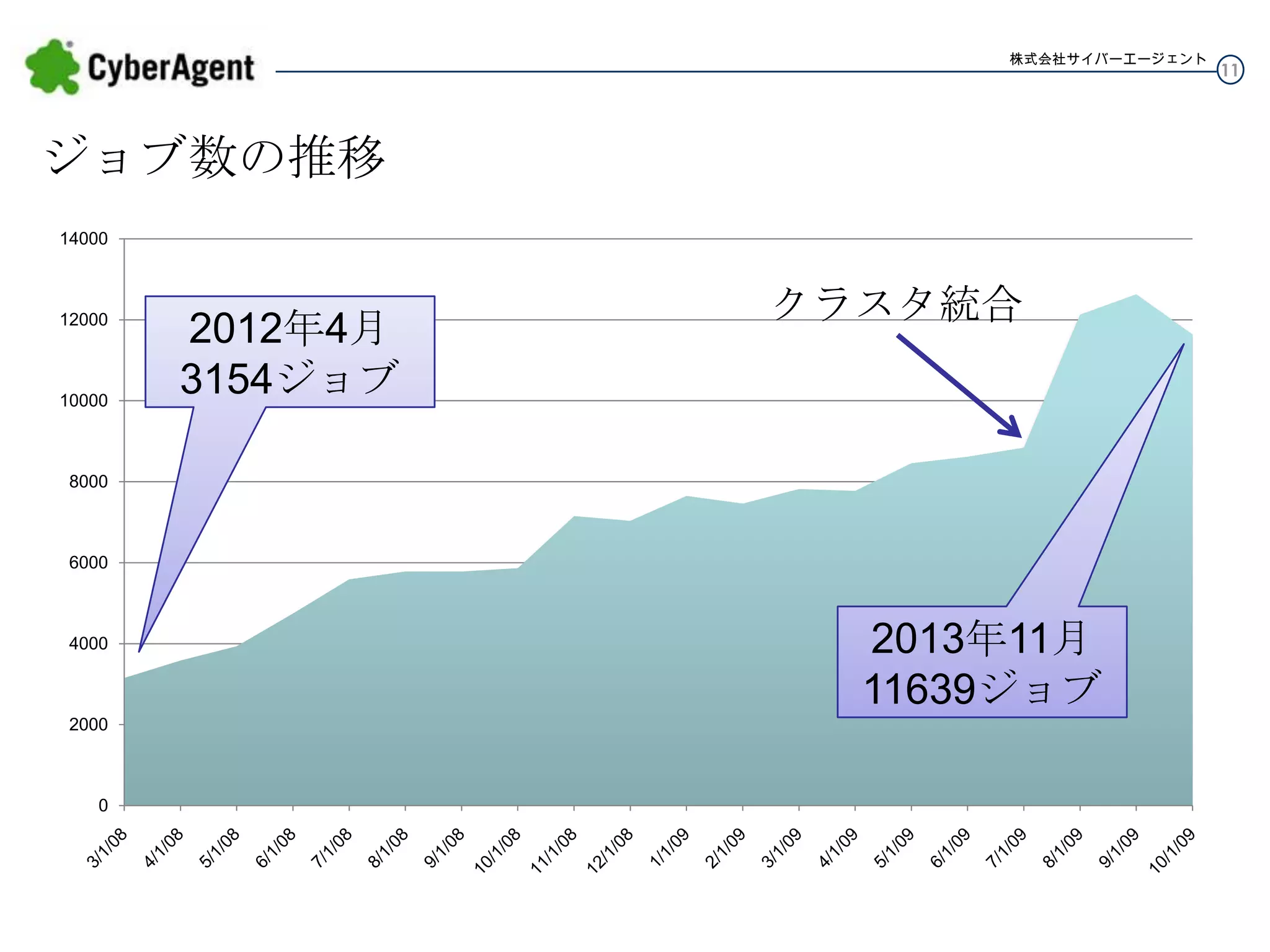
11.
株式会社サイバーエージェント ジョブ数の推移 14000 12000 10000 2012年4月 3154ジョブ クラスタ統合 8000 6000 4000 2000 0 2013年11月 11639ジョブ 11
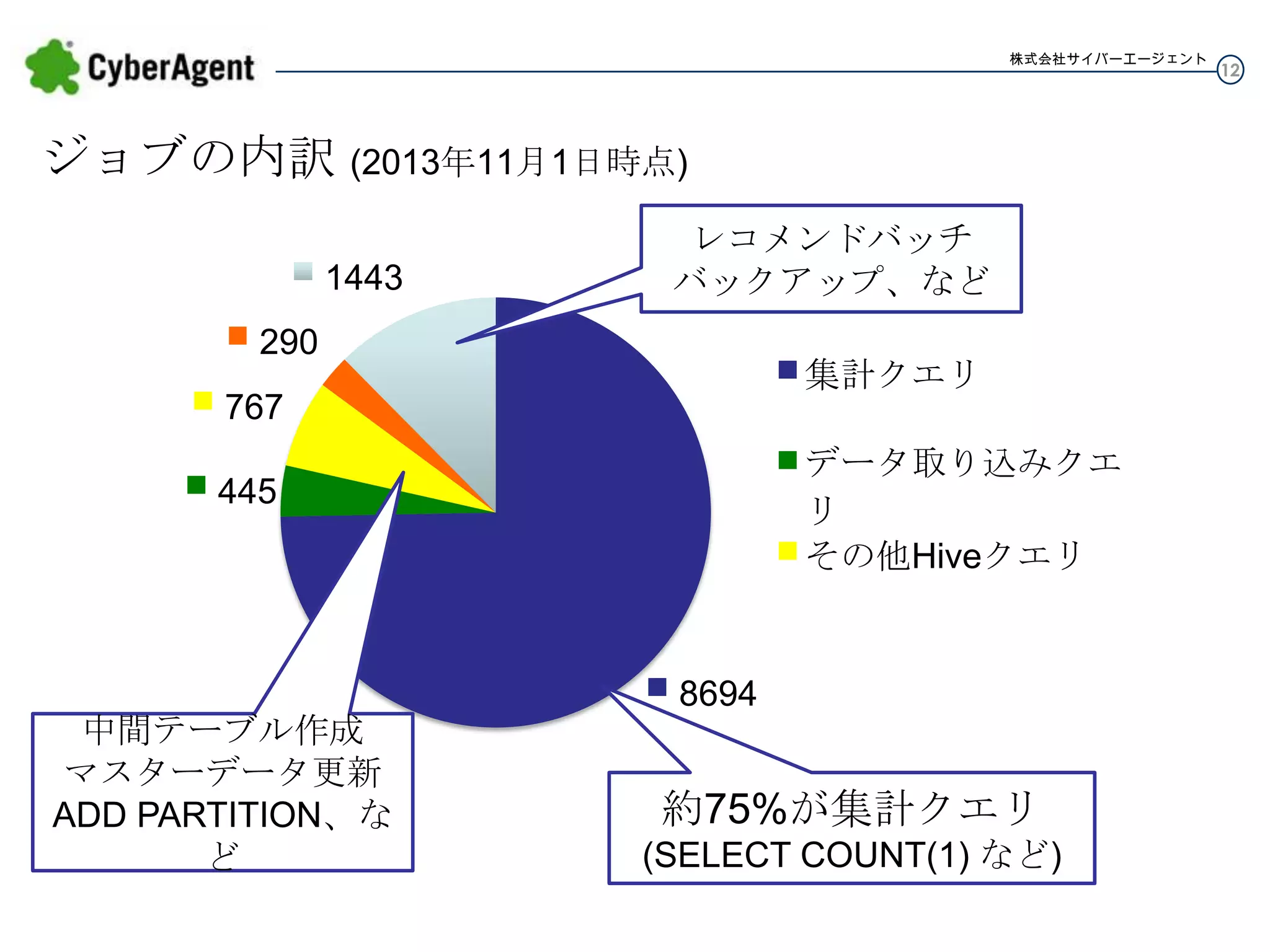
12.
株式会社サイバーエージェント ジョブの内訳 (2013年11月1日時点) 1443 レコメンドバッチ バックアップ、など 290 集計クエリ 767 データ取り込みクエリ 445 その他Hiveクエリ ログ転送 その他 8694 中間テーブル作成 マスターデータ更新 ADD PARTITION、など 約75%が集計クエリ (SELECT COUNT(1)
など) 12
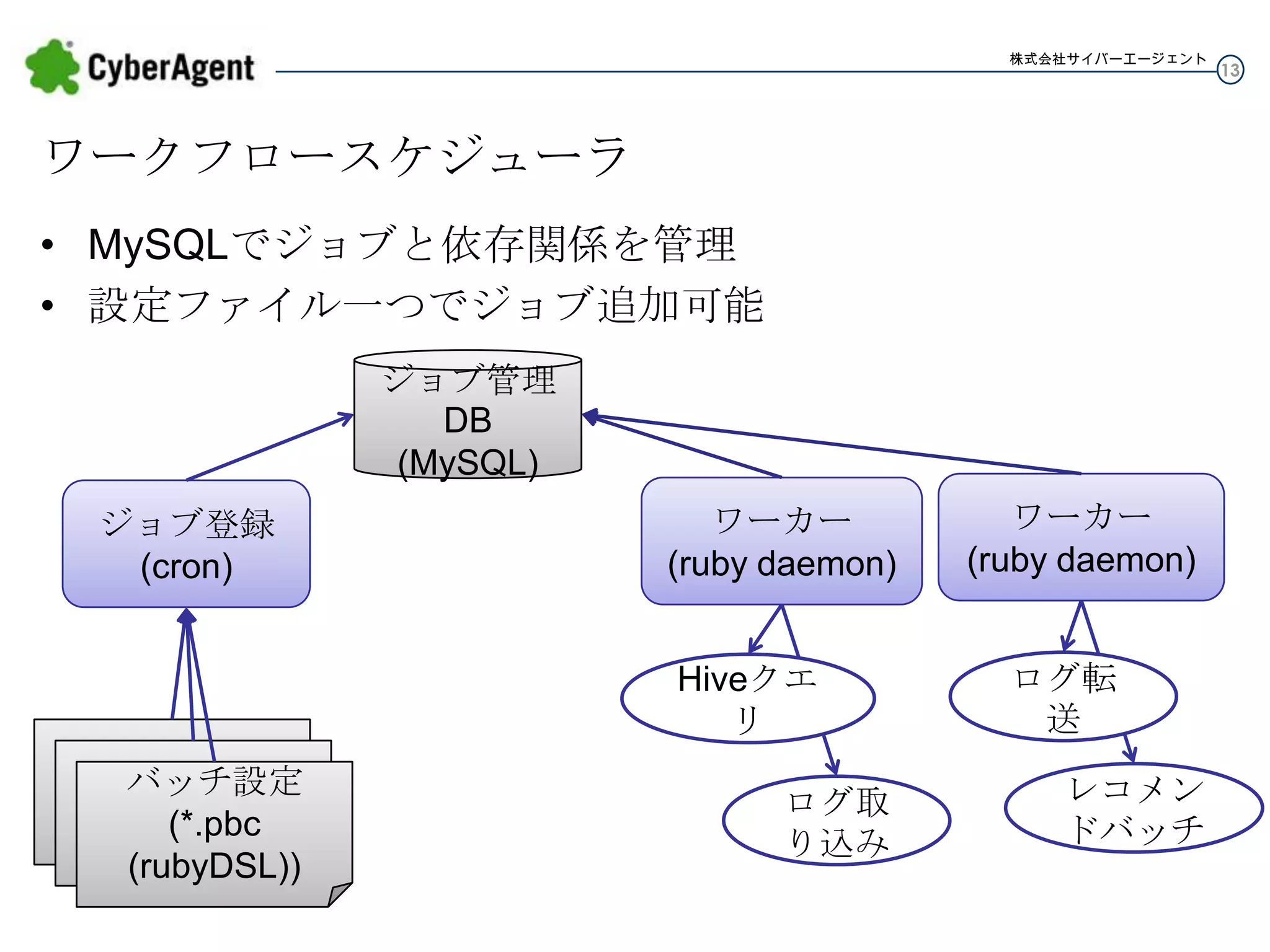
13.
株式会社サイバーエージェント ワークフロースケジューラ • MySQLでジョブと依存関係を管理 • 設定ファイル一つでジョブ追加可能 ジョブ管理DB (MySQL) ジョブ登録 (cron) ワーカー (ruby
daemon) Hiveクエリ (*.pbc バッチ設定 (*.pbc (rubyDSL)) (rubyDSL)) (*.pbc (rubyDSL)) ログ取り 込み ワーカー (ruby daemon) ログ転送 レコメンド バッチ 13
14.
株式会社サイバーエージェント ジョブ設定DSL • 柔軟なジョブのグループ化により細粒度の依存関係を簡潔に記述 • プラグインとしてコマンドを追加可能 ジョブをグループ化し job_group{ 依存関係を設定 require
['base_tbl_#{$dt}'] Hiveクエリを hivequery{ 実行するコマンド require ['tmp_tbl_#{date_sub($dt,1)}'] produce ['tmp_tbl_#{$dt}'] 日を跨ぐ hiveql 'INSERT OVERWRITE ...' 依存関係 } hive2hbase{ Hiveの結果を require ['tmp_tbl_#{$dt}'] HBaseにPutする hiveql 'SELECT count(distinct id) FROM ..' コマンド } } 14
15.
データ分析のためのPatriotの活用体制
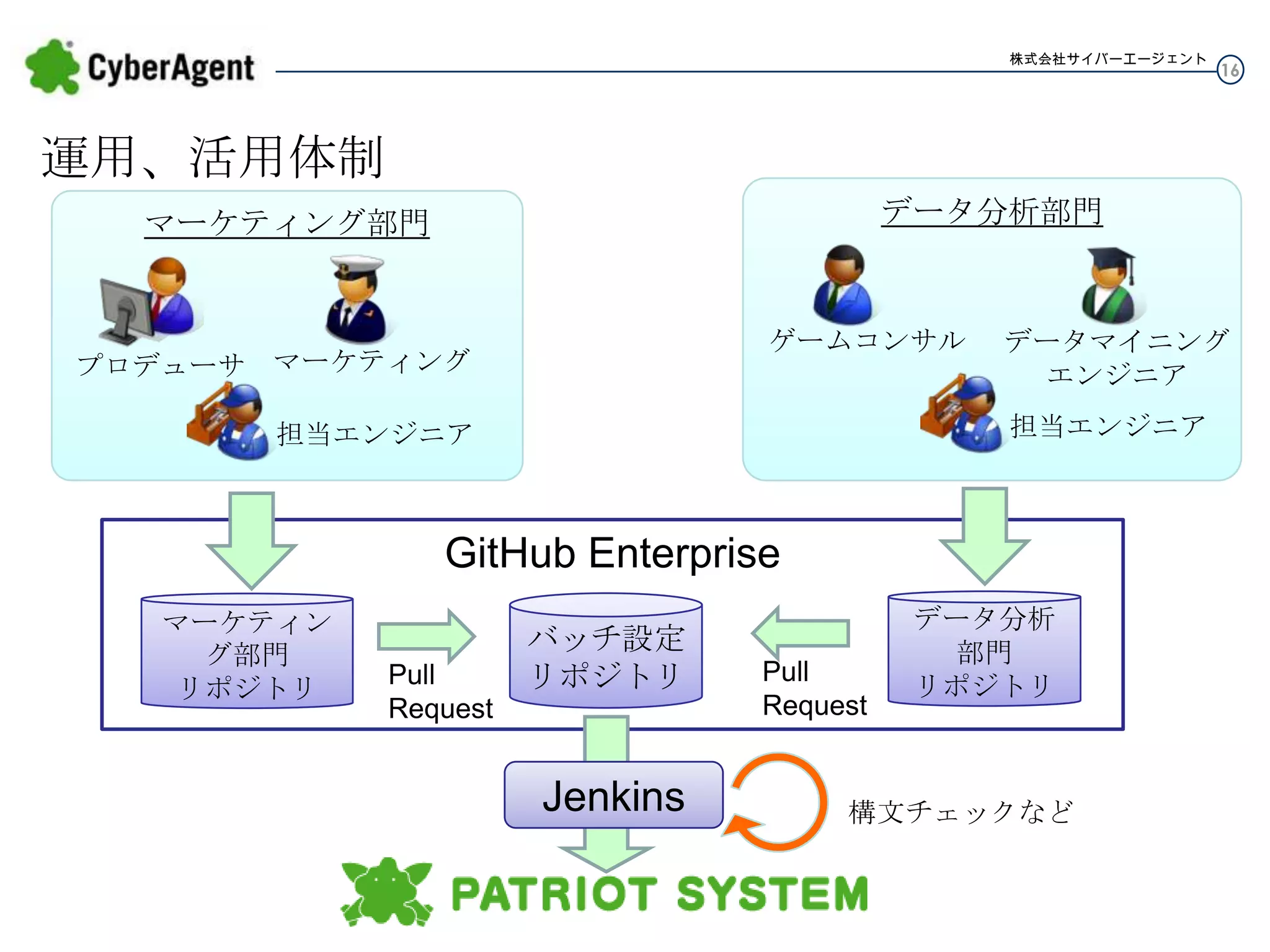
16.
株式会社サイバーエージェント 16 運用、活用体制 データ分析部門 マーケティング部門 ゲームコンサル プロデューサ マーケティング データマイニング エンジニア 担当エンジニア 担当エンジニア GitHub Enterprise マーケティング 部門 リポジトリ Pull Request バッチ設定 リポジトリ Jenkins Pull Request データ分析 部門 リポジトリ 構文チェックなど
17.
株式会社サイバーエージェント バッチ設定のレビュー •可能な部分はJenkinsで自動化 • 構文チェック • キーの重複検査 •テンプレートを用いた効率化 •
バッチ設定はERBテンプレートが利用可能 • 共通指標はテンプレート化しレビューを省略 •現在さらなる自動化を検討中 • クエリをパース・分析するライブラリを開発 • パーティションの選択の有無などレビュー時に必要な確認を自動化 • 最適化、リファクタリング • クエリの複雑さを計測 など 17
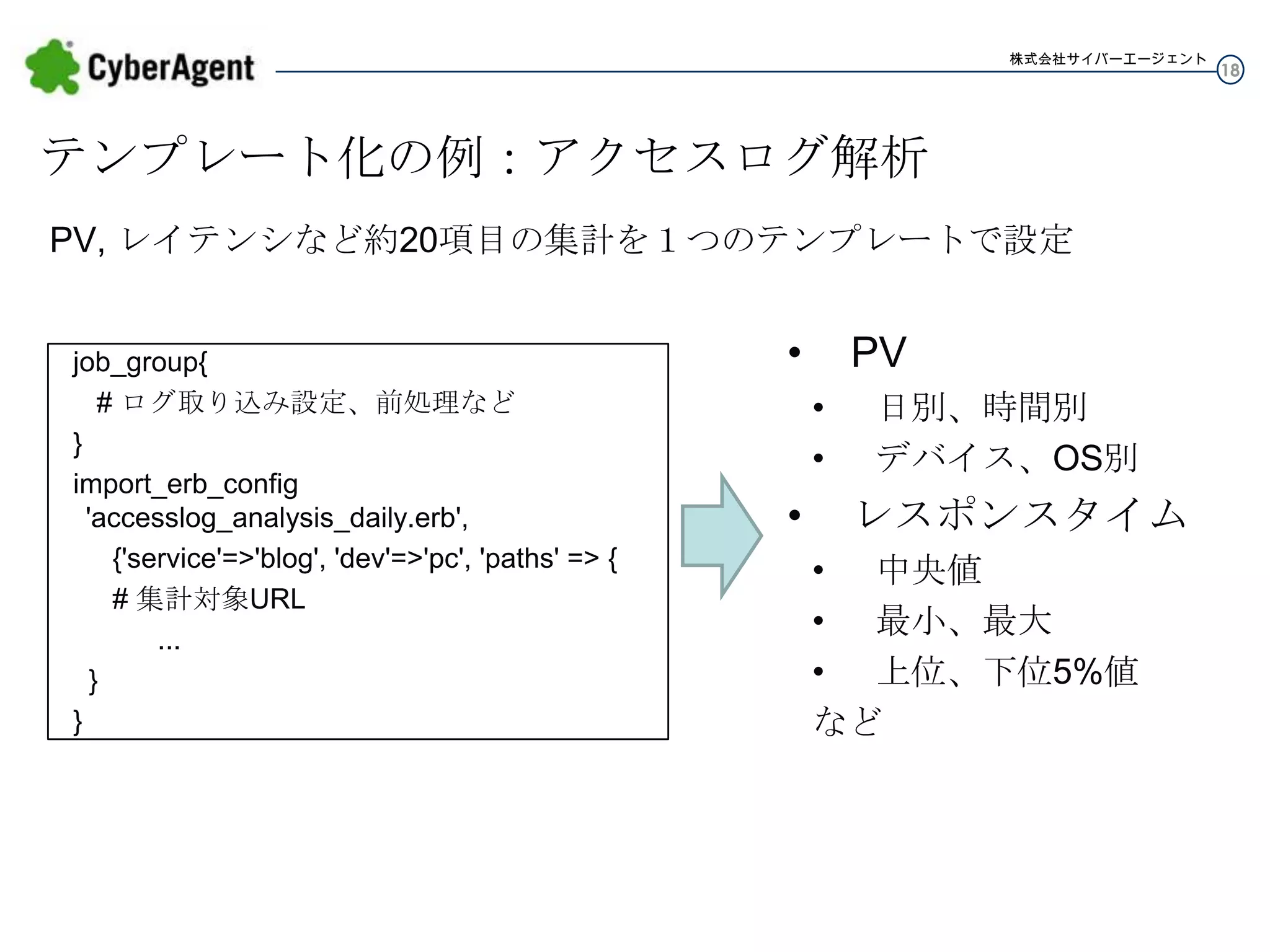
18.
株式会社サイバーエージェント テンプレート化の例:アクセスログ解析 PV, レイテンシなど約20項目の集計を1つのテンプレートで設定 job_group{ # ログ取り込み設定、前処理など } import_erb_config
'accesslog_analysis_daily.erb', {'service'=>'blog', 'dev'=>'pc', 'paths' => { # 集計対象URL ... } } • PV • • • 日別、時間別 デバイス、OS別 レスポンスタイム • 中央値 • 最小、最大 • 上位、下位5%値 など 18
19.
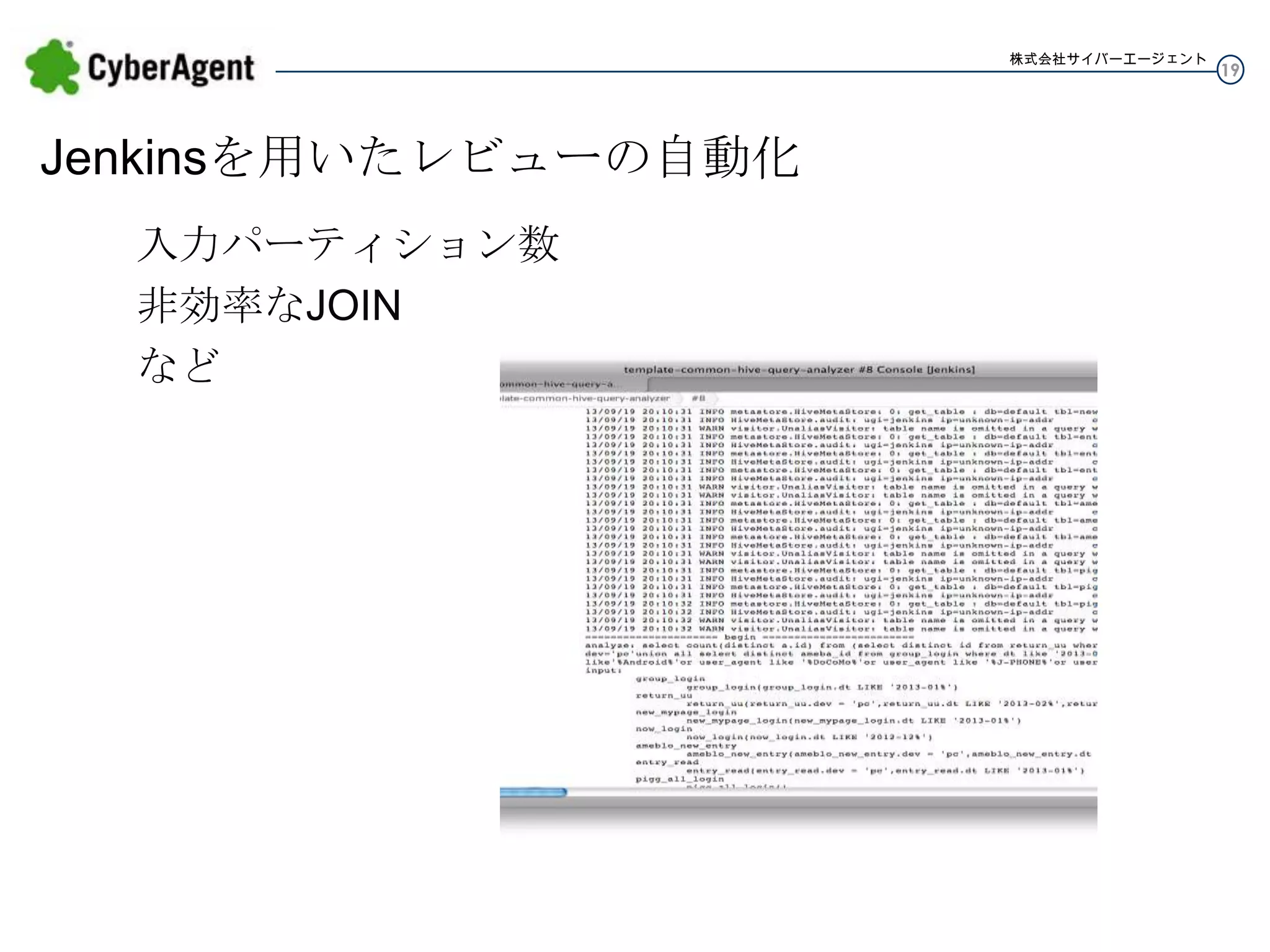
株式会社サイバーエージェント Jenkinsを用いたレビューの自動化 入力パーティション数 非効率なJOIN など 19
20.
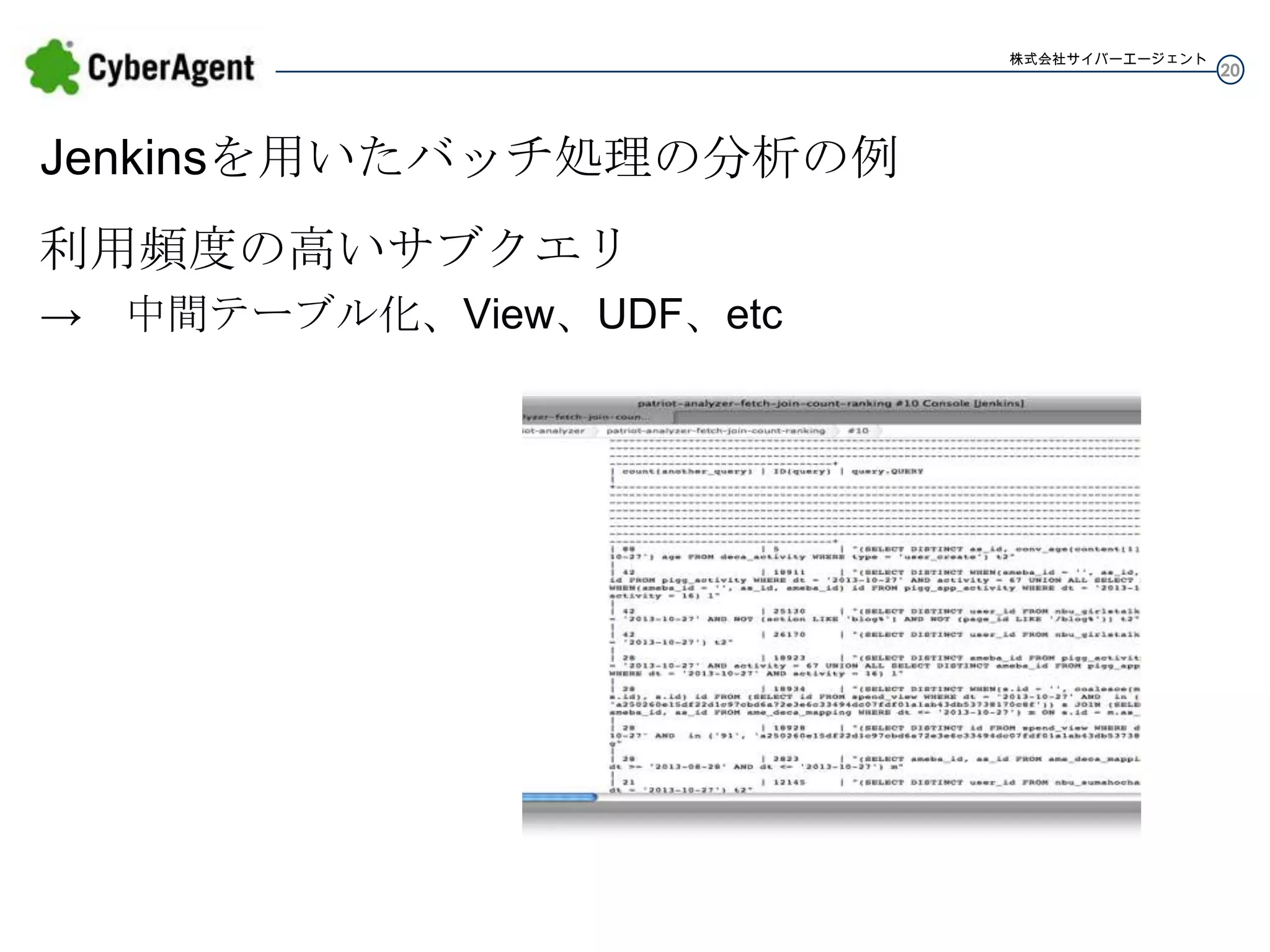
株式会社サイバーエージェント Jenkinsを用いたバッチ処理の分析の例 利用頻度の高いサブクエリ → 中間テーブル化、View、UDF、etc 20
21.
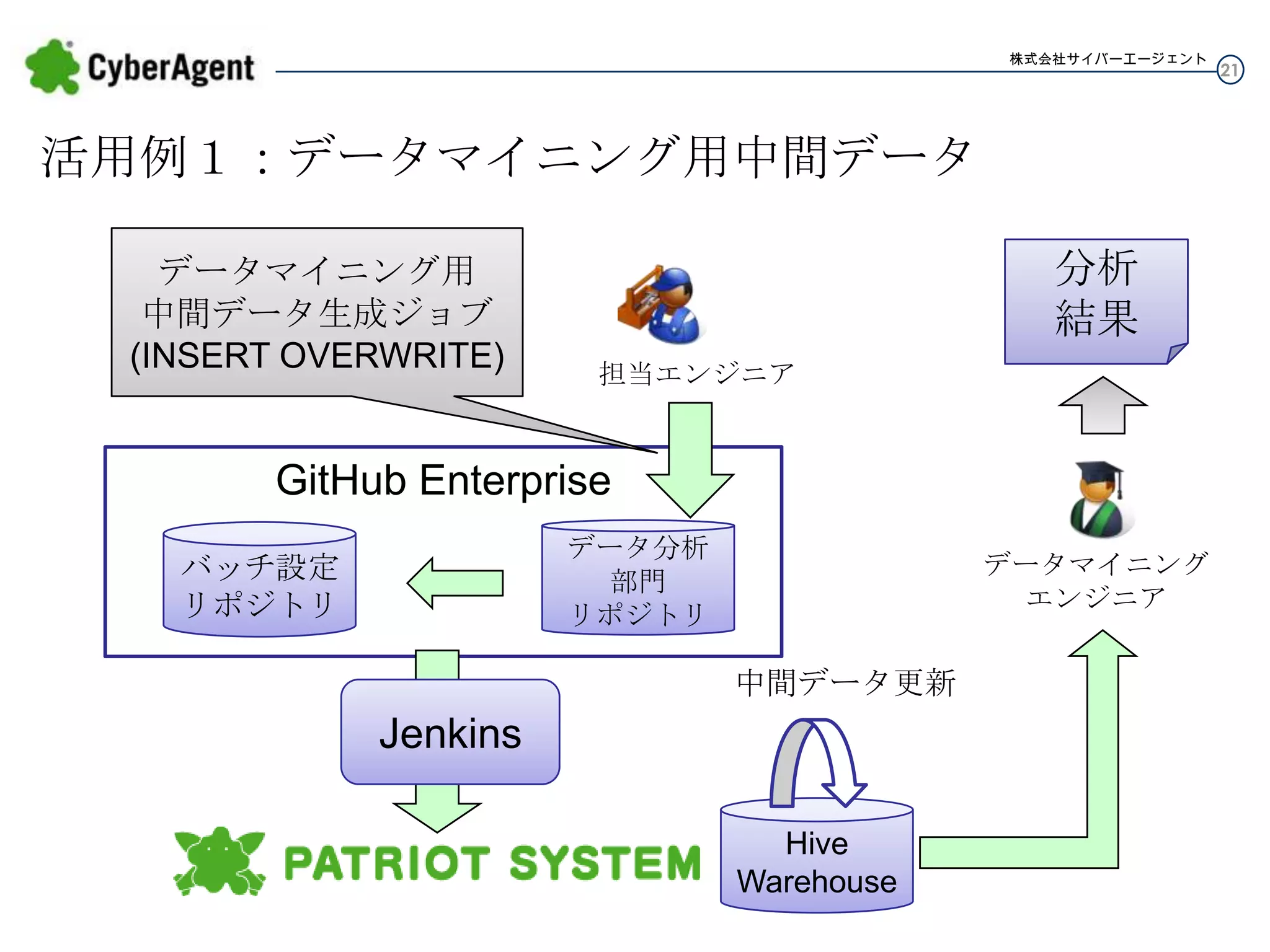
株式会社サイバーエージェント 活用例1:データマイニング用中間データ データマイニング用 中間データ生成ジョブ (INSERT OVERWRITE) 分析 結果 担当エンジニア GitHub Enterprise データ分析 部門 リポジトリ バッチ設定 リポジトリ データマイニング エンジニア 中間データ更新 Jenkins Hive Warehouse 21
22.
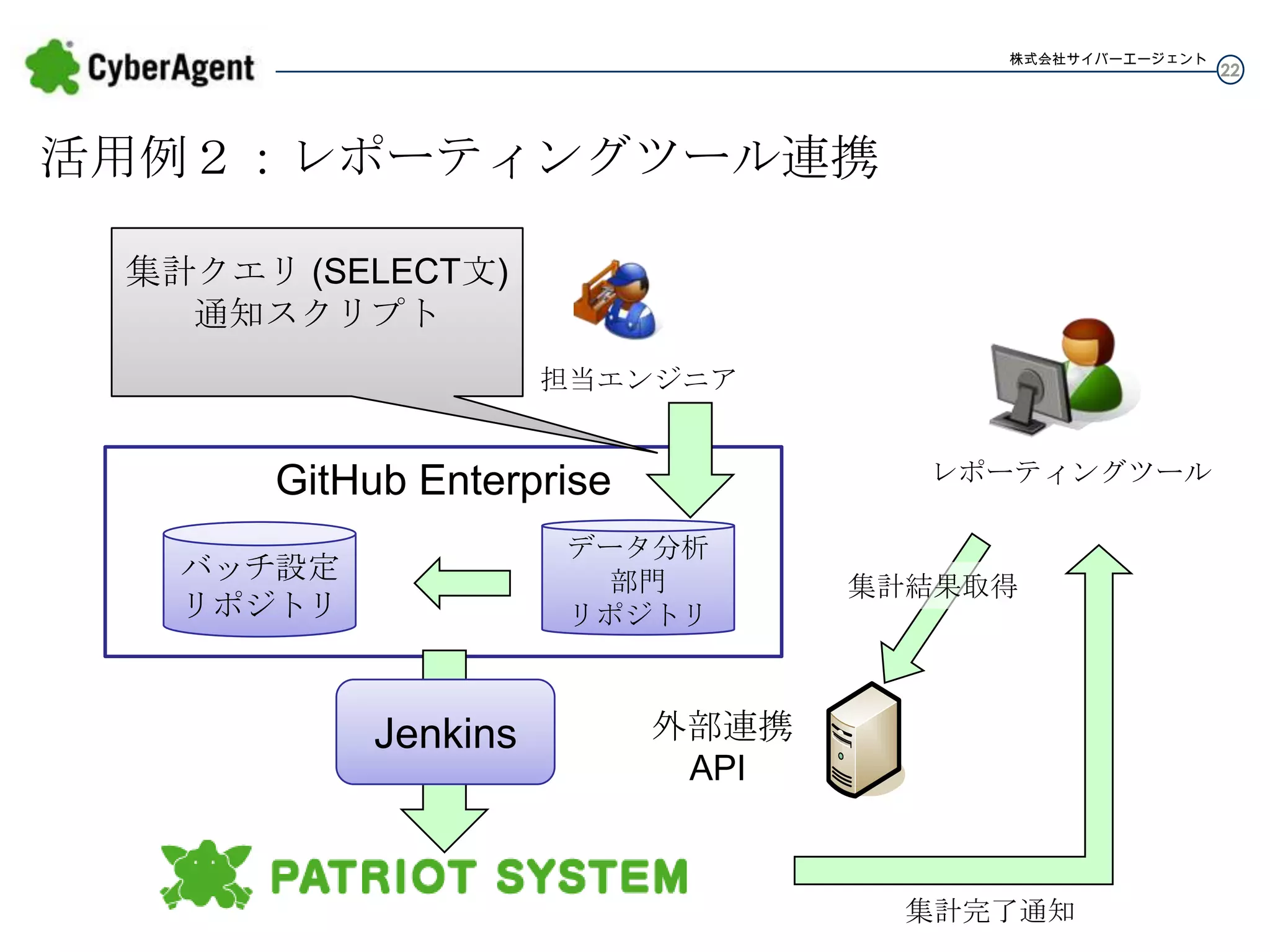
株式会社サイバーエージェント 活用例2:レポーティングツール連携 集計クエリ (SELECT文) 通知スクリプト 担当エンジニア レポーティングツール GitHub Enterprise データ分析 部門 リポジトリ バッチ設定 リポジトリ Jenkins 集計結果取得 外部連携 API 集計完了通知 22
23.
ログ転送システムと Apache Flume
24.
24 Patriotへのログ転送 • 2012.05以前 SCPでログ転送 •
2012.05 Scribeを使ったリアルタイムなログ転送を一部で開始 • 2012.10 ScribeをFlumeに置き換え、Amebaサービスに導入開始 • 2013.01 Patriot以外のシステムへの転送も開始 • 2013.09 主要AmebaサービスにほぼFlume導入完了 • 2013.11 Ameba SAP(CAグループ)のログ収集を計画中
25.
25 Patriotへのログ転送 • Flume導入サービス : 80
service (導入拡大中) • ログの種類 : 160 log type (service×log type) • 導入ホスト数 : 1,000 host • ピーク時 : 90,000 lines / sec • サイズ(Raw) : 1.0 TByte / day
26.
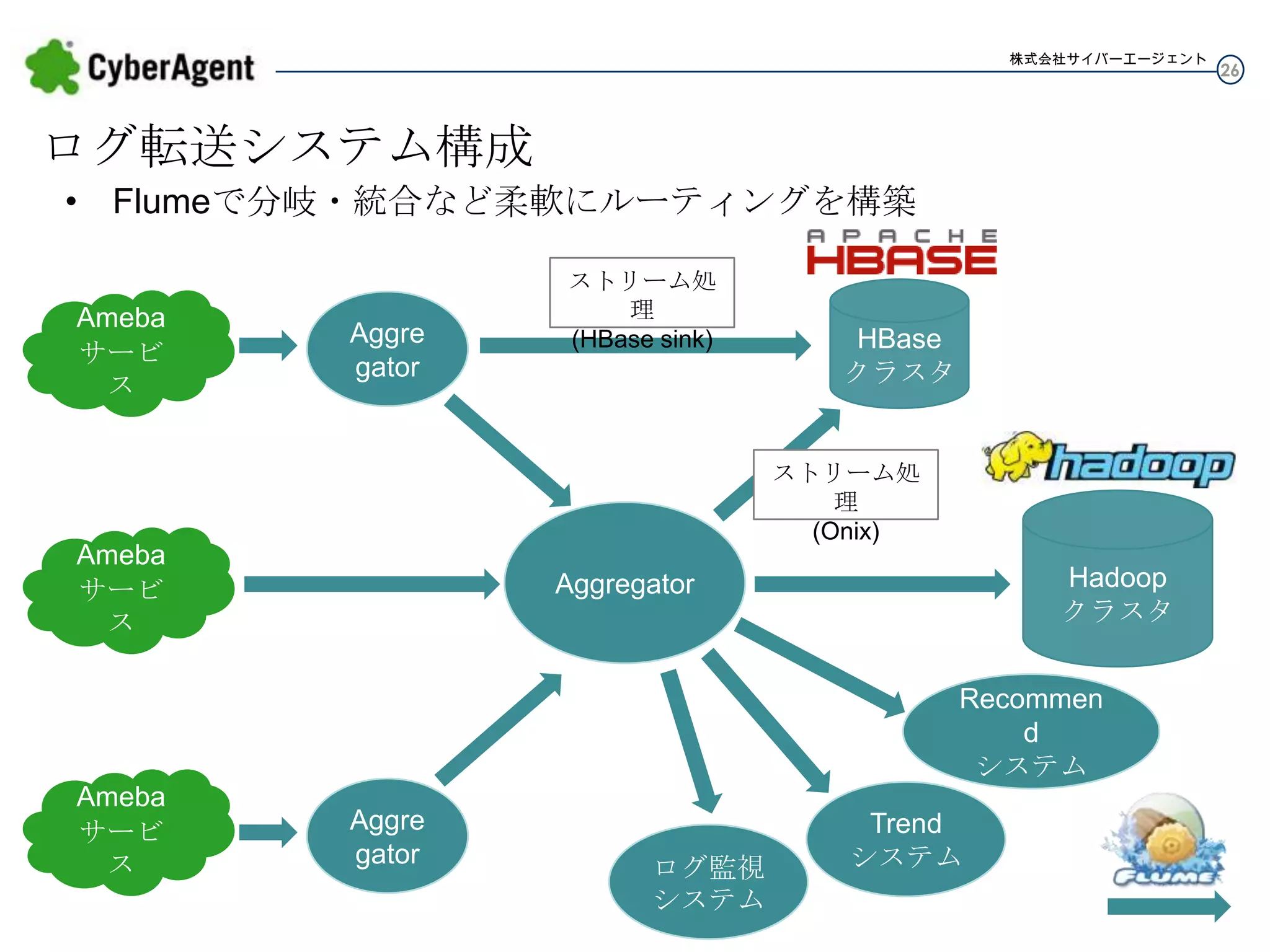
株式会社サイバーエージェント ログ転送システム構成 • Flumeで分岐・統合など柔軟にルーティングを構築 Ameba サービス Aggre gator ストリーム処理 (HBase sink) HBase クラスタ ストリーム処理 (Onix) Ameba サービス Hadoop クラスタ Aggregator Recommend システム Ameba サービス Aggre gator ログ監視 システム Trend システム 26
27.
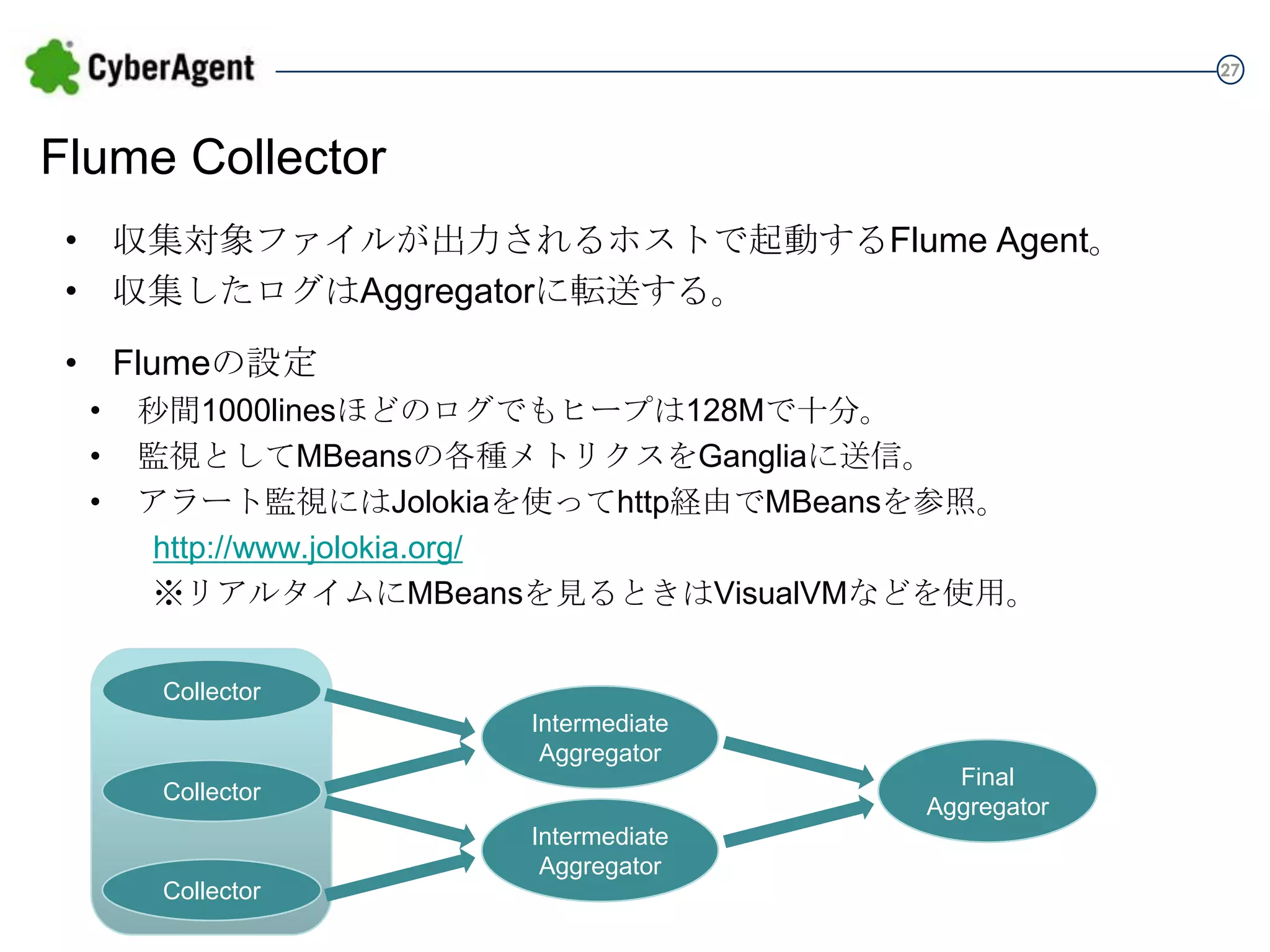
27 Flume Collector • 収集対象ファイルが出力されるホストで起動するFlume
Agent。 • 収集したログはAggregatorに転送する。 • Flumeの設定 • • • 秒間1000linesほどのログでもヒープは128Mで十分。 監視としてMBeansの各種メトリクスをGangliaに送信。 アラート監視にはJolokiaを使ってhttp経由でMBeansを参照。 http://www.jolokia.org/ ※リアルタイムにMBeansを見るときはVisualVMなどを使用。 Collector Intermediate Aggregator Collector Intermediate Aggregator Collector Final Aggregator
28.
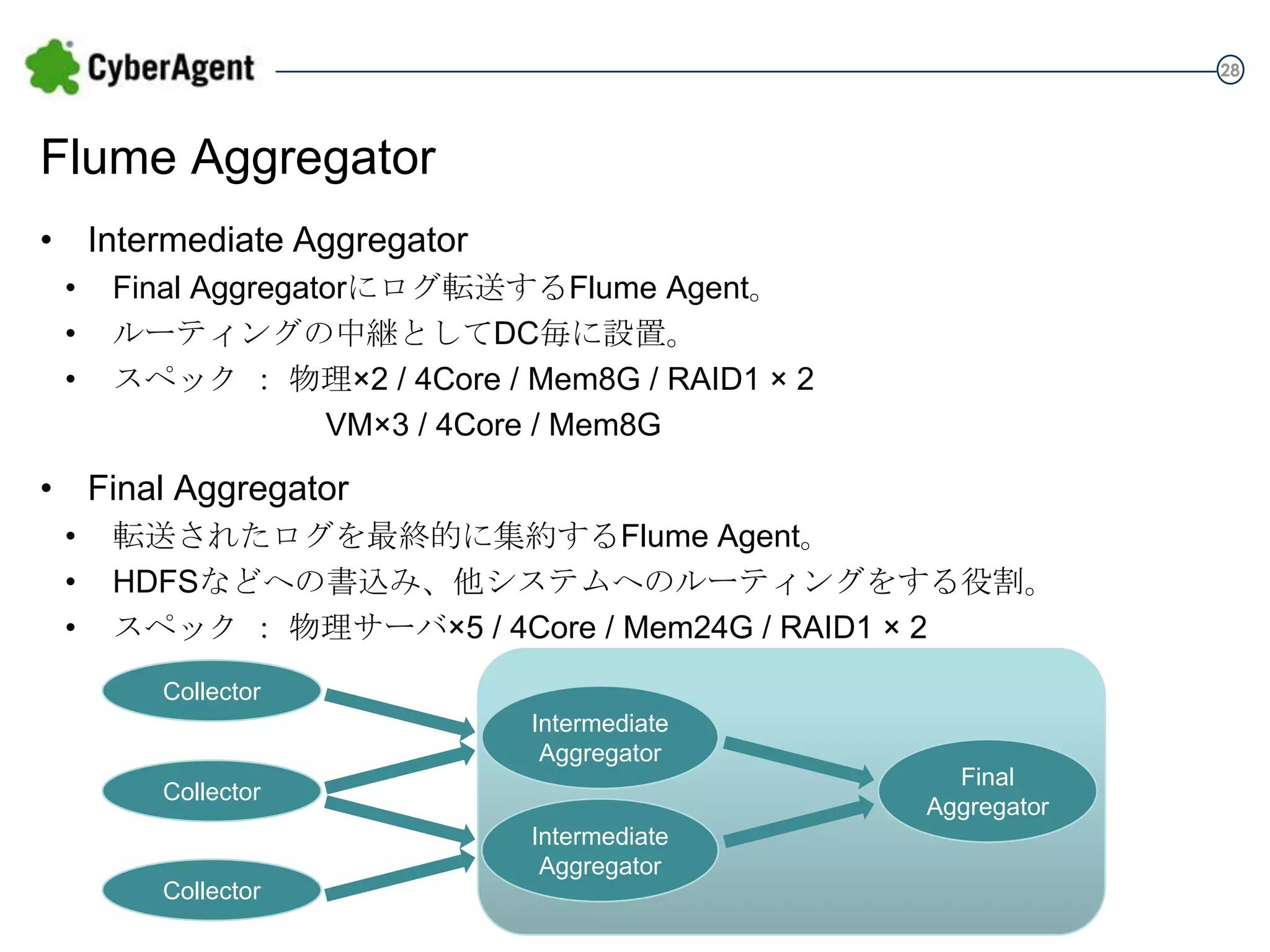
28 Flume Aggregator • Intermediate
Aggregator • • • Final Aggregatorにログ転送するFlume Agent。 ルーティングの中継としてDC毎に設置。 スペック : 物理×2 / 4Core / Mem8G / RAID1 × 2 VM×3 / 4Core / Mem8G • Final Aggregator • • • 転送されたログを最終的に集約するFlume Agent。 HDFSなどへの書込み、他システムへのルーティングをする役割。 スペック : 物理サーバ×5 / 4Core / Mem24G / RAID1 × 2 Collector Intermediate Aggregator Collector Intermediate Aggregator Collector Final Aggregator
29.
29 ログ転送で使っている機能 • Channel Selector :
他システムへの振り分け、Multiplexing • TimeStamp Bucket : 日時などでBucketingしてHDFSに書込み • Reset Connection : LoadBalancer経由のログ転送 • Deflate Compression : 圧縮転送 • HBase sink : HBaseに書込み • File Channel : ロストを許さないログで使用(集計 / 監視) • Memory Channel : 若干のロストを許容するログで使用 (Recommend / Trend)
30.
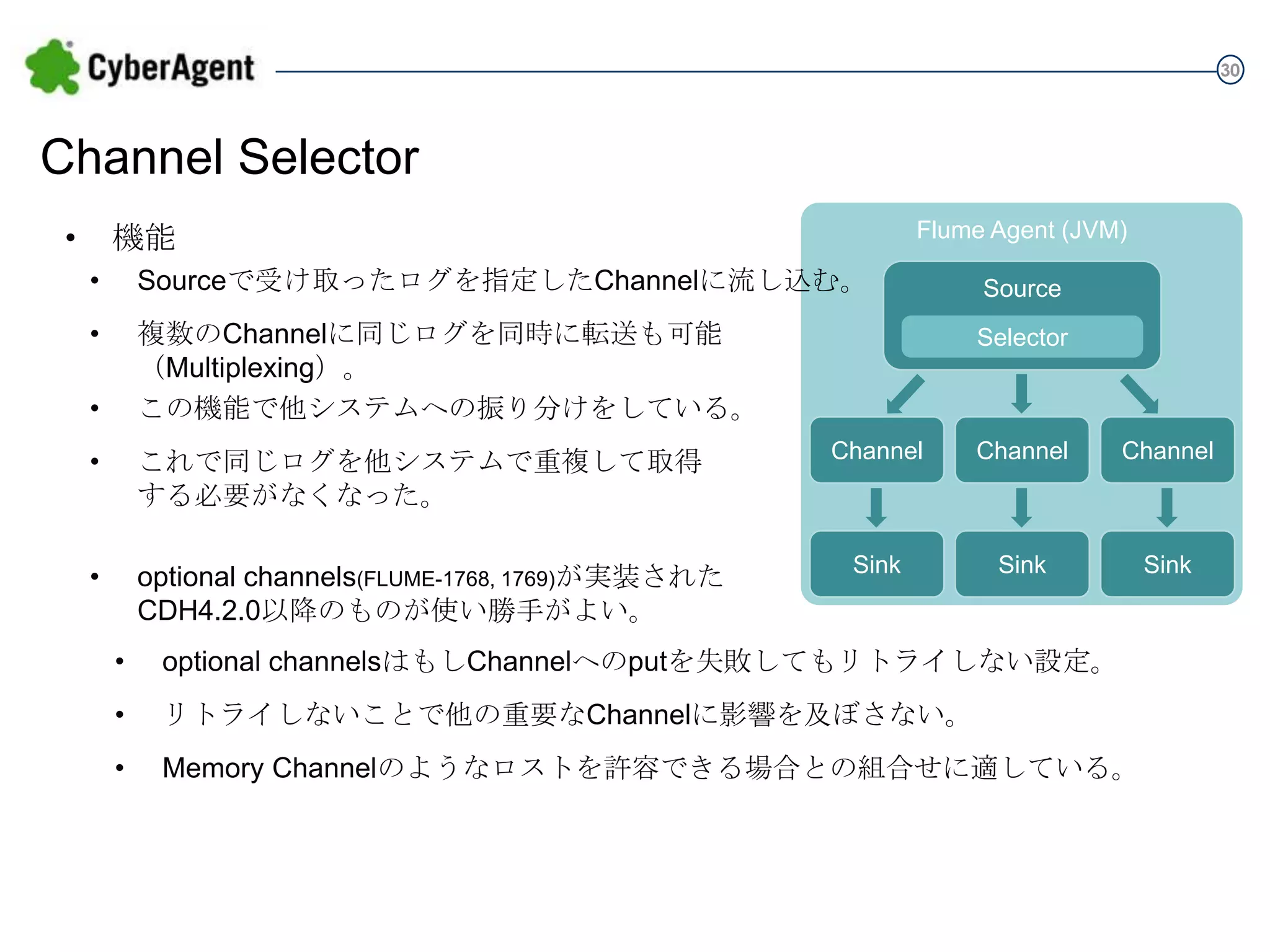
30 Channel Selector • Flume Agent
(JVM) 機能 • Sourceで受け取ったログを指定したChannelに流し込む。 Source • 複数のChannelに同じログを同時に転送も可能 (Multiplexing)。 この機能で他システムへの振り分けをしている。 Selector • • これで同じログを他システムで重複して取得 する必要がなくなった。 • optional channels(FLUME-1768, 1769)が実装された CDH4.2.0以降のものが使い勝手がよい。 Channel Channel Channel Sink Sink Sink • optional channelsはもしChannelへのputを失敗してもリトライしない設定。 • リトライしないことで他の重要なChannelに影響を及ぼさない。 • Memory Channelのようなロストを許容できる場合との組合せに適している。
31.
31 TimeStamp Bucket (HDFS
Sinkの機能) • 機能 • HDFSに書込みむとき、ログのHeaderのTimeStampを元に日付や時間で 正確にBucketingできる。 hdfs://namenode/flume/%{header1}/%{header2}/%Y-%m-%d/%H/ • TimeStampをsetするInterceptorについて • • Flumeの TimestampInterceptor では転送時の現在時刻をTimeStampとするが ログの日時をパースするように自社でInterceptorを独自実装。 JSON、TSV、Syslogなど多様なログに対応。
32.
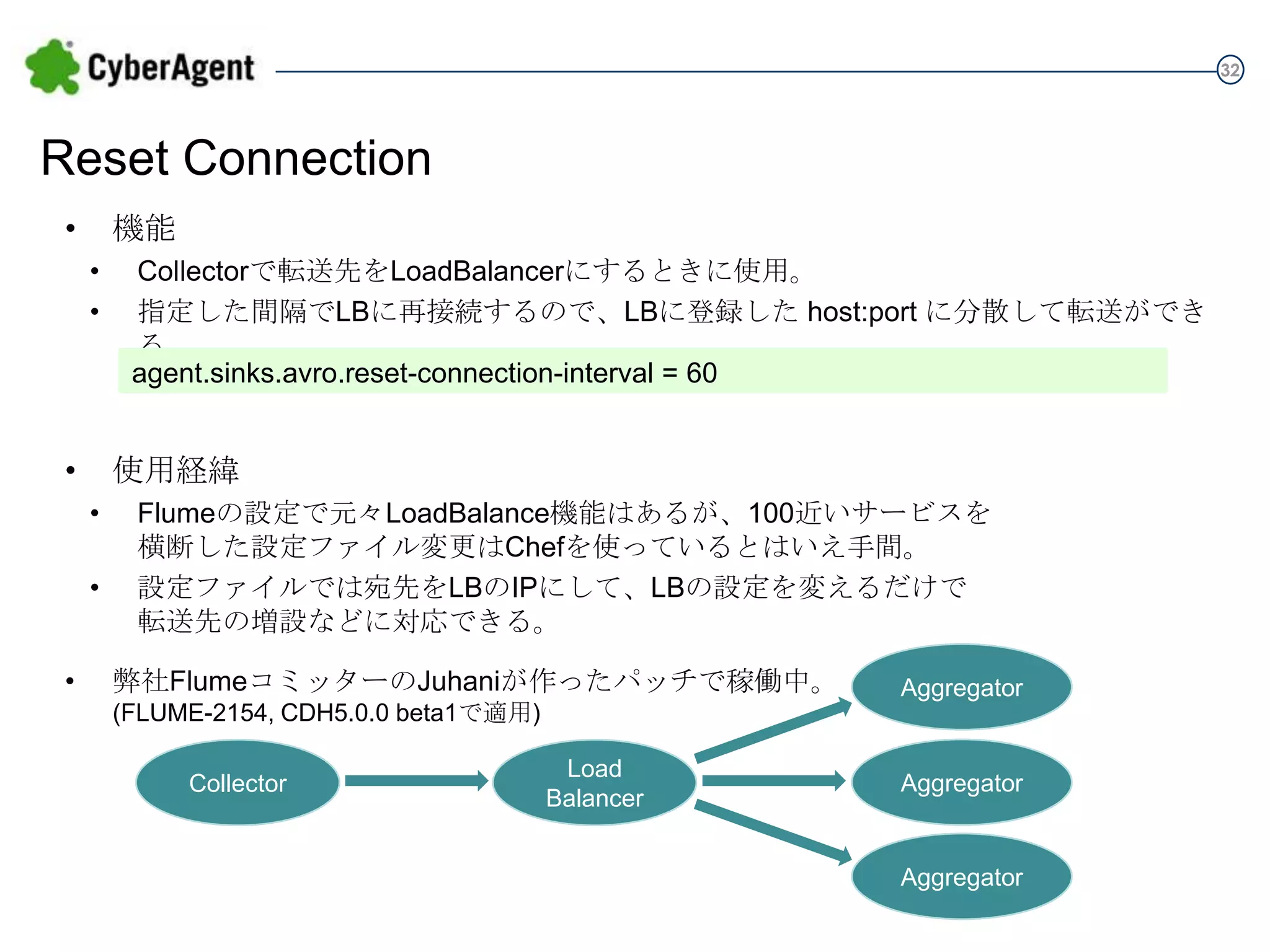
32 Reset Connection • 機能 • • Collectorで転送先をLoadBalancerにするときに使用。 指定した間隔でLBに再接続するので、LBに登録した host:port
に分散して転送ができる。 agent.sinks.avro.reset-connection-interval = 60 • 使用経緯 • • • Flumeの設定で元々LoadBalance機能はあるが、100近いサービスを 横断した設定ファイル変更はChefを使っているとはいえ手間。 設定ファイルでは宛先をLBのIPにして、LBの設定を変えるだけで 転送先の増設などに対応できる。 弊社FlumeコミッターのJuhaniが作ったパッチで稼働中。 (FLUME-2154, CDH5.0.0 beta1で適用) Collector Load Balancer Aggregator Aggregator Aggregator
33.
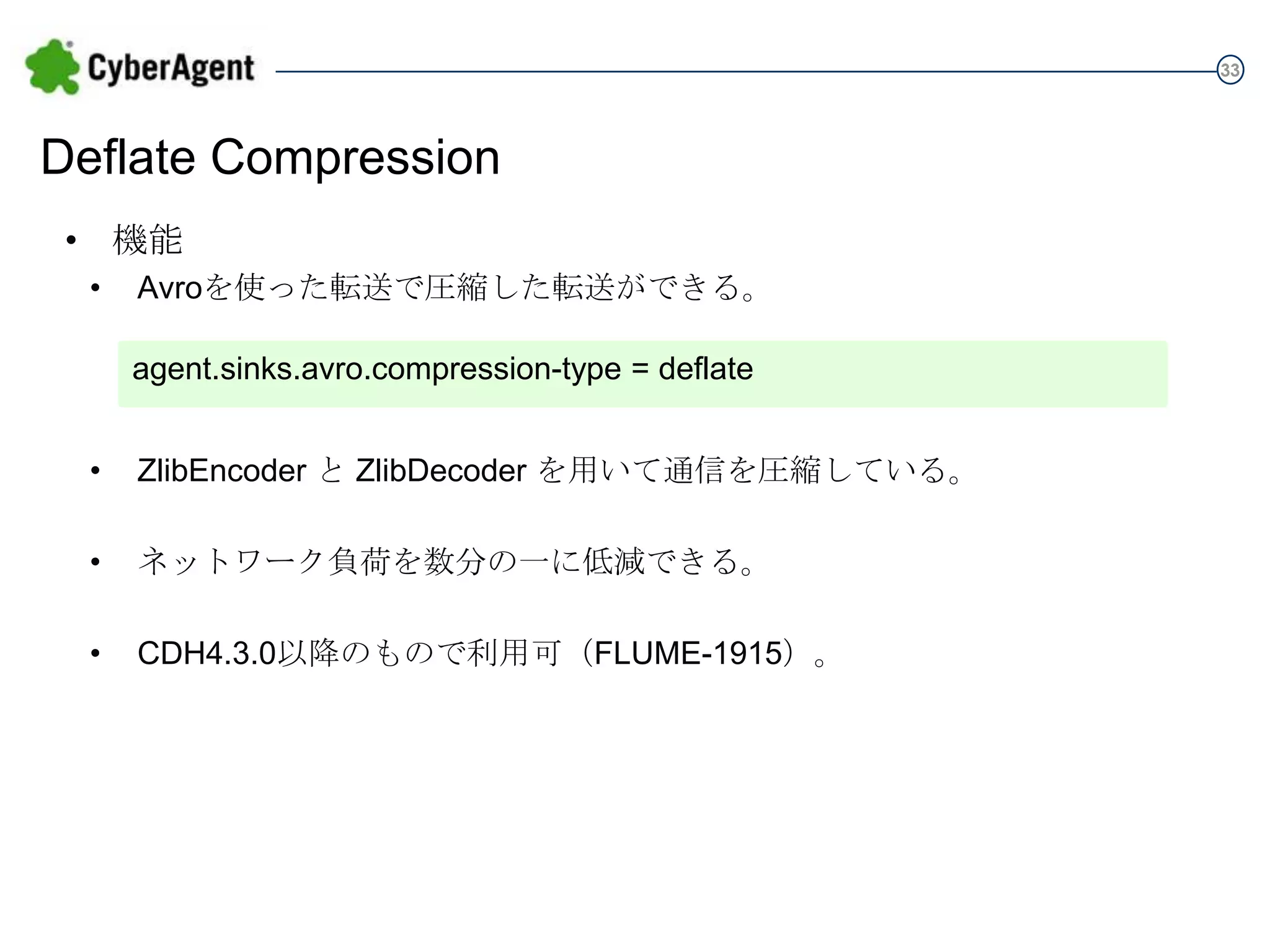
33 Deflate Compression • 機能 • Avroを使った転送で圧縮した転送ができる。 agent.sinks.avro.compression-type
= deflate • ZlibEncoder と ZlibDecoder を用いて通信を圧縮している。 • ネットワーク負荷を数分の一に低減できる。 • CDH4.3.0以降のもので利用可(FLUME-1915)。
34.
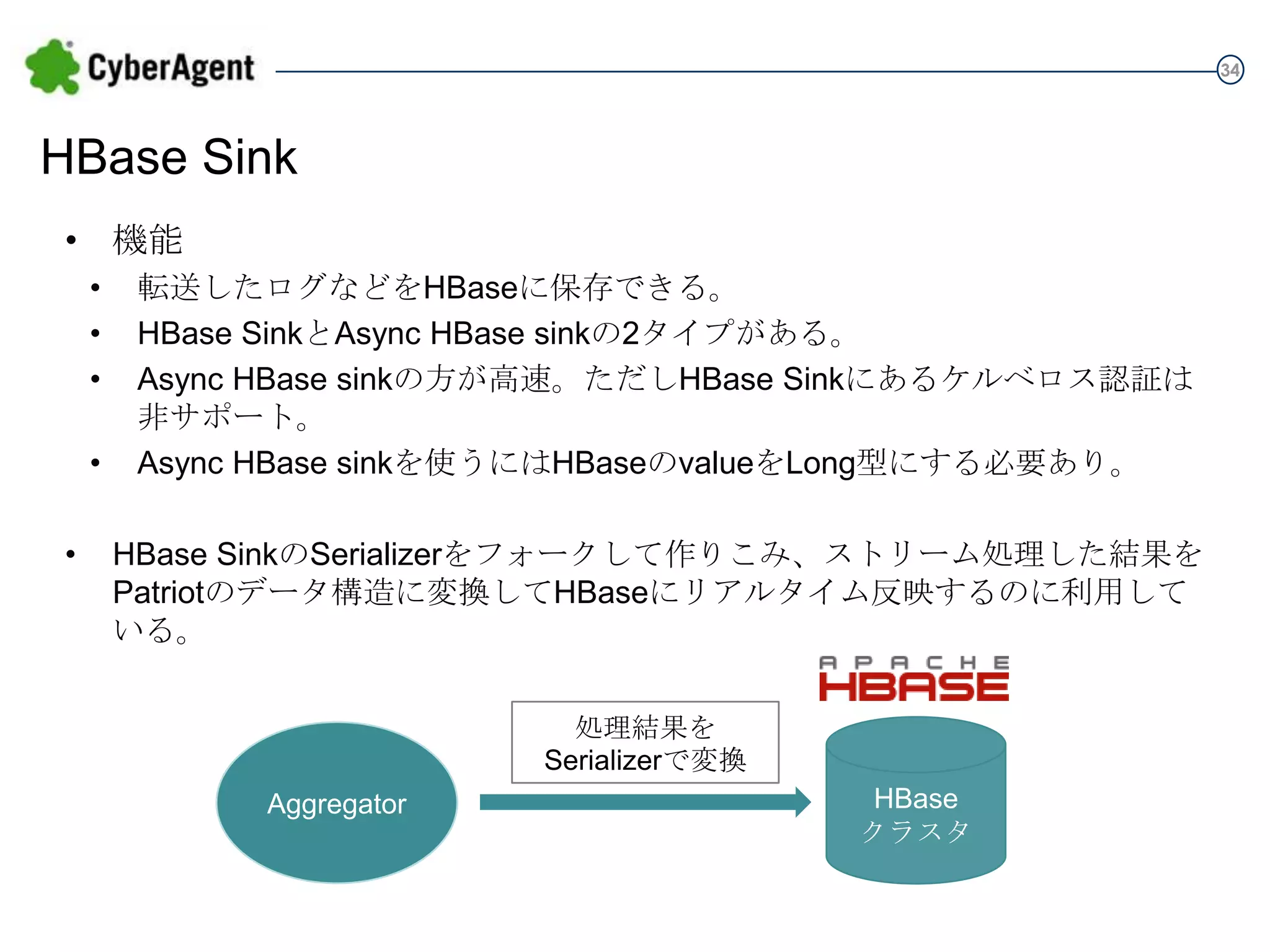
34 HBase Sink • 機能 • • • • • 転送したログなどをHBaseに保存できる。 HBase
SinkとAsync HBase sinkの2タイプがある。 Async HBase sinkの方が高速。ただしHBase Sinkにあるケルベロス認証は 非サポート。 Async HBase sinkを使うにはHBaseのvalueをLong型にする必要あり。 HBase SinkのSerializerをフォークして作りこみ、ストリーム処理した結果を Patriotのデータ構造に変換してHBaseにリアルタイム反映するのに利用している。 処理結果を Serializerで変換 Aggregator HBase クラスタ
35.
35 コンポーネントのカスタマイズ • カスタマイズしたコンポーネントをFlumeに簡単に組み込める。 • Jarファイルにして
/usr/lib/flume/lib などに配布して 下記のように指定する。 • このようにしてFlume自体に実装されてない機能、独自システムとの 連携などに対応できる。 # example agent.xxx.custom.type = [カスタマイズしたClass名やMethod名など] agent.xxx.custom.channel = ch1 agent.xxx.custom.port = 12345 ※ xxx : sources, channels, sinks などのコンポーネント
36.
36 コンポーネントのカスタマイズ - HBase
Sink • typeには自分で作ったClass名を指定。 ※ type = hbase と指定した場合はデフォルトのHBase Sinkになる。 • serializerのみClass指定することもできる。 • 設定項目もカスタマイズできる。 agent.sinks.hbase.type = jp.co.cyberagent.flume.sink.hbase.PatriotHBaseSink agent.sinks.hbase.serializer = jp.co.cyberagent.flume.sink.hbase.PatriotSerializer agent.sinks.hbase.channel = ch1 agent.sinks.hbase.table = table_name agent.sinks.hbase.columnFamily = data agent.sinks.hbase.custom = custom 処理結果を Serializerで変換 Aggregator HBase クラスタ
37.
37 コンポーネントのカスタマイズ - Channel
Selector Flume Agent (JVM) • デフォルトのSelectorは1headerでのみの判別になるが、 複数headerをみてChannelに流し込むようにカスタマイズ。 Source Selector • 設定例 • applog で、サービス名が「girlfriend」、行動タイプが spend のログは hdfs-ch と spend-ch の両方に流し込み、 • applog.girlfriend.spend default trend-log は trend-ch に流し込み、 • trend-log それ以外のログはデフォルトで hdfs-ch だけに流し込む設定。 trend-ch hdfs-ch spend-ch Sink Sink Sink agent.sources.avro.selector.type = jp.co.cyberagent.flume.selector.MultiHeaderSelector agent.sources.avro.selector.headers = category,service,type agent.sources.avro.selector.required.trend-log = trend-ch agent.sources.avro.selector.required.applog.girlfriend.spend = hdfs-ch spend-ch agent.sources.avro.selector.default = hdfs-ch
38.
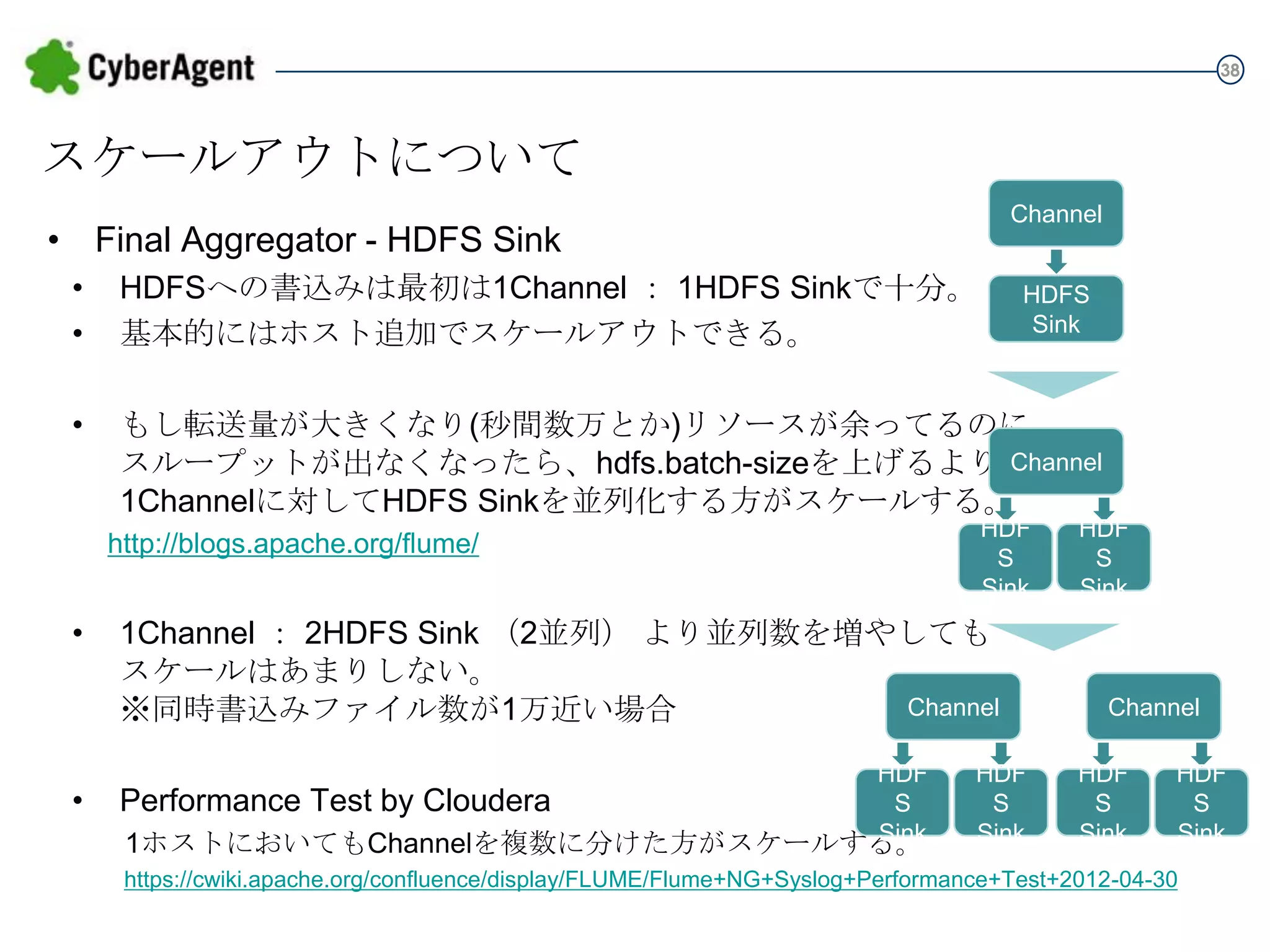
38 スケールアウトについて Channel • Final Aggregator
- HDFS Sink • • HDFSへの書込みは最初は1Channel : 1HDFS Sinkで十分。 基本的にはホスト追加でスケールアウトできる。 • もし転送量が大きくなり(秒間数万とか)リソースが余ってるのに スループットが出なくなったら、hdfs.batch-sizeを上げるより 1Channelに対してHDFS Sinkを並列化する方がスケールする。 http://blogs.apache.org/flume/ • • 1ホストにおいてもChannelを複数に分けた方がスケールする。 Channel HDFS Sink 1Channel : 2HDFS Sink (2並列) より並列数を増やしても スケールはあまりしない。 ※同時書込みファイル数が1万近い場合 Performance Test by Cloudera HDFS Sink Channel HDFS Sink HDFS Sink HDFS Sink Channel HDFS Sink HDFS Sink https://cwiki.apache.org/confluence/display/FLUME/Flume+NG+Syslog+Performance+Test+2012-04-30
39.
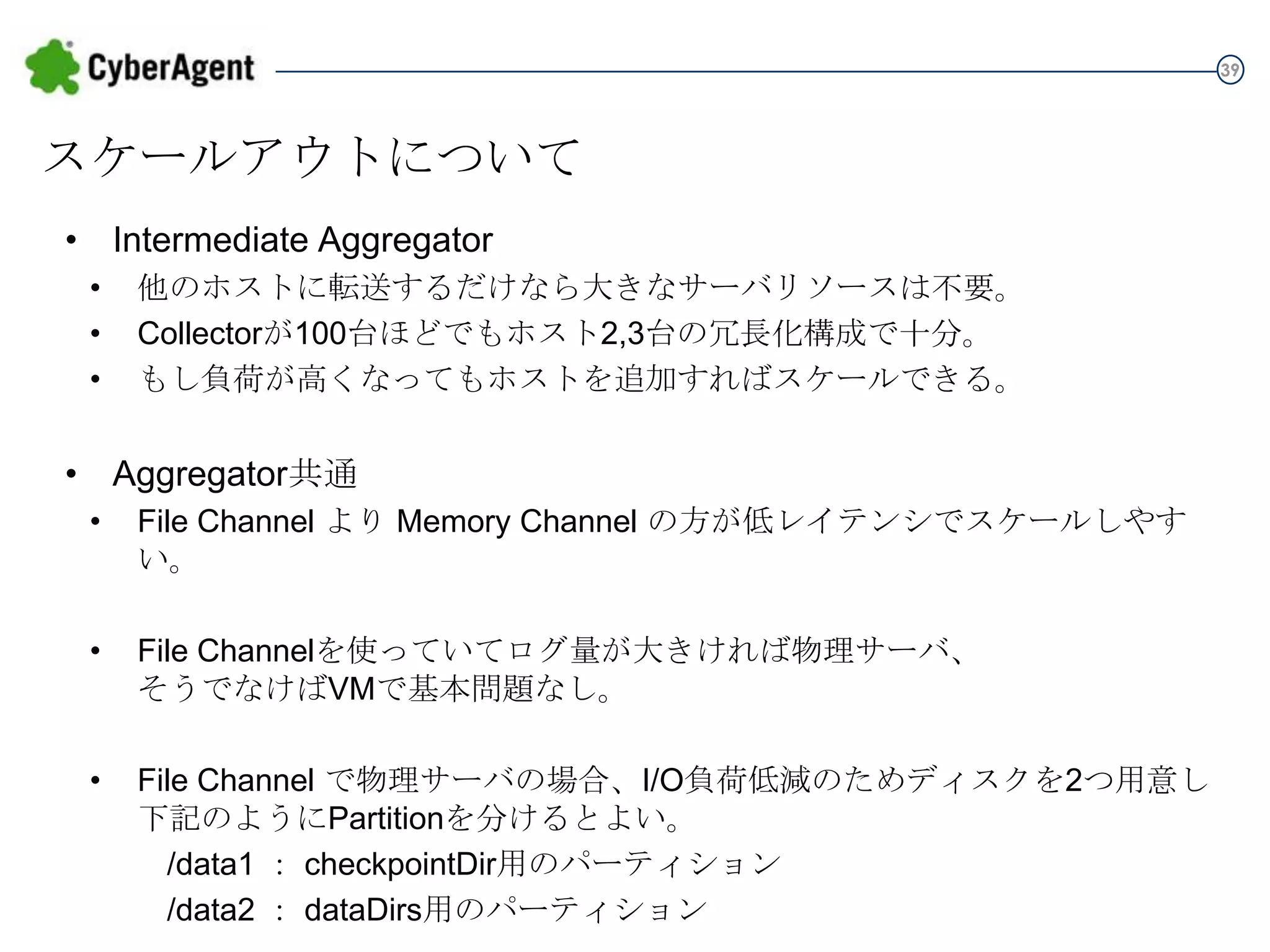
39 スケールアウトについて • Intermediate Aggregator • • • 他のホストに転送するだけなら大きなサーバリソースは不要。 Collectorが100台ほどでもホスト2,3台の冗長化構成で十分。 もし負荷が高くなってもホストを追加すればスケールできる。 •
Aggregator共通 • File Channel より Memory Channel の方が低レイテンシでスケールしやすい。 • File Channelを使っていてログ量が大きければ物理サーバ、 そうでなけばVMで基本問題なし。 • File Channel で物理サーバの場合、I/O負荷低減のためディスクを2つ用意し 下記のようにPartitionを分けるとよい。 /data1 : checkpointDir用のパーティション /data2 : dataDirs用のパーティション
40.
40 HDFSに保存したログの重複について • HDFS Client にはトランザクションの仕組みがなく、HDFSとの通信で タイムアウトなどが起こると、成功したか分からないものは処理を やり直すため若干の重複が起こりえる。 • HDFSに書き込む
batch-size が大きいほど重複は起こりやすい。 • 重複率は0%〜0.005%程度。 ※秒間1000linesほどのWebサーバのログ、batch-size=100の設定で調べた結果。 • 重複を許容できなければMapReduceでユニークにするなどで対応する。 • 逆にデータのロストは File Channel を使えば発生しない。 ※Memory Channelは停止前にChannelにデータがあれば、 その分は失われるしまう。その代わり、パフォーマンスが高い。
41.
41 過去のトラブル解決 • HDFSへの同時書込みファイル数のlimitに達した • • Flume Aggr側
: ulimitの上限を65536に変更。 DataNode側 : Xceiverの上限引き上げ。 • 起動時のReplayに時間がかかる場合 • • ChannelSizeが数千万以上溜まったときに稀に発生。 use-fast-replayをtrueにするなど他のReplay方式を試すと速く終わることも。 • File ChannelのCheckPointでファイルのlock取得でタイムアウト • • • I/O負荷が高いホストで発生。 I/O負荷の原因となっている元を解消する。 もしくはFile Channelの設定で write-timeout の値を引き上げ(default:3秒)。
42.
42 今後の展望 • Flume導入範囲の拡大 • SSL通信機能(FLUME-997,
CDH4.4.0で実装)の検証 • Final Aggregatorの負荷軽減 • HDFS上に作るファイル単位ごとに担当するAggregatorを振り分ければ より少ないサーバリソースでHDFSへ書込みできそう。
43.
43 まとめ • Amebaのログ解析基盤Patriotについて • GithubEnterpriseとJenkinsを用いて他部門が利用できる体制 •
データマイニングエンジニアやレポーティングツールとの連携 • FlumeでHadoopクラスタへリアルタイムに大規模なログ転送を実現 • HDFSへの書込みだけでなく、一度のログ転送で同時に他システムへ ログを流し込み、ネットワーク負荷を軽減
44.
44 最後に • 以前の発表 • Patriot
(Hadoop Conference 2011 winter) http://www.slideshare.net/toutouzone/hadoop-conferencejapan2011 • Flume (Hadoop Conference 2013 winter) http://www.slideshare.net/iijiji0314/flumeameba • Onix (Data Stream Processing and Analysis with Akka @ Scala Conference 2013) http://www.slideshare.net/romanshtykh/data-stream-processing-and-analysis-with-akka
45.
45 最後に • Ameba Technology
Lab ではエンジニアを 募集しています! http://www.cyberagent.co.jp/recruit/career/ • Hadoop / データマイニング / 機械学習/ 検索 などに 興味がある人はお声がけください。
46.
ご清聴ありがとうございました。
Download







![株式会社サイバーエージェント
ジョブ設定DSL
• 柔軟なジョブのグループ化により細粒度の依存関係を簡潔に記述
• プラグインとしてコマンドを追加可能
ジョブをグループ化し
job_group{
依存関係を設定
require ['base_tbl_#{$dt}']
Hiveクエリを
hivequery{
実行するコマンド
require ['tmp_tbl_#{date_sub($dt,1)}']
produce ['tmp_tbl_#{$dt}']
日を跨ぐ
hiveql 'INSERT OVERWRITE ...'
依存関係
}
hive2hbase{
Hiveの結果を
require ['tmp_tbl_#{$dt}']
HBaseにPutする
hiveql 'SELECT count(distinct id) FROM ..'
コマンド
}
}
14](https://image.slidesharecdn.com/20131107-cwt-zenmyoiijima-131110020212-phpapp02/75/Ameba-Patriot-14-2048.jpg)







![35
コンポーネントのカスタマイズ
• カスタマイズしたコンポーネントをFlumeに簡単に組み込める。
• Jarファイルにして /usr/lib/flume/lib などに配布して
下記のように指定する。
• このようにしてFlume自体に実装されてない機能、独自システムとの
連携などに対応できる。
# example
agent.xxx.custom.type = [カスタマイズしたClass名やMethod名など]
agent.xxx.custom.channel = ch1
agent.xxx.custom.port = 12345
※ xxx : sources, channels, sinks などのコンポーネント](https://image.slidesharecdn.com/20131107-cwt-zenmyoiijima-131110020212-phpapp02/75/Ameba-Patriot-35-2048.jpg)




































































![[Sumo Logic x AWS 共催セミナー_20190829] Sumo Logic on AWS -AWS を活用したログ分析とセキュリティモニ...](https://cdn.slidesharecdn.com/ss_thumbnails/sumologiconaws-loganalysisandsecuritymonitoringusingaws-20190829-190829114856-thumbnail.jpg?width=640&height=640&fit=bounds)

































