Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Katsunori Kanda
PDF, PPTX
9,934 views
データファースト開発
開発チームのためのデータ分析環境の構築と継続的改善の仕組み 2015.10.14 @ Developers Summit 2015 Autumn
Technology
◦
Read more
31
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PDF
Yahoo! JAPANが持つデータ分析ソリューションの紹介 #yjdsnight
by
Yahoo!デベロッパーネットワーク
PDF
Amebaにおけるレコメンデーションシステムの紹介
by
cyberagent
PDF
[db tech showcase Tokyo 2016] B15: サイバーエージェント アドテクスタジオの次世代データ分析基盤紹介 by 株式会社サイ...
by
Insight Technology, Inc.
PPTX
データドリブン企業におけるHadoop基盤とETL -niconicoでの実践例-
by
Makoto SHIMURA
PDF
All about 開発本部infra部 TASKs
by
gree_tech
PPTX
niconicoにおける継続的なデータ活用のためのHadoop運用事例
by
Makoto SHIMURA
PDF
データにまつわるWeb業界の仕事について
by
Masanori Takano
PDF
データサイエンスを支える基盤とそのテクノロジー@WebDBフォーラム2015 #webdbf2015
by
Yahoo!デベロッパーネットワーク
Yahoo! JAPANが持つデータ分析ソリューションの紹介 #yjdsnight
by
Yahoo!デベロッパーネットワーク
Amebaにおけるレコメンデーションシステムの紹介
by
cyberagent
[db tech showcase Tokyo 2016] B15: サイバーエージェント アドテクスタジオの次世代データ分析基盤紹介 by 株式会社サイ...
by
Insight Technology, Inc.
データドリブン企業におけるHadoop基盤とETL -niconicoでの実践例-
by
Makoto SHIMURA
All about 開発本部infra部 TASKs
by
gree_tech
niconicoにおける継続的なデータ活用のためのHadoop運用事例
by
Makoto SHIMURA
データにまつわるWeb業界の仕事について
by
Masanori Takano
データサイエンスを支える基盤とそのテクノロジー@WebDBフォーラム2015 #webdbf2015
by
Yahoo!デベロッパーネットワーク
What's hot
PPTX
クラウドの積極的利活用による生産性向上と経営に寄与する仕組みづくり
by
gree_tech
PPTX
上司が信用できない会社の内部統制~第32回WebSig会議「便利さと、怖さと、心強さと〜戦う会社のための社内セキュリティ 2013年のスタンダードとは?!...
by
WebSig24/7
PDF
【19-D-2】今更聞けない!?インフラ選定のケーススタディ「ベアメタルクラウド」を活用した最適な環境構築をするためのポイントはなんだ!?
by
Developers Summit
PDF
[Observability conference 2022/3/11] NewsPicks のプロダクト開発エンジニアが実践するスキルとしての SRE
by
Iida Yukako
PDF
Yahoo!ブラウザーアプリのプロダクトマネージャーが考えていること
by
Yahoo!デベロッパーネットワーク
PDF
Yahoo! JAPANを支えるビッグデータプラットフォーム技術
by
Yahoo!デベロッパーネットワーク
PPTX
グリーにおけるAWS移行の必然性
by
gree_tech
PPTX
SEGA : Growth hacking by Spark ML for Mobile games
by
DataWorks Summit/Hadoop Summit
PDF
グリーのセキュリティ戦略:組織改革成功の秘訣と新たな課題への取り組み
by
gree_tech
PDF
スタートアップで培ったアーキテクチャ設計ノウハウ
by
Masakazu Matsushita
PDF
【19-B-1】情シスの中のアーキテクト ~ソフトウェアアーキテクチャを超えて~
by
Developers Summit
PPTX
リリースを支える負荷測定
by
gree_tech
PPTX
第一回☆GREE AI Programming ContestでTensorFlow
by
gree_tech
PDF
行ってみよう、やってみよう!
by
gree_tech
PDF
【A-1】すべてがつながるIoT時代の共創のあり方
by
Developers Summit
PDF
[社内合同勉強会]インフラ業務を開発エンジニアへ移譲して 移譲前-移譲後-そして今-
by
Takahiro Moteki
PDF
Google big query × Amazon redshift
by
Fumihide Nario
PPTX
F.O.Xを支える技術
by
Yuto Suzuki
PDF
Sparkを活用したレコメンドエンジンのパフォーマンスチューニング&自動化
by
Nagato Kasaki
PDF
MapR Hadoop M7 in CyberAgent AdTech Studio
by
Ken Takao
クラウドの積極的利活用による生産性向上と経営に寄与する仕組みづくり
by
gree_tech
上司が信用できない会社の内部統制~第32回WebSig会議「便利さと、怖さと、心強さと〜戦う会社のための社内セキュリティ 2013年のスタンダードとは?!...
by
WebSig24/7
【19-D-2】今更聞けない!?インフラ選定のケーススタディ「ベアメタルクラウド」を活用した最適な環境構築をするためのポイントはなんだ!?
by
Developers Summit
[Observability conference 2022/3/11] NewsPicks のプロダクト開発エンジニアが実践するスキルとしての SRE
by
Iida Yukako
Yahoo!ブラウザーアプリのプロダクトマネージャーが考えていること
by
Yahoo!デベロッパーネットワーク
Yahoo! JAPANを支えるビッグデータプラットフォーム技術
by
Yahoo!デベロッパーネットワーク
グリーにおけるAWS移行の必然性
by
gree_tech
SEGA : Growth hacking by Spark ML for Mobile games
by
DataWorks Summit/Hadoop Summit
グリーのセキュリティ戦略:組織改革成功の秘訣と新たな課題への取り組み
by
gree_tech
スタートアップで培ったアーキテクチャ設計ノウハウ
by
Masakazu Matsushita
【19-B-1】情シスの中のアーキテクト ~ソフトウェアアーキテクチャを超えて~
by
Developers Summit
リリースを支える負荷測定
by
gree_tech
第一回☆GREE AI Programming ContestでTensorFlow
by
gree_tech
行ってみよう、やってみよう!
by
gree_tech
【A-1】すべてがつながるIoT時代の共創のあり方
by
Developers Summit
[社内合同勉強会]インフラ業務を開発エンジニアへ移譲して 移譲前-移譲後-そして今-
by
Takahiro Moteki
Google big query × Amazon redshift
by
Fumihide Nario
F.O.Xを支える技術
by
Yuto Suzuki
Sparkを活用したレコメンドエンジンのパフォーマンスチューニング&自動化
by
Nagato Kasaki
MapR Hadoop M7 in CyberAgent AdTech Studio
by
Ken Takao
Viewers also liked
PDF
ソーシャル系Webサービスのデータを用いた社会科学 資料
by
Masanori Takano
PDF
サラリーマンのための計算社会科学
by
Masanori Takano
PDF
広告におけるビッグデータの分析事例
by
Ken Takao
PDF
How Do Newcomers Blend into a Group?: Study on a Social Network Game
by
Masanori Takano
PDF
How to work Tableau x Google Cloud Platform in CyberAgent AdTech Studio
by
Ken Takao
PDF
社会関係の強さに基づく社会的グルーミング戦略の適応性
by
Masanori Takano
ソーシャル系Webサービスのデータを用いた社会科学 資料
by
Masanori Takano
サラリーマンのための計算社会科学
by
Masanori Takano
広告におけるビッグデータの分析事例
by
Ken Takao
How Do Newcomers Blend into a Group?: Study on a Social Network Game
by
Masanori Takano
How to work Tableau x Google Cloud Platform in CyberAgent AdTech Studio
by
Ken Takao
社会関係の強さに基づく社会的グルーミング戦略の適応性
by
Masanori Takano
Similar to データファースト開発
PDF
perfを使ったPostgreSQLの解析(前編)
by
Daichi Egawa
PDF
(道具としての)データサイエンティストのつかい方
by
Shohei Hido
PDF
tut_pfi_2012
by
Preferred Networks
PDF
AIOpsで実現する効率化 OSC 2022 Online Spring TIS
by
Daisuke Ikeda
PPTX
事業の進展とデータマネジメント体制の進歩(+プレトタイプの話)
by
Tokoroten Nakayama
PPTX
ビジネスに役立つデータ分析
by
Issei Kurahashi
PDF
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
PDF
New Relic University at Future Stack Tokyo 2019
by
New Relic
PPTX
データサイエンティスト向け性能問題対応の基礎
by
Tetsutaro Watanabe
PDF
「Oracle Database + Java + Linux」 環境における性能問題の調査手法 ~ミッションクリティカルシステムの現場から~ Part.1
by
Shogo Wakayama
PDF
利益を生み出すAnalytics Teamのあり方
by
Recruit Lifestyle Co., Ltd.
PDF
【講演資料】ビッグデータ時代の経営を支えるビジネスアナリティクスソリューション
by
Dell TechCenter Japan
PDF
サービス改善はログデータ分析から
by
Kenta Suzuki
PDF
データマイニングCROSS 第2部-機械学習・大規模分散処理
by
Koichi Hamada
PDF
Open Cloud Innovation2016 day1(これからのデータ分析者とエンジニアに必要なdatascienceexperienceツールと...
by
Atsushi Tsuchiya
PDF
利用者主体で行う分析のための分析基盤
by
Sotaro Kimura
PDF
Amazon Elastic MapReduceやSparkを中心とした社内の分析環境事例とTips
by
yuichi_komatsu
PDF
S01 t3 data_engineer
by
Takeshi Akutsu
PDF
Azure データサービスデザイン検討 (2015/10)
by
Koichiro Sasaki
PDF
現場の”今”を知る、これからのビッグデータ分析・活用のすすめ
by
yuji suzuki
perfを使ったPostgreSQLの解析(前編)
by
Daichi Egawa
(道具としての)データサイエンティストのつかい方
by
Shohei Hido
tut_pfi_2012
by
Preferred Networks
AIOpsで実現する効率化 OSC 2022 Online Spring TIS
by
Daisuke Ikeda
事業の進展とデータマネジメント体制の進歩(+プレトタイプの話)
by
Tokoroten Nakayama
ビジネスに役立つデータ分析
by
Issei Kurahashi
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
New Relic University at Future Stack Tokyo 2019
by
New Relic
データサイエンティスト向け性能問題対応の基礎
by
Tetsutaro Watanabe
「Oracle Database + Java + Linux」 環境における性能問題の調査手法 ~ミッションクリティカルシステムの現場から~ Part.1
by
Shogo Wakayama
利益を生み出すAnalytics Teamのあり方
by
Recruit Lifestyle Co., Ltd.
【講演資料】ビッグデータ時代の経営を支えるビジネスアナリティクスソリューション
by
Dell TechCenter Japan
サービス改善はログデータ分析から
by
Kenta Suzuki
データマイニングCROSS 第2部-機械学習・大規模分散処理
by
Koichi Hamada
Open Cloud Innovation2016 day1(これからのデータ分析者とエンジニアに必要なdatascienceexperienceツールと...
by
Atsushi Tsuchiya
利用者主体で行う分析のための分析基盤
by
Sotaro Kimura
Amazon Elastic MapReduceやSparkを中心とした社内の分析環境事例とTips
by
yuichi_komatsu
S01 t3 data_engineer
by
Takeshi Akutsu
Azure データサービスデザイン検討 (2015/10)
by
Koichiro Sasaki
現場の”今”を知る、これからのビッグデータ分析・活用のすすめ
by
yuji suzuki
More from Katsunori Kanda
PPTX
BazelでビルドしたアプリをGCPにデプロイしようとしてハマった話
by
Katsunori Kanda
PDF
Airflowを広告データのワークフローエンジンとして運用してみた話
by
Katsunori Kanda
PDF
RealSenseを使ってCrazyflieを自律飛行させてみた
by
Katsunori Kanda
PDF
Airflow 2.0 migration ガイド
by
Katsunori Kanda
PDF
Docker超入門
by
Katsunori Kanda
PDF
Spark Summit 2015 参加報告
by
Katsunori Kanda
PPTX
Hadoopことはじめ
by
Katsunori Kanda
PDF
Dockerだけではないコンテナのはなし
by
Katsunori Kanda
PDF
20150207 何故scalaを選んだのか
by
Katsunori Kanda
KEY
自動テストのすすめ
by
Katsunori Kanda
PDF
Discretized Streams: Fault-Tolerant Streaming Computation at Scaleの解説
by
Katsunori Kanda
PDF
KINECT WITH ROS
by
Katsunori Kanda
PDF
Web Privacy Survival Guide
by
Katsunori Kanda
PDF
GCSでstatic web hosting
by
Katsunori Kanda
BazelでビルドしたアプリをGCPにデプロイしようとしてハマった話
by
Katsunori Kanda
Airflowを広告データのワークフローエンジンとして運用してみた話
by
Katsunori Kanda
RealSenseを使ってCrazyflieを自律飛行させてみた
by
Katsunori Kanda
Airflow 2.0 migration ガイド
by
Katsunori Kanda
Docker超入門
by
Katsunori Kanda
Spark Summit 2015 参加報告
by
Katsunori Kanda
Hadoopことはじめ
by
Katsunori Kanda
Dockerだけではないコンテナのはなし
by
Katsunori Kanda
20150207 何故scalaを選んだのか
by
Katsunori Kanda
自動テストのすすめ
by
Katsunori Kanda
Discretized Streams: Fault-Tolerant Streaming Computation at Scaleの解説
by
Katsunori Kanda
KINECT WITH ROS
by
Katsunori Kanda
Web Privacy Survival Guide
by
Katsunori Kanda
GCSでstatic web hosting
by
Katsunori Kanda
データファースト開発
1.
データファースト開発 2015.10.14 @ Developers
Summit 2015 Autumn 開発チームのためのデータ分析環境の構築と 継続的改善の仕組み Presented By: Katsunori Kanda(@potix2) CyberAgent Inc.
2.
自己紹介 神田勝規(かんだかつのり) 株式会社サイバーエージェント アドテク本部 AMoAd所属 サーバーサイドエンジニア(OS/分散システムが専門) ! potix2@twitter/github ※1 毎月LispMeetup(shibuya.lisp)を開催してます ※2
SparkのMeetupや勉強会を開催してます
3.
システム改善のサイクル 現状把握 改善案の策定設計・実装 今日の話はこの辺り
4.
現状把握に何分かかるか? • 日別・週別のアクティブユーザー数 • ユーザーの平均広告接触回数/日 •
など・・・ 定型的な分析であれば即時 アドホックな分析だと1週間以上かかることも・・・
5.
時間がかかることによる弊害(1/2) 本当に困るまで調査しなくなる 「根拠のない思い込みによる誤った判断」 「古い調査結果に基づく誤った判断」
6.
時間がかかることによる弊害(2/2) データを見るには特異なスキルが必要だと誤認 (実際は、ステップ数が多いだけで誰でもできる) データ抽出&分析の属人化
7.
どの行程に時間がかかるのか? 2.ETL1.仮説立案 (対象データ選定) 3.データ抽出 4.分析 ※前提:すべてのデータを分析環境に置けない 分析対象のデータサイズに依存
8.
理想的には、 誰でも、気軽に データ抽出&分析ができるべき
9.
理想に向けて必要なこと 1.データへアクセスが容易 2.高い応答性(理想的には5分以内) 3.手順の再現性 最重要
10.
やったこと • データ分析の専用ログを出力するようにした • データ分析基盤の構築 •
計算エンジン: BigQuery + Spark(オンプレ) • ストレージ: Google Cloud Storage • UI: Apache Zeppelin + Jupyter
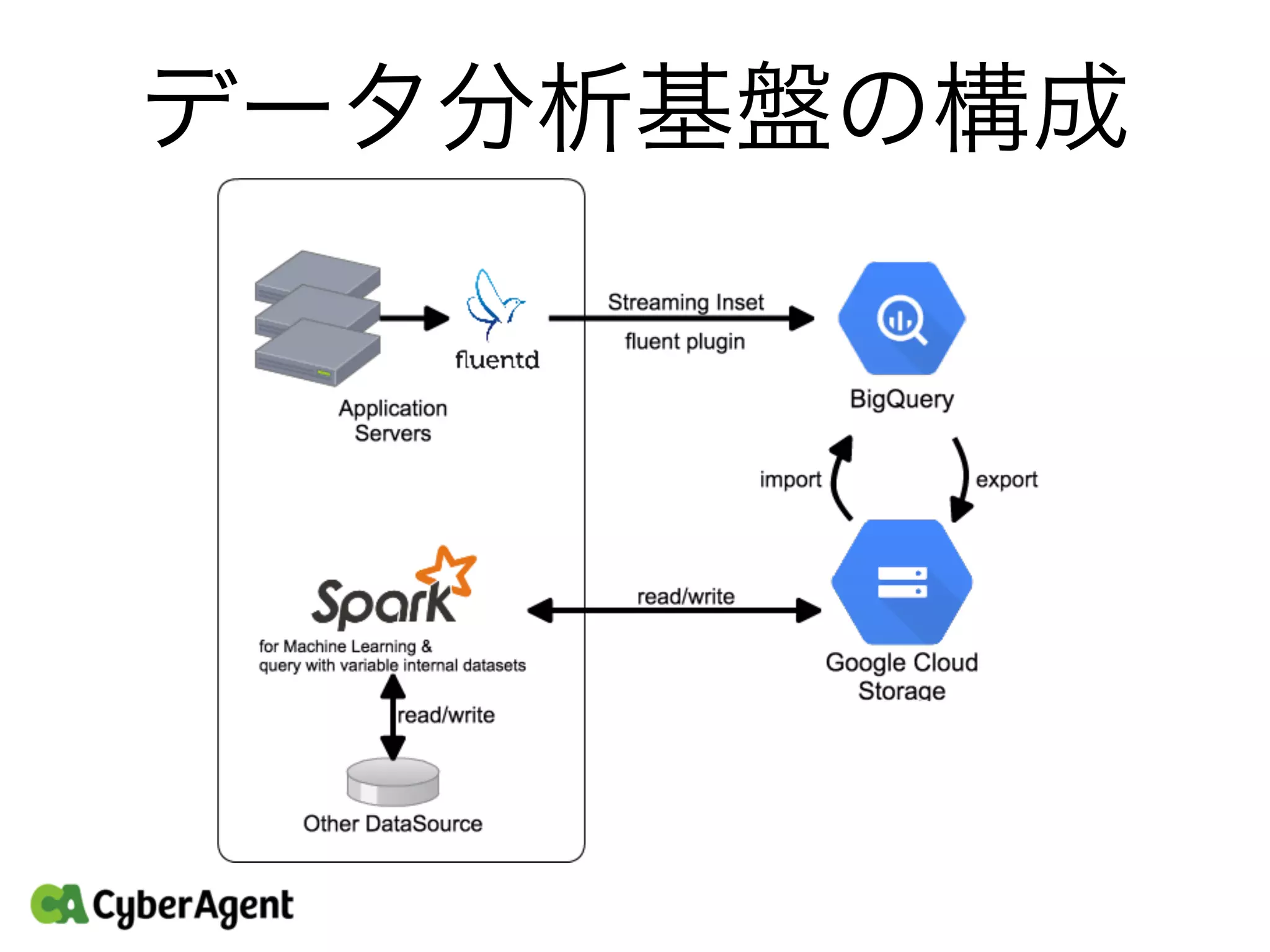
11.
データ分析基盤の構成
12.
どうしてこの構成になったのか? • 応答性を重視 • BigQueryではIndex的なものの定義が不要 •
アドホック分析にはBigQueryを使うのがベスト • 用途/データソースによって環境を使い分ける • 機械学習を使いたいときはSparkやscikit-learn • 分析ログに含まれないデータを調べたいときは Spark
13.
応答性を重視する理由 • フィーリングは重要 • 直感は、案外正しい •
根拠がない直感はダメ • 結果を得るのに時間がかかると • 調査コストと得られるメリットを天 にかけてし まい、遊びのある調査ができない • 思いついてから10分以内には結果を見たい
14.
データ分析環境ができ てみて・・・
15.
使われない・・・
16.
何故、使われないのか? 1.使い方がわからない 2.何に使えるのかが分からない
17.
「使い方」を共有するために • チュートリアルを開催 • BigQueryハンズオン •
ドキュメント化 • QiitaチームにTipsを共有 • ノートブックを活用 • 他の人が分析した手順がノートブックとして残っ ているので、参考にしやすい
18.
Apache Zeppleinのデモ
19.
「何に使えるのか」を共有するために • 基礎集計の結果と手順を共有 • チーム内のチャットグループで共有 •
有用なものは、定型ジョブとして自動化 • Tableauなどを使って可視化した結果を共有
20.
結局、エンジニアは データ分析基盤を何に使うのか? • 開発項目の選定 • 現状をより正確に把握 •
開発すべき根拠を導出 • システム改善の事前・事後の評価 • 改善施策の効果を客観的に評価 • 運用フローの改善 絶賛試行錯誤中
21.
これからの課題 • データの評価/分析のレベルをあげる • 得られた結果から何が言えるのか?読み取る力を あげる。(統計学の基礎知識など) •
可視化 • 可視化されることで新たな知見が得られる • ワークフローの自動化 • 手順が複雑になるとデータ分析が属人化する • ノートブックを定期実行ジョブ化したい
22.
まとめ • 速いことは正義 • BigQueryを使って人生が変わりました •
気軽にデータ抽出できることで新たな気付き • 誰でもデータアクセスできるといいことがある • 開発者がリリースした機能を自分で評価できる • 改善サイクルを回すスピードがあがる(はず) • データを見れないことをリスクと捉えるべき
Download























![[db tech showcase Tokyo 2016] B15: サイバーエージェント アドテクスタジオの次世代データ分析基盤紹介 by 株式会社サイ...](https://cdn.slidesharecdn.com/ss_thumbnails/6i9kohhirrcoablwy2vg-signature-de1723da869232faf642797bf4411177191c3ef937923c1c3c4b18848e6dd30c-poli-160721053413-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Observability conference 2022/3/11] NewsPicks のプロダクト開発エンジニアが実践するスキルとしての SRE](https://cdn.slidesharecdn.com/ss_thumbnails/observabilityconference2022311newspickssre-220310143345-thumbnail.jpg?width=640&height=640&fit=bounds)











![[社内合同勉強会]インフラ業務を開発エンジニアへ移譲して 移譲前-移譲後-そして今-](https://cdn.slidesharecdn.com/ss_thumbnails/random-170224055516-thumbnail.jpg?width=640&height=640&fit=bounds)











































