



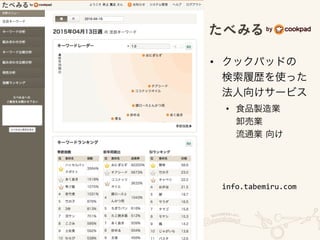

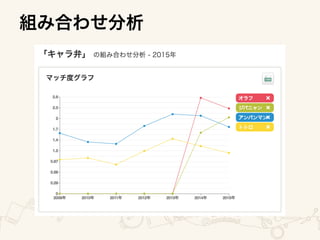
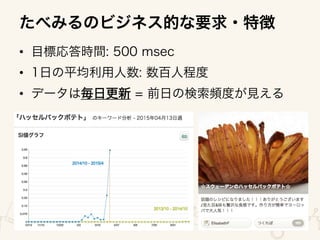
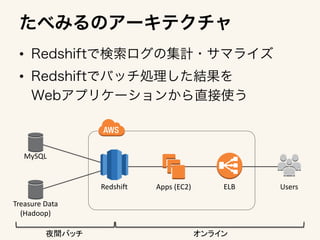


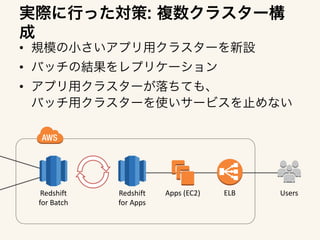
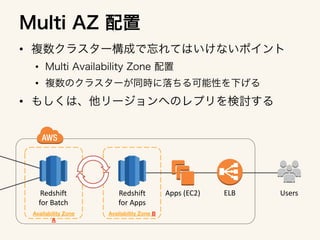
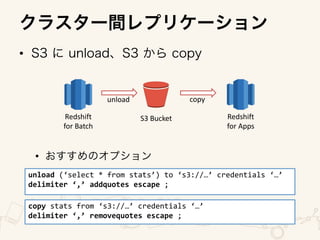


The document outlines an architecture for utilizing AWS services including EC2, ELB, and Redshift for both online and batch processing applications. It describes data unloading from Redshift to an S3 bucket and subsequent data loading from S3 into Redshift, detailing the necessary credentials and formatting. The setup spans multiple availability zones for enhanced reliability.





















































