Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
cyberagent
2,845 views
Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
WWW2019 論文読み会 Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
Engineering
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PPTX
Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vi...
by
Yoshitaka Ushiku
PDF
予測型戦略を知るための機械学習チュートリアル
by
Yuya Unno
PDF
Facebookの人工知能アルゴリズム「memory networks」について調べてみた
by
株式会社メタップスホールディングス
PDF
NIPS2013読み会: Distributed Representations of Words and Phrases and their Compo...
by
Yuya Unno
PDF
Deep learning を用いた画像から説明文の自動生成に関する研究の紹介
by
株式会社メタップスホールディングス
PPTX
機械学習を民主化する取り組み
by
Yoshitaka Ushiku
PDF
子どもの言語獲得のモデル化とNN Language ModelsNN
by
Chiba Institute of Technology
PPTX
Emnlp読み会資料
by
Jiro Nishitoba
Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vi...
by
Yoshitaka Ushiku
予測型戦略を知るための機械学習チュートリアル
by
Yuya Unno
Facebookの人工知能アルゴリズム「memory networks」について調べてみた
by
株式会社メタップスホールディングス
NIPS2013読み会: Distributed Representations of Words and Phrases and their Compo...
by
Yuya Unno
Deep learning を用いた画像から説明文の自動生成に関する研究の紹介
by
株式会社メタップスホールディングス
機械学習を民主化する取り組み
by
Yoshitaka Ushiku
子どもの言語獲得のモデル化とNN Language ModelsNN
by
Chiba Institute of Technology
Emnlp読み会資料
by
Jiro Nishitoba
What's hot
PDF
言語資源と付き合う
by
Yuya Unno
PPTX
Learning Cooperative Visual Dialog with Deep Reinforcement Learning(関東CV勉強会 I...
by
Yoshitaka Ushiku
PDF
単語・句の分散表現の学習
by
Naoaki Okazaki
PDF
深層学習時代の自然言語処理
by
Yuya Unno
PDF
形態素解析の過去・現在・未来
by
Preferred Networks
PPTX
Jacet2014ykondo_final
by
早稲田大学
PDF
言語と知識の深層学習@認知科学会サマースクール
by
Yuya Unno
言語資源と付き合う
by
Yuya Unno
Learning Cooperative Visual Dialog with Deep Reinforcement Learning(関東CV勉強会 I...
by
Yoshitaka Ushiku
単語・句の分散表現の学習
by
Naoaki Okazaki
深層学習時代の自然言語処理
by
Yuya Unno
形態素解析の過去・現在・未来
by
Preferred Networks
Jacet2014ykondo_final
by
早稲田大学
言語と知識の深層学習@認知科学会サマースクール
by
Yuya Unno
Similar to Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
PDF
The Web Conference 2020 国際会議報告(ACM SIGMOD 日本支部第73回支部大会・依頼講演)
by
Kosetsu Tsukuda
PDF
スペル修正プログラムの作り方 #pronama
by
Hiroyoshi Komatsu
PDF
20201010 kaggle tweet コンペの話
by
taguchi naoya
PPT
スペルミス修正プログラムを作ろう
by
Naoya Ito
PDF
WWW2017論文読み会 Spam Detection と Question Answering & Topic Modeling
by
cyberagent
PDF
kaggle tweet コンペの話
by
taguchi naoya
PDF
bigdata2012nlp okanohara
by
Preferred Networks
PDF
サブカルのためのWord2vec
by
DeNA
PPTX
Coling読み会 2014
by
ai_06_14
PDF
編集操作の測定でアプローチする自然言語処理の提案
by
yamahige
PPTX
All-but-the-Top: Simple and Effective Postprocessing for Word Representations
by
Makoto Takenaka
PDF
Twitterユーザに対するゼロショットタグ付け
by
Kohei Shinden
PPTX
dont_count_predict_in_acl2014
by
Sho Takase
PDF
論文紹介:"RAt: Injecting Implicit Bias for Text-To-Image Prompt Refinement Models...
by
Toru Tamaki
PDF
GhostTweet
by
ayatsuka
PDF
言語処理学会へ遊びに行ったよ
by
antibayesian 俺がS式だ
PPTX
Interop2017
by
tak9029
PPTX
Mtg121024
by
Kosuke Kagawa
PDF
ACL2020 best papers
by
Kazuki Fujikawa
PDF
Survey of Scientific Publication Analysis by NLP and CV
by
Shintaro Yamamoto
The Web Conference 2020 国際会議報告(ACM SIGMOD 日本支部第73回支部大会・依頼講演)
by
Kosetsu Tsukuda
スペル修正プログラムの作り方 #pronama
by
Hiroyoshi Komatsu
20201010 kaggle tweet コンペの話
by
taguchi naoya
スペルミス修正プログラムを作ろう
by
Naoya Ito
WWW2017論文読み会 Spam Detection と Question Answering & Topic Modeling
by
cyberagent
kaggle tweet コンペの話
by
taguchi naoya
bigdata2012nlp okanohara
by
Preferred Networks
サブカルのためのWord2vec
by
DeNA
Coling読み会 2014
by
ai_06_14
編集操作の測定でアプローチする自然言語処理の提案
by
yamahige
All-but-the-Top: Simple and Effective Postprocessing for Word Representations
by
Makoto Takenaka
Twitterユーザに対するゼロショットタグ付け
by
Kohei Shinden
dont_count_predict_in_acl2014
by
Sho Takase
論文紹介:"RAt: Injecting Implicit Bias for Text-To-Image Prompt Refinement Models...
by
Toru Tamaki
GhostTweet
by
ayatsuka
言語処理学会へ遊びに行ったよ
by
antibayesian 俺がS式だ
Interop2017
by
tak9029
Mtg121024
by
Kosuke Kagawa
ACL2020 best papers
by
Kazuki Fujikawa
Survey of Scientific Publication Analysis by NLP and CV
by
Shintaro Yamamoto
More from cyberagent
PDF
WWW2019で見るモバイルコンピューティングの技術と動向 山本悠ニ
by
cyberagent
PDF
WebにおけるHuman Dynamics 武内慎
by
cyberagent
PDF
Webと経済学 數見拓朗
by
cyberagent
PDF
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
PDF
継続的な開発スタイル AbemaTVのiOSアプリを週1でリリースしている話
by
cyberagent
PDF
AbemaTVにおける推薦システム
by
cyberagent
PDF
AbemaTV レコメンド開発エンジニアによる RecSys 2018 参加レポート
by
cyberagent
PDF
機械学習エンジニアを見せたAWSの再:発明とは? 〜re:Invent 2018 参加レポート〜
by
cyberagent
PPTX
インターネットテレビ局「AbemaTV」プロダクトの変遷
by
cyberagent
PDF
番組宣伝に関するAbemaTV分析事例の紹介
by
cyberagent
PDF
WWW2018 論文読み会 Webと経済学
by
cyberagent
PDF
WWW2018 論文読み会 WebにおけるHuman Dynamics
by
cyberagent
PDF
WWW2018 論文読み会 Web Search and Mining
by
cyberagent
PDF
サイバーエージェントの機械学習エンジニアが体験したGoogle I/O 2018
by
cyberagent
PDF
ログ解析基盤におけるストリーム処理パイプラインについて
by
cyberagent
PDF
Orion an integrated multimedia content moderation system for web services
by
cyberagent
PDF
Orion an integrated multimedia content moderation system for web services
by
cyberagent
PDF
「これ危ない設定じゃないでしょうか」とヒアリングするための仕組み @AWS Summit Tokyo 2018
by
cyberagent
PPTX
"マルチメディア機械学習" の取り組み
by
cyberagent
PDF
推薦アルゴリズムの今までとこれから
by
cyberagent
WWW2019で見るモバイルコンピューティングの技術と動向 山本悠ニ
by
cyberagent
WebにおけるHuman Dynamics 武内慎
by
cyberagent
Webと経済学 數見拓朗
by
cyberagent
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
継続的な開発スタイル AbemaTVのiOSアプリを週1でリリースしている話
by
cyberagent
AbemaTVにおける推薦システム
by
cyberagent
AbemaTV レコメンド開発エンジニアによる RecSys 2018 参加レポート
by
cyberagent
機械学習エンジニアを見せたAWSの再:発明とは? 〜re:Invent 2018 参加レポート〜
by
cyberagent
インターネットテレビ局「AbemaTV」プロダクトの変遷
by
cyberagent
番組宣伝に関するAbemaTV分析事例の紹介
by
cyberagent
WWW2018 論文読み会 Webと経済学
by
cyberagent
WWW2018 論文読み会 WebにおけるHuman Dynamics
by
cyberagent
WWW2018 論文読み会 Web Search and Mining
by
cyberagent
サイバーエージェントの機械学習エンジニアが体験したGoogle I/O 2018
by
cyberagent
ログ解析基盤におけるストリーム処理パイプラインについて
by
cyberagent
Orion an integrated multimedia content moderation system for web services
by
cyberagent
Orion an integrated multimedia content moderation system for web services
by
cyberagent
「これ危ない設定じゃないでしょうか」とヒアリングするための仕組み @AWS Summit Tokyo 2018
by
cyberagent
"マルチメディア機械学習" の取り組み
by
cyberagent
推薦アルゴリズムの今までとこれから
by
cyberagent
Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
1.
Web フィルタリング最前線: 「「 検閲回避
」 回避」 株式会社サイバーエージェント 秋葉原ラボ ⾓⽥ 孝昭 WWW-2019 論⽂読み会
2.
はじめに ⾃⼰紹介 l ⾓⽥ 孝昭(つのだ
たかあき) • 技術本部 秋葉原ラボ • ⾃然⾔語処理研究 → 博⼠(⼯学)→ 現職 l おしごと • アメブロ、タップル誕⽣を中⼼とした スパム‧不正利⽤対策、サービス健全化 • 機械学習‧⾃然⾔語処理系のタスク諸々 • 秋葉原ラボ主催の勉強会で写真を撮りに⾏く係 📸 l しゅみ: 写真, ⾳ゲー, スマブラSP 2
3.
はじめに 本発表で取り上げる論⽂ 1. Hongyu Gong,
Yuchen Li, Suma Bhat, Pramod Viswanath, 2019. Context-Sensitive Malicious Spelling Error Correction. WWW-2019. • コンテンツフィルターを回避するために「敢えて」スペルミスをしている投稿を発⾒ (例: stupid → stup*d, stupi.d と書き換えるなど) 2. Longtao Huang, Ting Ma, Junyu Lin, Jizhong Han, Songlin Hu, 2019. A Multimodal Text Matching Model for Obfuscated Language Identification in Adversarial Communication. WWW-2019. • コンテンツフィルターを回避するために隠語化している投稿を発⾒ (例: 爆弾 → ⽕暴⼸単 と書き換えるなど) 3 WWW-2019 から最先端のフィルタリング論⽂を2本紹介 ★ 本資料の⽂献番号 (例: [1]) は各論⽂で利⽤している番号になります
4.
はじめに コンテンツフィルターとは? l 有害コンテンツの投稿を発⾒‧阻⽌するための分類器 • スパム‧フィッシング等のコンテンツ •
違法(薬物取引など‧犯罪予告)‧誹謗中傷等のコンテンツ l キーワードフィルター‧機械学習フィルター等による コンテンツの監視が必要 • データ量が揃わないタイプにはキーワードフィルターが重要 4 ★ もちろんコンテンツではなく、ユーザの⾏動(連投など)に基づくフィルターも存在する。ただし、 本発表ではフィルターと⾔ったらコンテンツフィルターを指すことにする
5.
はじめに コンテンツフィルター「回避」とは? l フィルターに掛かりそうな単語に⼿を加えてフィルターを回避 5 Spelling Errors (スペル誤り) Obfuscation (難読化) 爆弾
⽕暴⼸単 茸, 禿, 庭, 芋(携帯キャリア) シンナー アンパンstupid stupi.d stupd stuqid stup*d ★ Perspective(有害度等を判定できる⾔語処理 API)による toxic score [0.0, 1.0] は、“stupid” を含むとある⽂を ⼊⼒すると 86% であったのに対し、”stup*d” に置換すると 8% に低下する [論⽂①] これらの細⼯はフィルターに多⼤な影響を及ぼす!★
6.
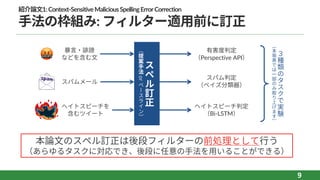
はじめに コンテンツフィルター 「「回避」回避」 とは? l
フィルター回避を狙う⼩細⼯に対応する • スペル誤り単語を発⾒‧訂正してから判定 [論⽂①] • 周辺の単語や視覚的類似性などの情報を利⽤して判定 [論⽂②] l • スペル誤り‧難読化などの復元性能ではなく、有害コンテンツの 検知性能で有効性を検証している ⁃ [論⽂①] メールスパム検出、⼈種差別‧性差別ツイート検出 ⁃ [論⽂②] 有害ツイート検出(Weibo) • ただし、2つの論⽂では⼿法の枠組みが⼤きく異なる 論⽂①では前処理として訂正、論⽂②では訂正(復元)をしない等 6 両論⽂のポイント
7.
紹介論⽂1: Context-Sensitive Malicious Spelling
Error Correction 7 Hongyu Gong, Yuchen Li, Suma Bhat, Pramod Viswanath, 2019.
8.
紹介論⽂1:Context-SensitiveMaliciousSpellingErrorCorrection ⽬的: スペル誤り訂正でフィルター回避に対応 l スペル誤りはフィルターに多⼤な影響を及ぼす •
「わざと」誤りを⼊れれば回避できてしまう可能性も l • 前処理としてスペル誤りを訂正、後段処理での影響を軽減 • スペル誤り語の周辺⽂脈を参照し、訂正候補語をランキング ⁃ 訂正候補と周辺単語群の分散表現ベクトルの近さに基づく 8 My thoughts are that people should stop being stupid. My thoughts are that people should stop being stup*d. 86% 8% Perspective API による toxic score (有害度) 😱 アイディア
9.
紹介論⽂1:Context-SensitiveMaliciousSpellingErrorCorrection ⼿法の枠組み: フィルター適⽤前に訂正 9 訂 正 ︵ 提 案 ⼿ 法 or ︶ 🤬 暴⾔‧誹謗 などを含む⽂ スパムメール ヘイトスピーチを 含むツイート 有害度判定 (Perspective API) スパム判定 (ベイズ分類器) ヘイトスピーチ判定 (Bi-LSTM) 3 種 類 実 験 ︵ 本 発 表 ⼀ 部 取 上 ︶ 本論⽂のスペル訂正は後段フィルターの前処理として⾏う (あらゆるタスクに対応でき、後段に任意の⼿法を⽤いることができる)
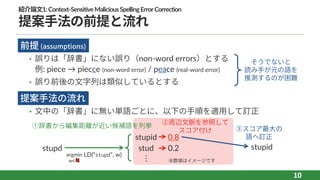
10.
紹介論⽂1:Context-SensitiveMaliciousSpellingErrorCorrection 提案⼿法の前提と流れ l • 誤りは「辞書」にない誤り(non-word errors)とする 例:
piece → piecce (non-word error) / peace (real-word error) • 誤り前後の⽂字列は類似しているとする l • ⽂中の「辞書」に無い単語ごとに、以下の⼿順を適⽤して訂正 10 前提 (assumptions) そうでないと 読み⼿が元の語を 推測するのが困難 提案⼿法の流れ stupd stupid stud ︙ ①辞書から編集距離が近い候補語を列挙 argmin 0.8 0.2 ②周辺⽂脈を参照して スコア付け stupid ③スコア最⼤の 語へ訂正 ※数値はイメージですw∈📕 LD(“stupd”, w)
11.
紹介論⽂1:Context-SensitiveMaliciousSpellingErrorCorrection 提案⼿法: 周辺⽂脈を参照した候補語スコア付け l 単語の分散表現
(embedding) の2つの特徴を利⽤ 1. phrase ベクトルは構成単語ベクトルの線形結合で近似できる [31] 例: 2. 単語がある⽂脈に合う場合、単語と⽂脈のベクトルは類似している [10] l 単語 c と⽂脈 Tp の距離 dist を次のように考える (式 (1); (2), (3) は解説略) 11 hate_group ⇡ hate + group dist(c,Tp) = min {ai } 1 || c ||2 || p ÿ i= p,i,0 ai i c ||2 2 (正規化項) Σ 内が最⼩になるような 都合の良い係数達 ⽂脈 (前後 p 単語) ⽂脈語の 単語ベクトル 候補語の 単語ベクトル 候補語 (stupid, stud, …) 周辺語の単語ベクトル (の定数倍) との ユークリッド距離の和を 最終的な距離と考える 非常にざっくり言えば 単語が文脈 Tp にどの程度 合ってるかを見ている
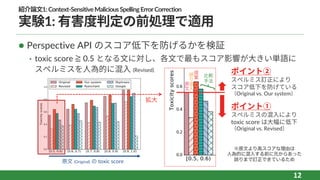
12.
紹介論⽂1:Context-SensitiveMaliciousSpellingErrorCorrection 実験1: 有害度判定の前処理で適⽤ l Perspective
API のスコア低下を防げるかを検証 • toxic score ≧ 0.5 となる⽂に対し、各⽂で最もスコア影響が⼤きい単語に スペルミスを⼈為的に混⼊ (Revised) 12 原⽂ (Original) の toxic score 拡⼤ ポイント① スペルミスの混⼊により toxic score は⼤幅に低下 (Original vs. Revised) ポイント② スペルミス訂正により スコア低下を防げている (Original vs. Our system) ⽐較 ⼿法 ※原文より高スコアな理由は 人為的に混入する前に元からあった 誤りまで訂正できているため 原 ⽂ 誤 混 ⼊ 提 案
13.
紹介論⽂1:Context-SensitiveMaliciousSpellingErrorCorrection 実験3: ヘイトスピーチ検出の前処理で適⽤ l 実
Twitter データに前処理を加えて検出率が上がるかを検証 • ヘイトスピーチデータ [34] を利⽤、⼈種差別 (racism)‧性差別 (sexism) を対象 • 後段の分類器には Bi-LSTM を利⽤ • ⼈為的に誤りは⼊れない; 実際の悪意あるスペルミスに対応できるか検証 13 ⽐較⼿法 ポイント① スペル訂正をした⽅が 検出性能は⾼くなる (Original vs. 他) ポイント② sexist では提案⼿法が今⼀つ → 「辞書」になかった略語を 無理⽮理訂正して性能低下 (例: kys = kill yourself)
14.
紹介論⽂1:Context-SensitiveMaliciousSpellingErrorCorrection まとめと雑感 l まとめ • 前処理としてのスペル訂正により後段フィルターの性能向上を達成 •
候補語と⽂脈との距離に基づいて訂正候補を提⽰ l 雑感 • 後段処理の⽅法を問わないため、応⽤先が広そう 様々なタスクへの応⽤可能性を、実験を通じて⽰している点が WWW 的に⾼評価? • 「辞書」をどのように作るかが肝になりそう 本論⽂でもある程度対応はしていたが、結局 kys, nsw (= non sexual way) 等の略語に対応できず • 分かち書きされていない⾔語への応⽤は難しい? ⽇本語のスペル訂正が英語等の⾔語とは⼤きく異なり、そして難しい理由 14
15.
紹介論⽂2: A Multimodal Text
Matching Model for Obfuscated Language Identification in Adversarial Communication 15 Longtao Huang, Ting Ma, Junyu Lin, Jizhong Han, Songlin Hu, 2019.
16.
紹介論⽂2:AMultimodalTextMatchingModelforObfuscatedLanguageIdentificationinAdversarialCommunication ⽬的: 様々な難読化によるフィルター回避に対応 l 難読化(隠語化)の⽅法は無限 •
⾦⽇成 → ⾦太阳 「⽇」を同じ意味の「太阳(太陽)」に置き換え • 薄熙来 → 平⻄王 中国の政治家と中国史の⼈物。いずれも同地域を収めるも、後に失脚したことからあだ名に • 炸弹 → ⽕乍⼸单 部⾸を分解。視覚的に近いがテキスト的には無関係 l 全ての候補を列挙することは不可能 l • ⽂全体を活⽤。⽂と NG ワードの対応付け問題として考える ⁃ 難読化された語の復元は⾏わない。⽂全体の単位で⾒る • テキストに加え視覚的要素を素性に利⽤ (multimodal) 16 アイディア
17.
紹介論⽂2:AMultimodalTextMatchingModelforObfuscatedLanguageIdentificationinAdversarialCommunication ⼿法の概要 17 テキスト素性 (textual features) Embedding Bi-LSTM Activation (Softmax) 画 像 素 性 (visualfeatures) テキスト‧画像素性の ベクトルを引いたり掛けたり したもの。式
(10), (11) 参照 (non-linear interaction を ⼊れると良くなるらしい [17])
18.
紹介論⽂2:AMultimodalTextMatchingModelforObfuscatedLanguageIdentificationinAdversarialCommunication 画像素性: テンプレートマッチングを利⽤ l • ある画像中において、指定された部分画像の 領域を⾒つけるタスク l
テキストを画像化してマッチさせる • ⼊⼒画像: OK/NG を判定したいテキスト • テンプレート画像: NG ワード 18 テンプレートマッチング (template matching) テンプレート 画像 ▶ 入 力 画 像 电影中十大令人难忘的果体场面… (この映画の忘れられないヌードシーンベスト10は…) 裸体① 判定領域を1pxずつずらして⾏く ② 判定領域とテンプレート画像の 類似度を計算 @ 式 (8) ③ 類似度の MaxPool を取って素性に ④ 全ての NG ワードで 同様のステップを繰り返す テンプレートマッチングの例
19.
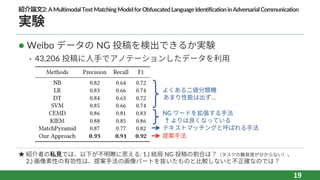
紹介論⽂2:AMultimodalTextMatchingModelforObfuscatedLanguageIdentificationinAdversarialCommunication 実験 l Weibo データの
NG 投稿を検出できるか実験 • 43,206 投稿に⼈⼿でアノテーションしたデータを利⽤ 19 よくある⼆値分類機 あまり性能は出ず… NG ワードを拡張する⼿法 ↑ よりは良くなっている テキストマッチングと呼ばれる⼿法 提案⼿法 ★ 紹介者の私⾒では、以下が不明瞭に思える: 1.) 結局 NG 投稿の割合は?(タスクの難易度が分からない)、 2.) 画像素性の有効性は、提案⼿法の画像パートを抜いたものと⽐較しないと不正確なのでは?
20.
紹介論⽂2:AMultimodalTextMatchingModelforObfuscatedLanguageIdentificationinAdversarialCommunication まとめと雑感 l まとめ • NG
ワードの復元を前提としない検出⼿法を提案 • テキスト素性‧画像素性の利⽤により性能向上を主張 l 雑感 • 分かち書き不要、存在する単語への変換でも対応できる → ⽇本語でも利⽤できそう • 本当に画像素性が有効だったかは追加検証が必要(私⾒) • 縦読み‧斜め読みなど、無数の可能性をどこまでカバーできるか? 20
21.
まとめ 21
22.
Webフィルタリング最前線:「「検閲回避」回避」 まとめと雑感 l まとめ • フィルターを回避する試みに対応した2つの論⽂を紹介 •
問題は類似しているが、⼿法は割と異なる l 雑感 〜健全化対応に携わる発表者からの若⼲の私⾒を添えて〜 • 今回は主要でなかった部分にも改善の余地はある ⁃ [論⽂①] 「辞書」の作り⽅、後段の分類器、… ⁃ [論⽂②] NG ワードリストの作成‧拡張、… • 絶対的な性能は悪くないが、タスク的には 100% に近付ける必要がある 抜け⽳がバレると⼀瞬で広がり、時既に遅し… / ⾃動フィルター化は ≒ 100% でないと難しい • フィルタリングはまだ取り組むべき問題の⼀つ 単純にディープラーニングに突っ込めば解消する問題ではない。データも集めにくい 22
Download




![はじめに
本発表で取り上げる論⽂
1. Hongyu Gong, Yuchen Li, Suma Bhat, Pramod Viswanath, 2019.
Context-Sensitive Malicious Spelling Error Correction. WWW-2019.
• コンテンツフィルターを回避するために「敢えて」スペルミスをしている投稿を発⾒
(例: stupid → stup*d, stupi.d と書き換えるなど)
2. Longtao Huang, Ting Ma, Junyu Lin, Jizhong Han, Songlin Hu, 2019.
A Multimodal Text Matching Model for Obfuscated Language Identification
in Adversarial Communication. WWW-2019.
• コンテンツフィルターを回避するために隠語化している投稿を発⾒
(例: 爆弾 → ⽕暴⼸単 と書き換えるなど)
3
WWW-2019 から最先端のフィルタリング論⽂を2本紹介
★ 本資料の⽂献番号 (例: [1]) は各論⽂で利⽤している番号になります](https://image.slidesharecdn.com/wwwtsunoda-190905113952/85/Web-3-320.jpg)

![はじめに
コンテンツフィルター「回避」とは?
l フィルターに掛かりそうな単語に⼿を加えてフィルターを回避
5
Spelling Errors
(スペル誤り)
Obfuscation
(難読化)
爆弾 ⽕暴⼸単
茸, 禿, 庭, 芋(携帯キャリア)
シンナー アンパンstupid
stupi.d
stupd
stuqid
stup*d
★ Perspective(有害度等を判定できる⾔語処理 API)による toxic score [0.0, 1.0] は、“stupid” を含むとある⽂を
⼊⼒すると 86% であったのに対し、”stup*d” に置換すると 8% に低下する [論⽂①]
これらの細⼯はフィルターに多⼤な影響を及ぼす!★](https://image.slidesharecdn.com/wwwtsunoda-190905113952/85/Web-5-320.jpg)
![はじめに
コンテンツフィルター 「「回避」回避」 とは?
l フィルター回避を狙う⼩細⼯に対応する
• スペル誤り単語を発⾒‧訂正してから判定 [論⽂①]
• 周辺の単語や視覚的類似性などの情報を利⽤して判定 [論⽂②]
l
• スペル誤り‧難読化などの復元性能ではなく、有害コンテンツの
検知性能で有効性を検証している
⁃ [論⽂①] メールスパム検出、⼈種差別‧性差別ツイート検出
⁃ [論⽂②] 有害ツイート検出(Weibo)
• ただし、2つの論⽂では⼿法の枠組みが⼤きく異なる
論⽂①では前処理として訂正、論⽂②では訂正(復元)をしない等
6
両論⽂のポイント](https://image.slidesharecdn.com/wwwtsunoda-190905113952/85/Web-6-320.jpg)


![紹介論⽂1:Context-SensitiveMaliciousSpellingErrorCorrection
提案⼿法: 周辺⽂脈を参照した候補語スコア付け
l 単語の分散表現 (embedding) の2つの特徴を利⽤
1. phrase ベクトルは構成単語ベクトルの線形結合で近似できる [31]
例:
2. 単語がある⽂脈に合う場合、単語と⽂脈のベクトルは類似している [10]
l 単語 c と⽂脈 Tp の距離 dist を次のように考える (式 (1); (2), (3) は解説略)
11
hate_group ⇡ hate + group
dist(c,Tp) = min
{ai }
1
|| c ||2
||
p
ÿ
i= p,i,0
ai i c ||2
2
(正規化項)
Σ 内が最⼩になるような
都合の良い係数達
⽂脈
(前後 p 単語)
⽂脈語の
単語ベクトル
候補語の
単語ベクトル
候補語
(stupid, stud, …)
周辺語の単語ベクトル (の定数倍) との
ユークリッド距離の和を
最終的な距離と考える
非常にざっくり言えば
単語が文脈 Tp にどの程度
合ってるかを見ている](https://image.slidesharecdn.com/wwwtsunoda-190905113952/85/Web-11-320.jpg)
![紹介論⽂1:Context-SensitiveMaliciousSpellingErrorCorrection
実験3: ヘイトスピーチ検出の前処理で適⽤
l 実 Twitter データに前処理を加えて検出率が上がるかを検証
• ヘイトスピーチデータ [34] を利⽤、⼈種差別 (racism)‧性差別 (sexism) を対象
• 後段の分類器には Bi-LSTM を利⽤
• ⼈為的に誤りは⼊れない; 実際の悪意あるスペルミスに対応できるか検証
13
⽐較⼿法
ポイント①
スペル訂正をした⽅が
検出性能は⾼くなる
(Original vs. 他)
ポイント②
sexist では提案⼿法が今⼀つ
→ 「辞書」になかった略語を
無理⽮理訂正して性能低下
(例: kys = kill yourself)](https://image.slidesharecdn.com/wwwtsunoda-190905113952/85/Web-13-320.jpg)



![紹介論⽂2:AMultimodalTextMatchingModelforObfuscatedLanguageIdentificationinAdversarialCommunication
⼿法の概要
17
テキスト素性 (textual features)
Embedding
Bi-LSTM
Activation
(Softmax)
画
像
素
性
(visualfeatures)
テキスト‧画像素性の
ベクトルを引いたり掛けたり
したもの。式 (10), (11) 参照
(non-linear interaction を
⼊れると良くなるらしい [17])](https://image.slidesharecdn.com/wwwtsunoda-190905113952/85/Web-17-320.jpg)



![Webフィルタリング最前線:「「検閲回避」回避」
まとめと雑感
l まとめ
• フィルターを回避する試みに対応した2つの論⽂を紹介
• 問題は類似しているが、⼿法は割と異なる
l 雑感 〜健全化対応に携わる発表者からの若⼲の私⾒を添えて〜
• 今回は主要でなかった部分にも改善の余地はある
⁃ [論⽂①] 「辞書」の作り⽅、後段の分類器、…
⁃ [論⽂②] NG ワードリストの作成‧拡張、…
• 絶対的な性能は悪くないが、タスク的には 100% に近付ける必要がある
抜け⽳がバレると⼀瞬で広がり、時既に遅し… / ⾃動フィルター化は ≒ 100% でないと難しい
• フィルタリングはまだ取り組むべき問題の⼀つ
単純にディープラーニングに突っ込めば解消する問題ではない。データも集めにくい
22](https://image.slidesharecdn.com/wwwtsunoda-190905113952/85/Web-22-320.jpg)






















































