Download as PDF, PPTX










![Sampling…
## Creating Development and ValidationSample
##dummy_df = pd.read_csv("/home/utkarsh/Desktop/bank.csv", na_values =['NA'])
##x_train, x_test, y_train, y_test = train_test_split(x,y,test_size =0.5)
CTDF.dev <- pd.read_csv("datafile/DEV_SAMPLE.csv", sep = ",", header = T)
CTDF.holdout <- pd.read_csv ("datafile/HOLDOUT_SAMPLE.csv", sep = ",", header = T)
SamplingCode
Separate Dev & Val
samples areprovidedas
such we will directly
import them rather than
use samplingcode
Visit: Learnbay.co](https://image.slidesharecdn.com/cart-200902055603/85/Classification-Tree-Cart-18-320.jpg)












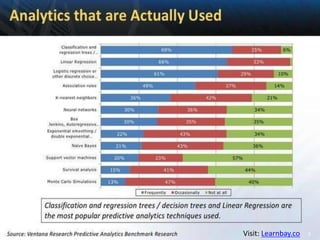
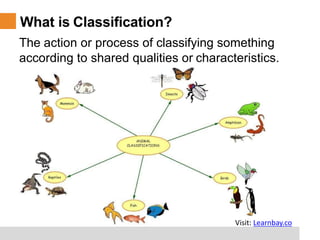
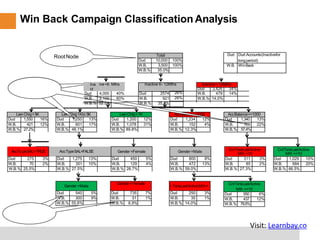
This document provides a comprehensive overview of classification tree learning in data science and AI, covering training procedures, classification techniques such as CHAID, CART, and C4.5, and practical considerations like pruning and overfitting. It includes definitions of classification, the importance of classification in predicting outcomes, and detailed descriptions of various classification algorithms and their metrics, like Gini index and misclassification error. Additionally, it highlights the training environment and objectives for learners, detailing the structure and expectations of the training program.



































































