CIDR 2009: Jeff Heer Keynote
•
5 likes•1,601 views

This is a CIDR 2009 presentation. See http://infoblog.stanford.edu/ for more information and http://www-db.cs.wisc.edu/cidr/cidr2009/program.html for downloads.

Recommended
More Related Content
Viewers also liked (6)
Similar to CIDR 2009: Jeff Heer Keynote
Similar to CIDR 2009: Jeff Heer Keynote (20)
More from infoblog
More from infoblog (14)
Recently uploaded
Recently uploaded (20)
CIDR 2009: Jeff Heer Keynote
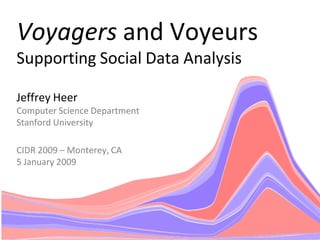
- 1. Voyagers and Voyeurs Supporting Social Data Analysis Jeffrey Heer Computer Science Department Stanford University CIDR 2009 – Monterey, CA 5 January 2009
- 2. A Tale of Two Visualizations
- 3. vizster
- 4. Observations Groups spent more time in front of the visualization than individuals. Friends encouraged each other to unearth relationships, probe community boundaries, and challenge reported information. Social play resulted in informal analysis, often driven by story-telling of group histories.
- 5. NameVoyager The Baby Name Voyager
- 10. Social Data Analysis Visual sensemaking can be social as well as cognitive. Analysis of data coupled with social interpretation and deliberation. How can user interfaces catalyze and support collaborative visual analysis?
- 11. sense.us A Web Application for Collaborative Visualization of Demographic Data
- 13. Voyagers and Voyeurs Complementary faces of analysis Voyager – focus on visualized data Active engagement with the data Serendipitous comment discovery Voyeur – focus on comment listings Investigate others’ explorations Find people and topics of interest Catalyze new explorations
- 14. Out of the Lab, Into the Wild
- 17. Wikimapia.org
- 18. DecisionSite posters Spotfire Decision Site Posters
- 19. Tableau Server
- 21. Many-Eyes
- 22. Social Data Analysis In Action 1. Discussion and Debate 2. Text is Data, Too 3. Data Integrity and Cleaning 4. Integrating Data in Context 5. Pointing and Naming For each, some thoughts on future directions. I asked my colleagues: if you could give database researchers a wish list, what would it be?
- 27. Tableau X-Box / Quest Diag? “Valley of Death”
- 31. Content Analysis of Comments Service Sense.us Many-Eyes Observation Question Hypothesis Data Integrity Linking Socializing System Design Testing Tips To-Do Affirmation 0 20 40 60 80 0 20 40 60 80 Percentage Percentage Feature prevalence from content analysis (min Cohen’s = .74) High co-occurrence of Observations, Questions, and Hypotheses
- 32. WANTED: Structured Conversation Reduce the cost of synthesizing contributions Wikipedia: Shared Revisions NASA ClickWorkers: Statistics
- 33. WANTED: Structured Conversation Reduce the cost of synthesizing contributions Can we represent data, visualizations, and social activity in a unified data model?
- 34. Text is Data, Too
- 35. Visualization Popularity Service Many-Eyes Swivel Tag Cloud Bubble Graph Word Tree Bar Chart Maps Network Diagram Treemap Matrix Chart Line Graph Scatterplot Stacked Graph Pie Chart Histogram 0.0 0.1 0.2 0.3 0.4 0.5 0.0 0.1 0.2 0.3 0.4 0.5 Percentage Percentage Over 1/3 of Many-Eyes visualizations use free text
- 37. Alberto Gonzales
- 38. WANTED: Better Tools for Text Statistical Analysis of text (with ties to source!) Entity Extraction Aggregation and Comparison of texts Get a “global” view of documents We can do better than Tag Clouds (!?) Use text analysis tools to enable analysis of structured conversation by the community.
- 39. Data Integrity and Cleaning
- 40. No cooks in 1910? … There may have been cooks then. But maybe not.
- 41. The great postmaster scourge of 1910? Or just a bug in the data?
- 44. Content Analysis of Comments Service Sense.us Many-Eyes Observation Question Hypothesis Data Integrity Linking Socializing System Design Testing Tips To-Do Affirmation 0 20 40 60 80 0 20 40 60 80 Percentage Percentage 16% of sense.us comments and 10% of Many-Eyes comments reference data quality or integrity.
- 45. WANTED: Data Cleaning Tools Reshape data, reformat rows & columns Handle missing data: label, repair, interpolate Entity resolution and de-duplication Group related values into aggregates Assist table lookups & data transforms Provide tools in situ to leverage collective Transparency requires provenance
- 46. Integrating Data in Context
- 49. College Drug Use
- 50. College Drug Use
- 51. Harry Potter is Freaking Popular
- 53. WANTED: In-Situ Data Integration Search for and suggest related data or views User input for types, schema matching, or data Apply in context of the current task But record mappings for future use Record provenance: chain of data sources Examples: Google Web Tables, Pay-As-You-Go, Stanford Vispedia, Utah VisTrails
- 55. “Look at that spike.”
- 56. “Look at the spike for Turkey.”
- 57. “Look at the spike in the middle.”
- 58. Free-form Data-aware
- 59. Visual Queries Model selections as declarative queries over interface elements or underlying data (-118.371 ≤ lon AND lon ≤ -118.164) AND (33.915 ≤ lat AND lat ≤ 34.089)
- 60. Visual Queries Model selections as declarative queries over interface elements or underlying data Applicable to dynamic, time-varying data Retarget selection across visual encodings Support social navigation and data mining
- 61. WANTED: Data-Aware Annotation Meta-queries linking annotations to views Visually specifying notification triggers Annotating data aggregates (use lineage?) Unified model (again!) to facilitate reference How to make it work at scale? How else to use machine-readable annotations? Can annotations be used to steer data mining?
- 62. Conclusion
- 63. Social Data Analysis Collective analysis of data supported by social interaction. 1. Discussion and Debate 2. Text is Data, Too 3. Data Integrity and Cleaning 4. Integrating Data in Context 5. Pointing and Naming
- 64. Summary As visualization becomes common on the web, opportunities for collaborative analysis abound. Weave visualizations into the web: data access, visualization creation, view sharing and pointing. Support discovery, discussion, and integration of contributions to leverage the collective. Improve both processes and technologies for communication and dissemination.
- 65. Parting Thoughts Visualizations may have a catalytic effect on social interaction around data. Encourage participation by minimizing or offsetting interaction costs. Provide incentives by fostering the personal relevance of the data.
- 66. Acknowledgements @ Berkeley: Maneesh Agrawala, Wes Willett, danah boyd, Marti Hearst, Joe Hellerstein @ IBM: Martin Wattenberg, Fernanda Viégas @ PARC: Stu Card @ Tableau: Jock Mackinlay, Chris Stolte, Christian Chabot
- 67. Voyagers and Voyeurs Supporting Social Data Analysis Jeffrey Heer Stanford University jheer@stanford.edu http://jheer.org
- 68. With a collaborative spirit, with a collaborative platform where people can upload data, explore data, compare solutions, discuss the results, build consensus, we can engage passionate people, local communities, media and this will raise - incredibly - the amount of people who can understand what is going on. And this would have fantastic outcomes: the engagement of people, especially new generations; it would increase knowledge, unlock statistics, improve transparency and accountability of public policies, change culture, increase numeracy, and in the end, improve democracy and welfare. Enrico Giovannini, Chief Statistician, OECD. June 2007.