Download as PDF, PPTX








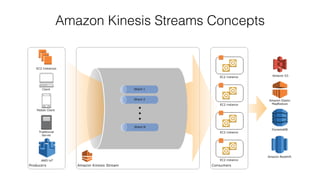
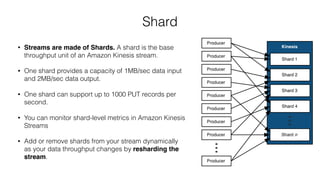



















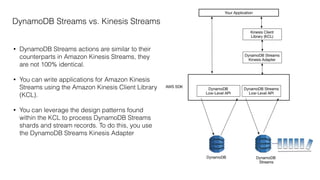

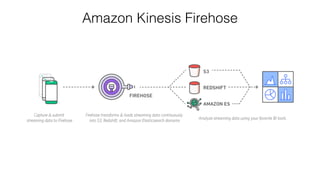





This document provides an overview of AWS Kinesis and its components for streaming data. It describes Amazon Kinesis Streams for processing real-time streaming data at large scale. Key concepts explained include shards, data records, partition keys, sequence numbers, and resharding streams. It also covers the Amazon Kinesis Producer Library, Amazon Kinesis Client Library, and how to handle failures and duplicate records. Amazon Kinesis Firehose and Kinesis Analytics are introduced for loading and analyzing streaming data. Comparisons are made between Kinesis and other AWS services like DynamoDB Streams, SQS, and Kafka.











![[RDS /Remote Desktop Services] Lesson 1 : Security Risks & Best Practices You...](https://cdn.slidesharecdn.com/ss_thumbnails/rdssecurity-riskssecuritypracticesyoushouldknow-190112220533-thumbnail.jpg?width=640&height=640&fit=bounds)























































