Download as PDF, PPTX






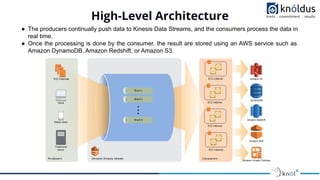









This document provides an introduction and overview of Amazon Kinesis Data Streams. It begins with definitions of streaming data and examples. It then introduces Amazon Kinesis Data Streams as a scalable real-time data streaming service. It outlines the basic architecture involving producers, streams, shards, and consumers. It defines key concepts like records, partitions, and capacity modes. It also lists some basic operations on streams like creating, describing, putting records, and getting records. Finally, it concludes with references for further reading.























































































