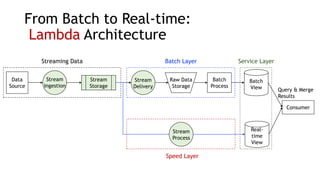
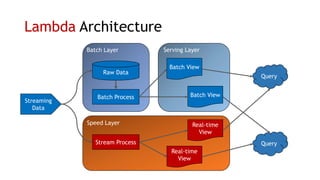
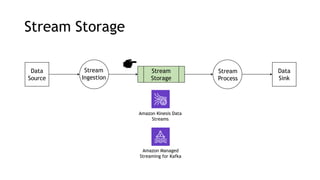
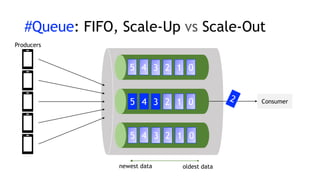
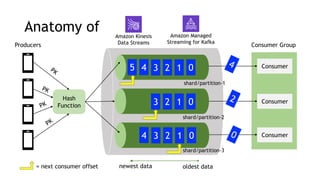
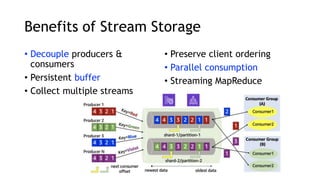
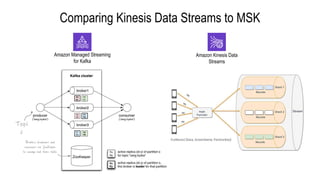
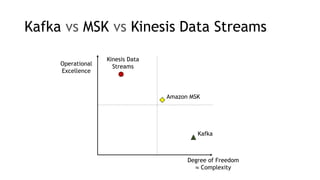
- Amazon Kinesis Data Streams and Amazon Managed Streaming for Kafka (MSK) are services for stream storage and processing. Kinesis Data Streams uses shards that can scale out, while MSK uses Kafka brokers that require more manual scaling.
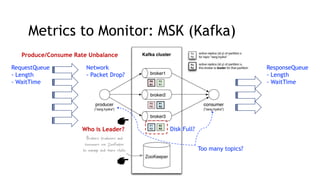
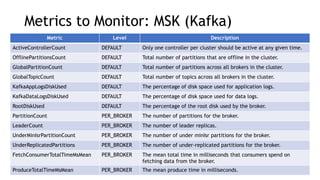
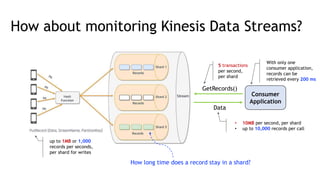
- Key metrics to monitor for stream processing include request/response queues, produce/consume rates, network traffic, and disk usage. Monitoring helps identify bottlenecks or imbalances.
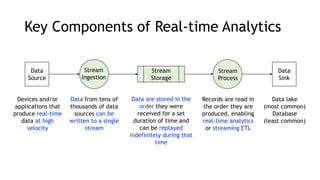
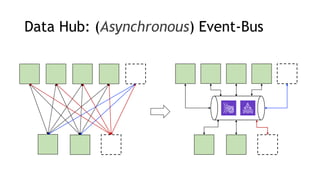
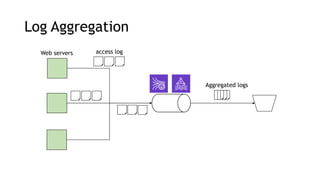
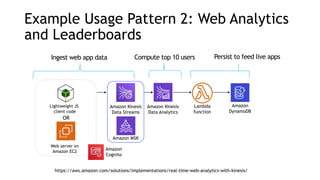
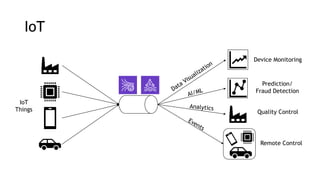
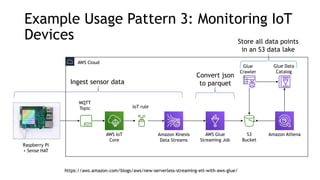
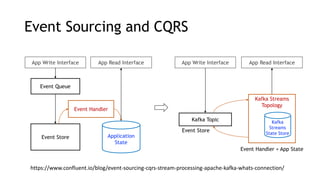
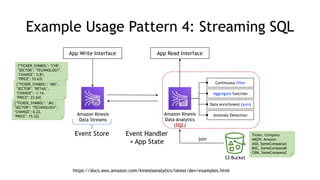
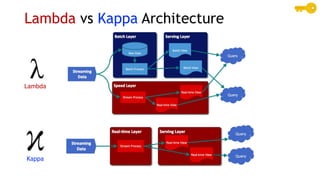
- Common streaming architectures include using Kinesis/MSK as an event bus, log aggregation from IoT devices, event sourcing with CQRS, and real-time analytics with Kinesis Analytics. These patterns are useful for building real-time applications and analytics.