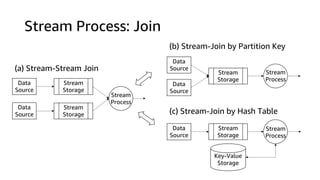
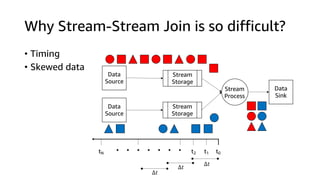
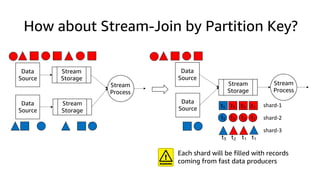
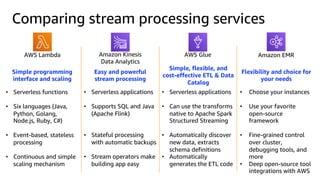
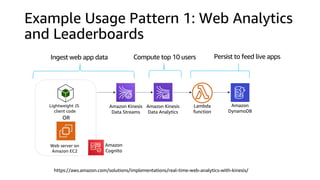
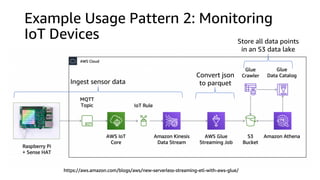
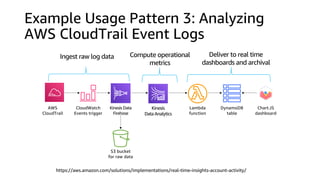
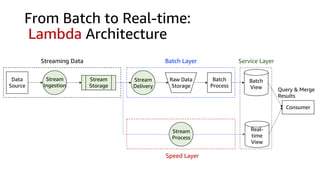
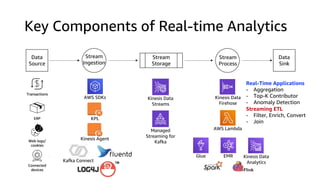
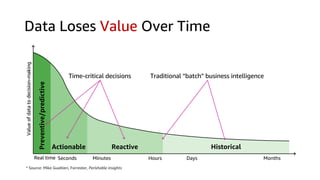
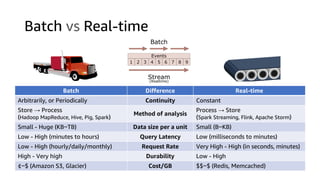
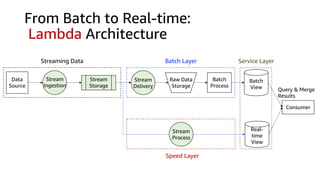
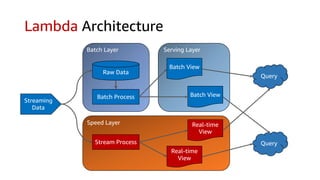
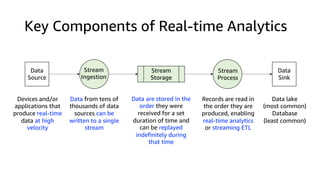
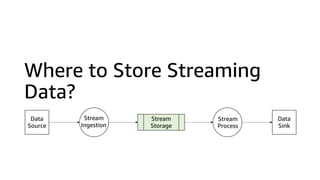
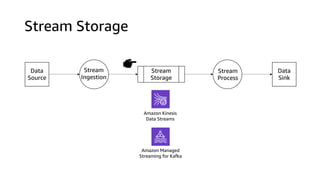
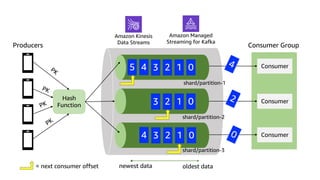
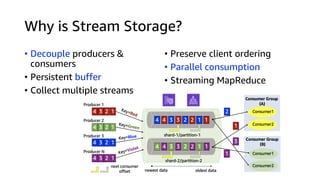
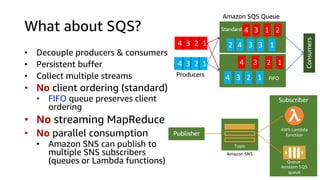
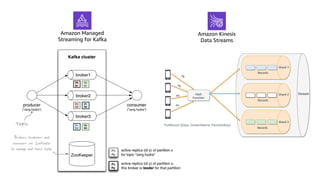
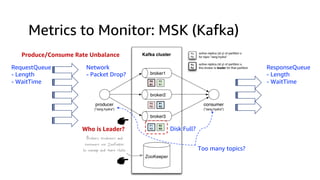
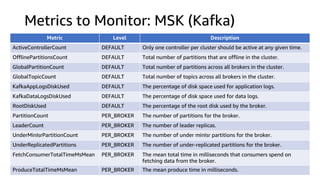
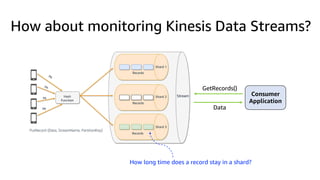
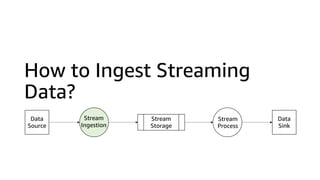
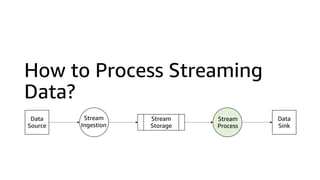
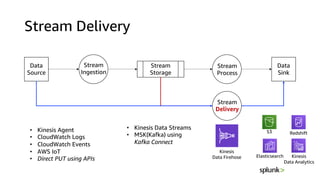
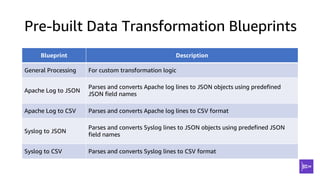
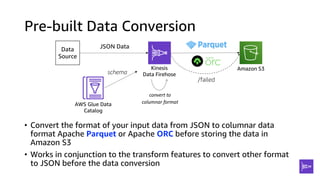
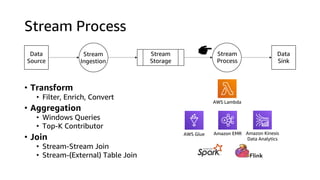
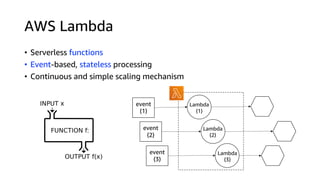
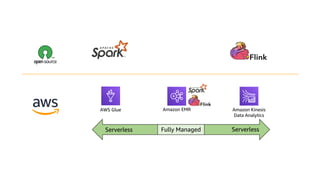
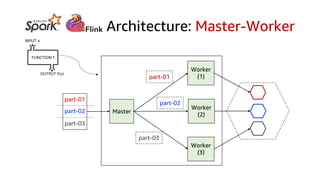
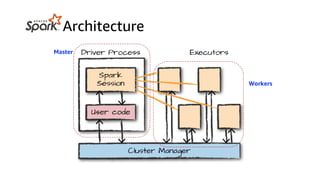
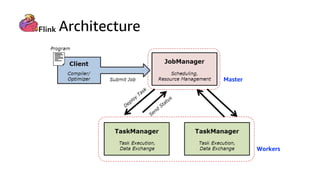
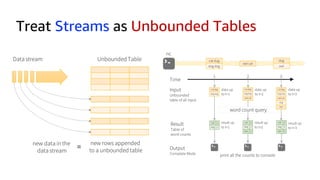
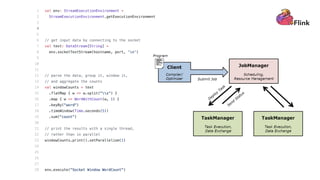
This document discusses real-time analytics on streaming data. It describes why real-time data streaming and analytics are important due to the perishable nature of data value over time. It then covers key components of real-time analytics systems including data sources, stream storage, stream ingestion, stream processing, and stream delivery. Finally, it discusses streaming data processing techniques like filtering, enriching, and converting streaming data.








![Kinesis Firehose: Filter, Enrich, Convert
Data
Source
apache log
apache log
json Data
Sink
[Wed Oct 11 14:32:52 2017] [error] [client 192.34.86.178]
[Wed Oct 11 14:32:53 2017] [info] [client 127.0.0.1]
{
"date": "2017/10/11 14:32:52",
"status": "error",
"source": "192.34.86.178",
"city": "Boston",
"state": "MA"
}
geo-ip
{
"recordId": "1",
"result": "Ok",
"data": {
"date": "2017/10/11 14:32:52",
"status": "error",
"source": "192.34.86.178",
"city": "Boston",
"state": "MA"
},
},
{
"recordId": "2",
"result": "Dropped"
}
json
Lambda function
Kinesis
Data Firehose](https://image.slidesharecdn.com/realtimeanalyticsonaws-200618041523/85/Realtime-Analytics-on-AWS-27-320.jpg)



![“It's raining cats and dogs!”
["It's", "raining", "cats", "and", "dogs!"]
[("It's", 1), ("raining", 1), ("cats", 1),
("and", 1), ("dogs!", 1)]
It’s 1
raining 1
cats 1
and 1
dogs! 1](https://image.slidesharecdn.com/realtimeanalyticsonaws-200618041523/85/Realtime-Analytics-on-AWS-40-320.jpg)
![“It's raining cats and dogs!”
["It's", "raining", "cats", "and", "dogs!"]
[("It's", 1), ("raining", 1), ("cats", 1),
("and", 1), ("dogs!", 1)]
It’s 1
raining 1
cats 1
and 1
dogs! 1](https://image.slidesharecdn.com/realtimeanalyticsonaws-200618041523/85/Realtime-Analytics-on-AWS-42-320.jpg)

![What about (Stream) SQL?
Data
Source
Stream
Storage
Stream
SQL
Process
Stream
Ingestion
Data
Sink
[("It's", 1),
("raining", 1),
("cats", 1),
("and", 1),
("dogs!", 1)]
“It's raining cats and dogs!” It’s 1
raining 1
cats 1
and 1
dogs! 1](https://image.slidesharecdn.com/realtimeanalyticsonaws-200618041523/85/Realtime-Analytics-on-AWS-45-320.jpg)
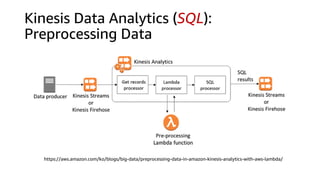
![Kinesis Data Analytics (SQL)
• STREAM (in-application): a continuously
updated entity that you can SELECT from and
INSERT into like a TABLE
• PUMP: an entity used to continuously
'SELECT ... FROM' a source STREAM, and
INSERT SQL results into an output STREAM
• Create output stream, which can be used to
send to a destination
SOURCE
STREAM
INSERT
& SELECT
(PUMP)
DESTIN.
STREAM
Destination
Source
[("It's", 1),
("raining", 1),
("cats", 1),
("and", 1),
("dogs!", 1)]](https://image.slidesharecdn.com/realtimeanalyticsonaws-200618041523/85/Realtime-Analytics-on-AWS-46-320.jpg)


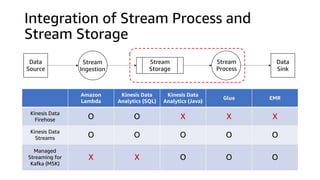
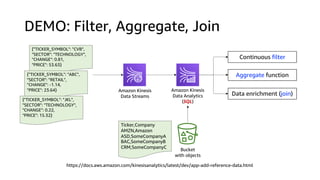
![https://aws.amazon.com/ko/blogs/aws/new-amazon-kinesis-data-analytics-for-java/
Amazon Kinesis
Data Streams
Amazon Kinesis
Data Firehose
Amazon S3Amazon Kinesis
Data Analytics
(Java)
Amazon Kinesis
Data Streams
Amazon Kinesis
Data Streams
Amazon Kinesis
Data Analytics
(SQL)
DEMO: Word Count
“It's raining cats and dogs!”
[("It's", 1),
("raining", 1),
("cats", 1),
("and", 1),
("dogs!", 1)]
It’s 1
raining 1
cats 1
and 1
dogs! 1
[("It's", 1),
("raining", 1),
("cats", 1),
("and", 1),
("dogs!", 1)]
1
2](https://image.slidesharecdn.com/realtimeanalyticsonaws-200618041523/85/Realtime-Analytics-on-AWS-49-320.jpg)
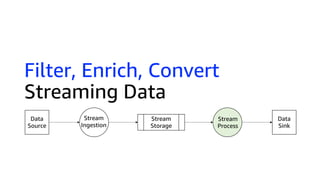
![Revisit Example: Filter, Enrich, Convert
Data
Source
Kinesis
Data Firehose
apache log
apache log
json Data
Sink
[Wed Oct 11 14:32:52 2017] [error] [client 192.34.86.178]
[Wed Oct 11 14:32:53 2017] [info] [client 127.0.0.1]
{
"date": "2017/10/11 14:32:52",
"status": "error",
"source": "192.34.86.178",
"city": "Boston",
"state": "MA"
}
geo-ip
{
"recordId": "1",
"result": "Ok",
"data": {
"date": "2017/10/11 14:32:52",
"status": "error",
"source": "192.34.86.178",
"city": "Boston",
"state": "MA"
},
},
{
"recordId": "2",
"result": "Dropped"
}
json
Lambda function](https://image.slidesharecdn.com/realtimeanalyticsonaws-200618041523/85/Realtime-Analytics-on-AWS-51-320.jpg)
![Stream Process: Filter, Enrich, Convert
Data
Source
apache log
apache log
json Data
Sink
[Wed Oct 11 14:32:52 2017] [error] [client 192.34.86.178]
[Wed Oct 11 14:32:53 2017] [info] [client 127.0.0.1]
{
"date": "2017/10/11 14:32:52",
"status": "error",
"source": "192.34.86.178",
"city": "Boston",
"state": "MA"
}
geo-ip
{
"recordId": "1",
"result": "Ok",
"data": {
"date": "2017/10/11 14:32:52",
"status": "error",
"source": "192.34.86.178",
"city": "Boston",
"state": "MA"
},
},
{
"recordId": "2",
"result": "Dropped"
}
Amazon Kinesis
Data Streams
Lambda function
Amazon EMR AWS GlueAmazon Kinesis
Data Analytics](https://image.slidesharecdn.com/realtimeanalyticsonaws-200618041523/85/Realtime-Analytics-on-AWS-52-320.jpg)
![Stream Process: Filter, Enrich, Convert
Data
Source
apache log
apache log
json Data
Sink
[Wed Oct 11 14:32:52 2017] [error] [client 192.34.86.178]
[Wed Oct 11 14:32:53 2017] [info] [client 127.0.0.1]
{
"date": "2017/10/11 14:32:52",
"status": "error",
"source": "192.34.86.178",
"city": "Boston",
"state": "MA"
}
geo-ip
{
"recordId": "1",
"result": "Ok",
"data": {
"date": "2017/10/11 14:32:52",
"status": "error",
"source": "192.34.86.178",
"city": "Boston",
"state": "MA"
},
},
{
"recordId": "2",
"result": "Dropped"
} Amazon EMR AWS Glue
Amazon MSK
Amazon Kinesis
Data Analytics
(Java)](https://image.slidesharecdn.com/realtimeanalyticsonaws-200618041523/85/Realtime-Analytics-on-AWS-53-320.jpg)