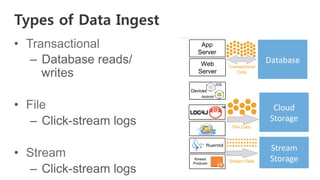
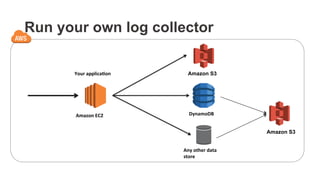
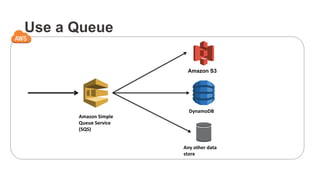
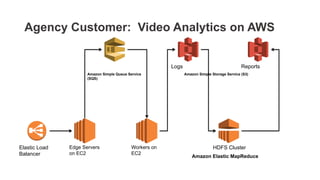
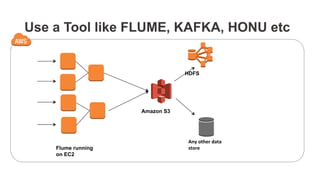
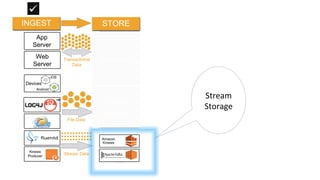
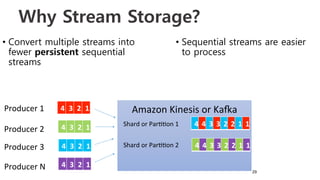
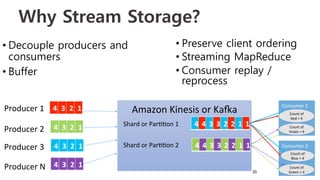
Download as PDF, PPTX












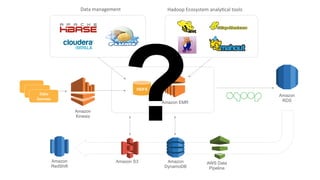
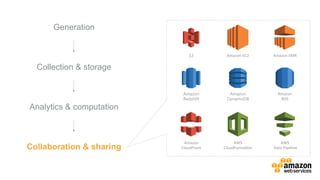




![Data
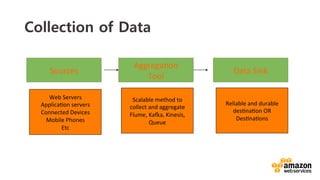
Sources
App.4
[Machine
Learning]
AWS
Endpoint
App.1
[Aggregate
&
De-‐Duplicate]
Data
Sources
Data
Sources
Data
Sources
App.2
[Metric
Extrac0on]
S3
DynamoDB
Redshift
App.3
[Sliding
Window
Analysis]
Data
Sources
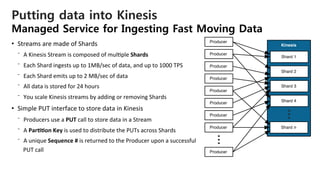
Availability
Zone
Shard
1
Shard
2
Shard
N
Availability
Zone
Availability
Zone
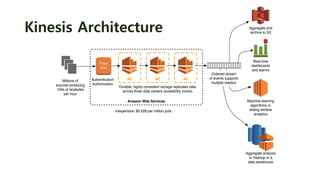
Introducing Amazon Kinesis
Managed Service for Real-Time Processing of Big Data
EMR](https://image.slidesharecdn.com/krwebinar2015yourfirstbigdataonaws-150712121920-lva1-app6892/85/AWS-AWS-2015-32-320.jpg)

![37
Easy
Administra0on
Managed
service
for
real-‐8me
streaming
data
collec8on,
processing
and
analysis.
Simply
create
a
new
stream,
set
the
desired
level
of
capacity,
and
let
the
service
handle
the
rest.
Real-‐0me
Performance
Perform
con8nual
processing
on
streaming
big
data.
Processing
latencies
fall
to
a
few
seconds,
compared
with
the
minutes
or
hours
associated
with
batch
processing.
High
Throughput.
Elas0c
Seamlessly
scale
to
match
your
data
throughput
rate
and
volume.
You
can
easily
scale
up
to
gigabytes
per
second.
The
service
will
scale
up
or
down
based
on
your
opera8onal
or
business
needs.
S3,
EMR,
Storm,
RedshiY,
&
DynamoDB
Integra0on
Reliably
collect,
process,
and
transform
all
of
your
data
in
real-‐8me
&
deliver
to
AWS
data
stores
of
choice,
with
Connectors
for
S3,
Redshi],
and
DynamoDB.
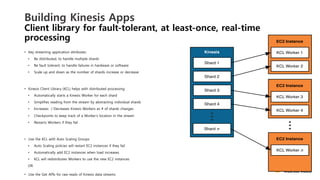
Build
Real-‐0me
Applica0ons
Client
libraries
that
enable
developers
to
design
and
operate
real-‐8me
streaming
data
processing
applica8ons.
Low
Cost
Cost-‐efficient
for
workloads
of
any
scale.
You
can
get
started
by
provisioning
a
small
stream,
and
pay
low
hourly
rates
only
for
what
you
use.
Amazon Kinesis: Key Developer Benefits](https://image.slidesharecdn.com/krwebinar2015yourfirstbigdataonaws-150712121920-lva1-app6892/85/AWS-AWS-2015-37-320.jpg)

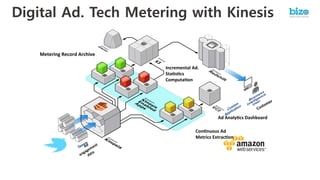
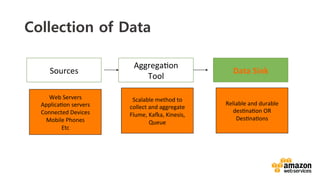
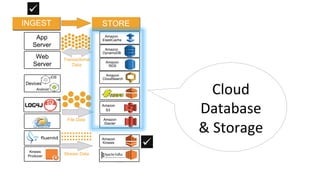
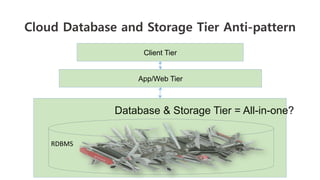
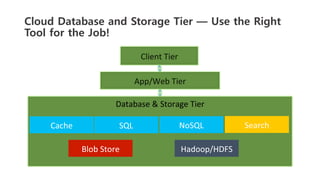
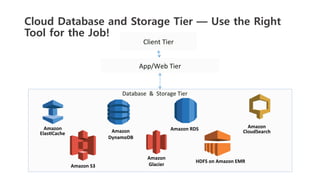

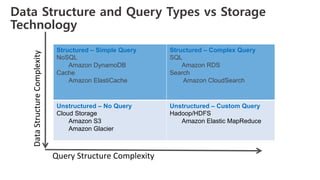
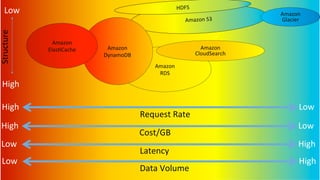


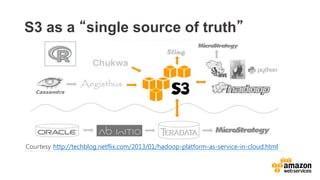
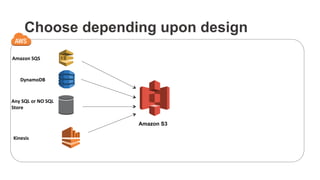



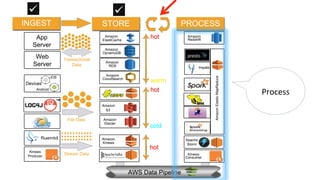


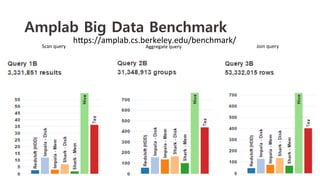
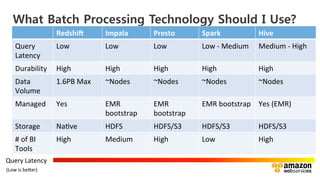

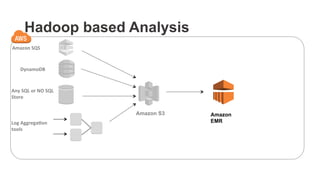
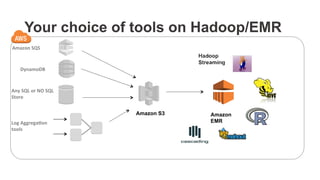
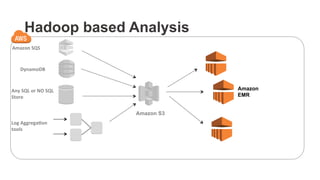
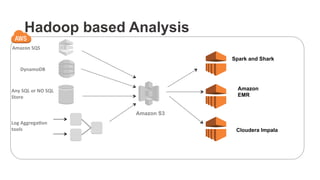


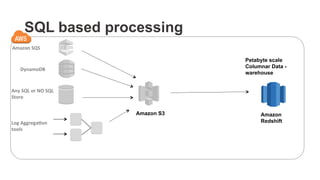
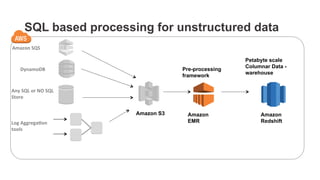
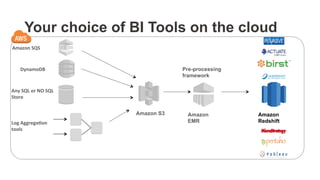
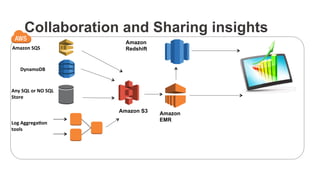
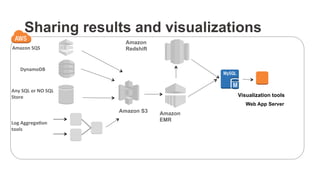
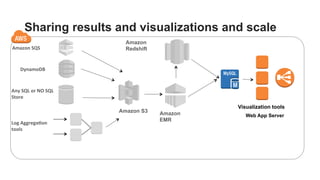
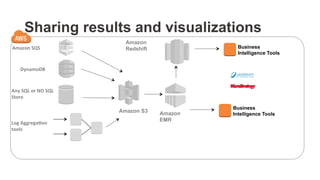
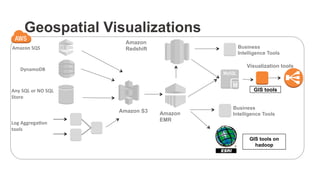
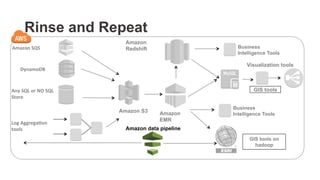
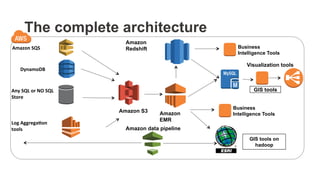
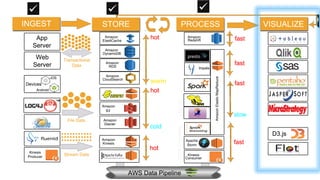



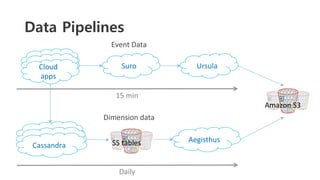




The document outlines a webinar on starting big data projects using Amazon Web Services (AWS) tools such as Elastic MapReduce, Redshift, and Kinesis. It covers various AWS big data components, data collection and storage methods, and analytics strategies, providing insights into real-time data processing and successful use cases, particularly for video analytics. The presentation emphasizes the importance of selecting the right tools at the right scale and time for effective big data solutions.






























































![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)























