





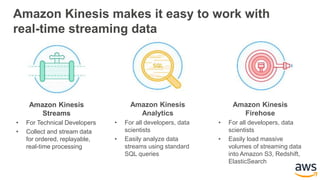
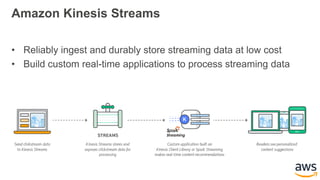
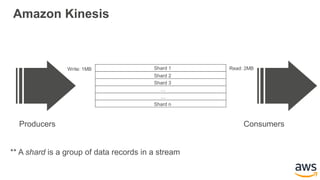
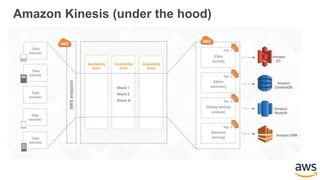







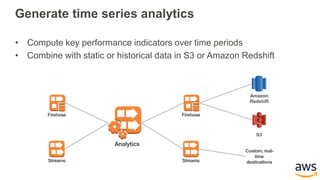
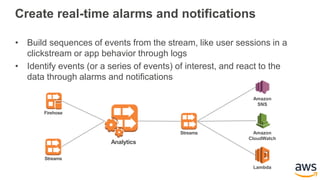
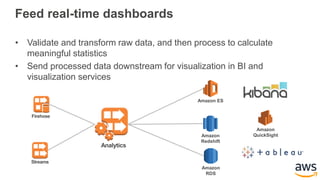


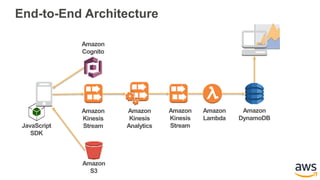

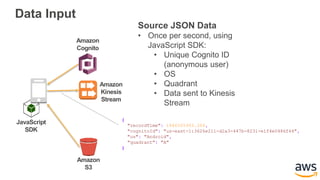



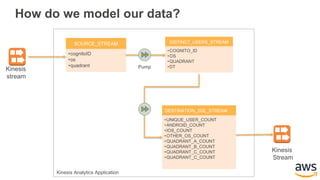


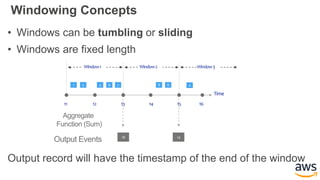
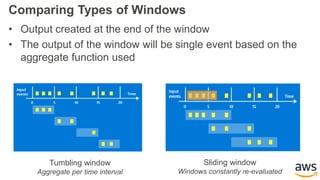
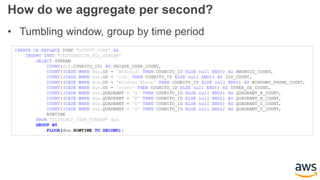

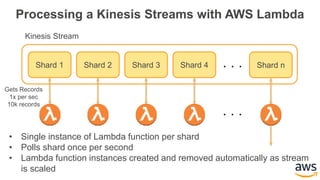

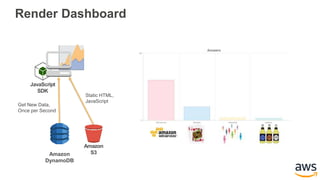




This document provides an overview of building a real-time streaming data visualization system with Amazon Kinesis Analytics. It begins with an introduction and outlines what will be covered, including streaming data, the Amazon Kinesis platform, Kinesis Analytics patterns and features, and a walkthrough of an end-to-end streaming data example. It then provides details on the Amazon Kinesis platform and services, demonstrates how to write SQL queries to analyze streaming data in Kinesis Analytics, and shows how to output results to destinations like Kinesis streams, S3, and DynamoDB. It concludes with notes on deploying Kinesis Analytics applications and testing.



































































