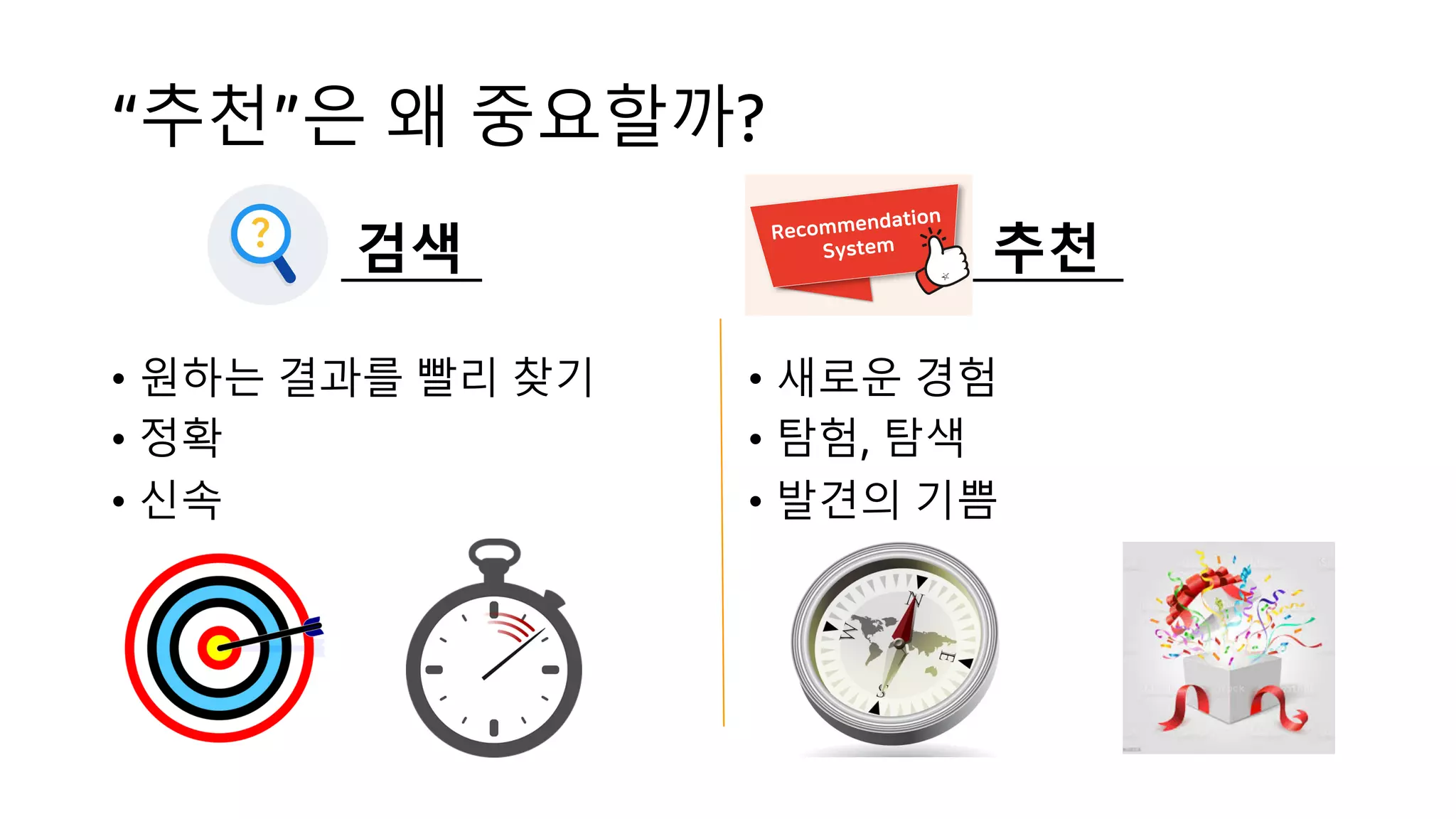
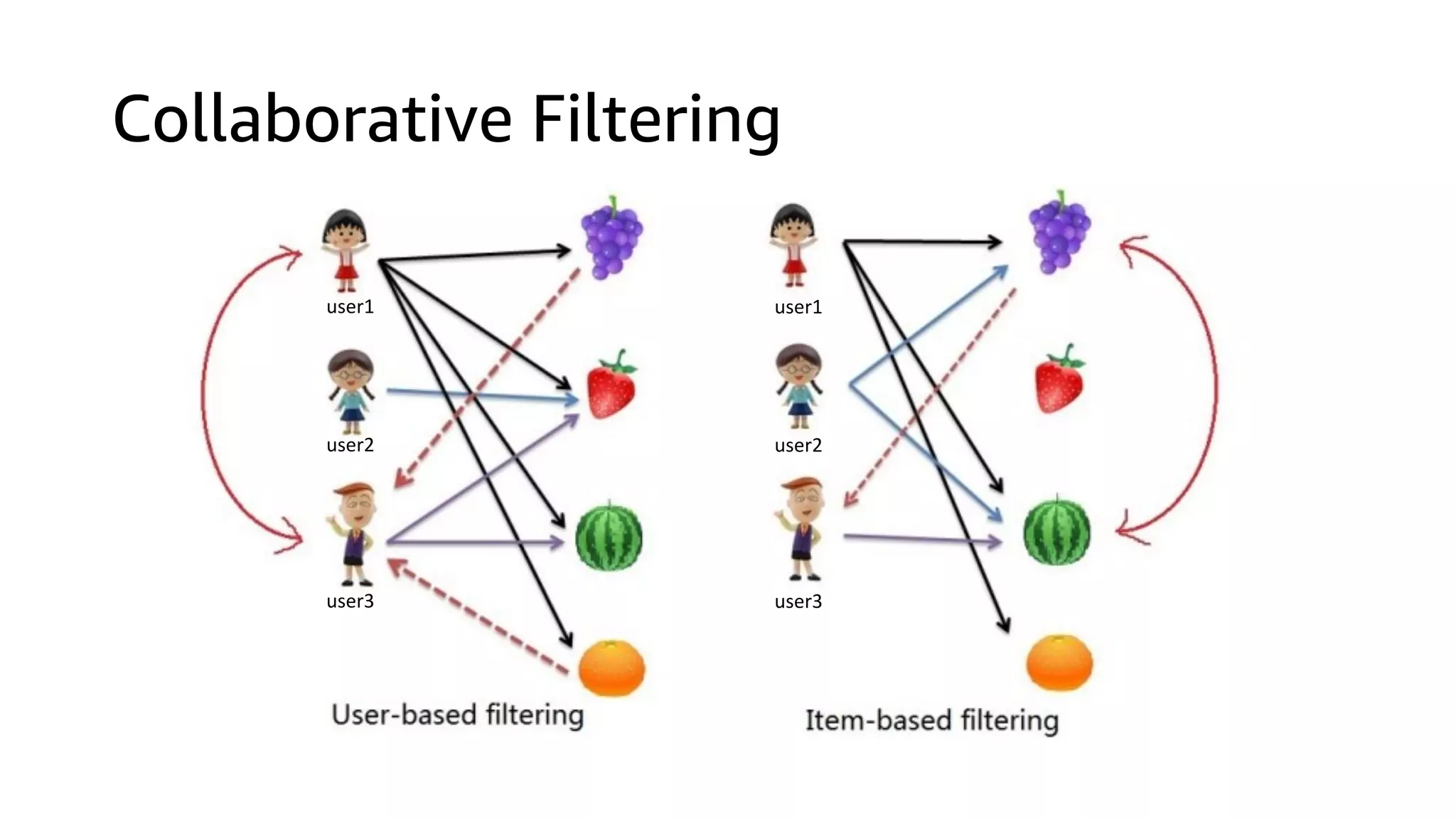
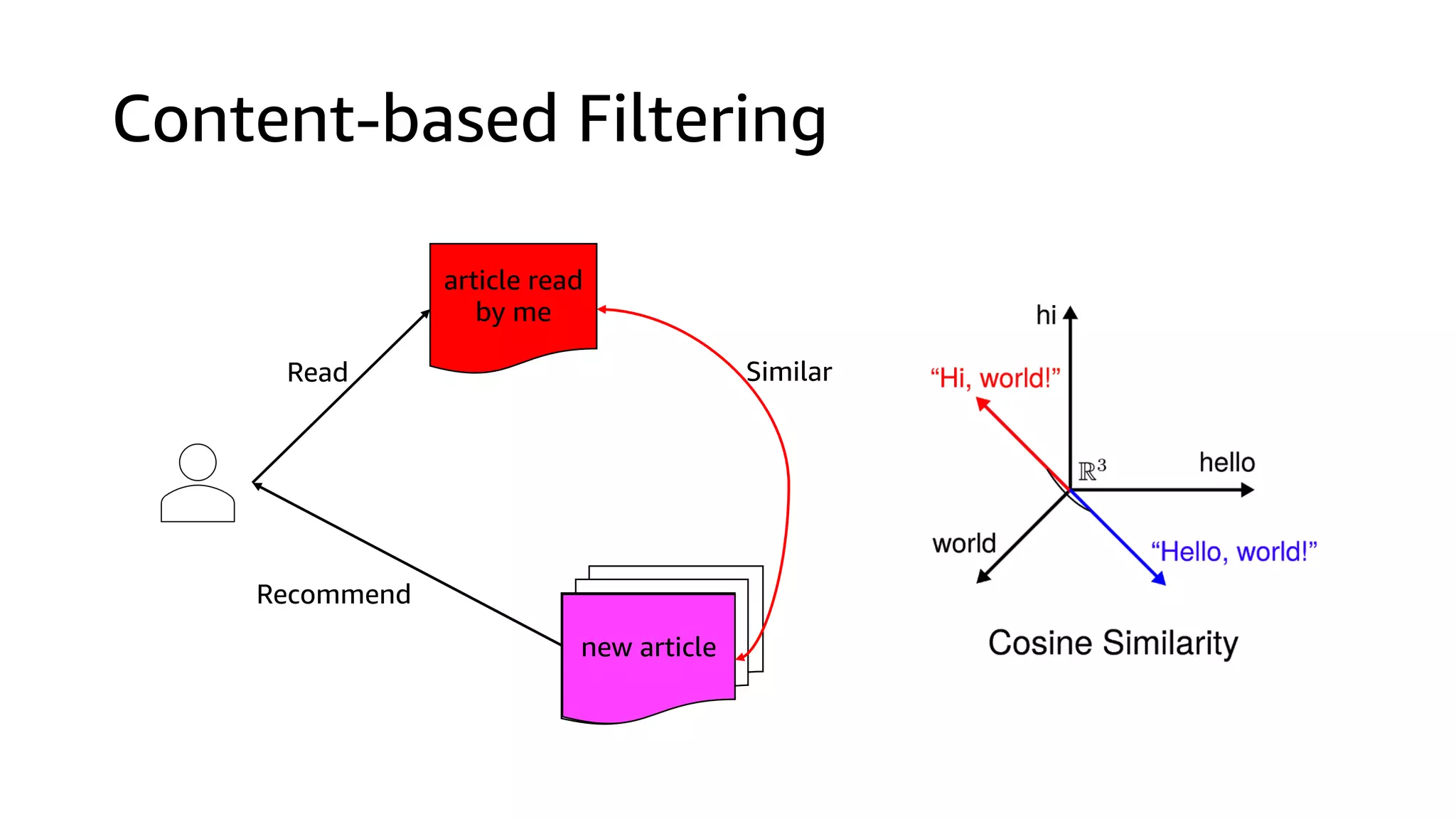
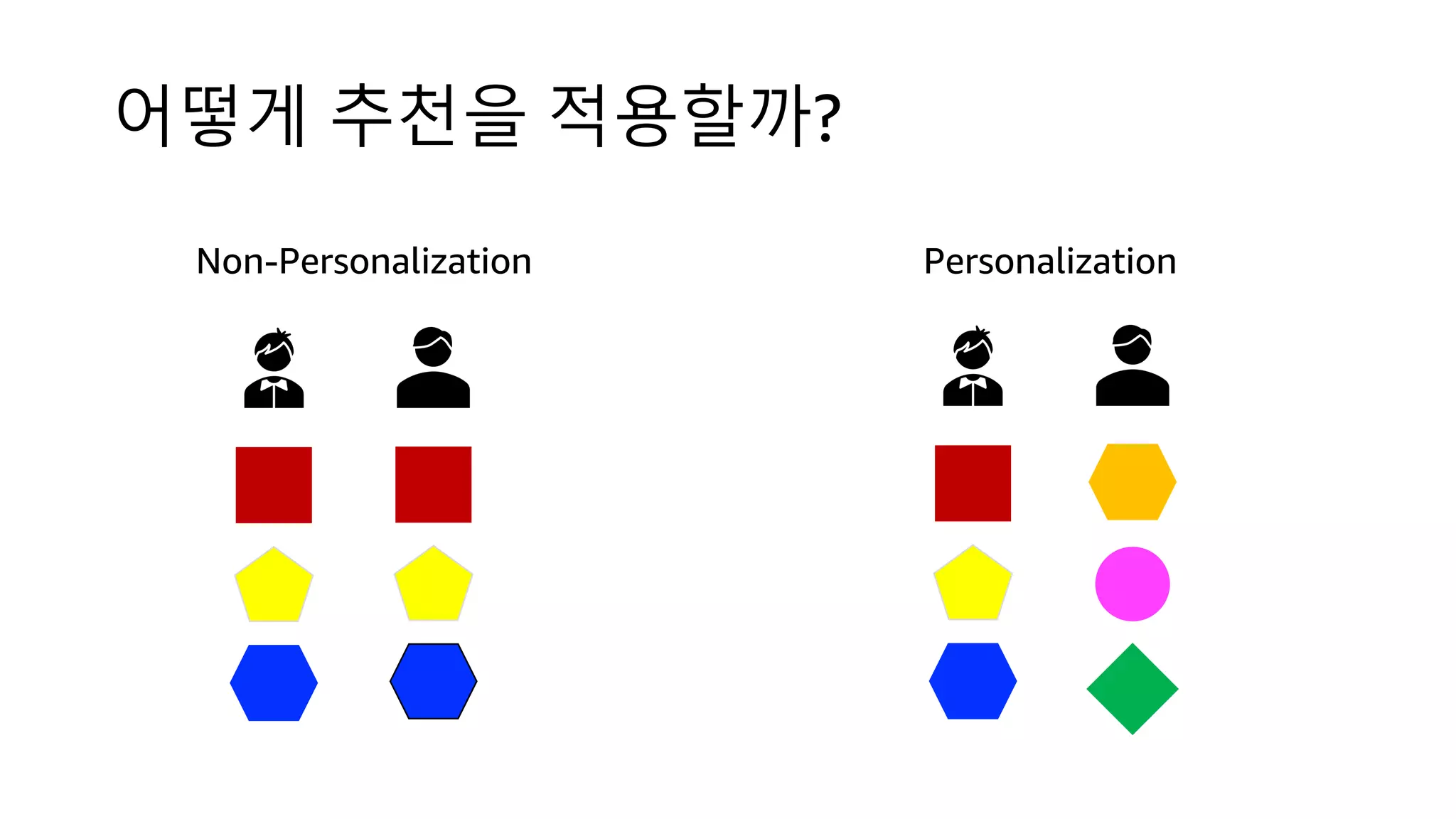
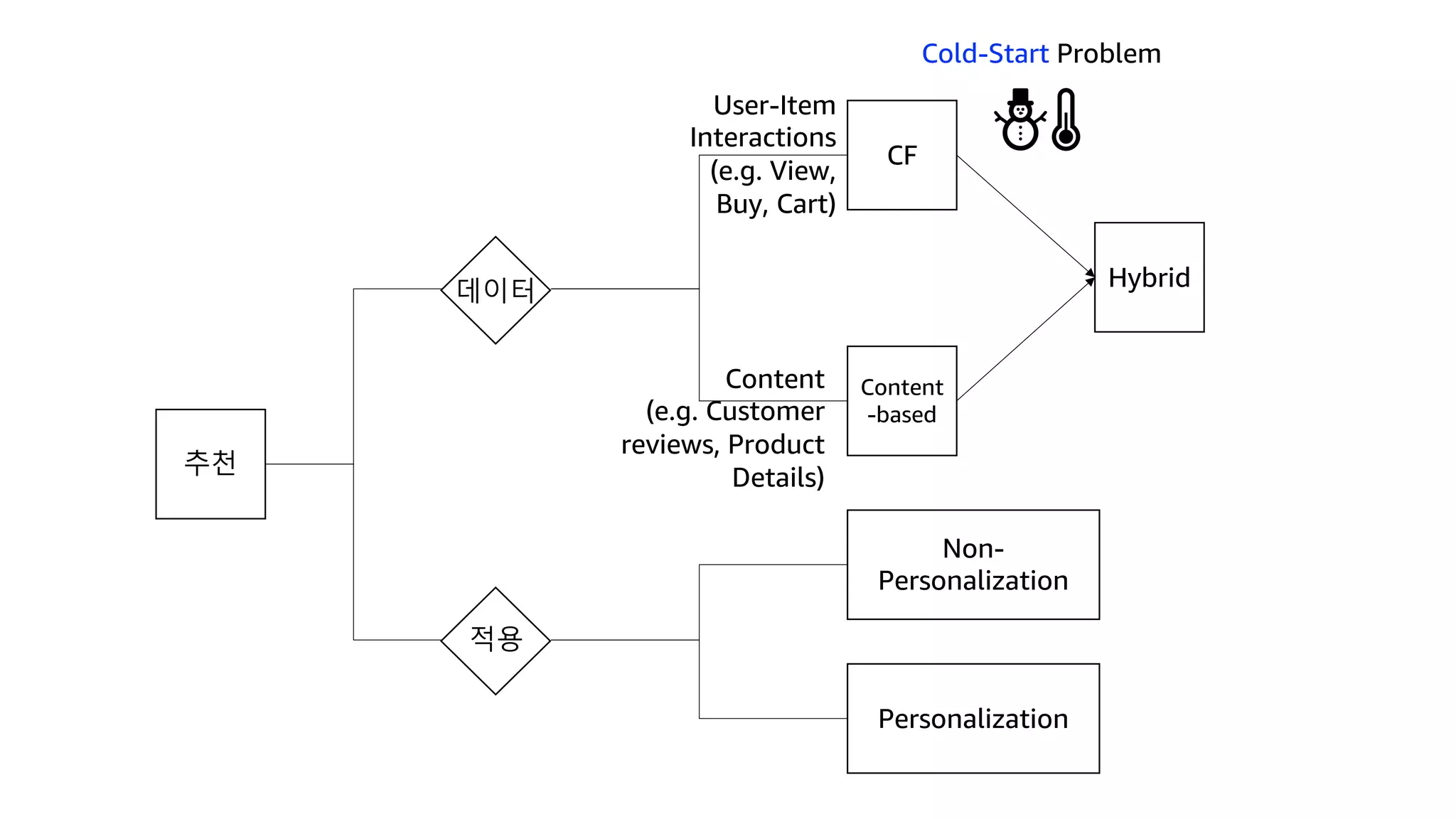
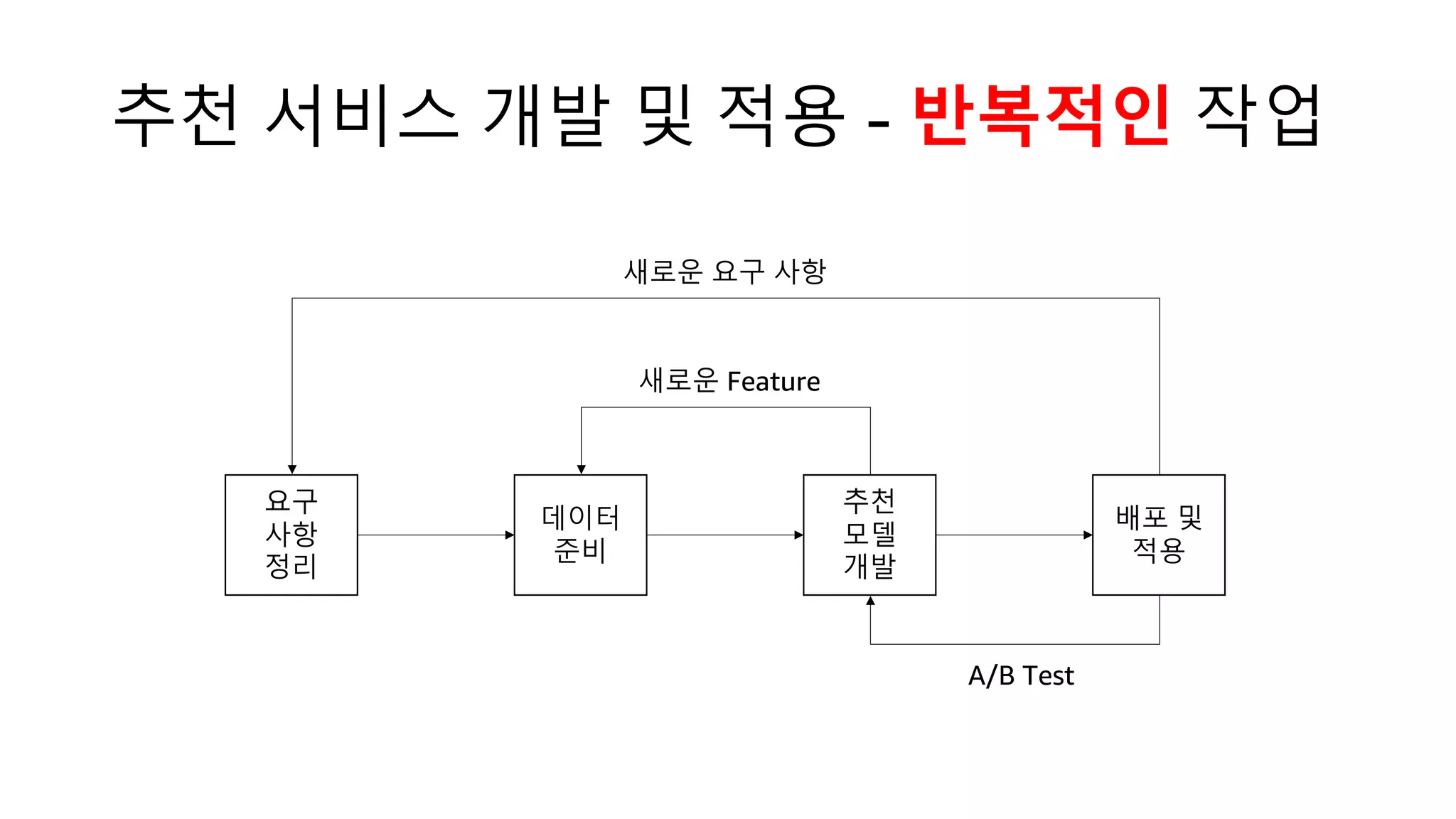
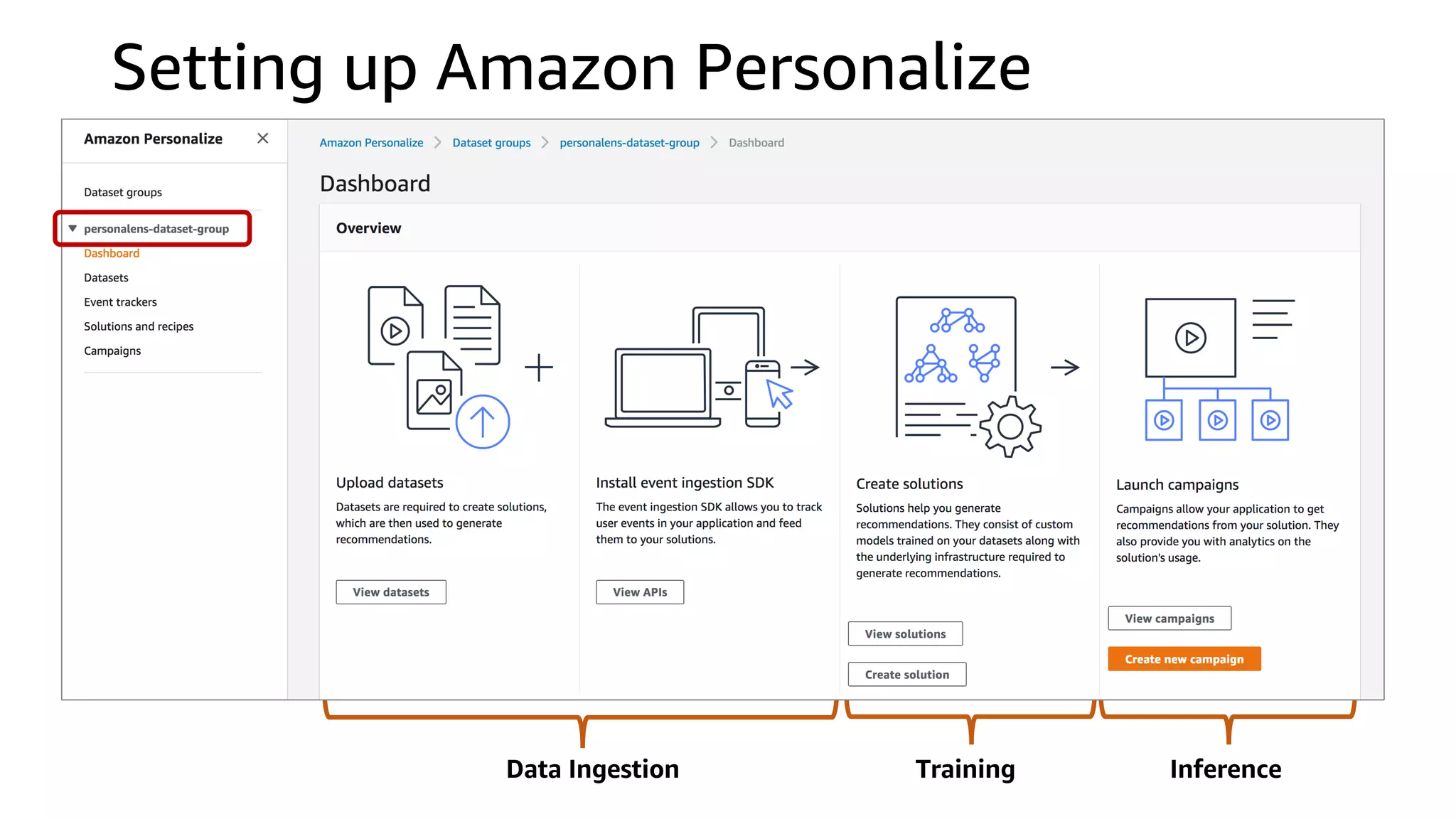
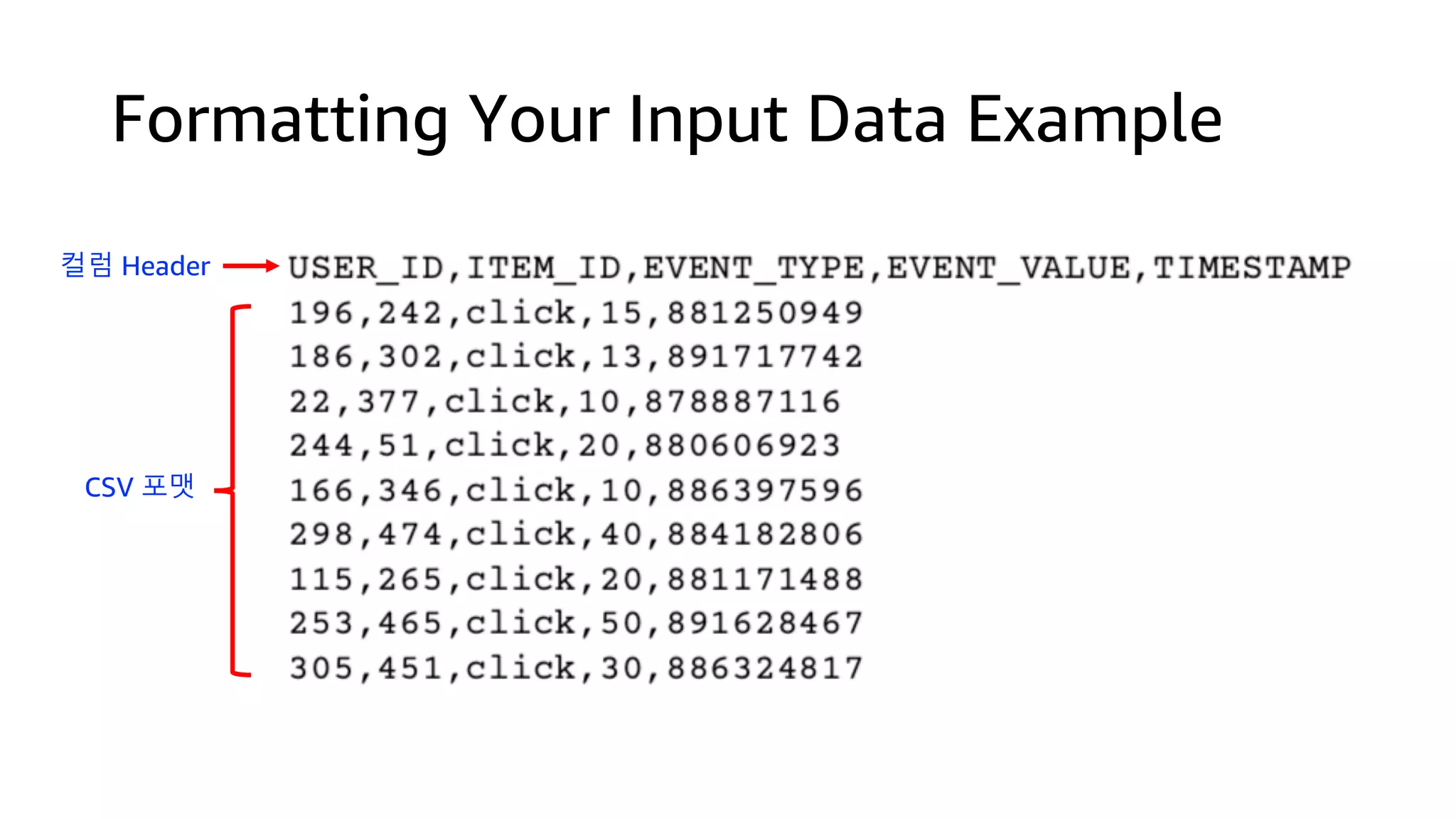
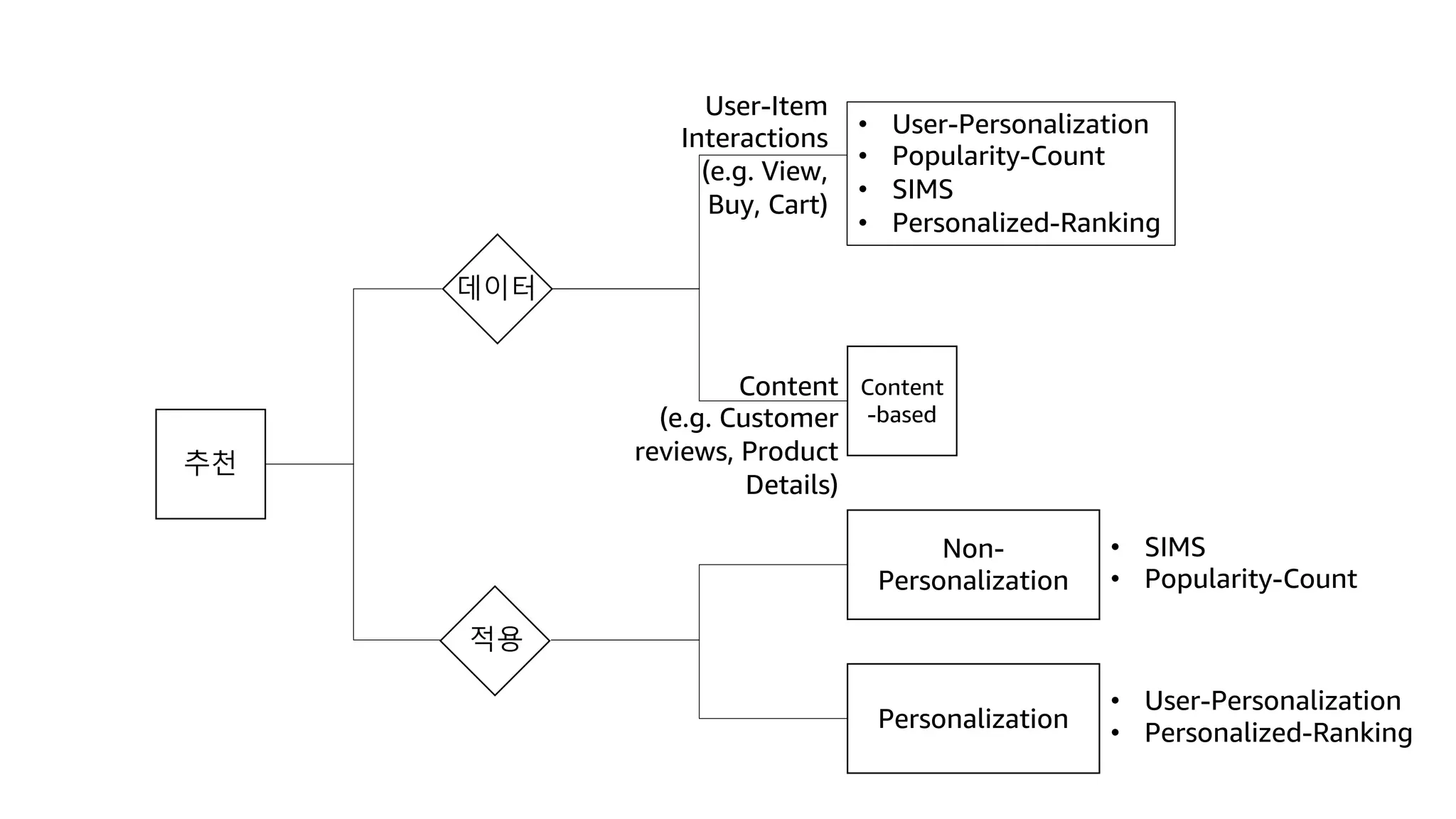
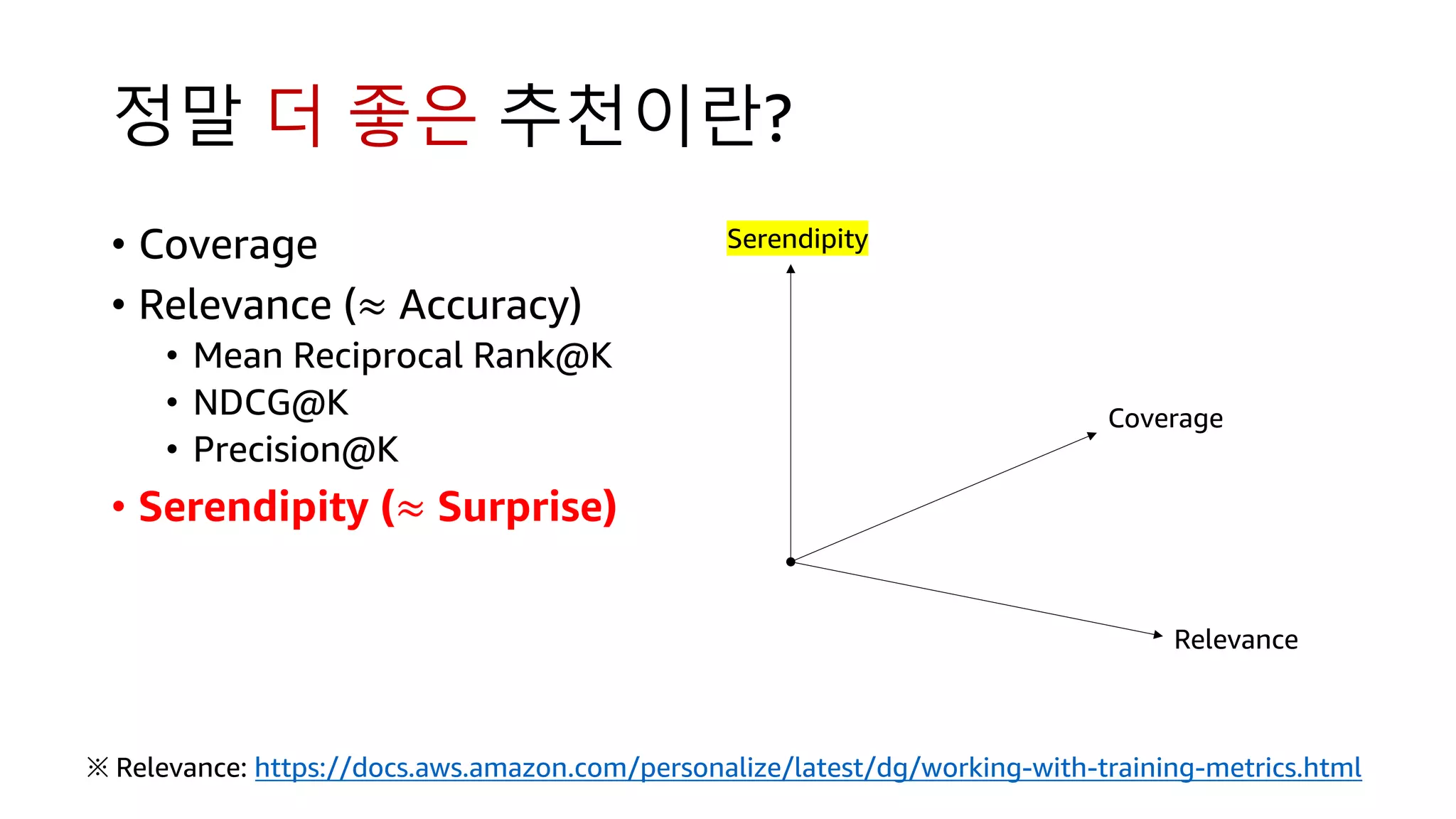
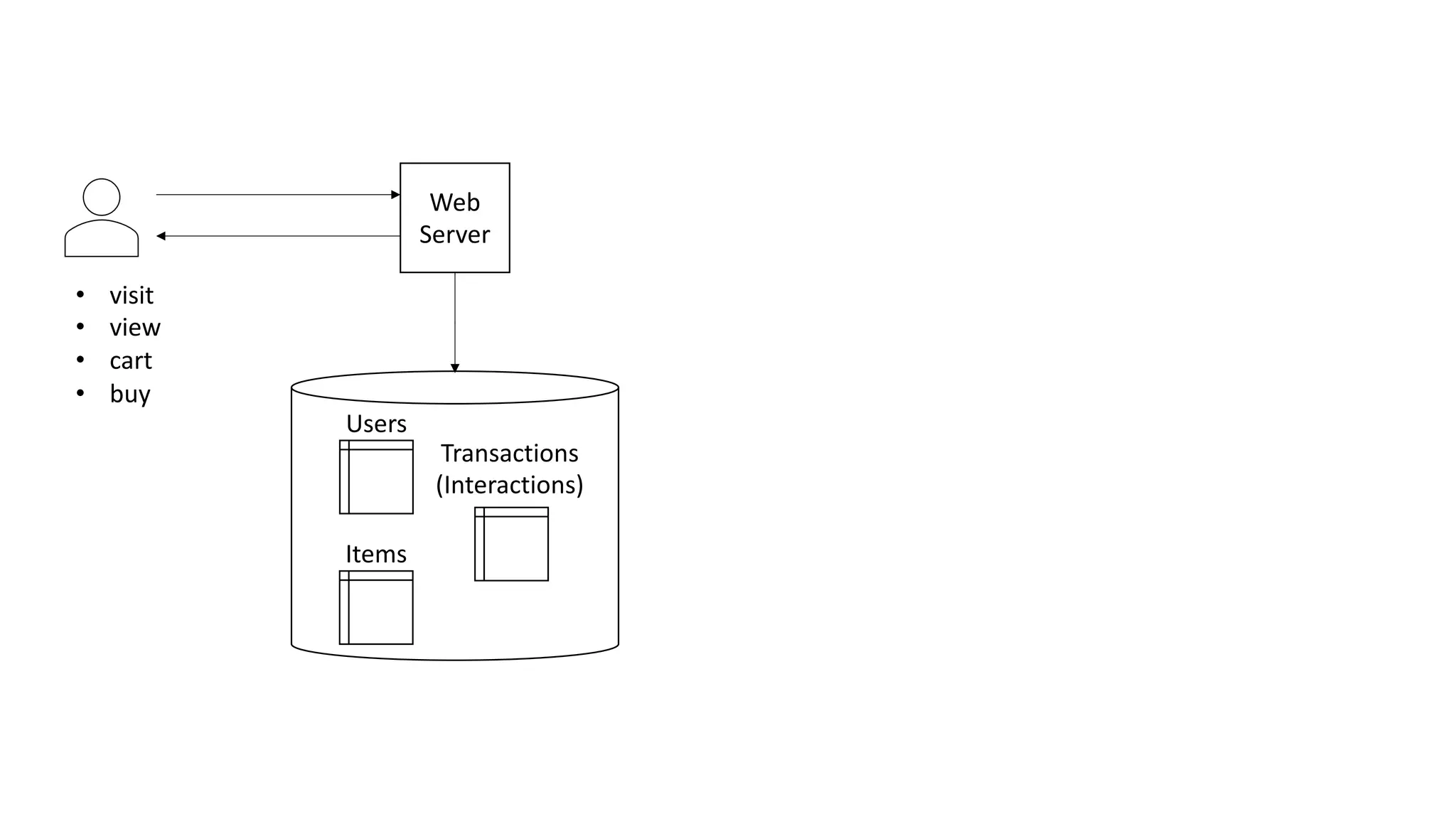
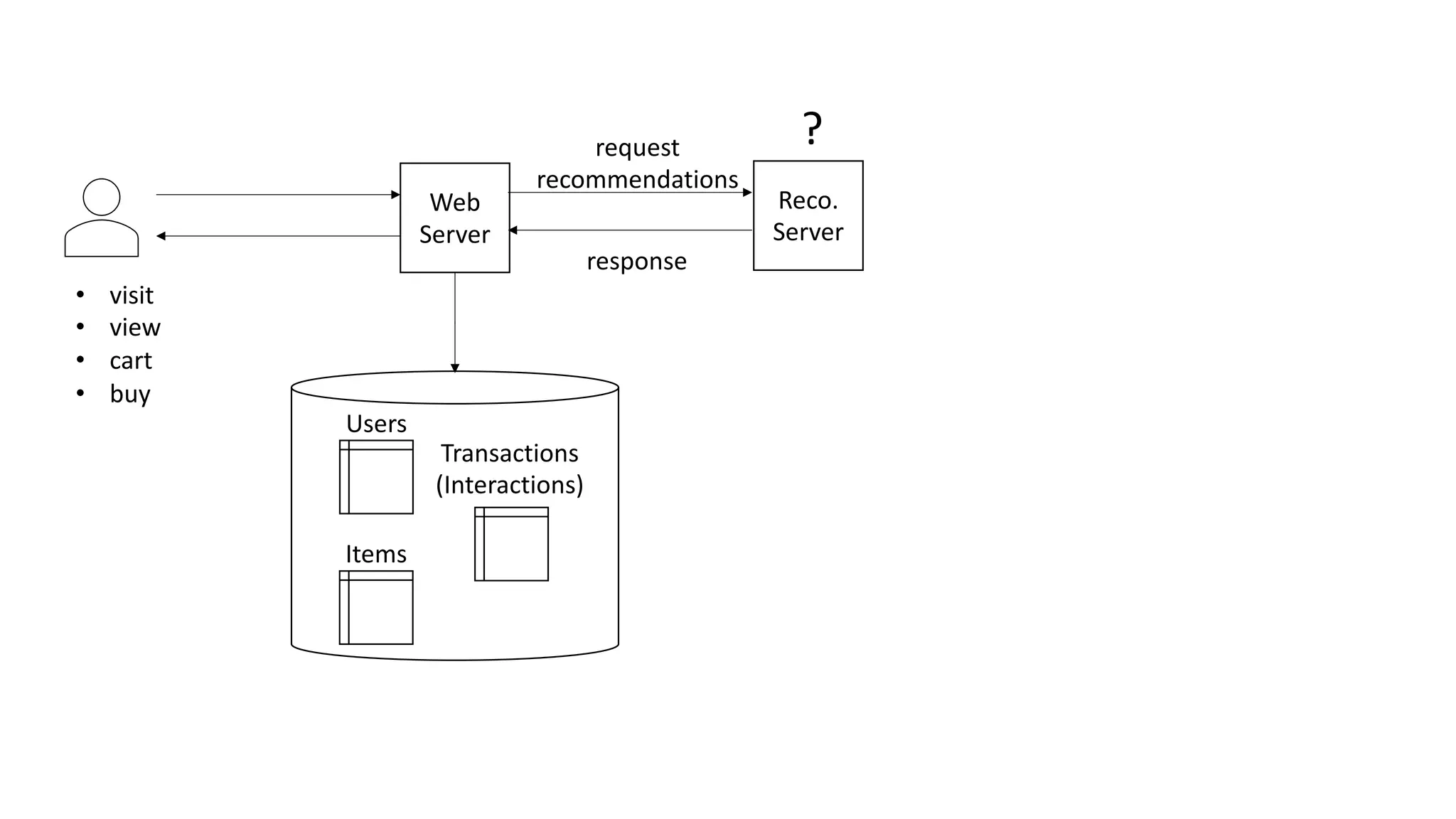
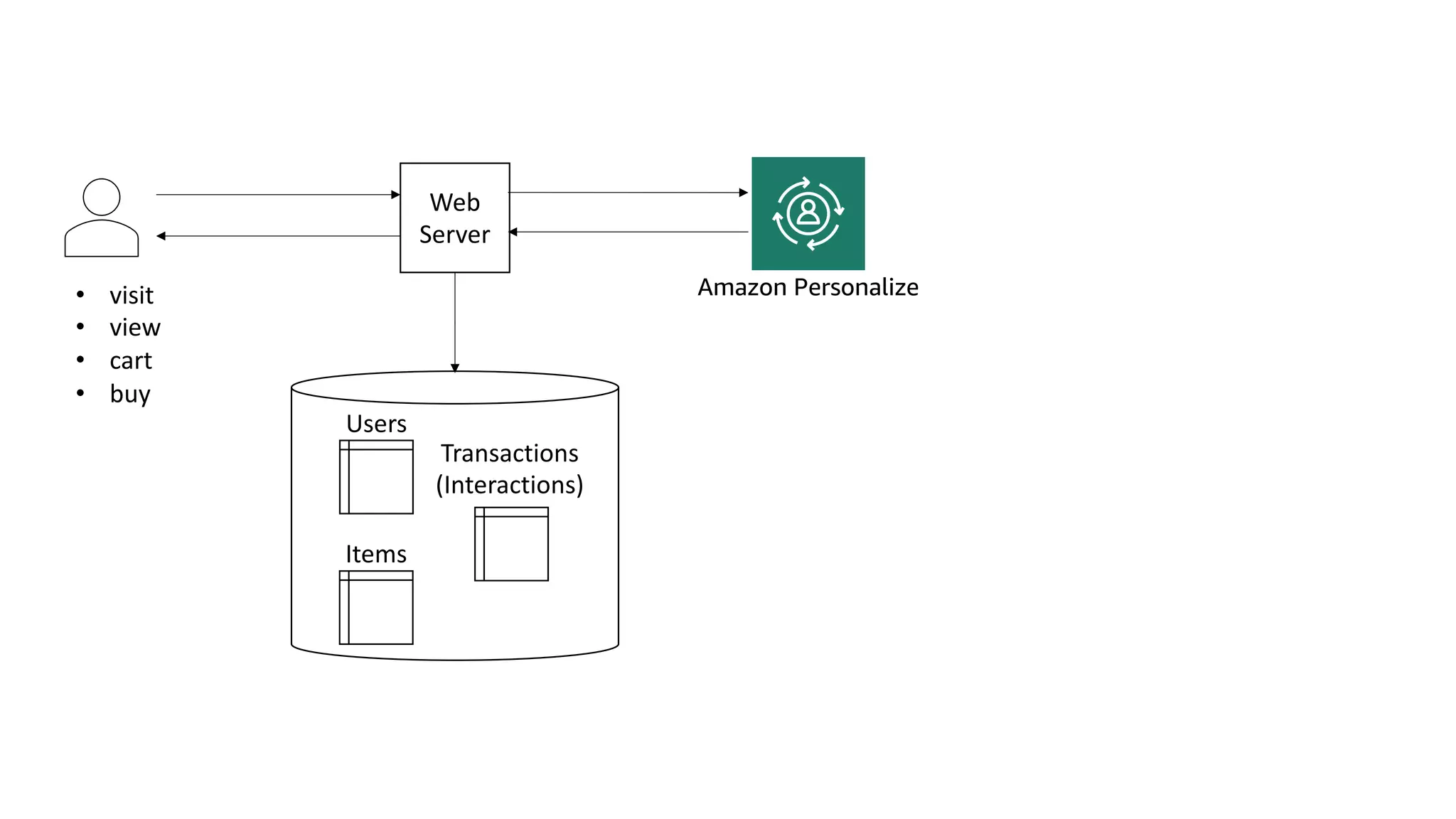
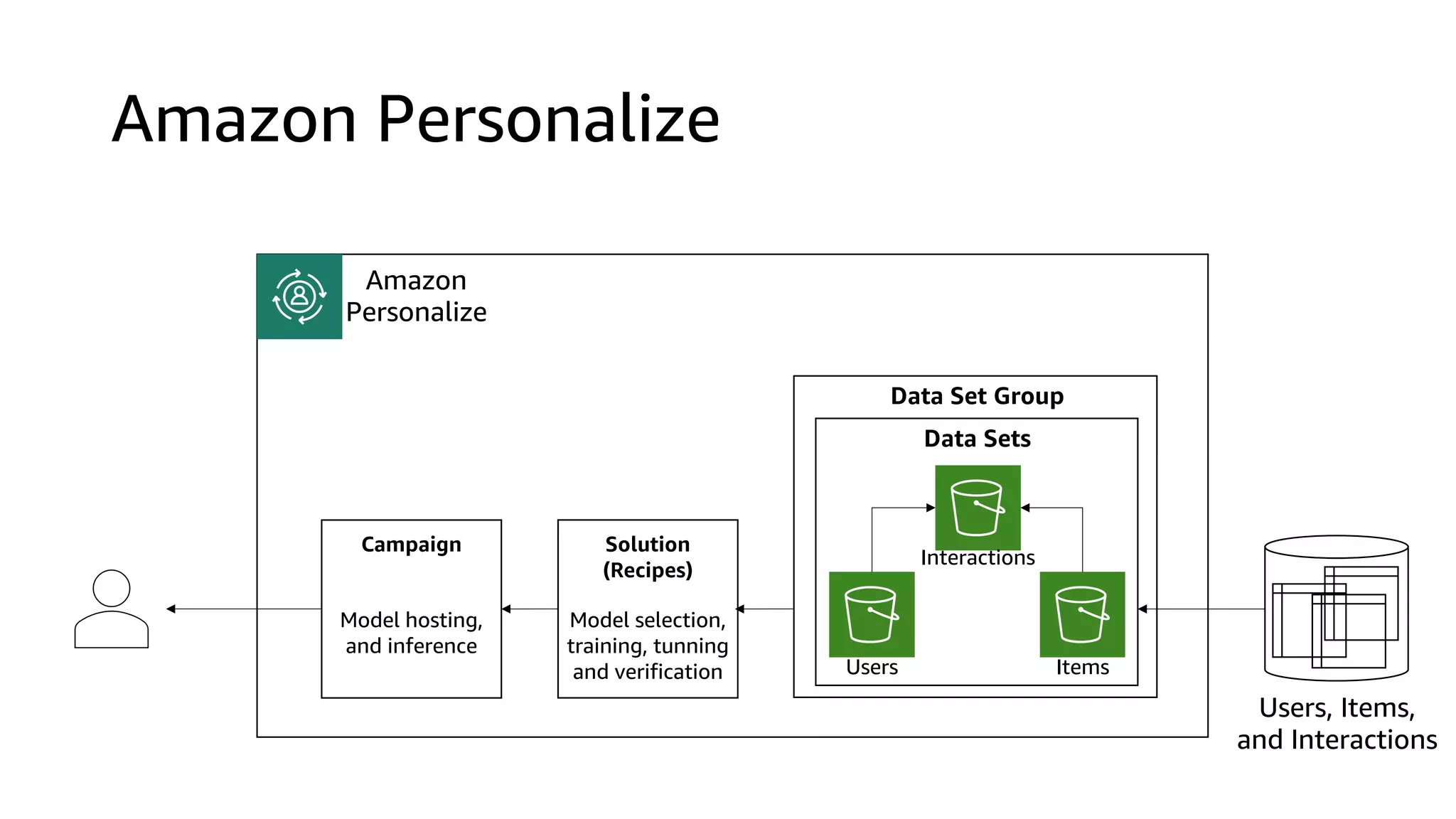
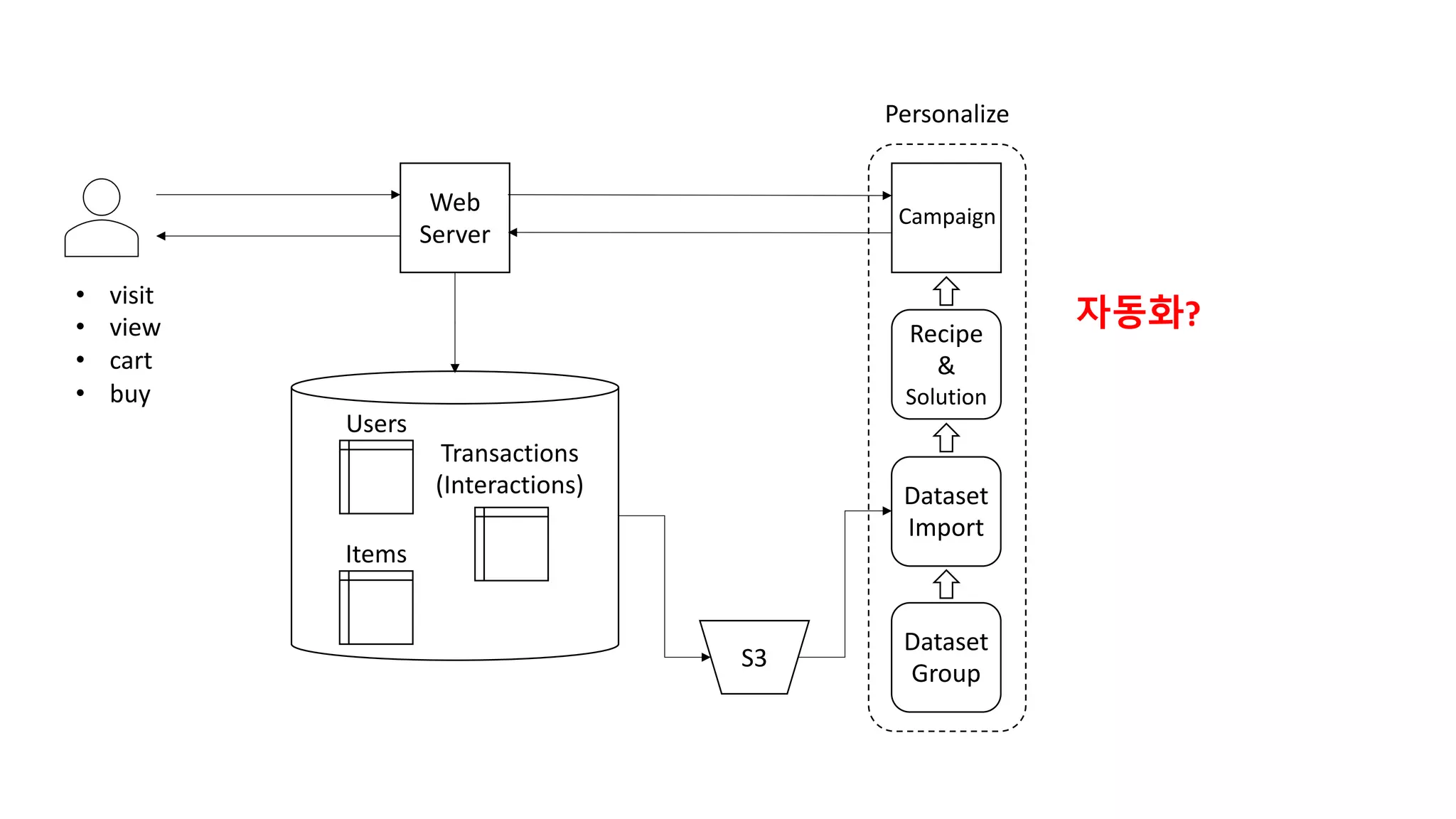
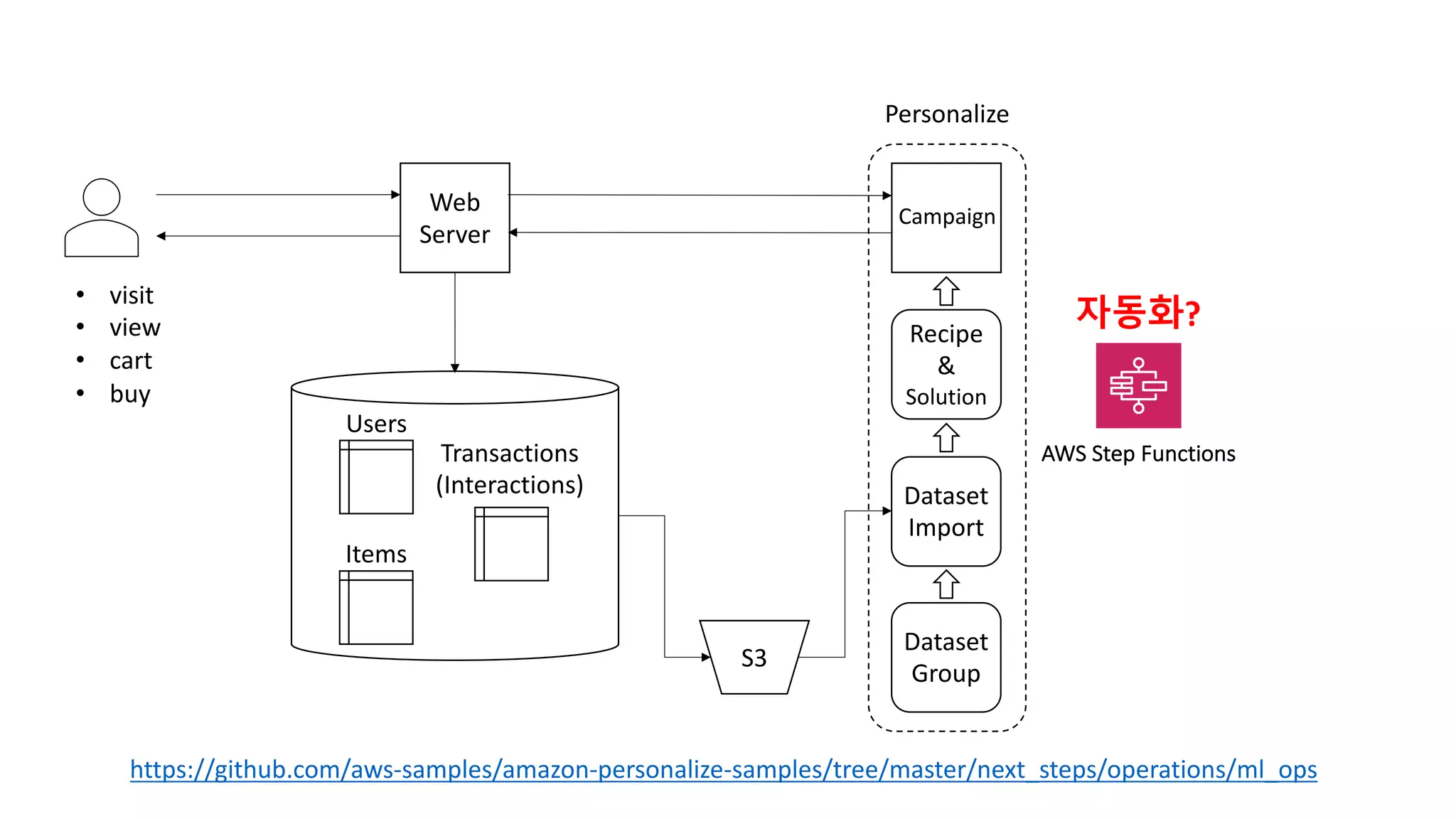
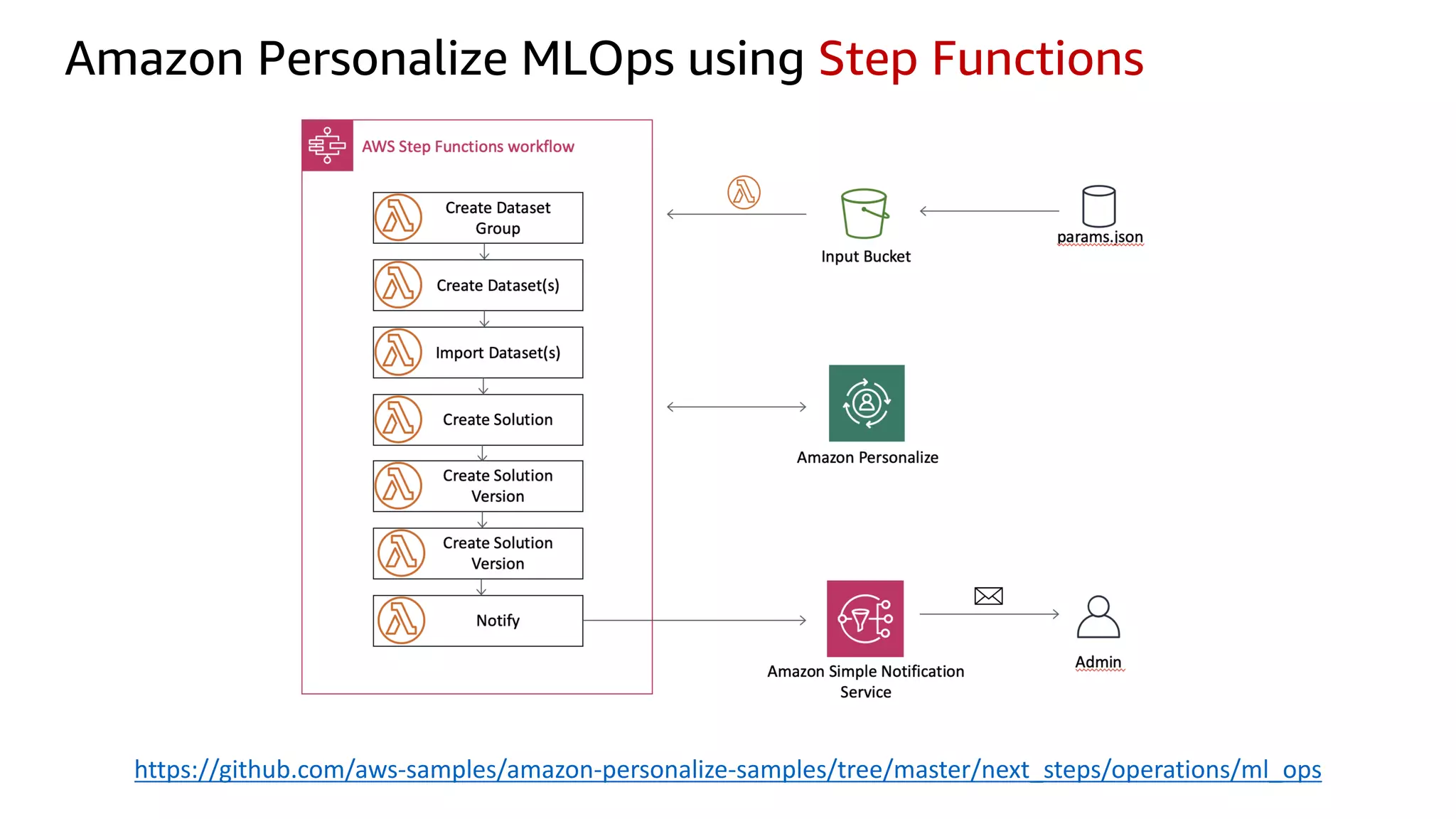
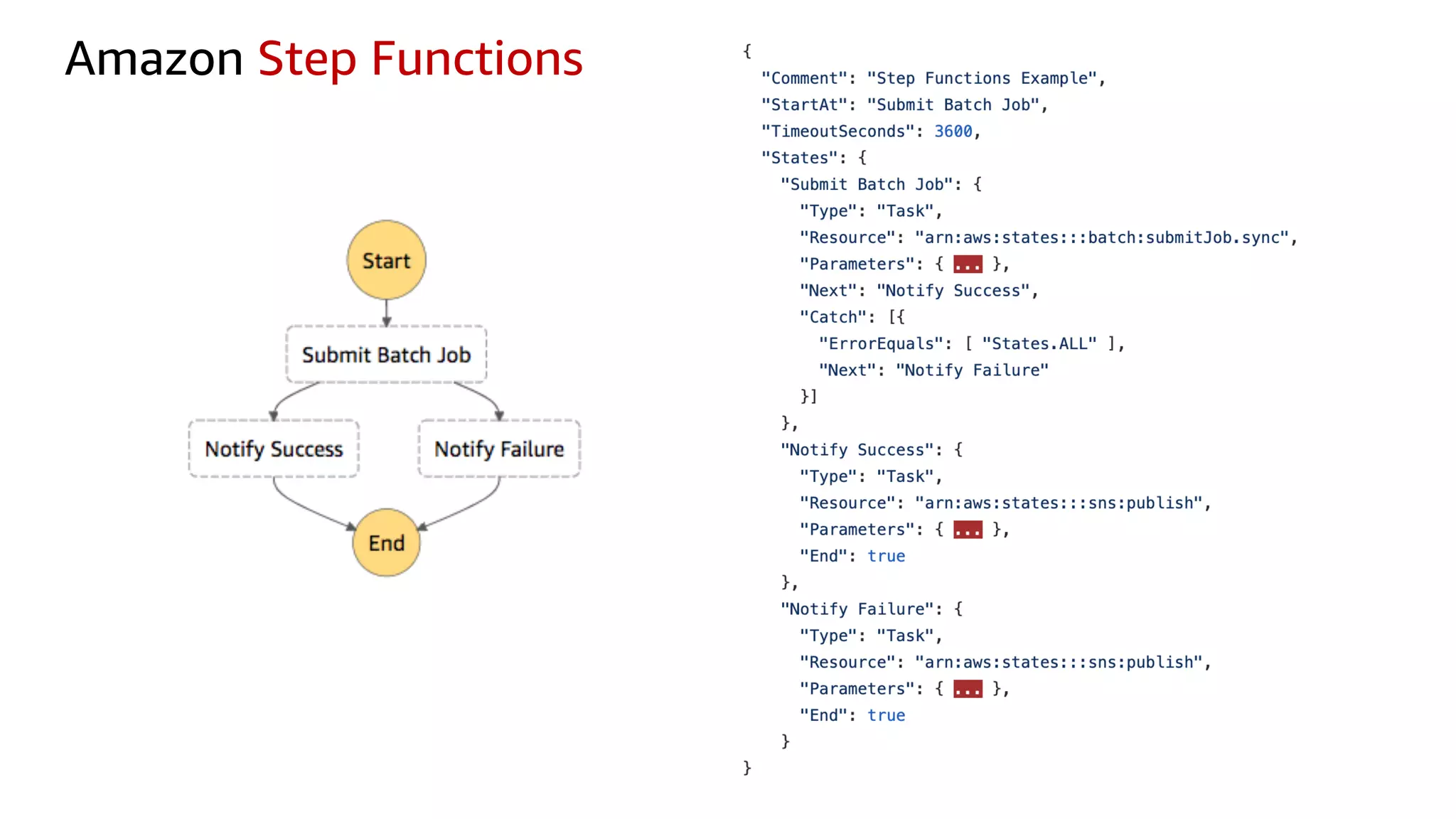
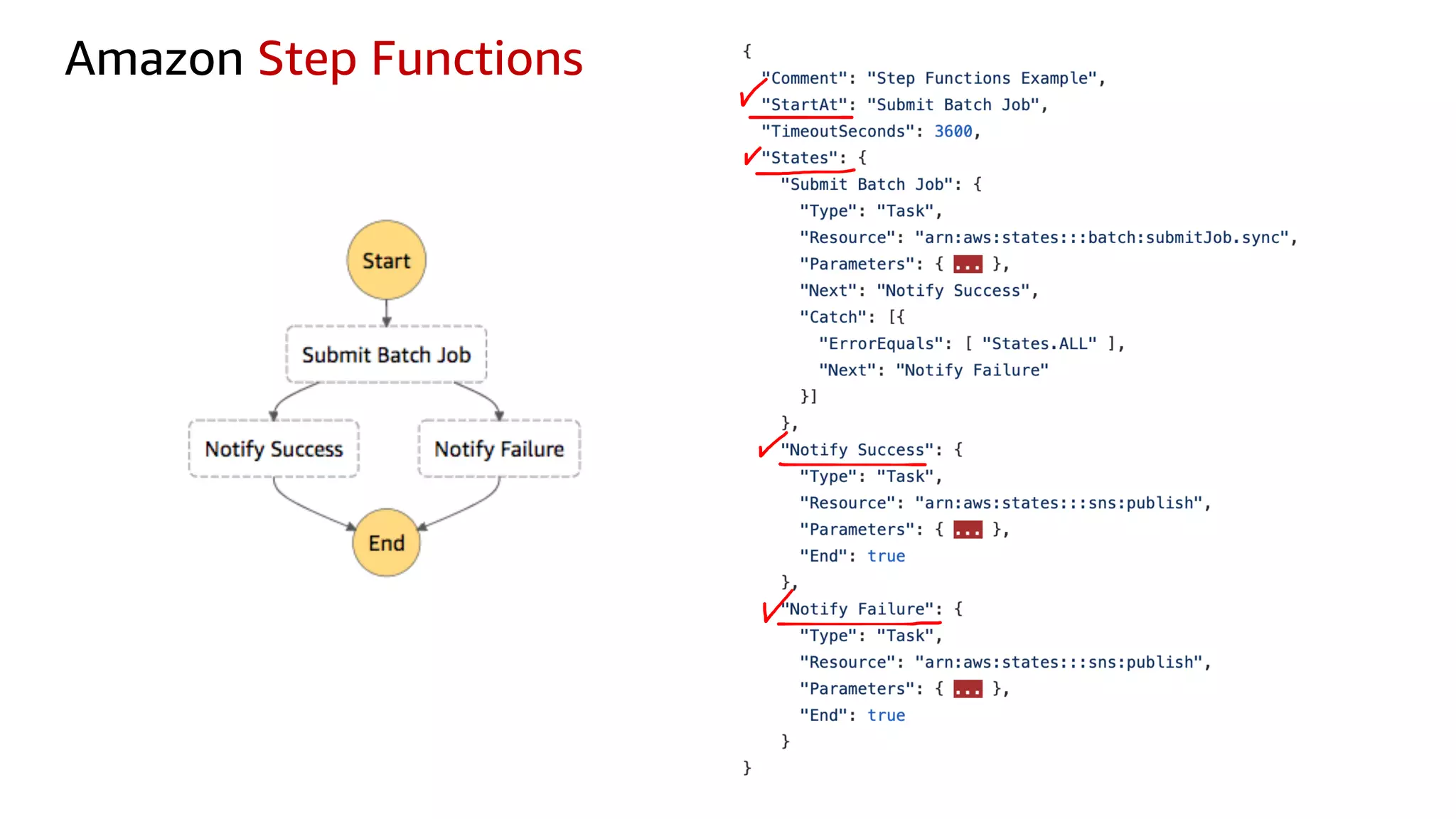
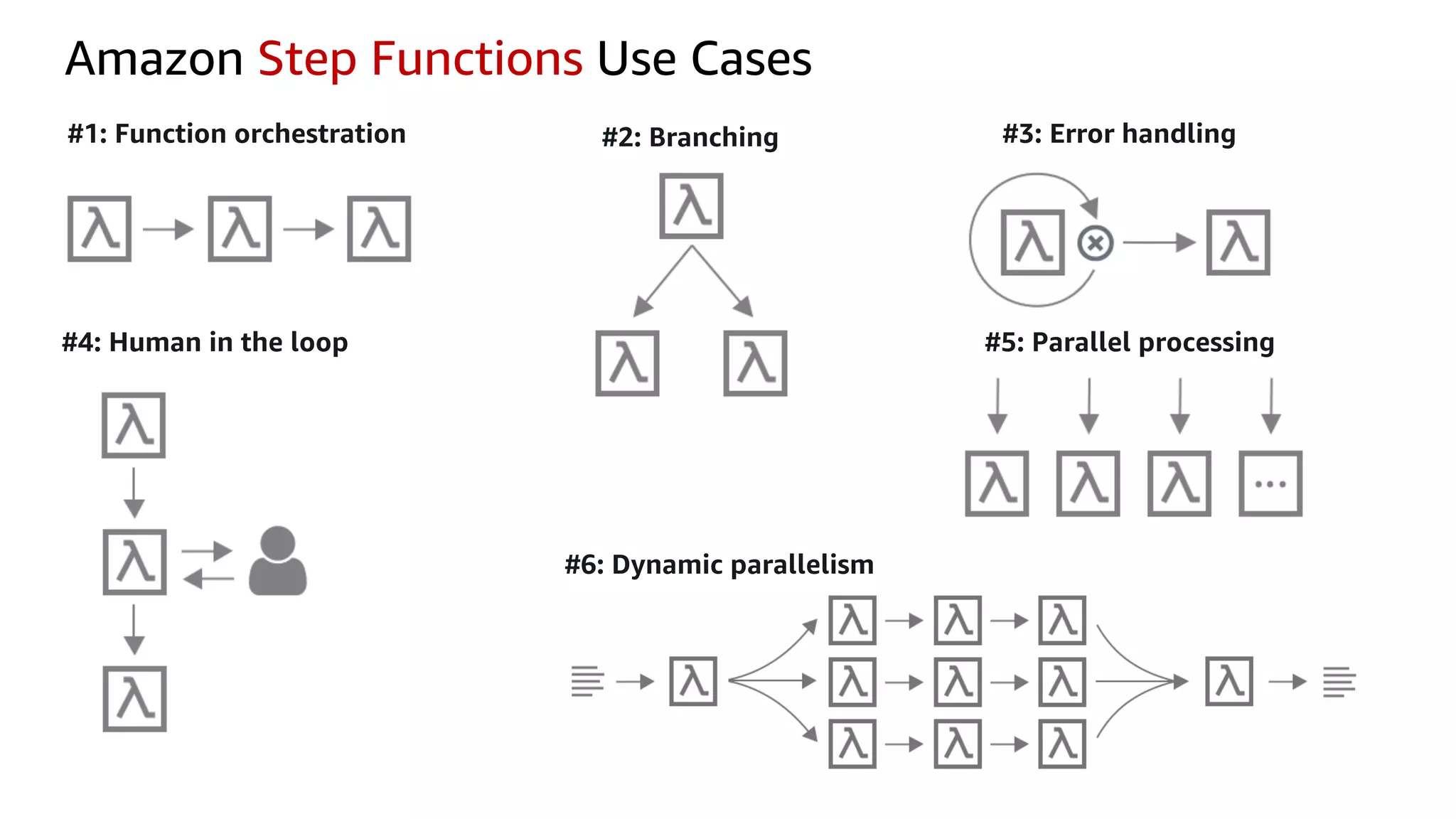
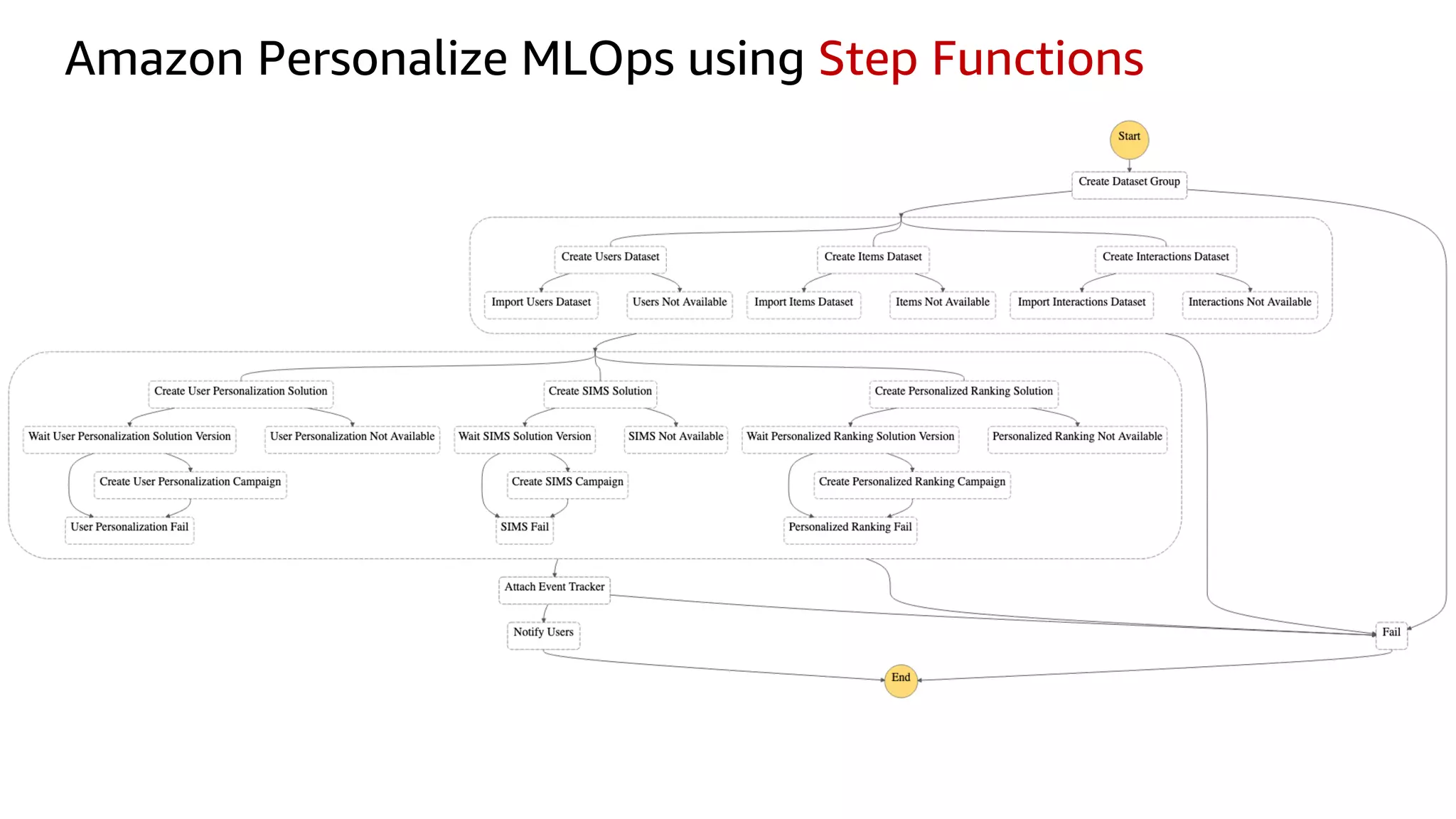
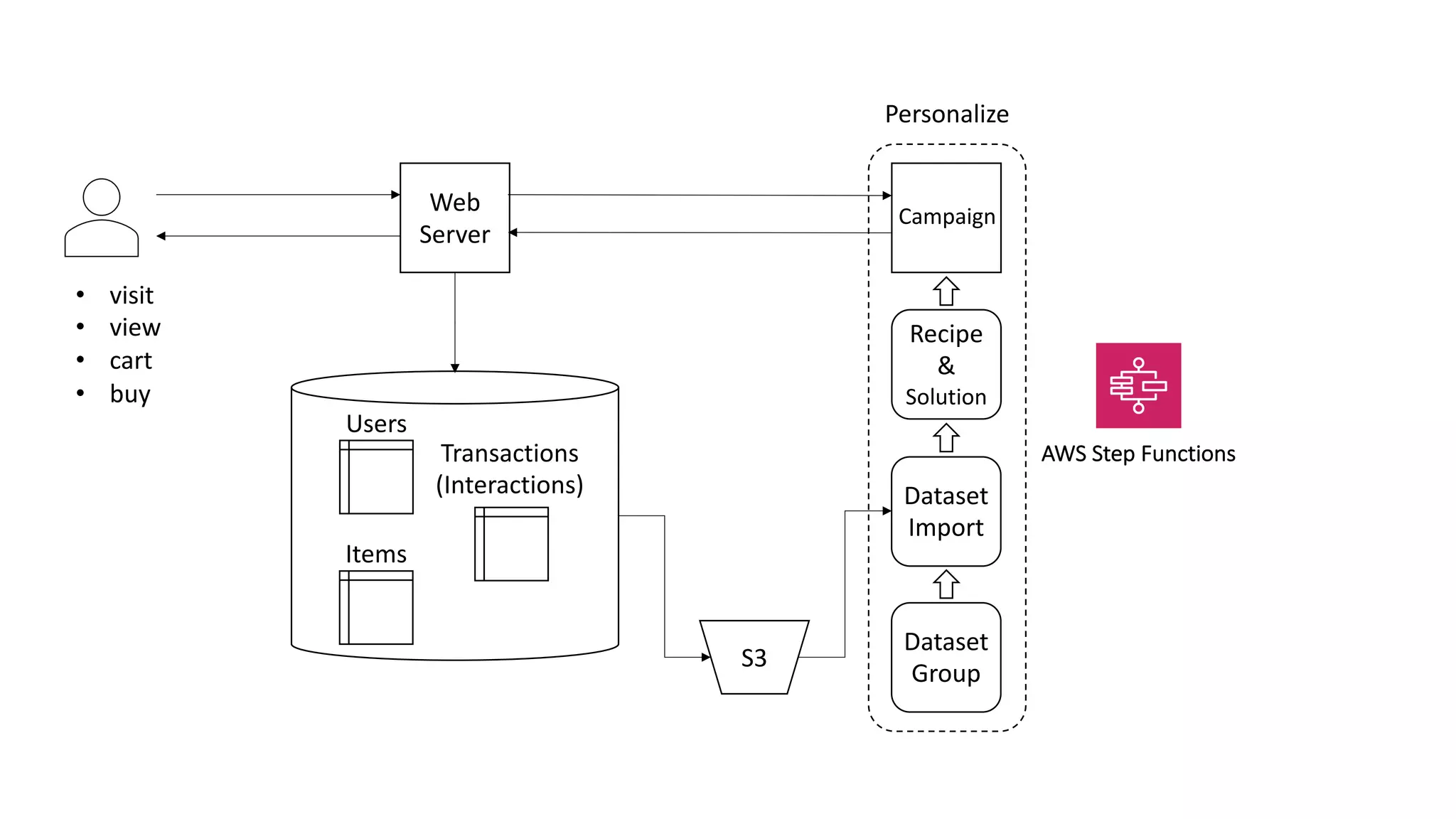
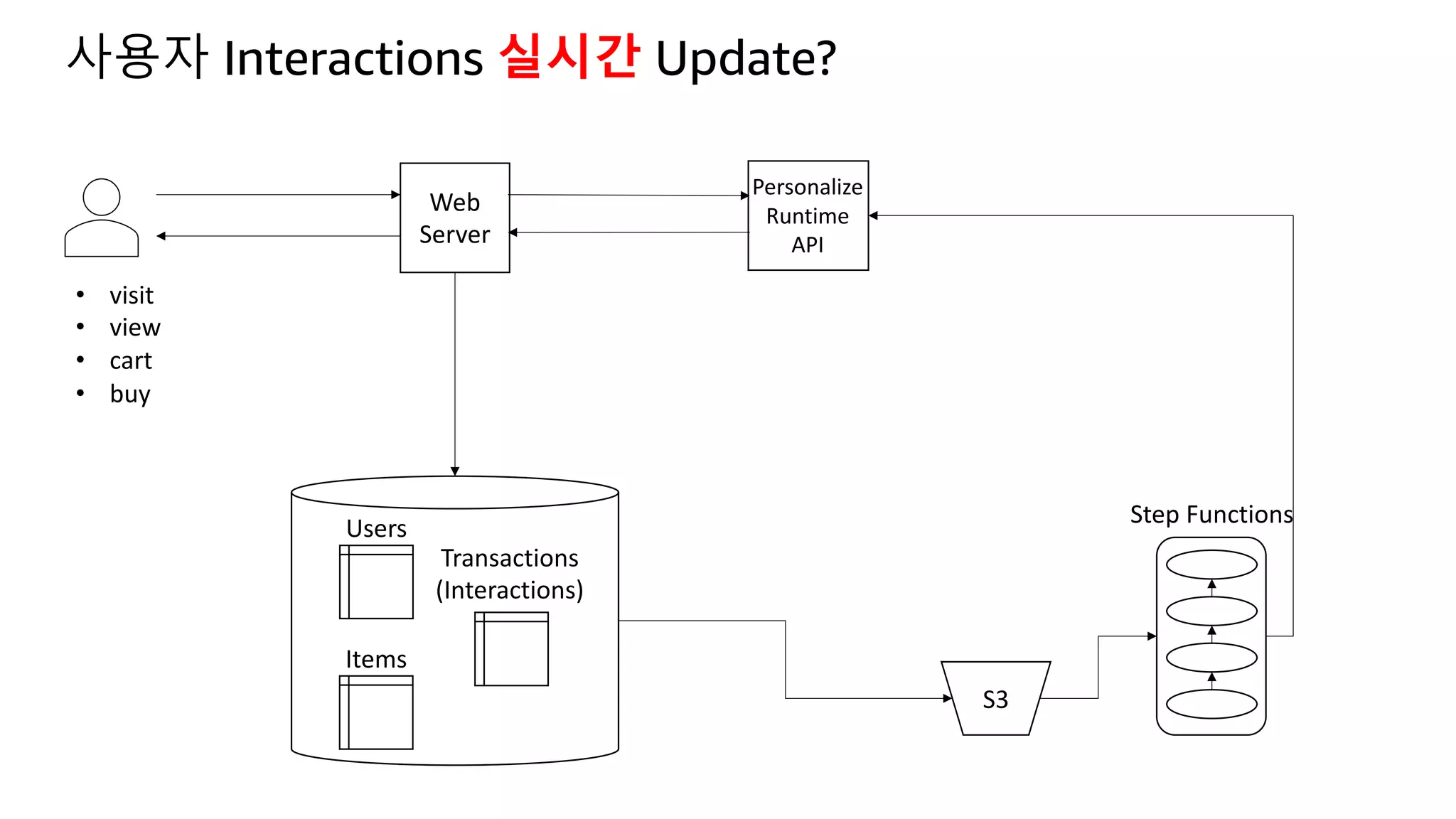
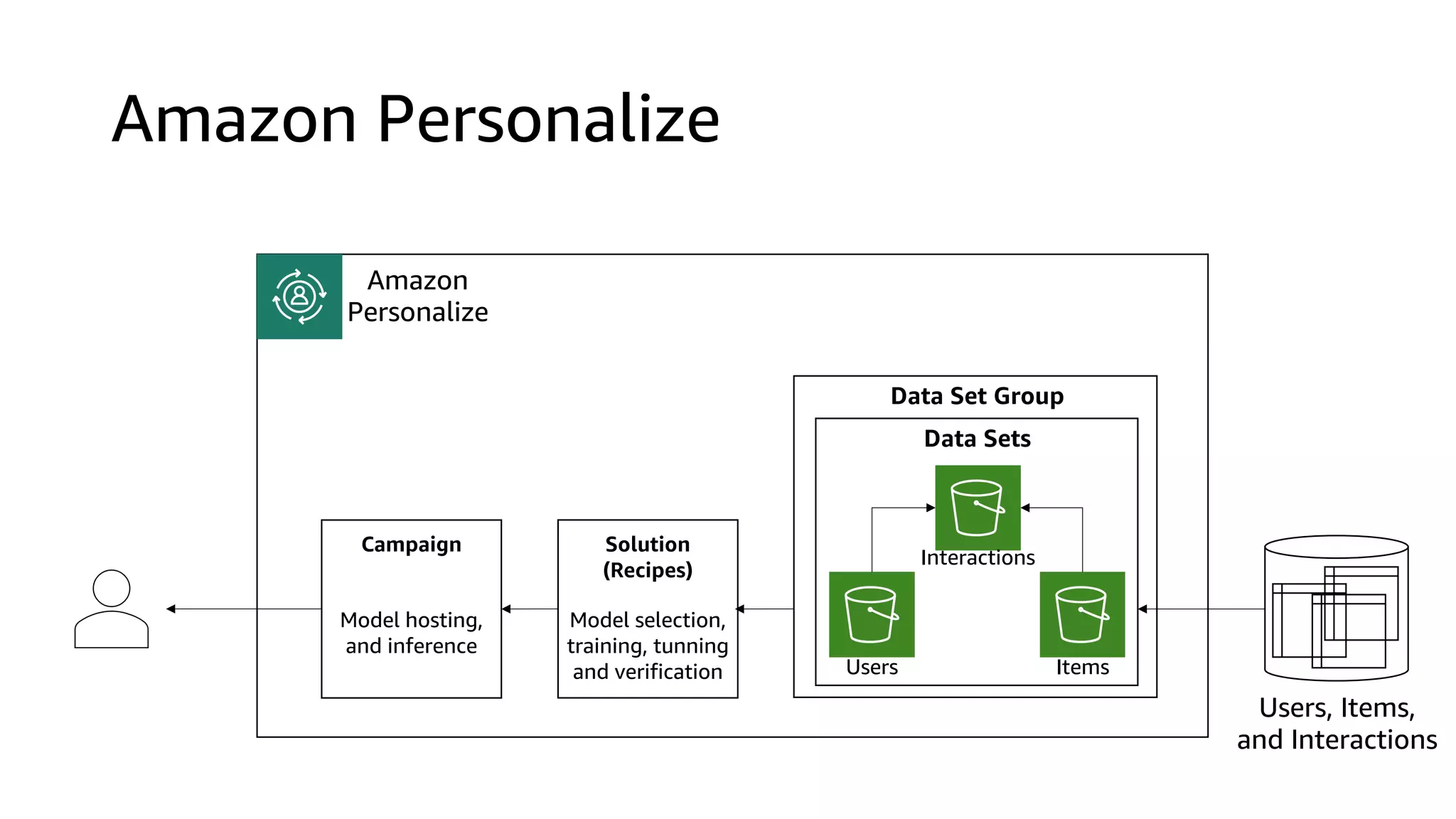
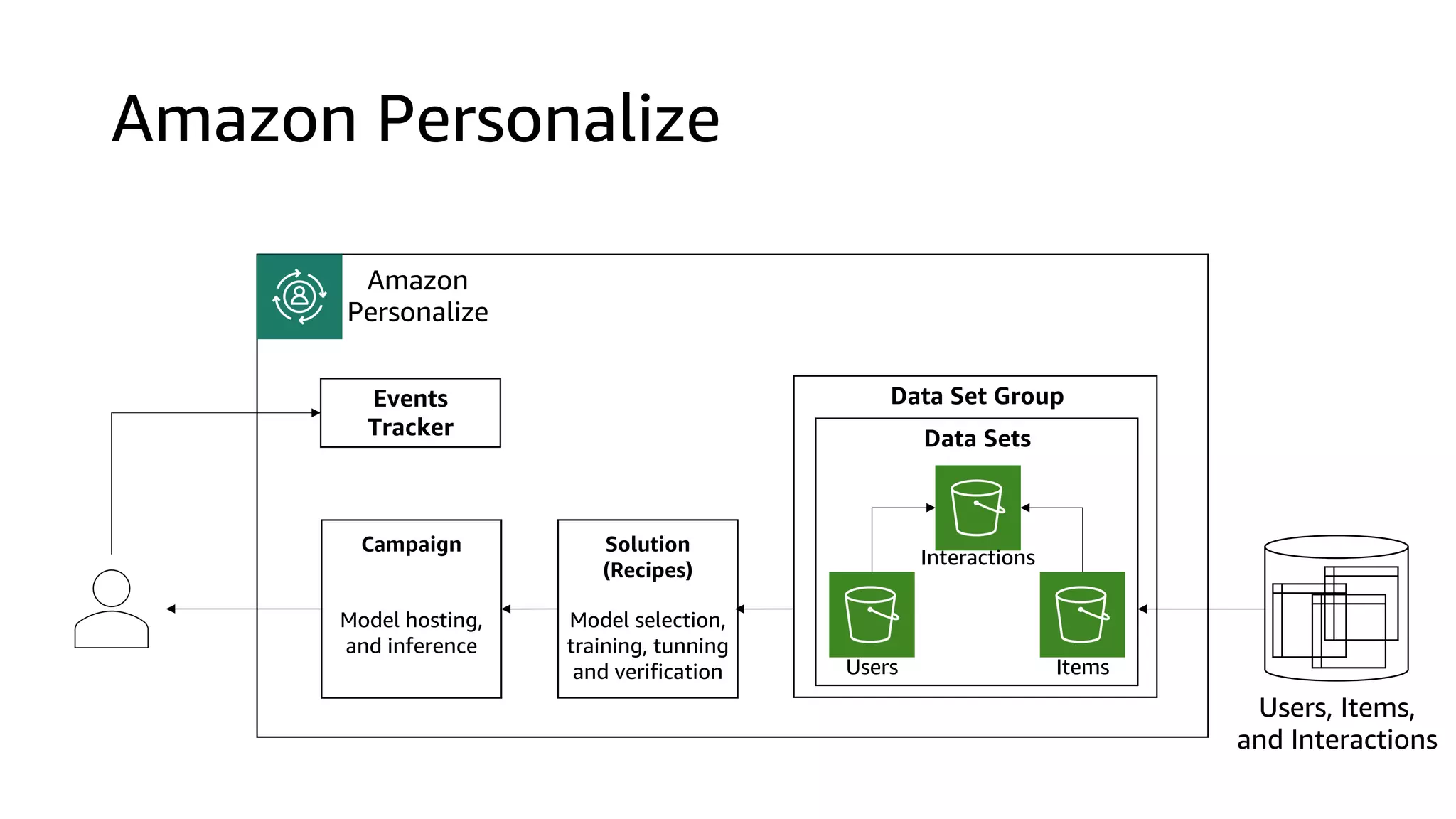
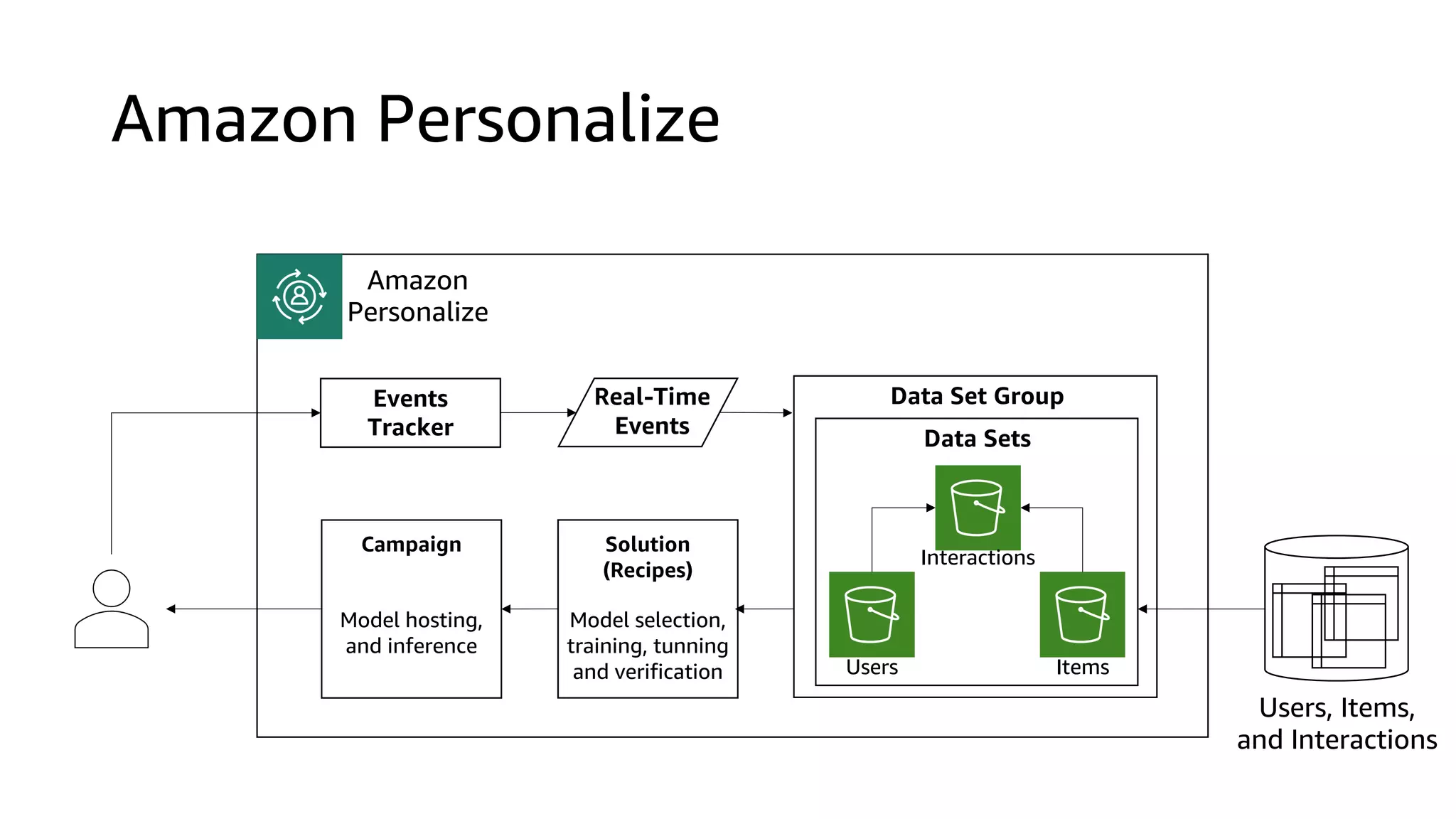
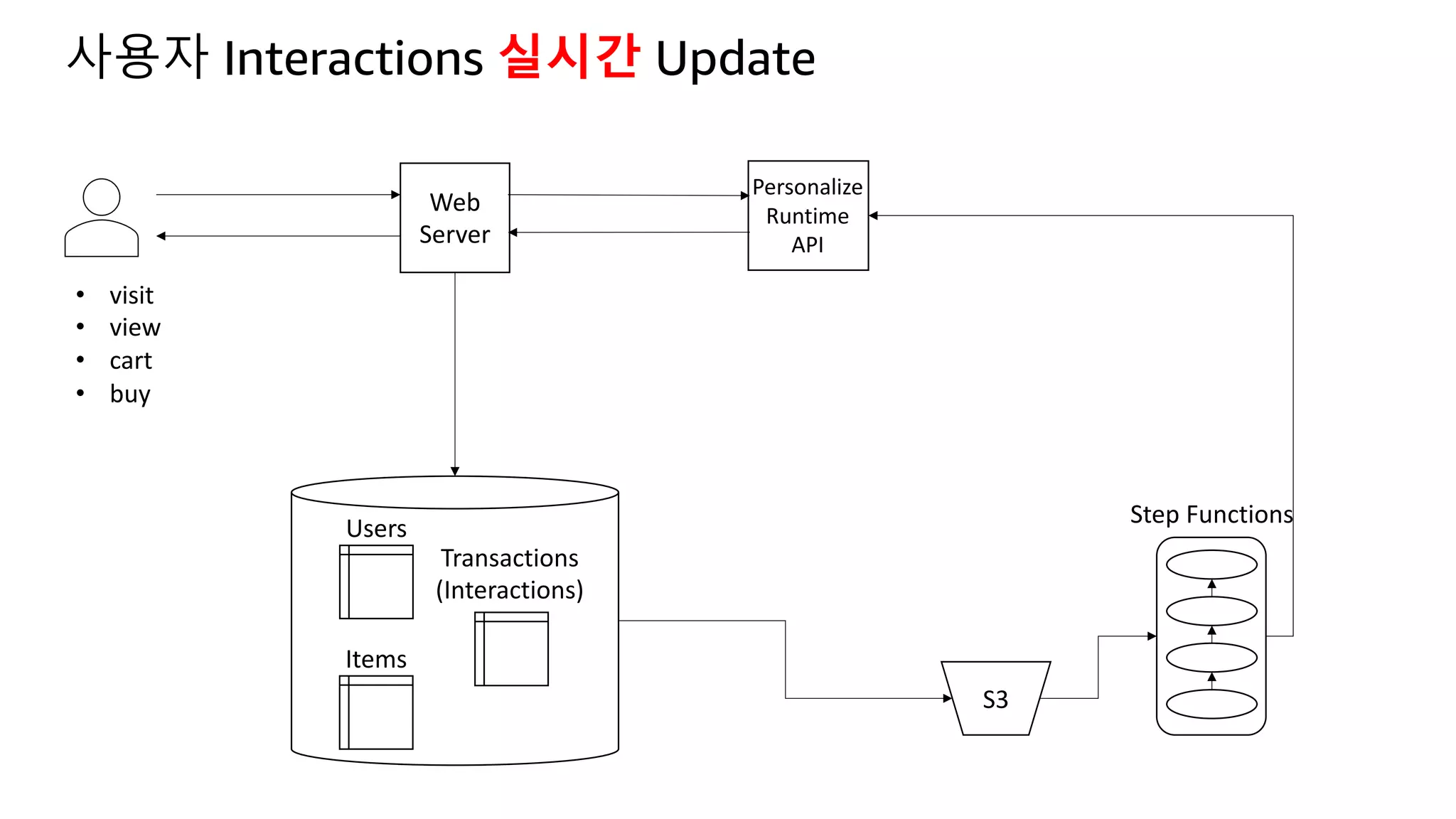
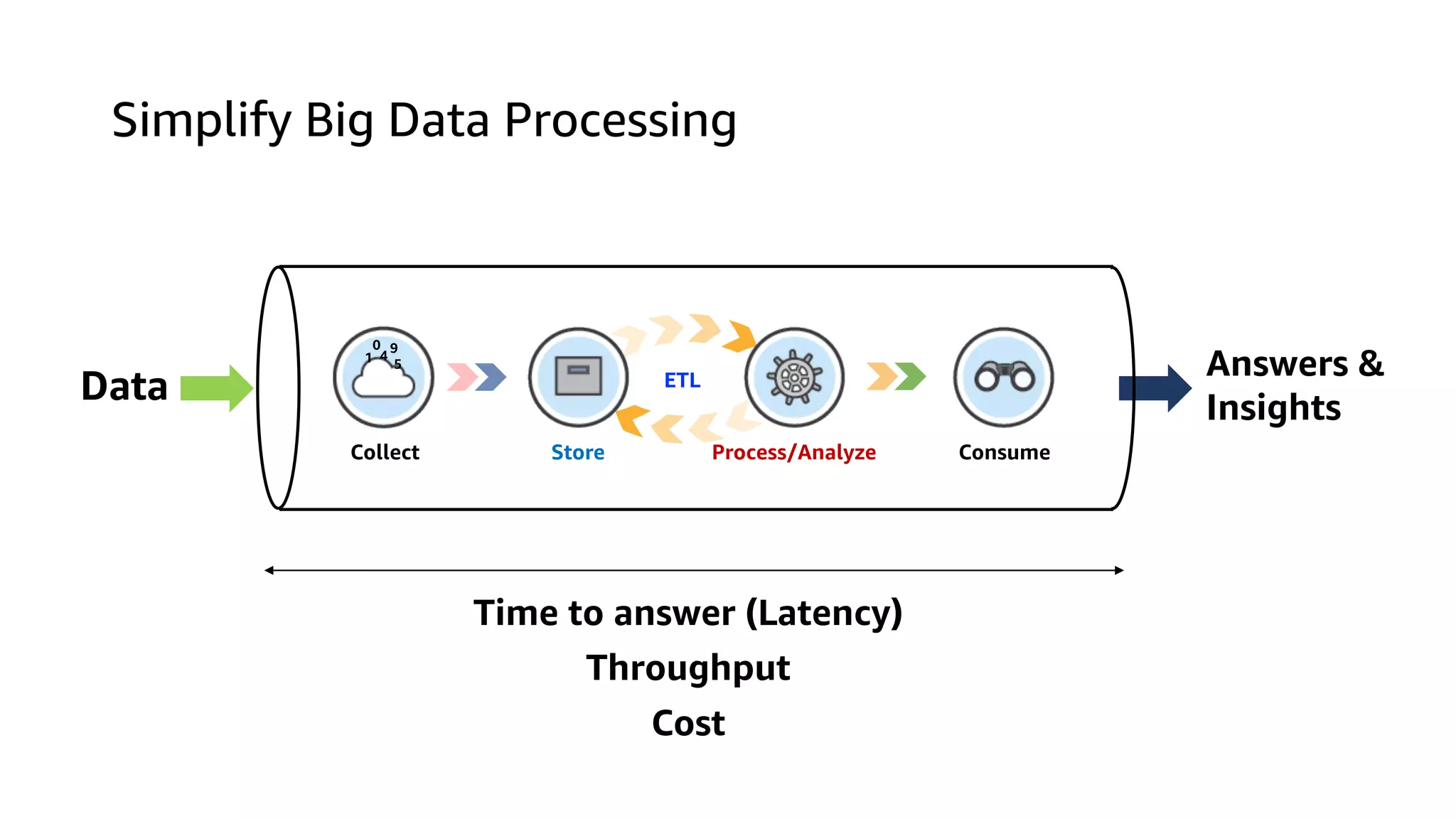
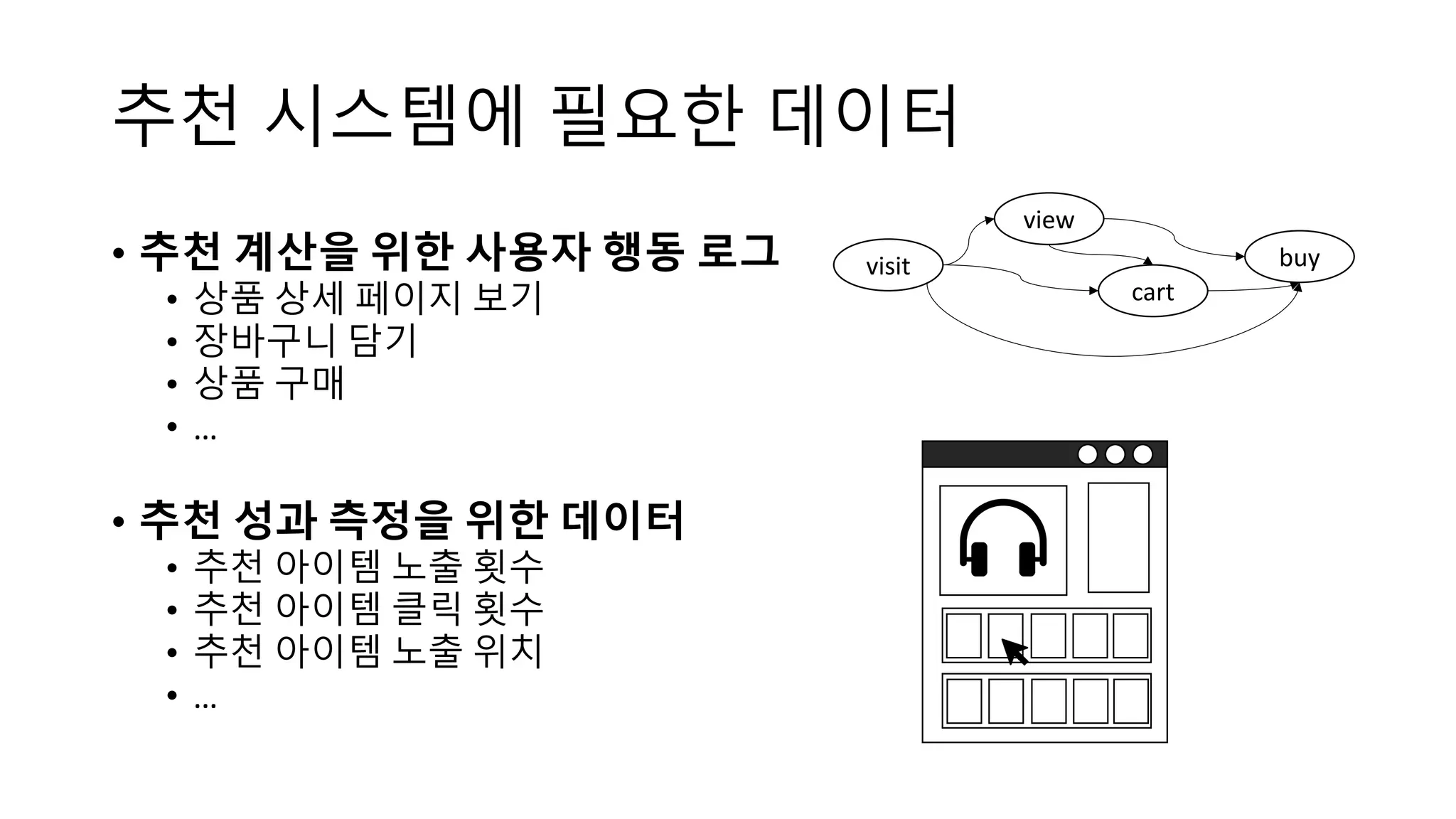
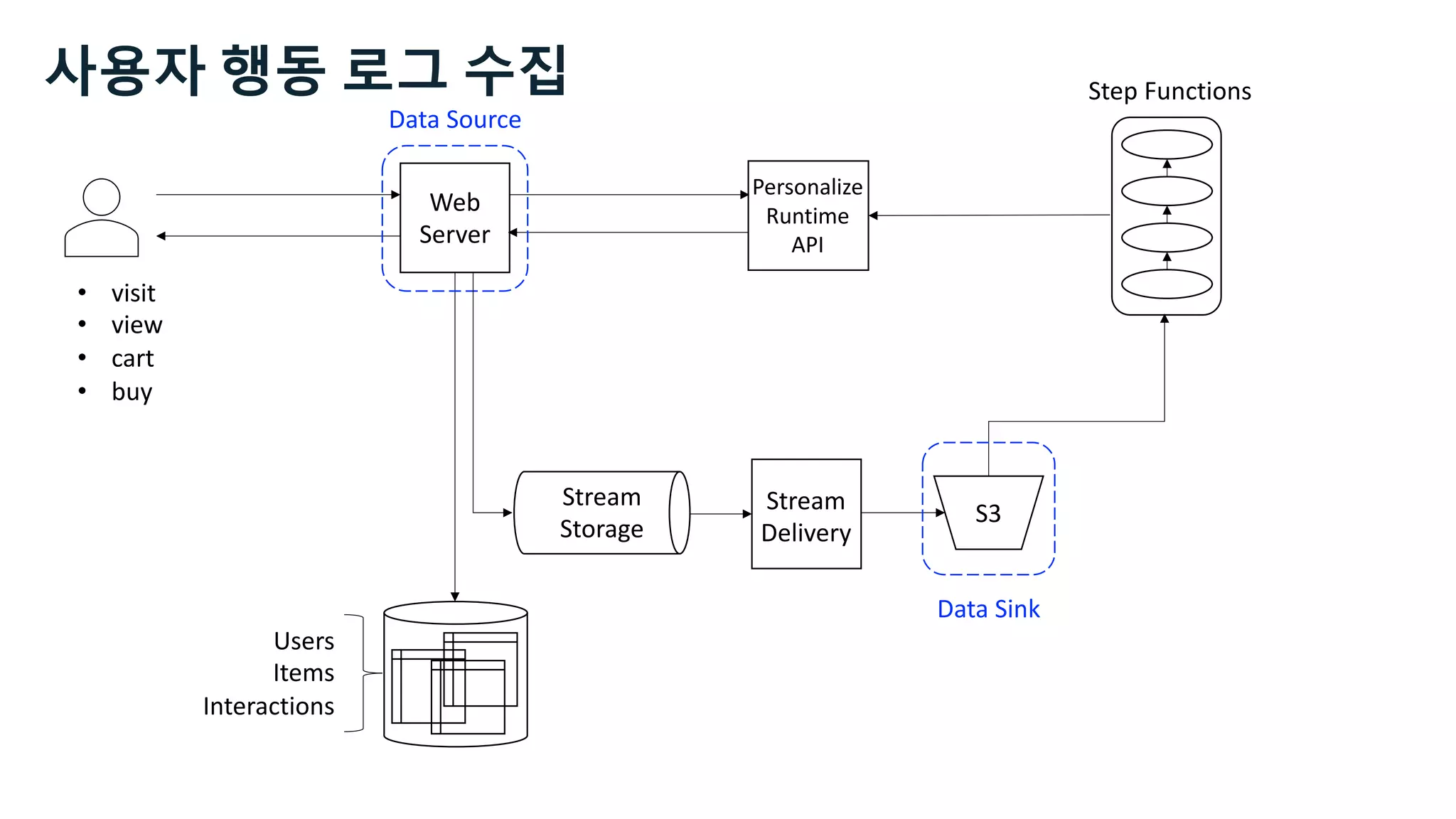
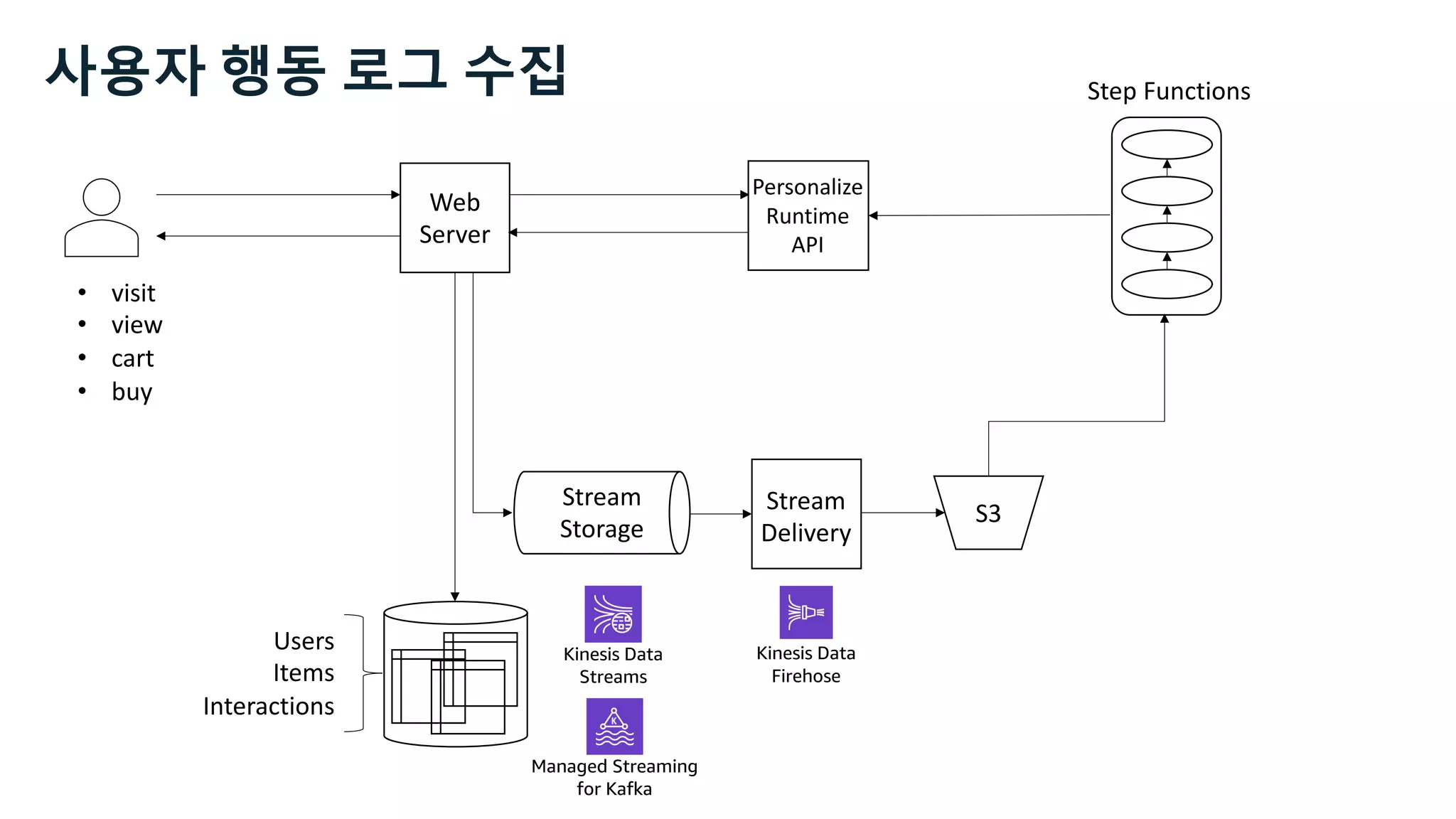
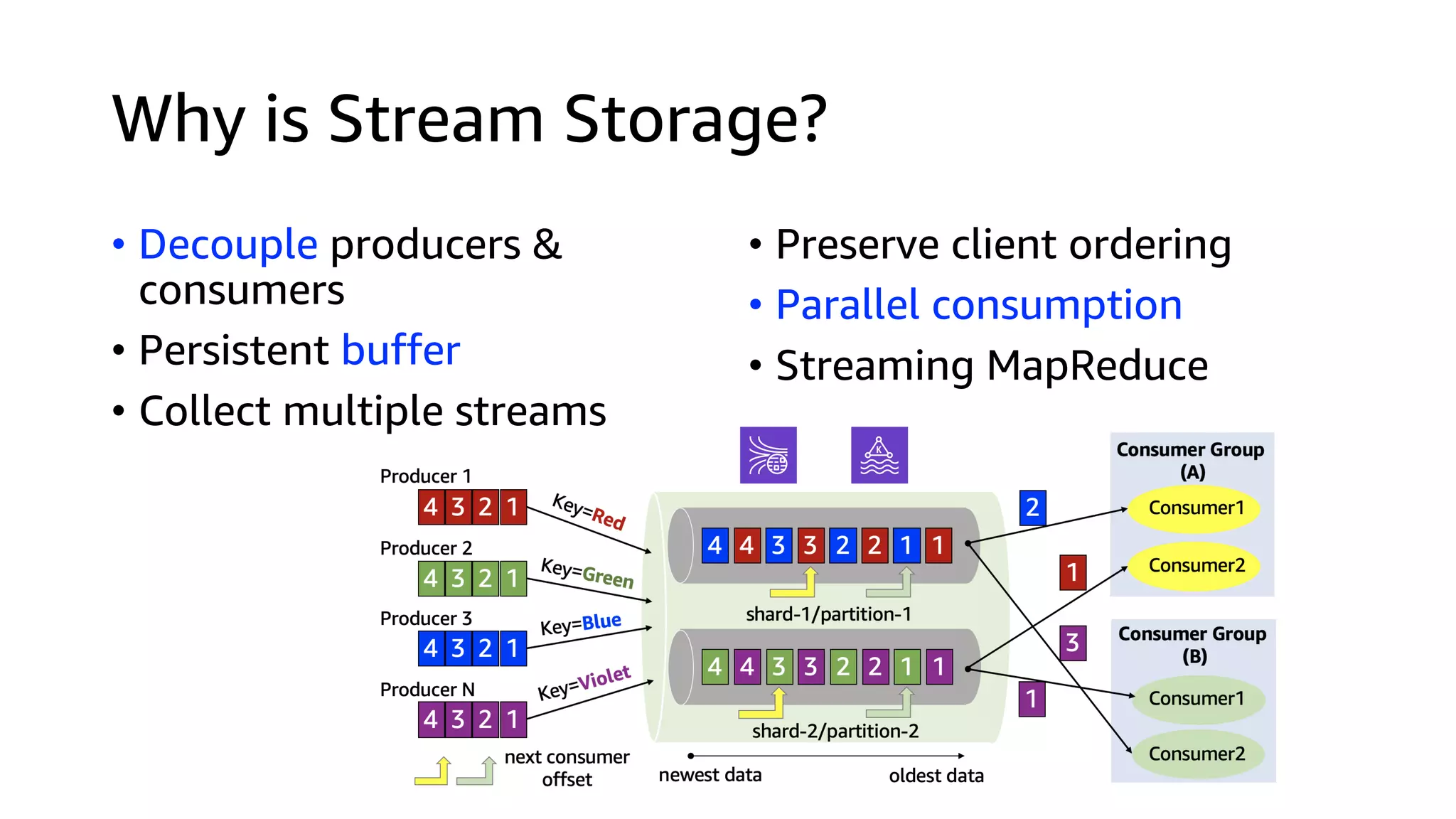
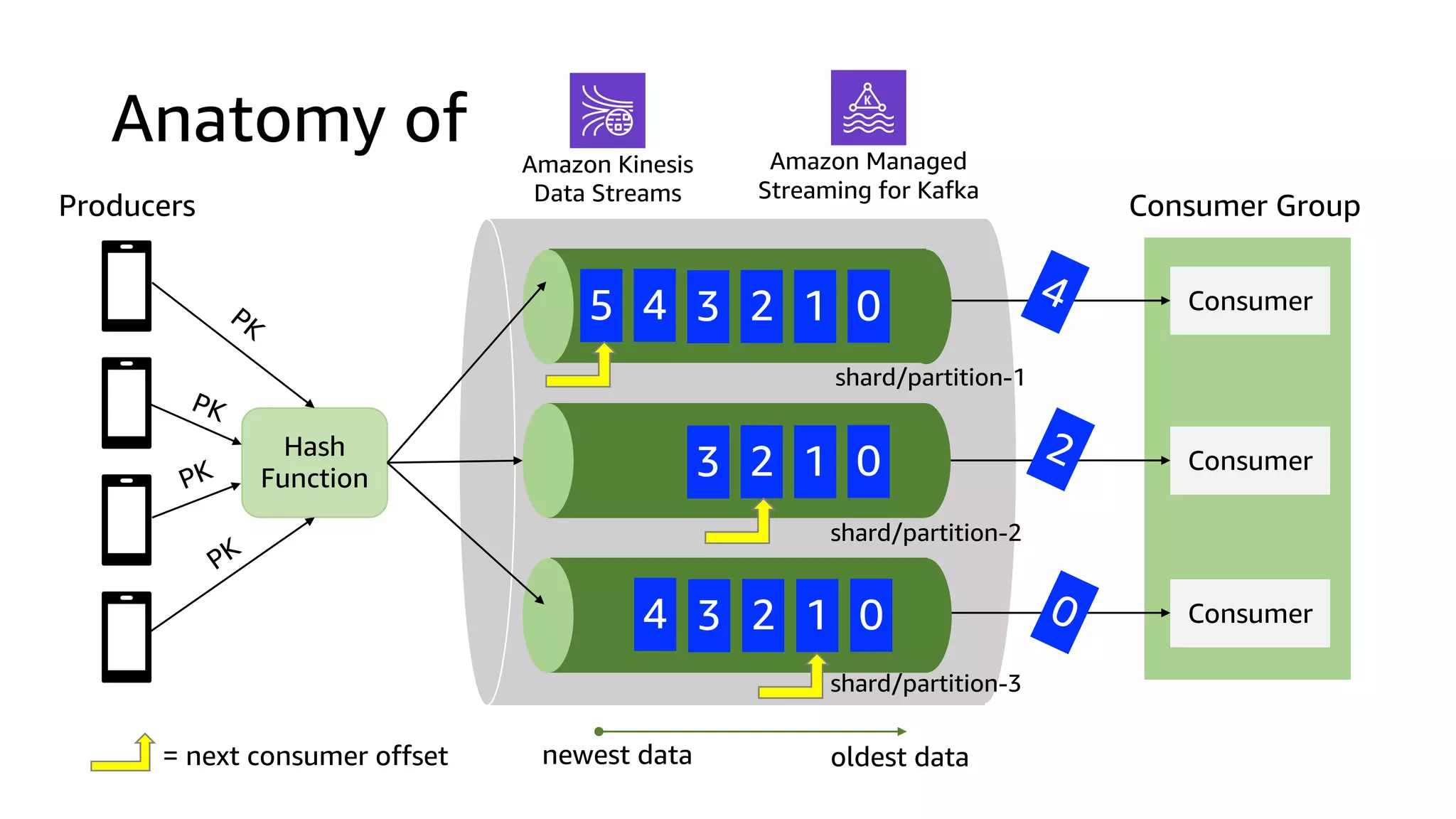
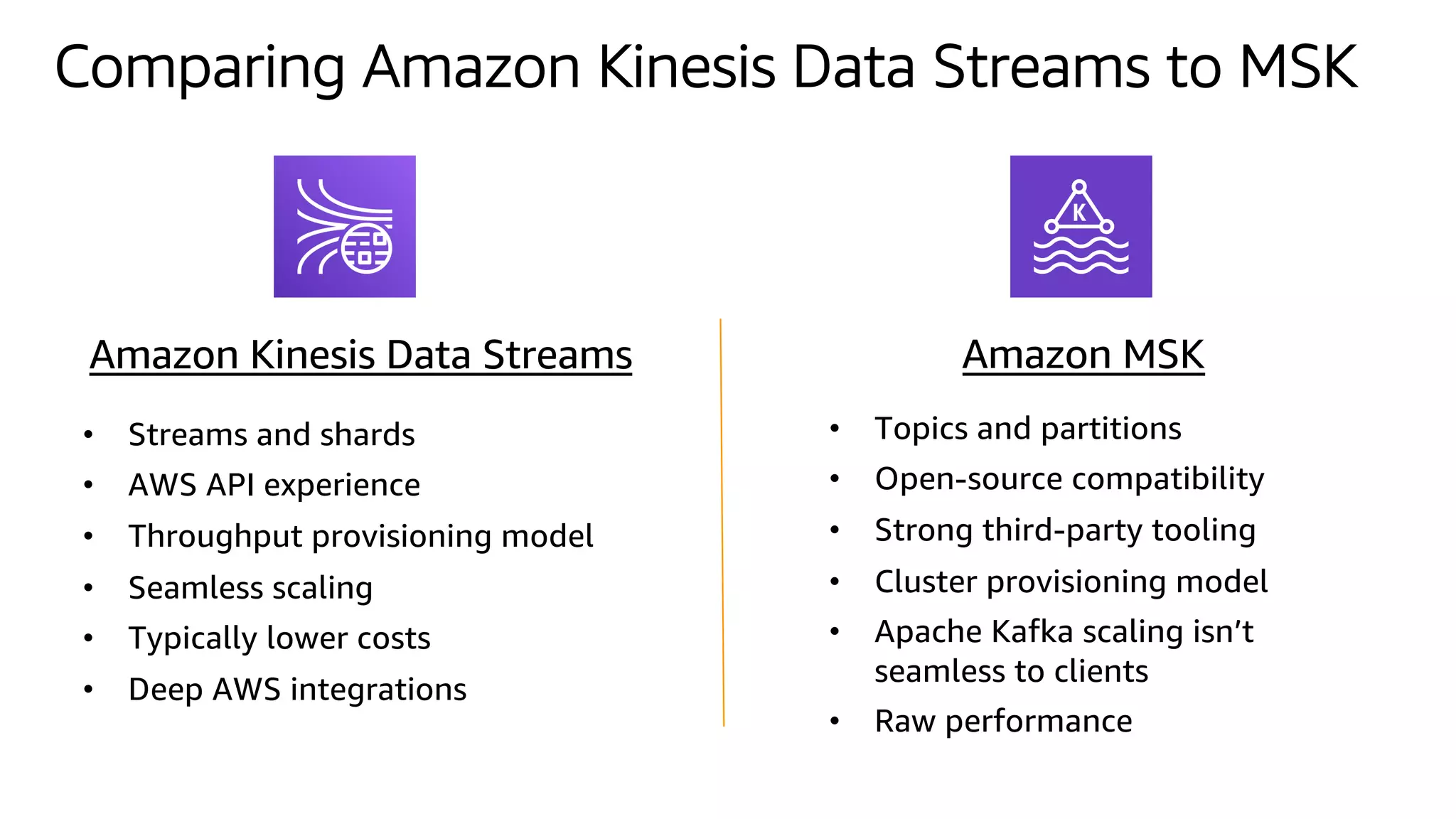
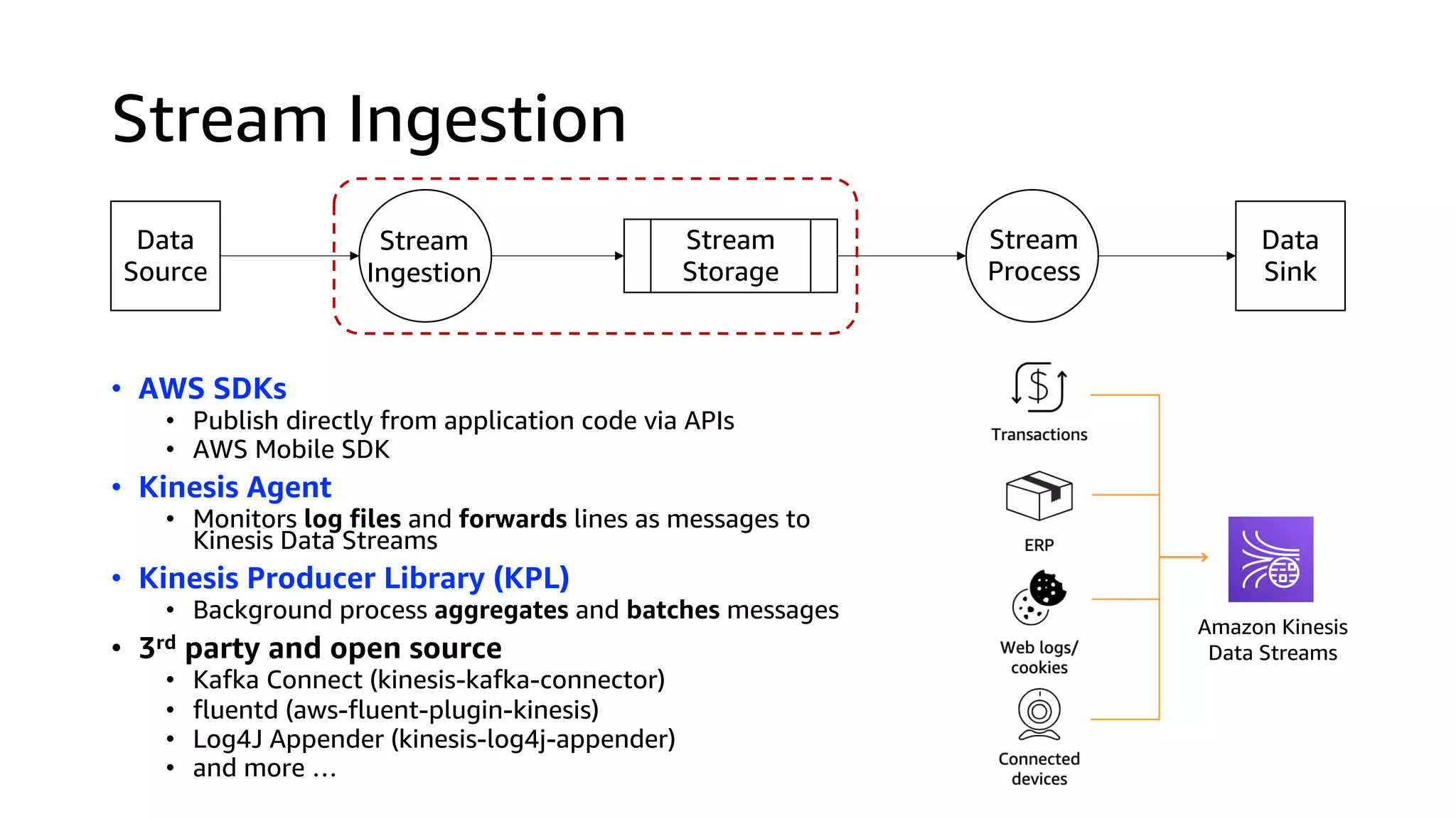
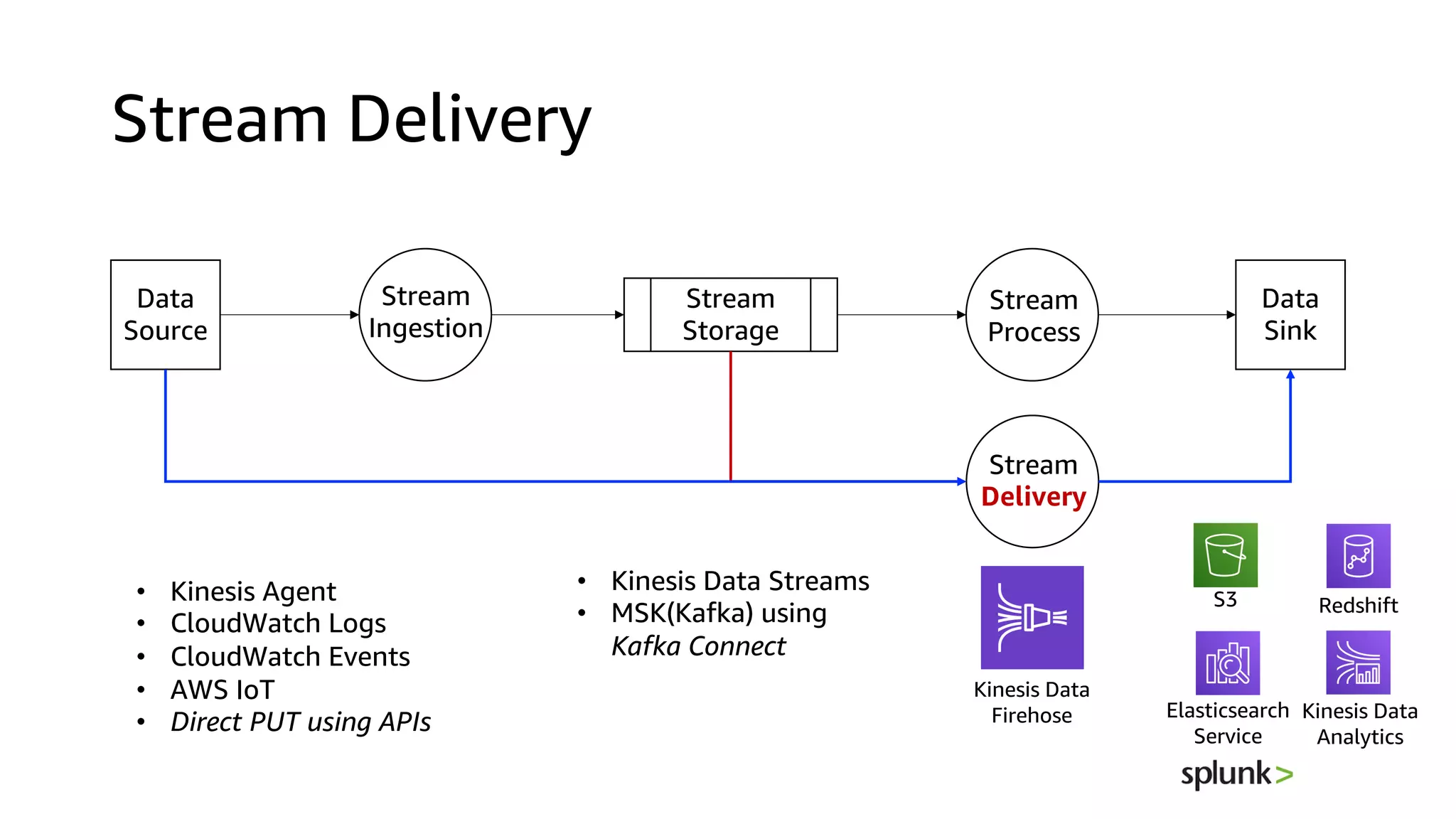
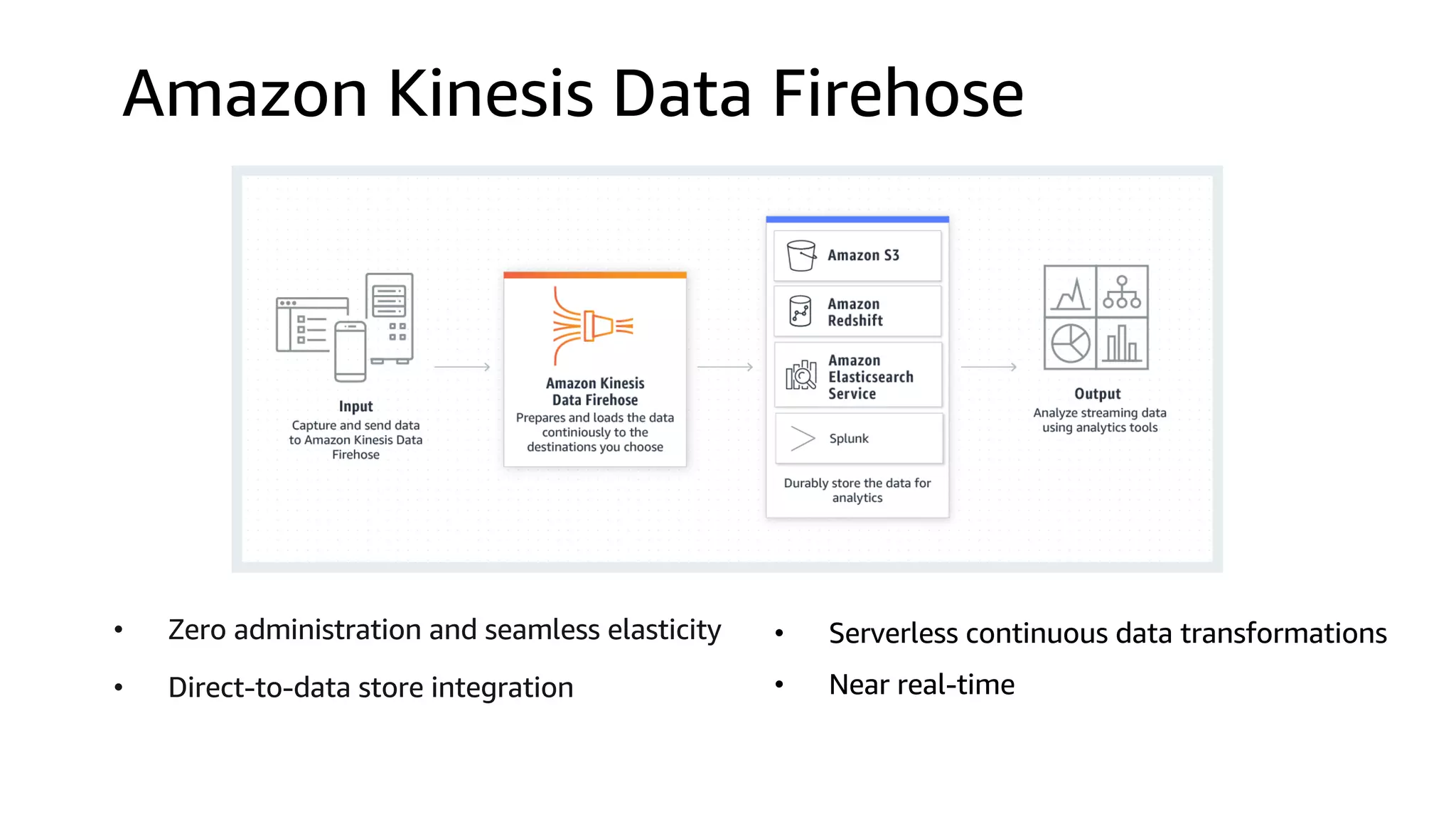
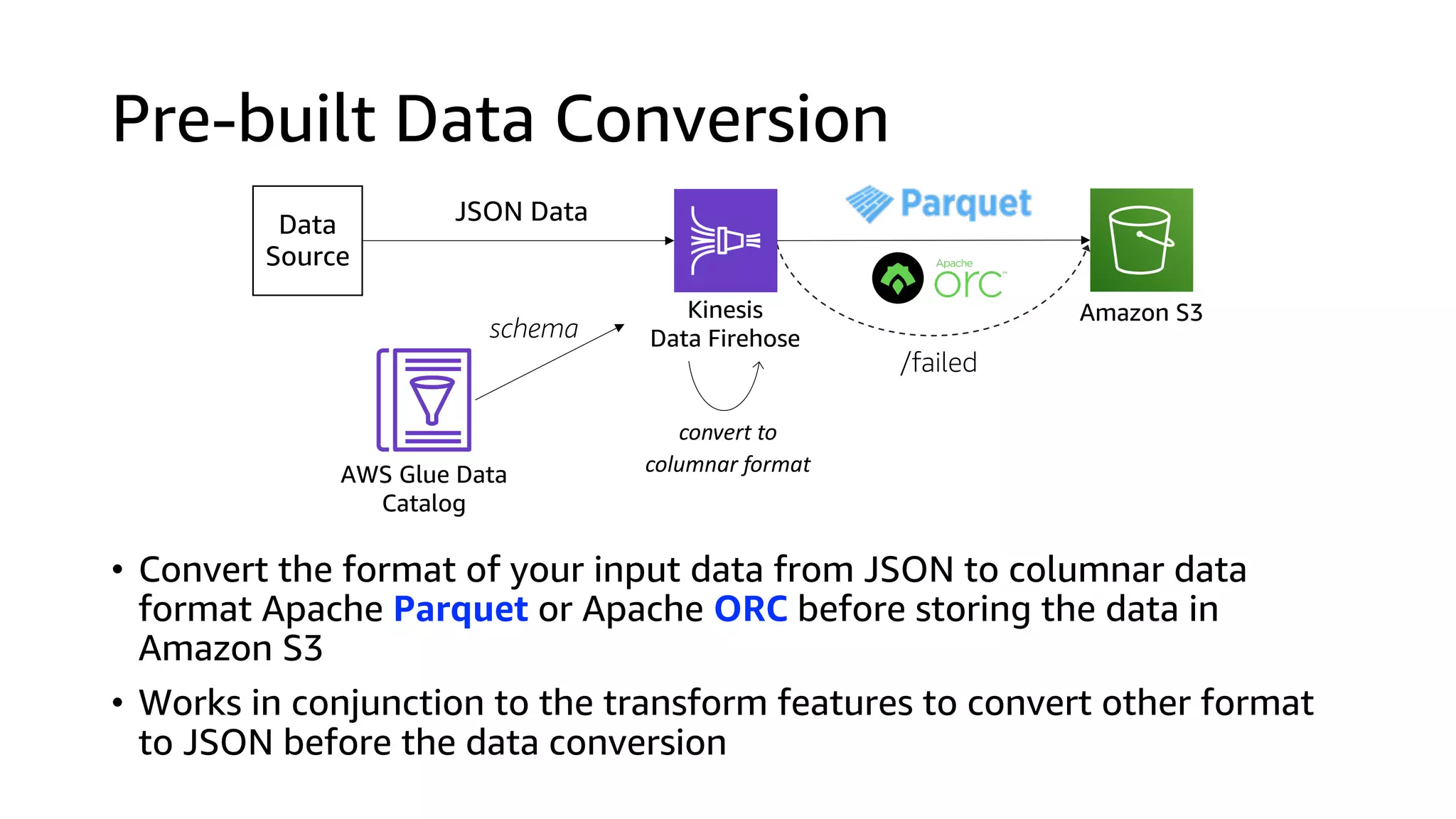
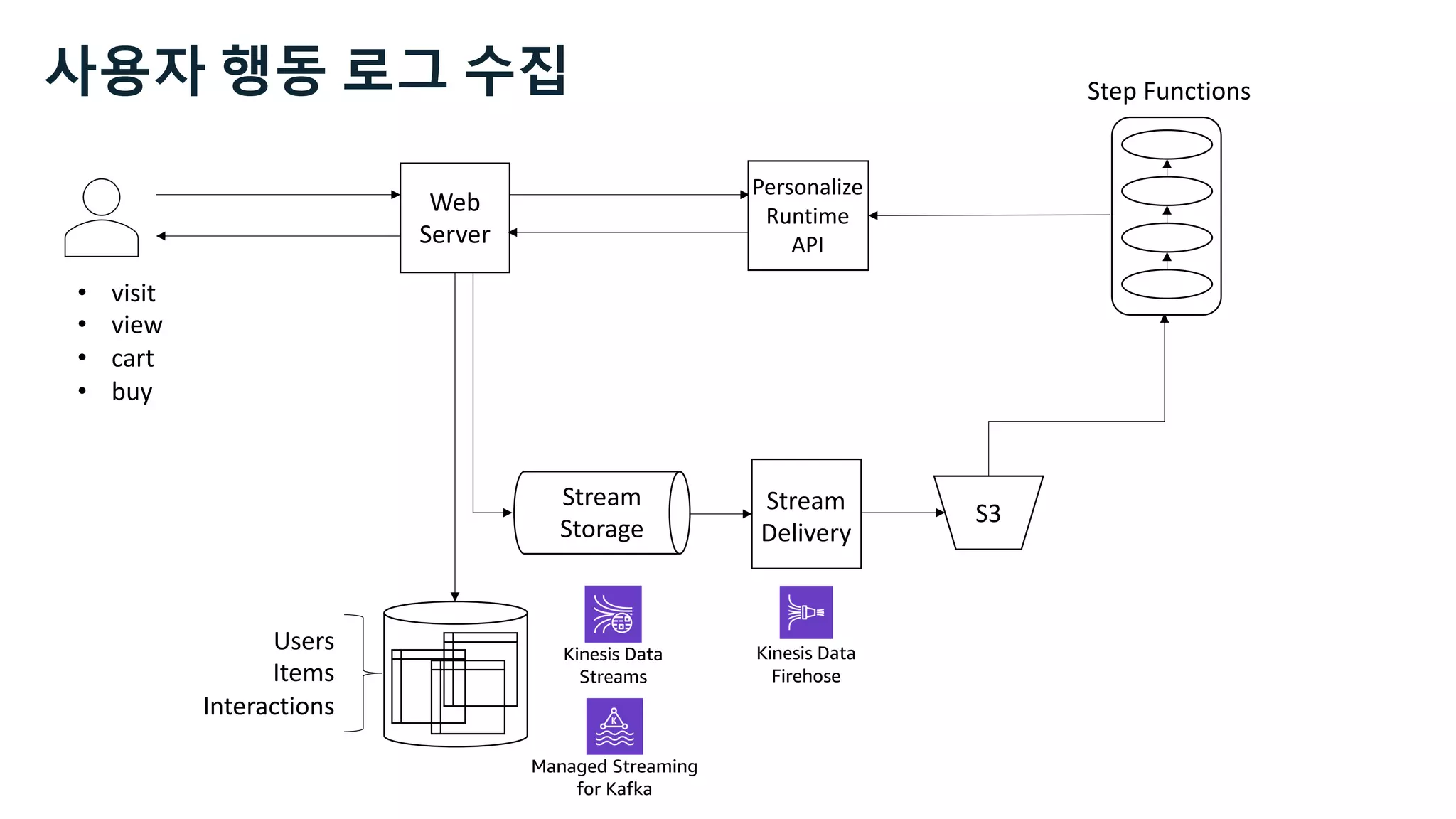
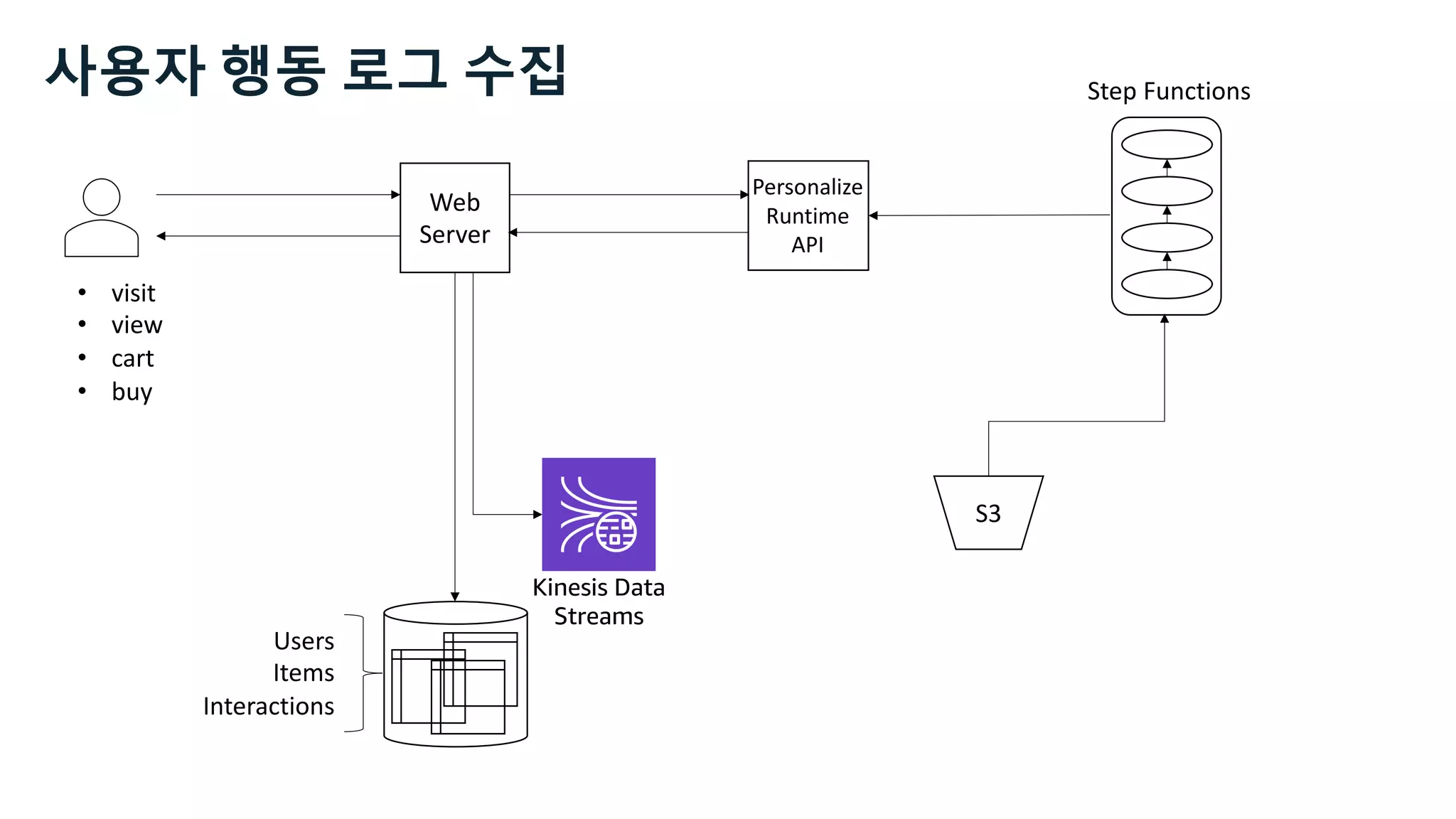
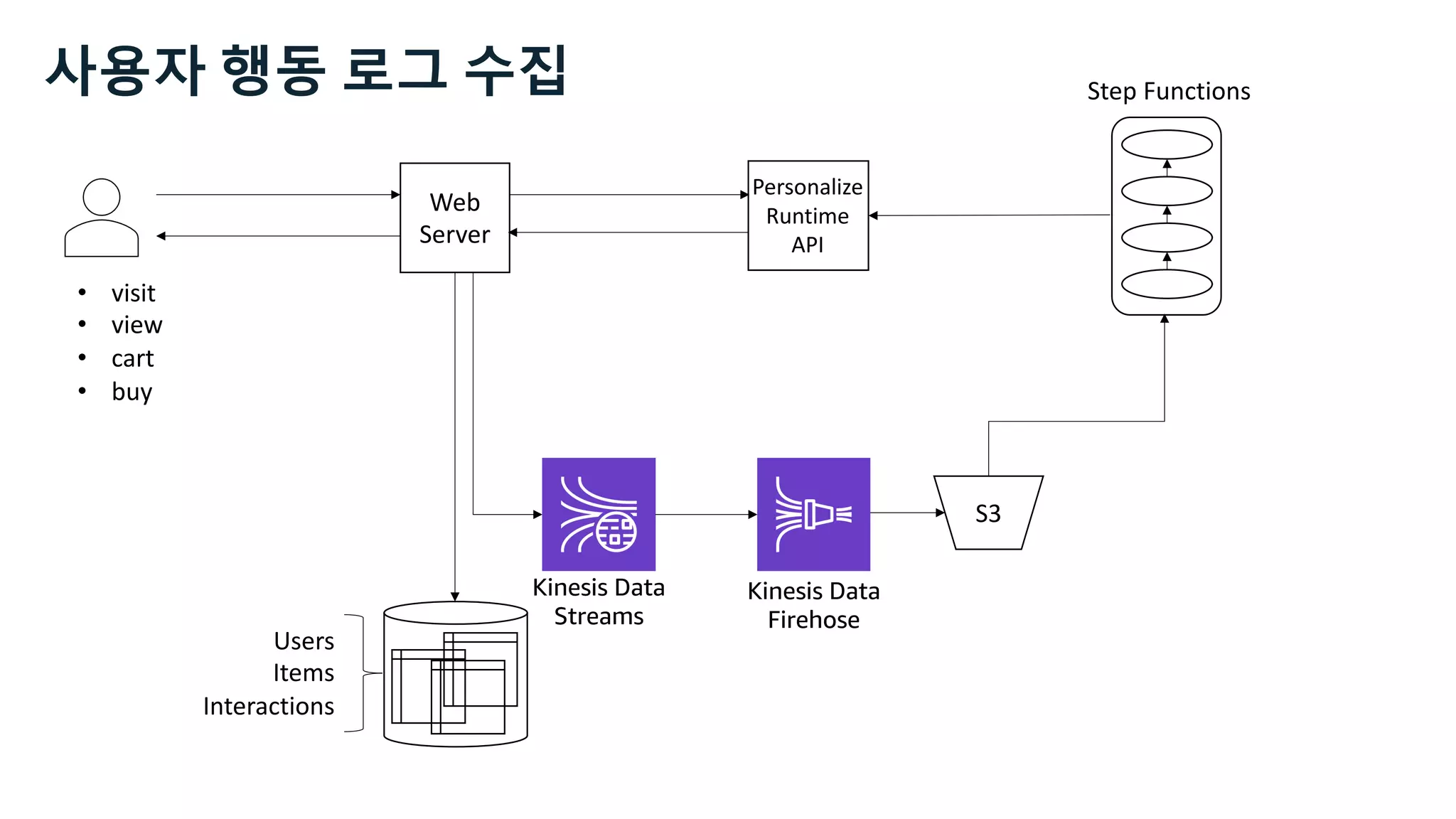
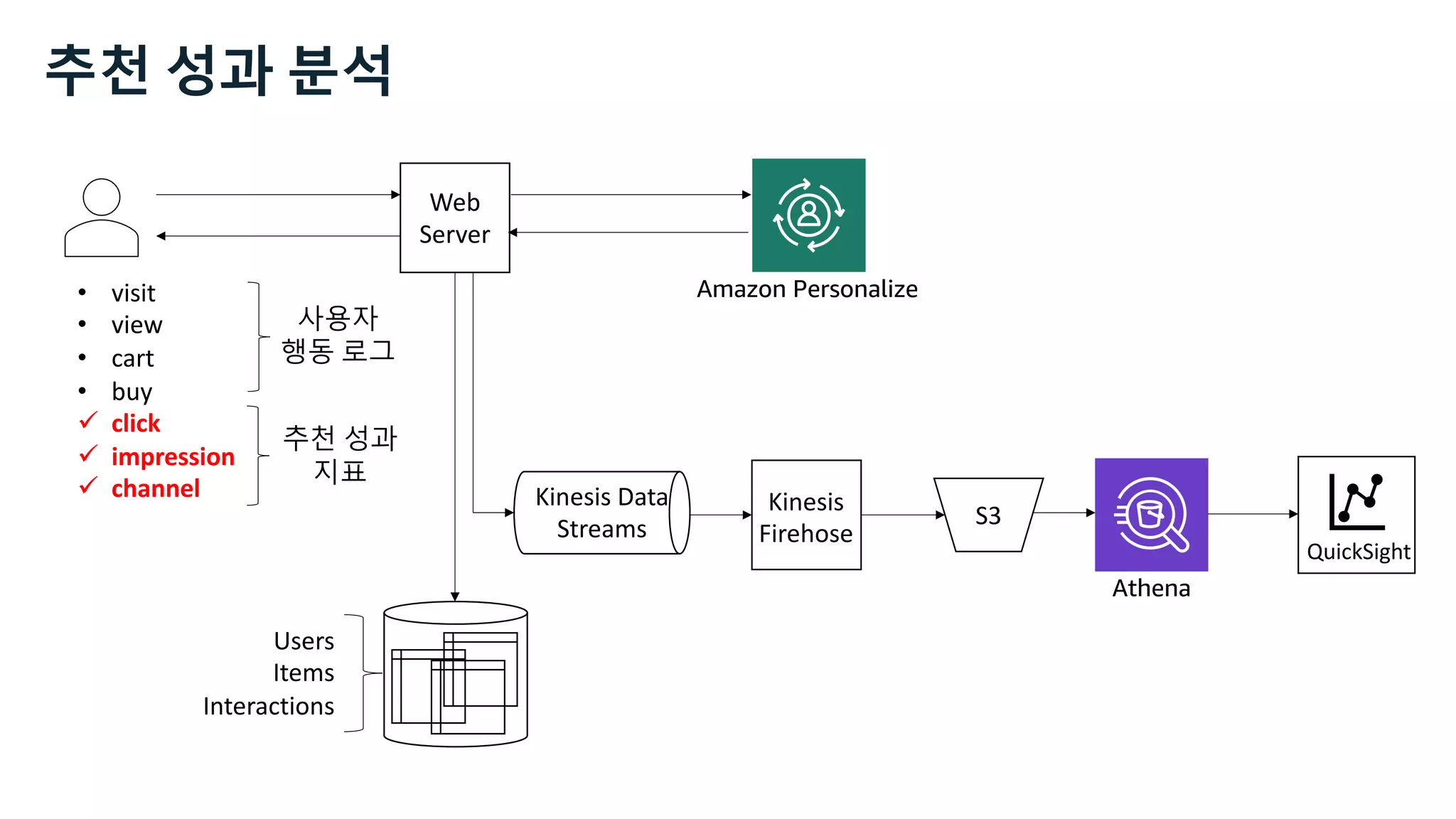
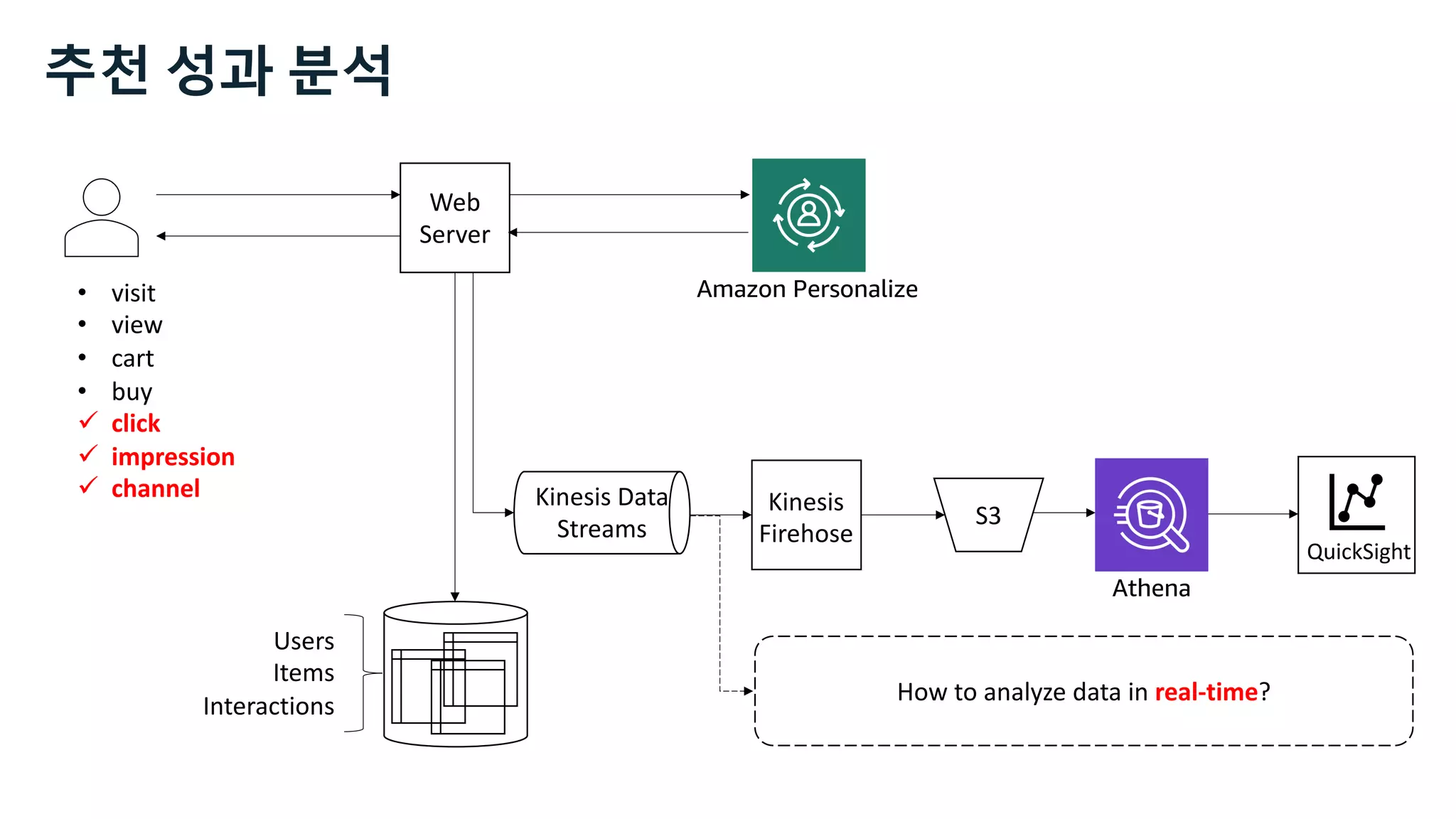
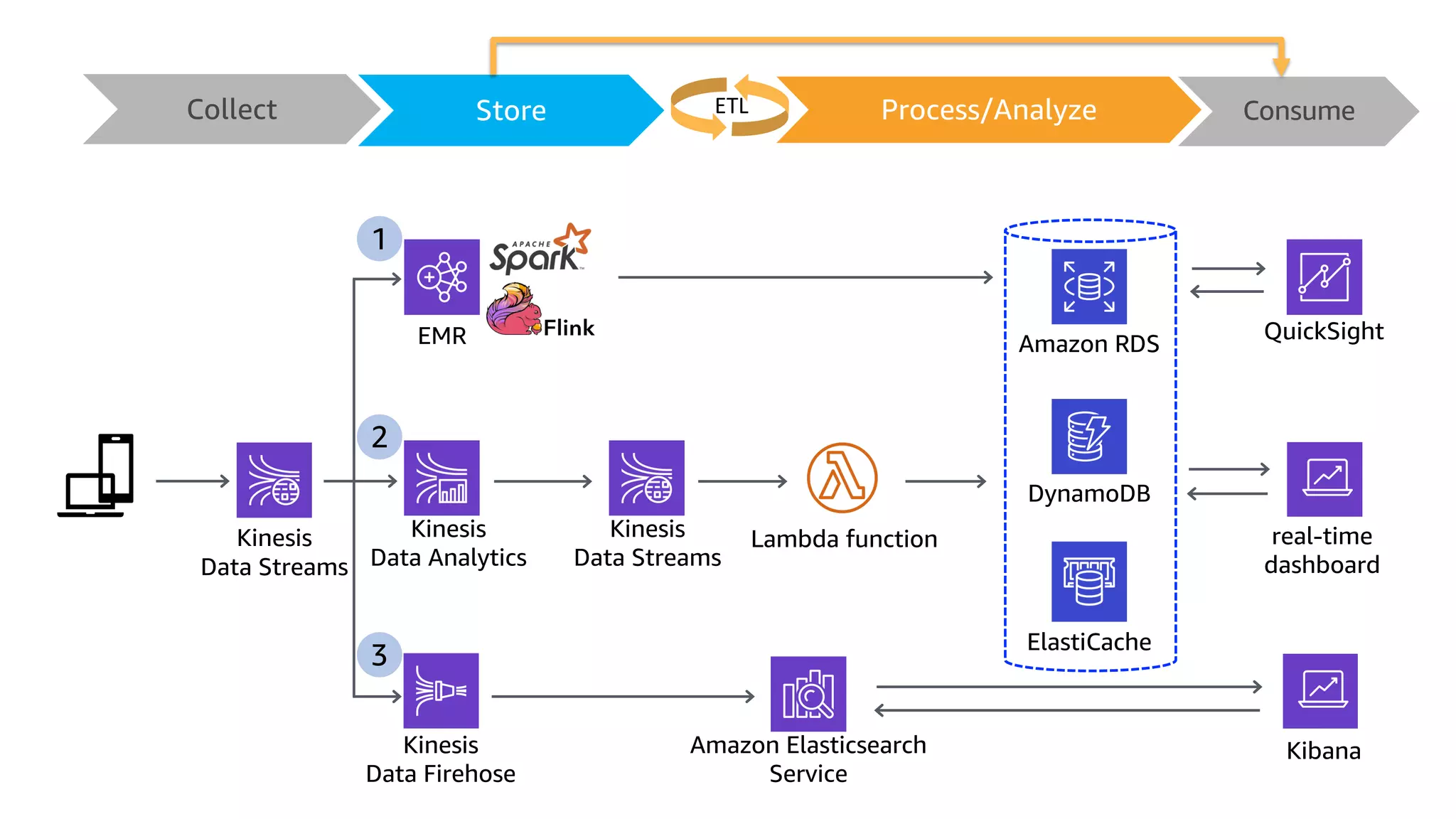
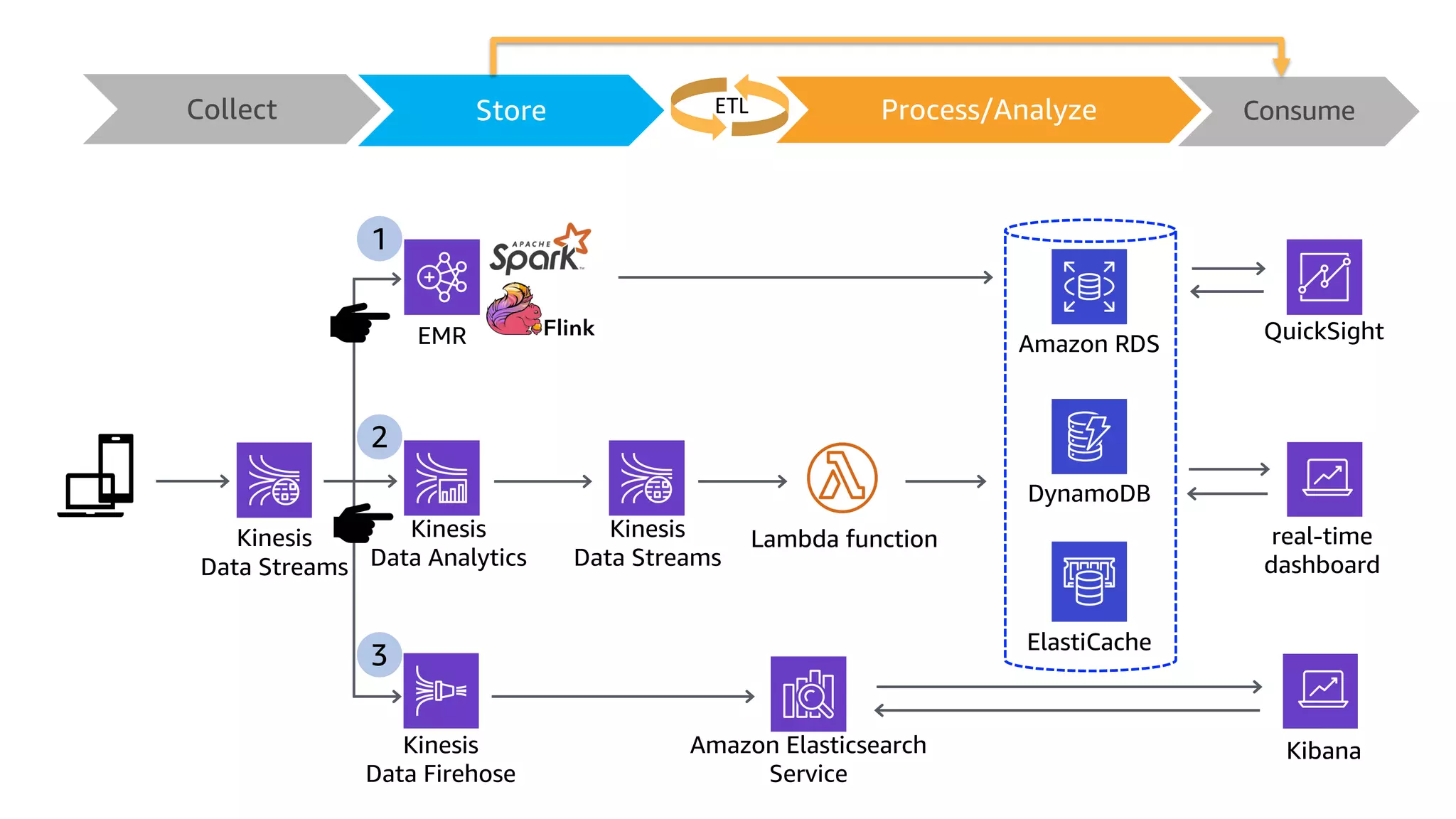
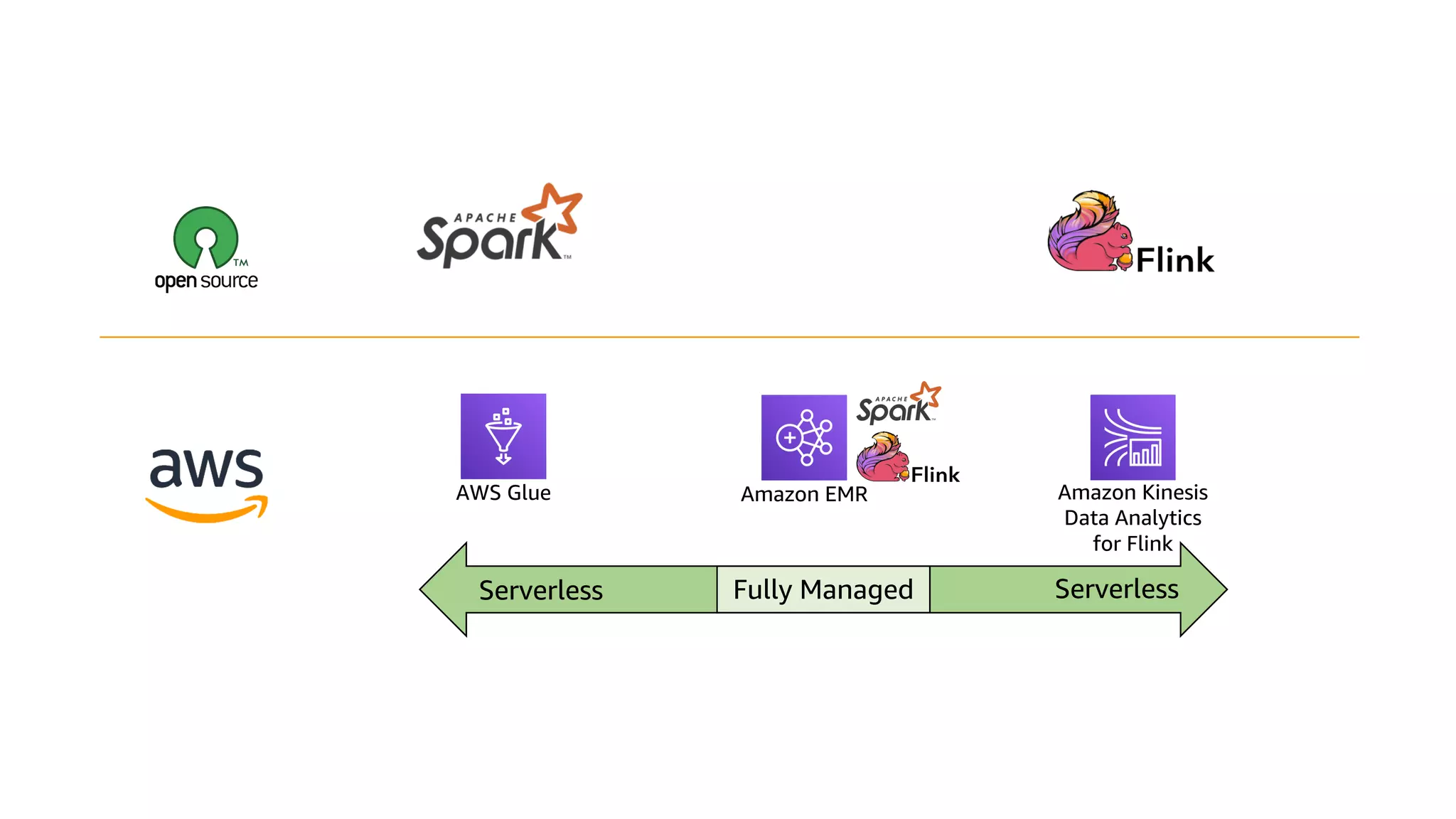
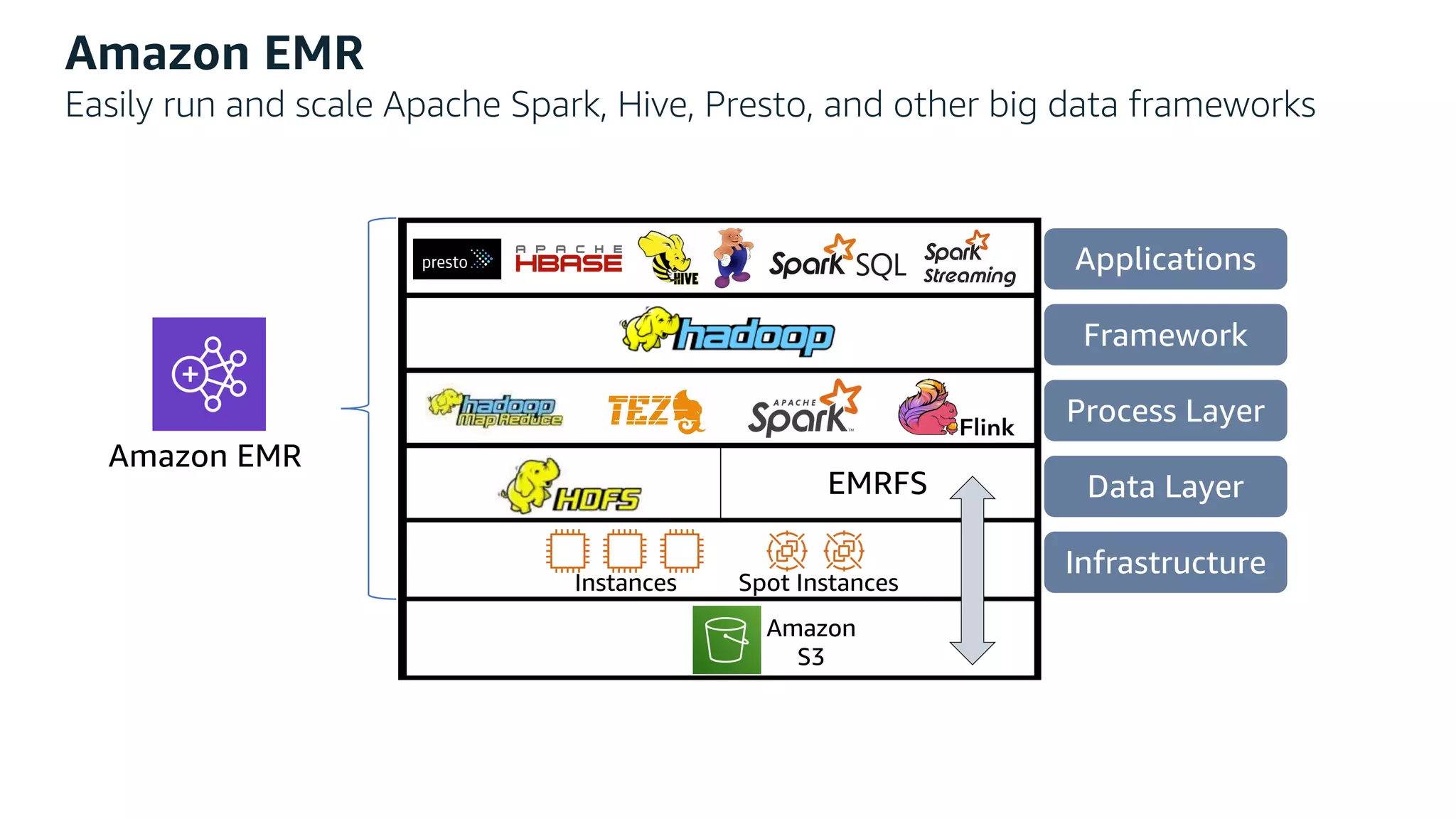
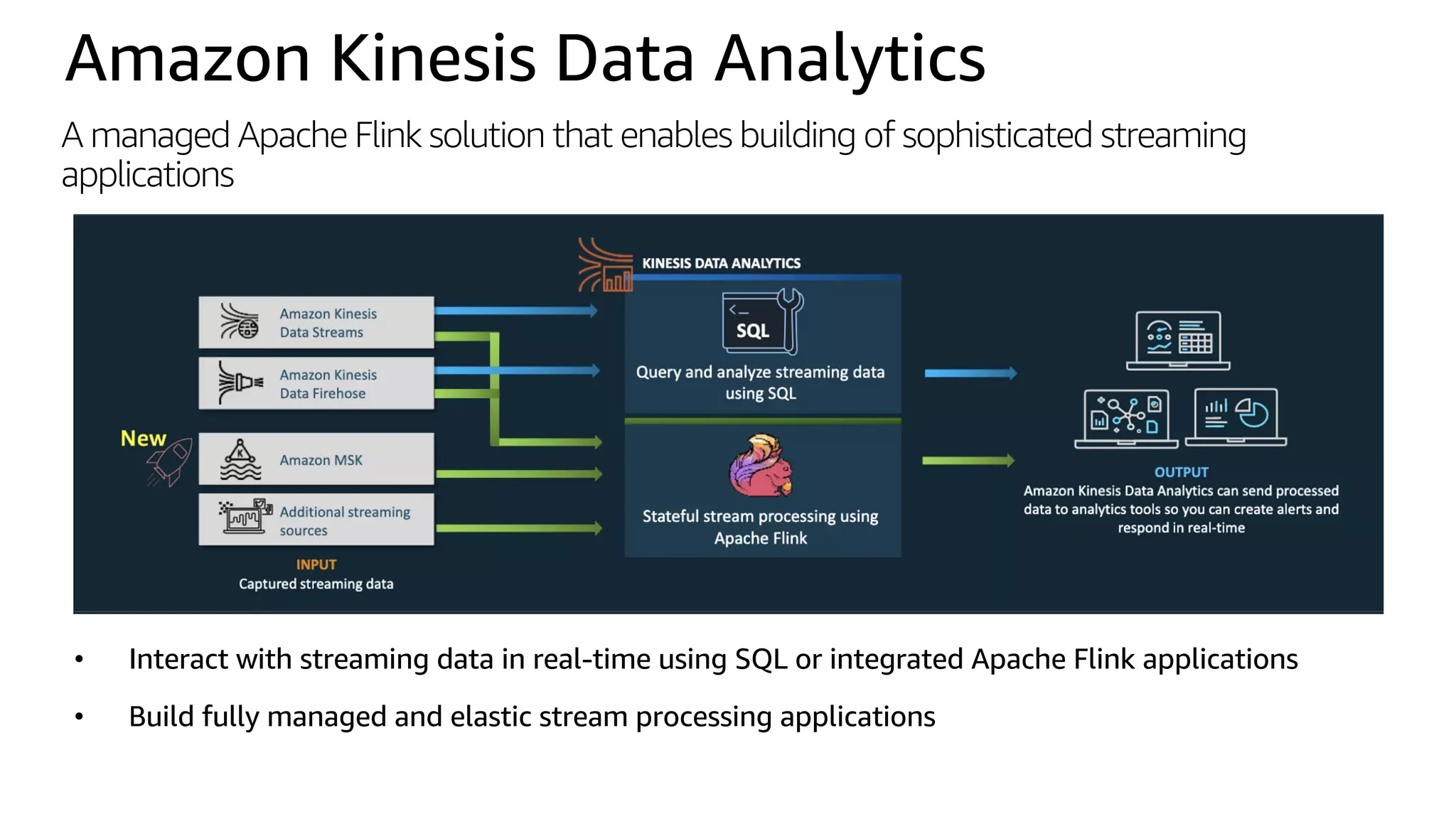
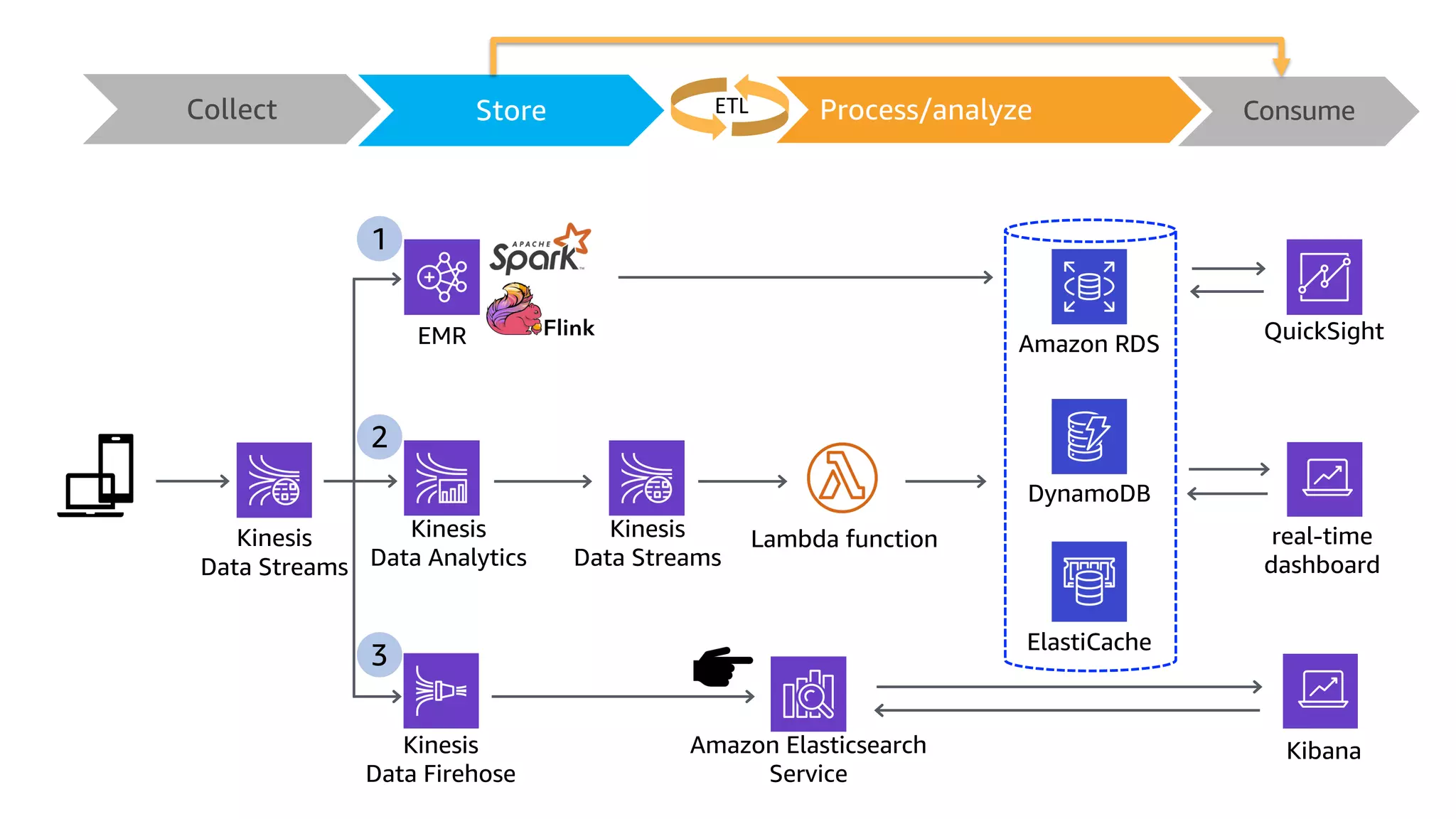
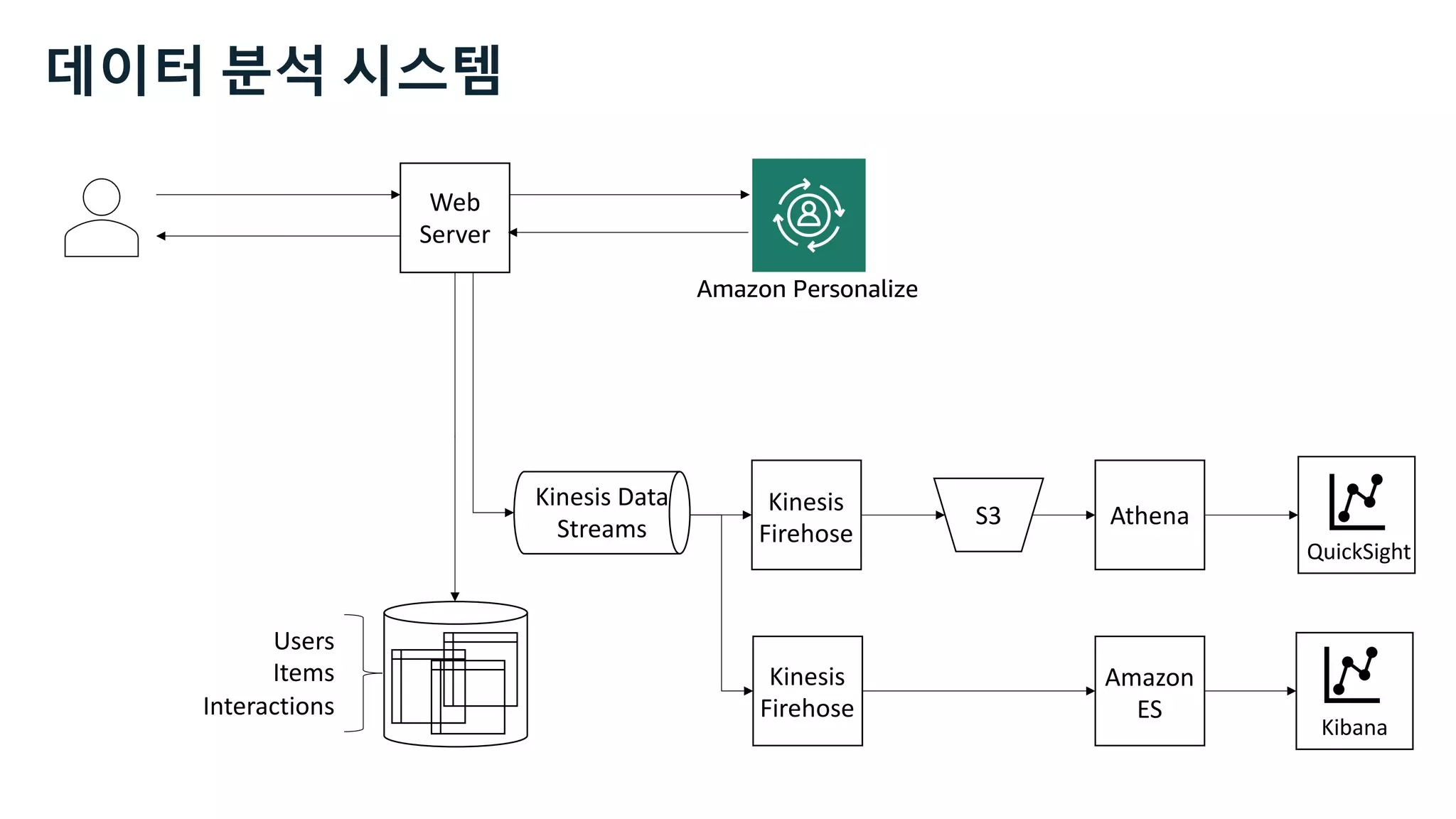
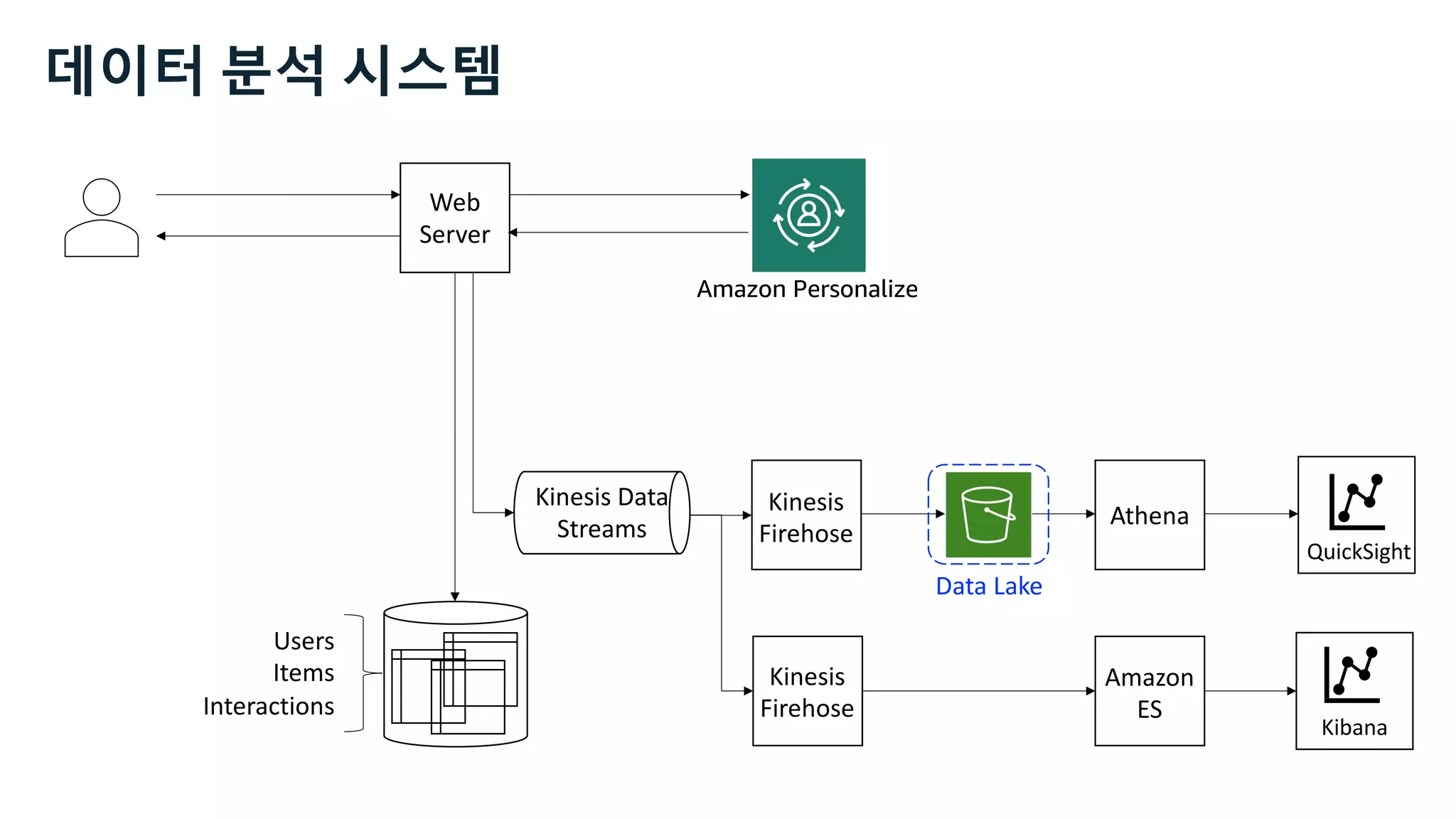
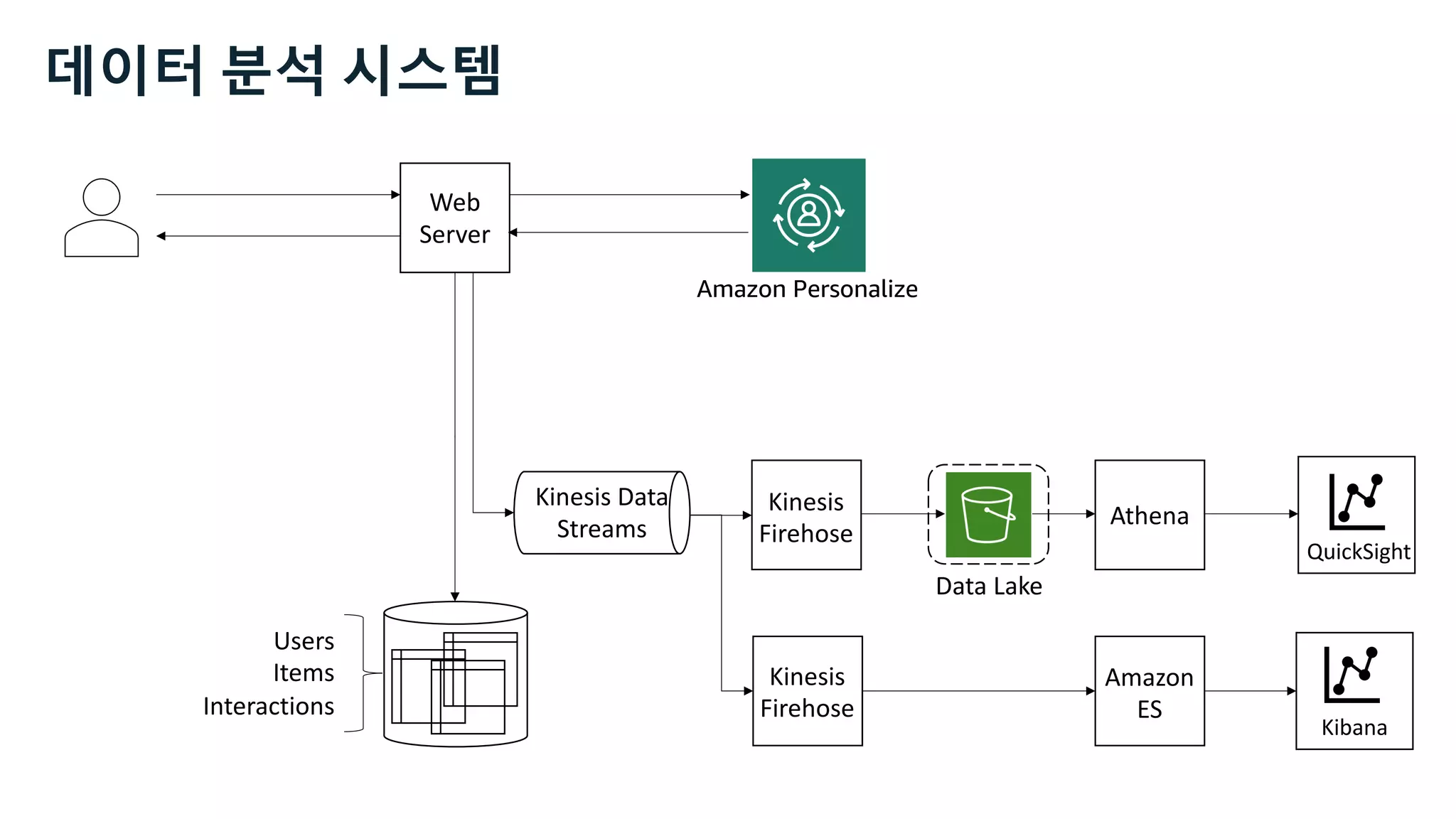
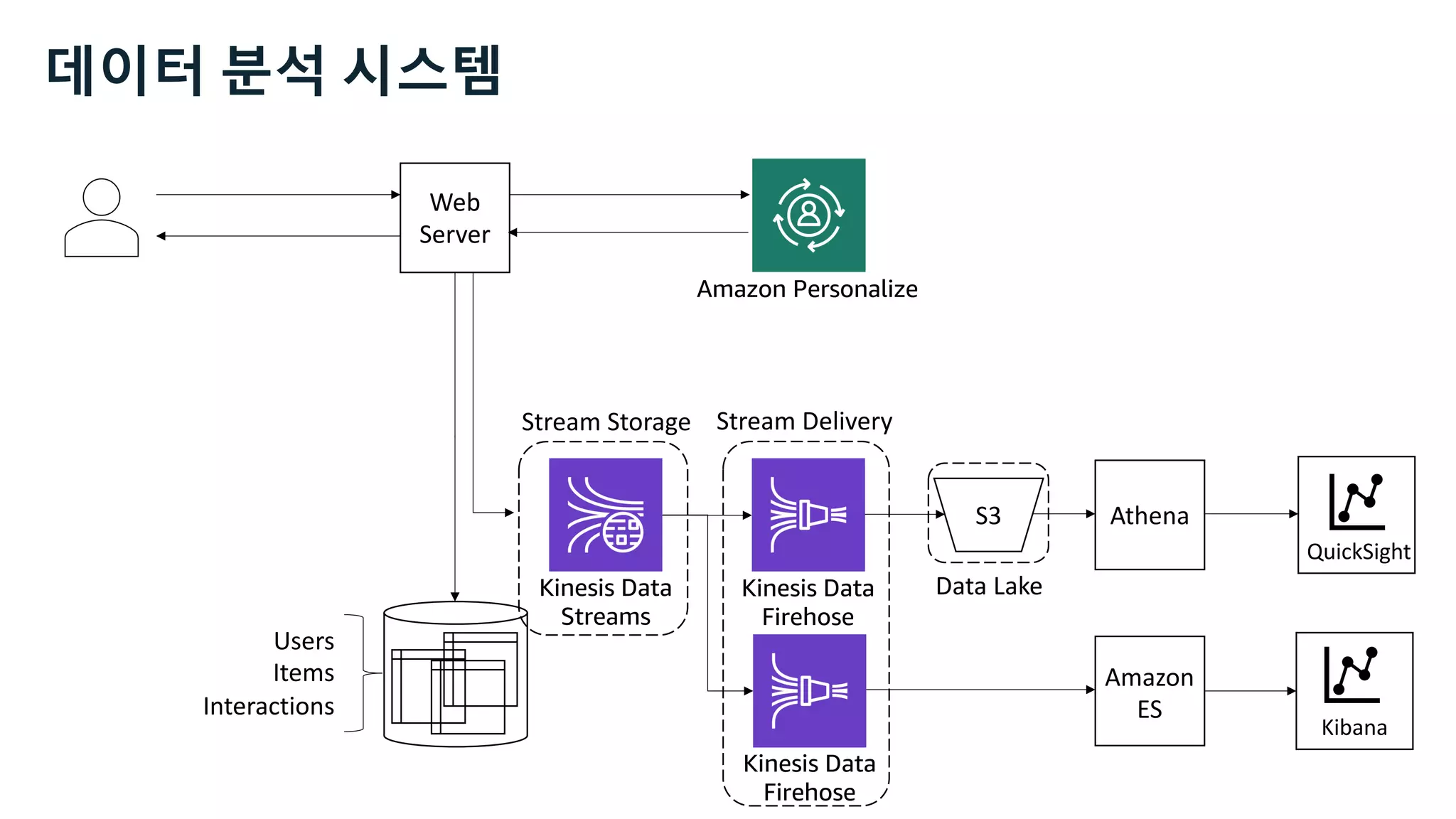
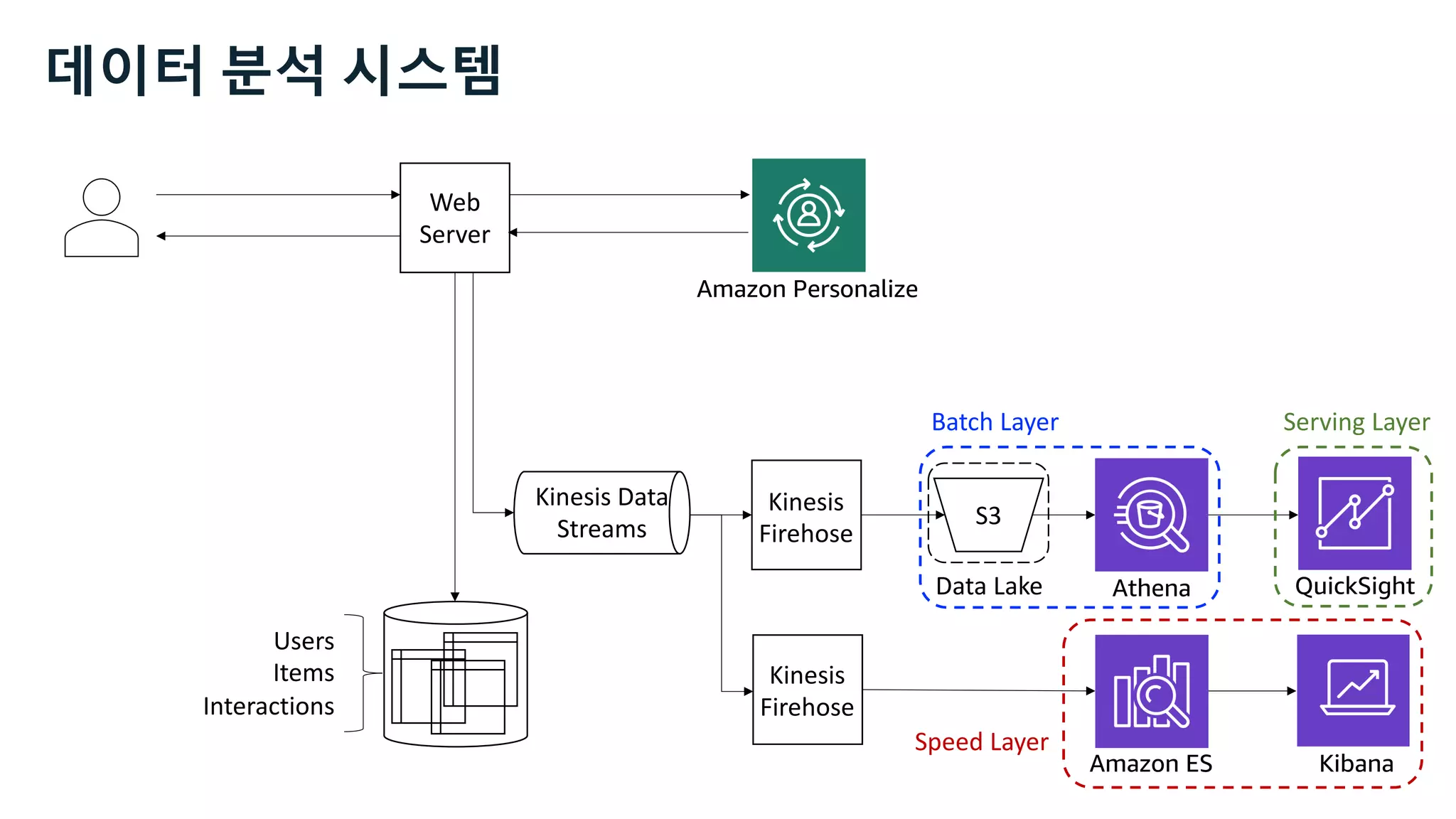
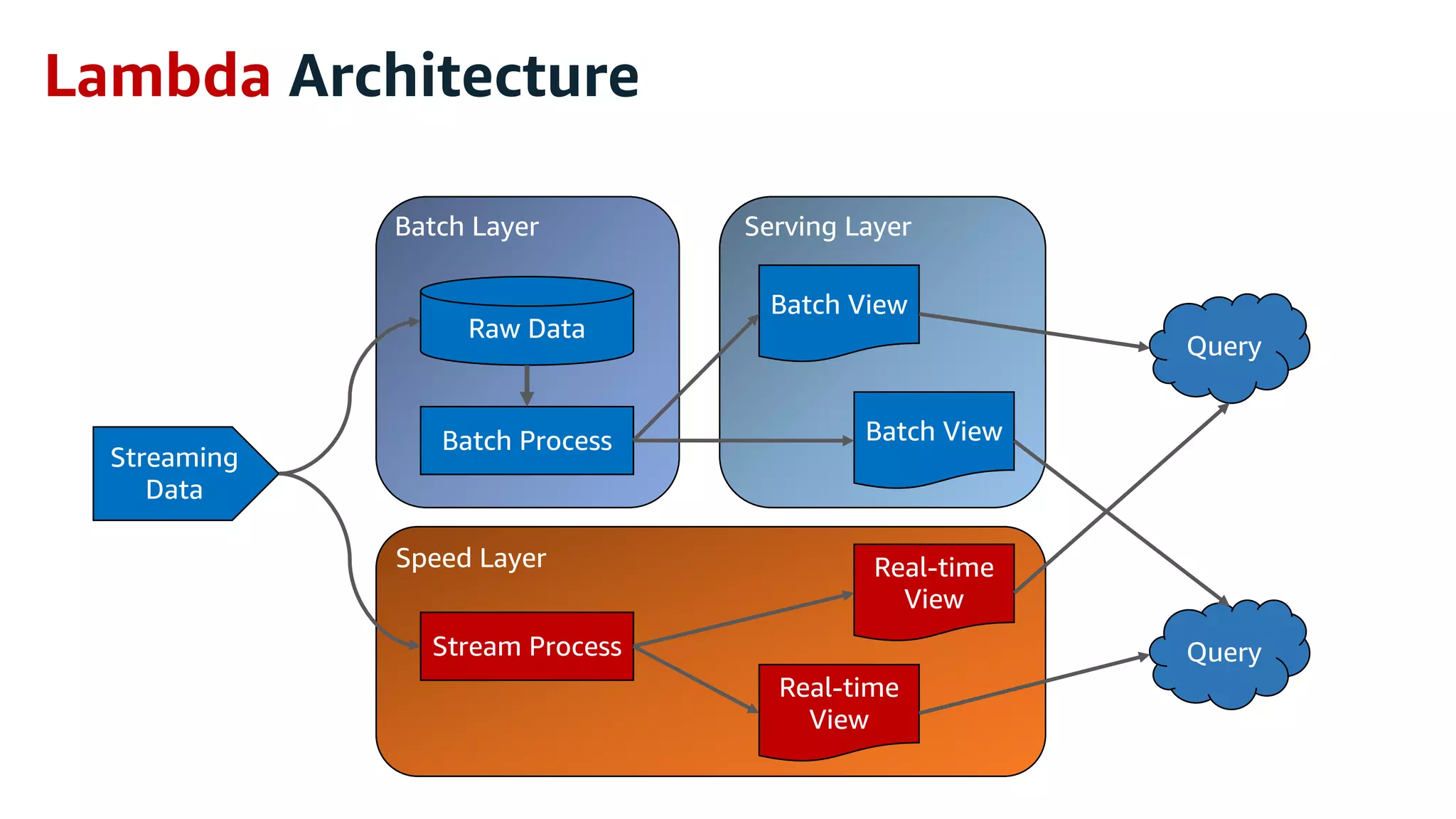
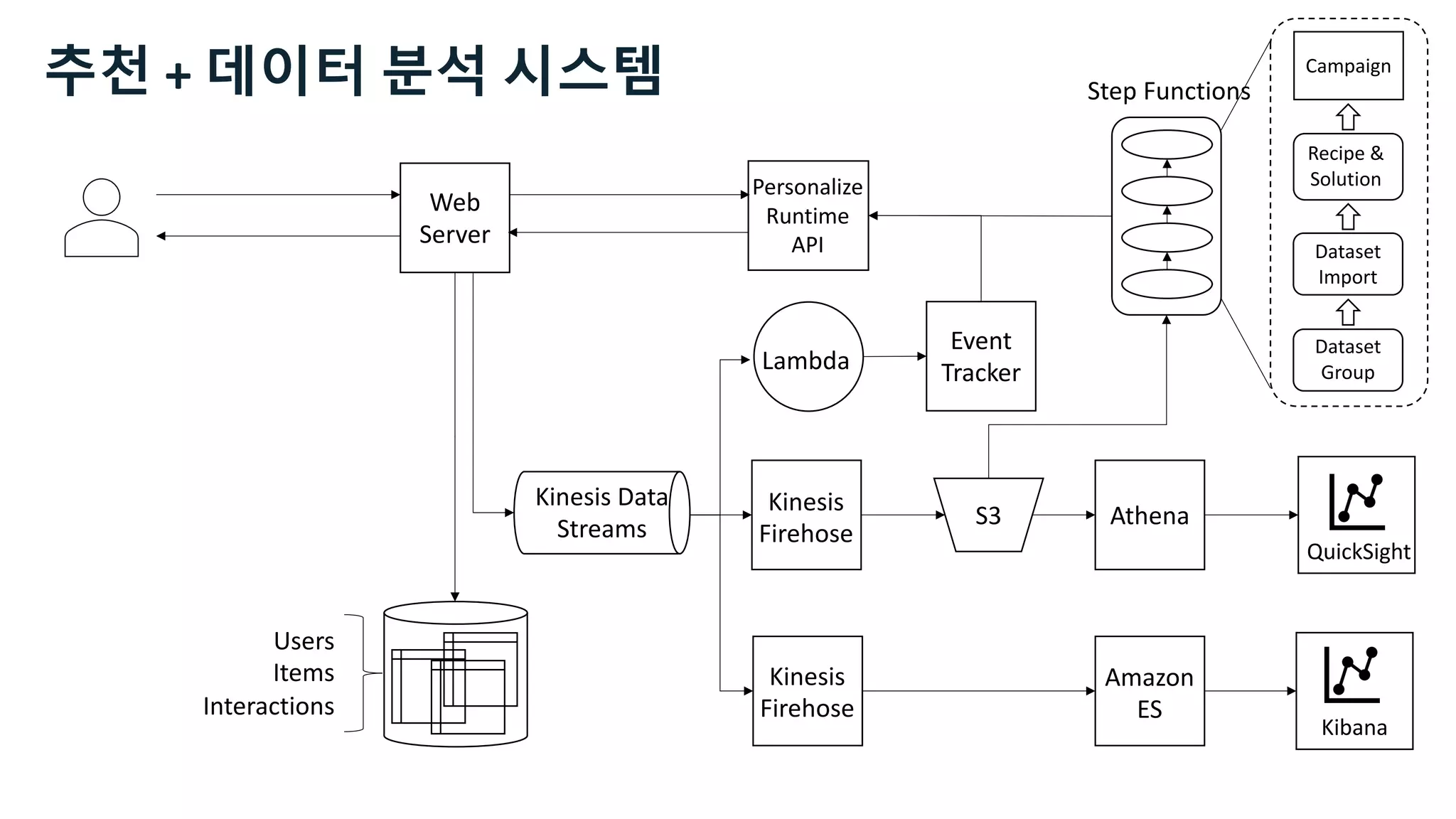
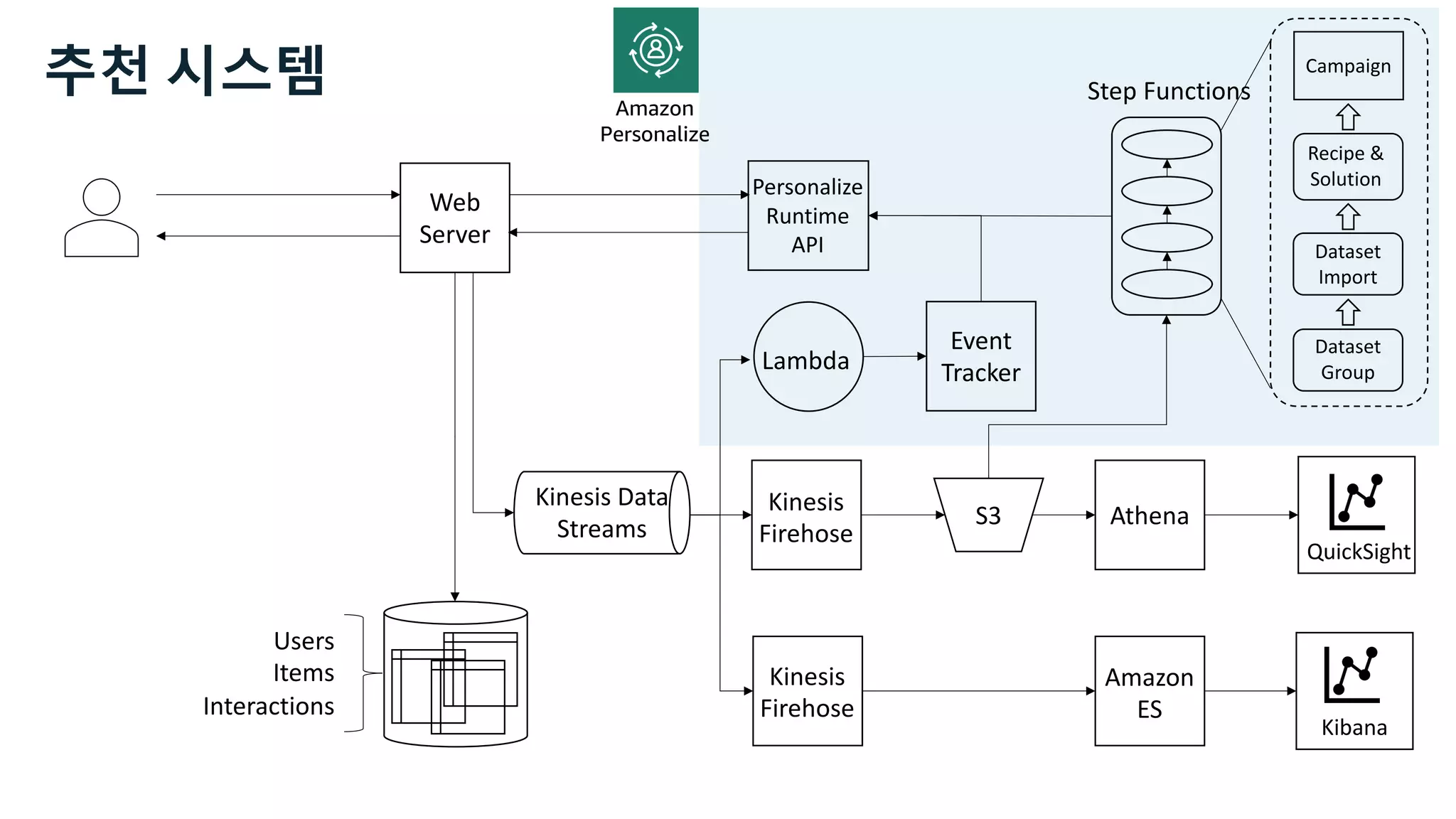
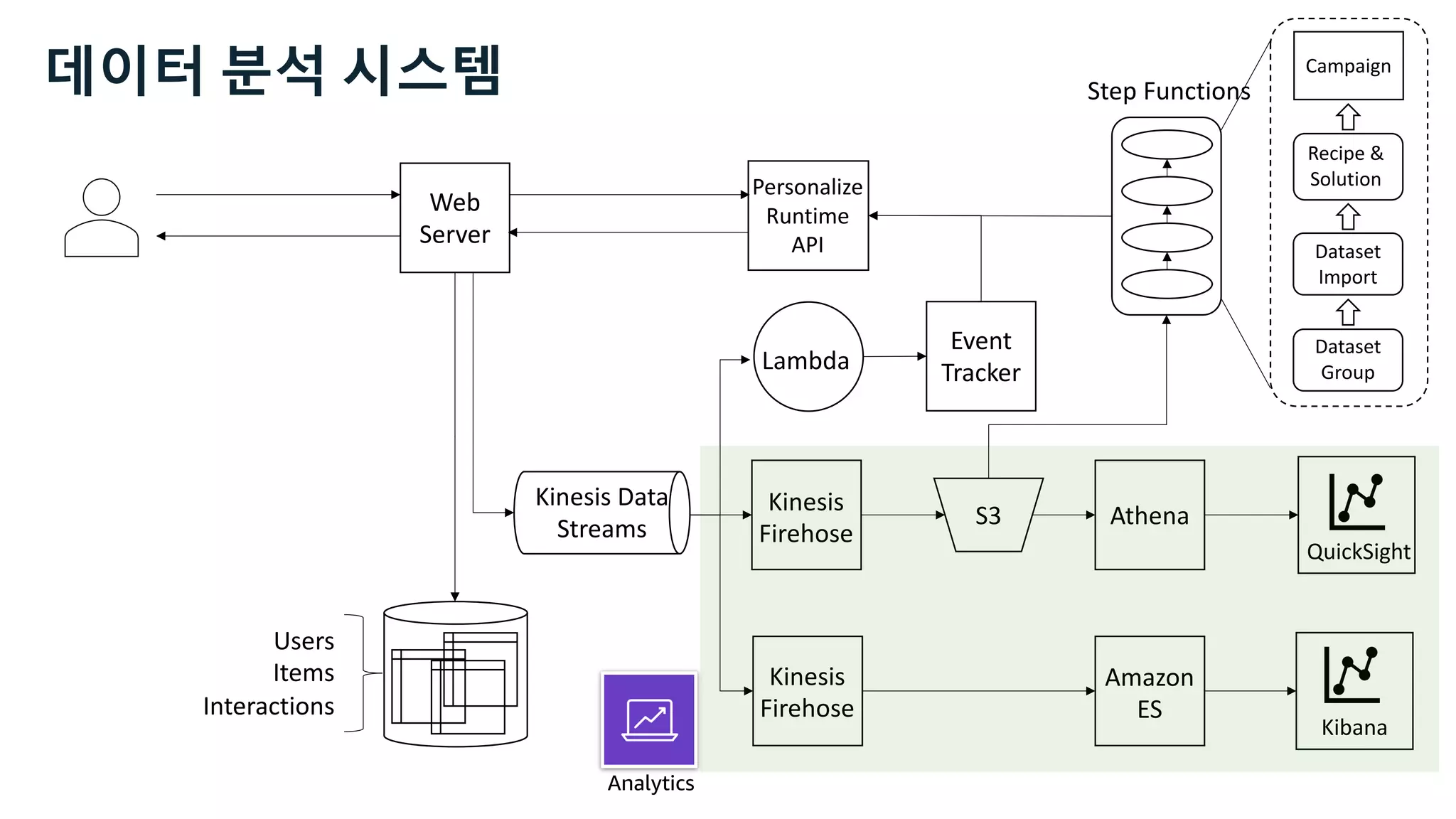
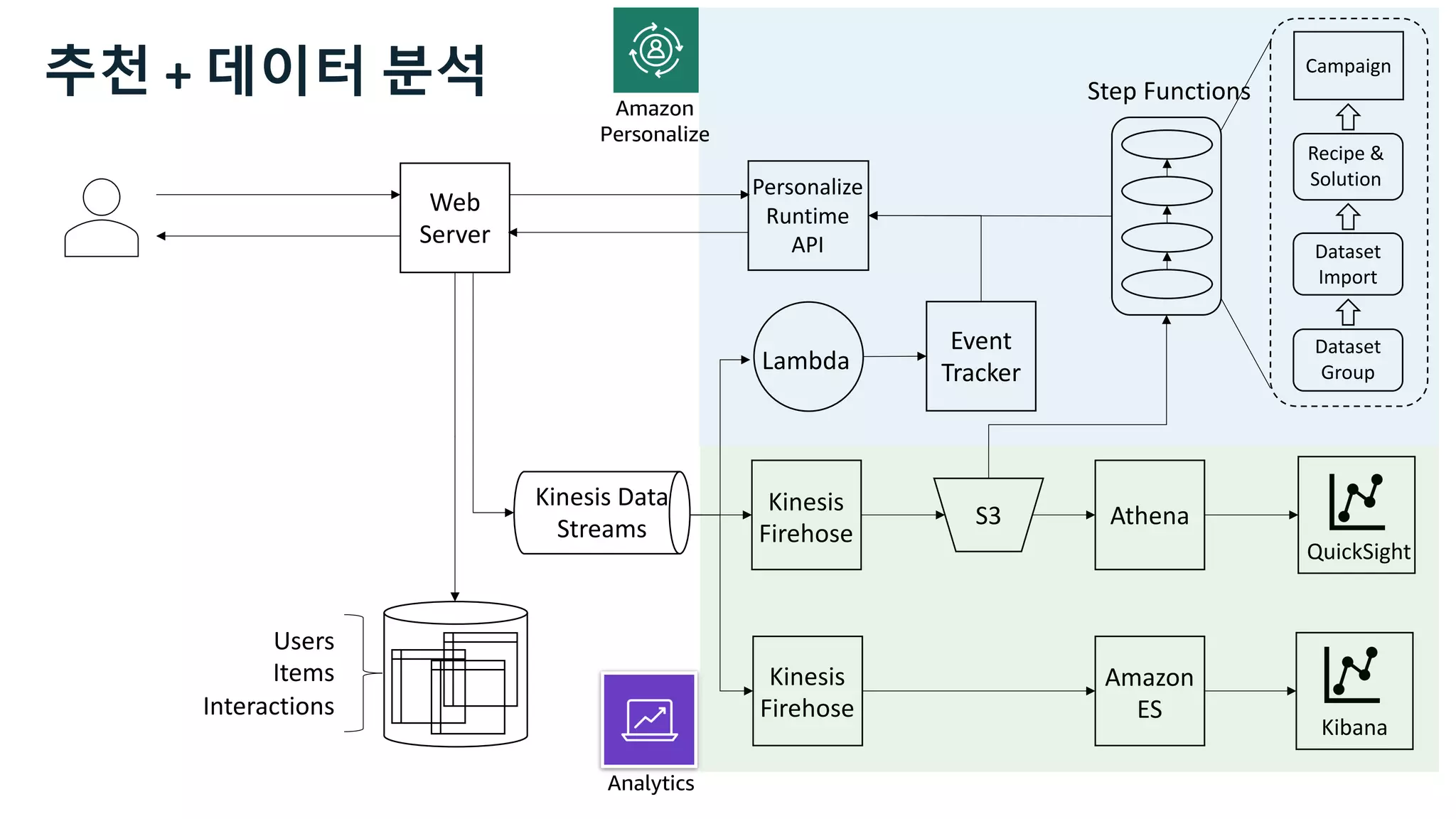
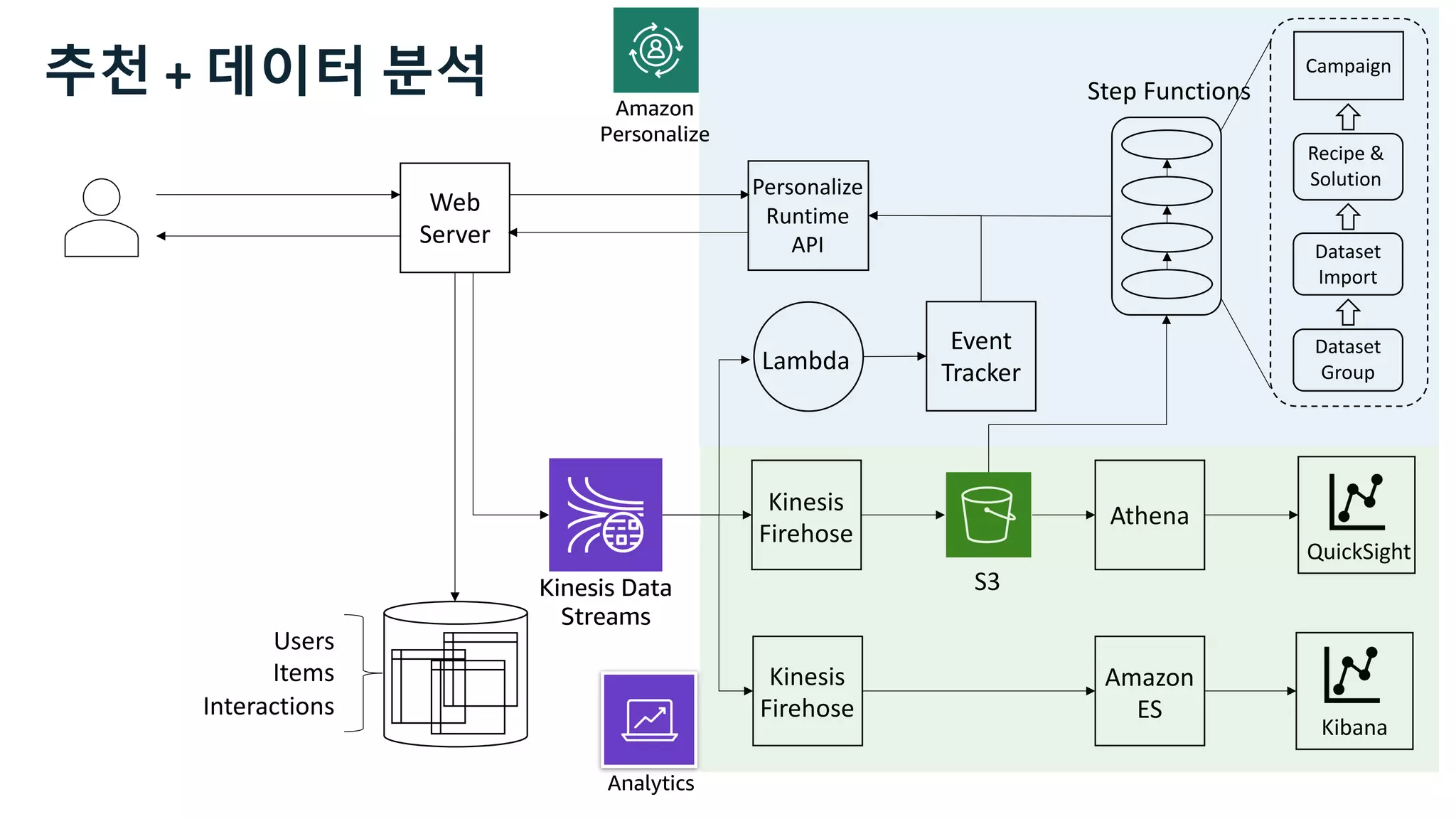
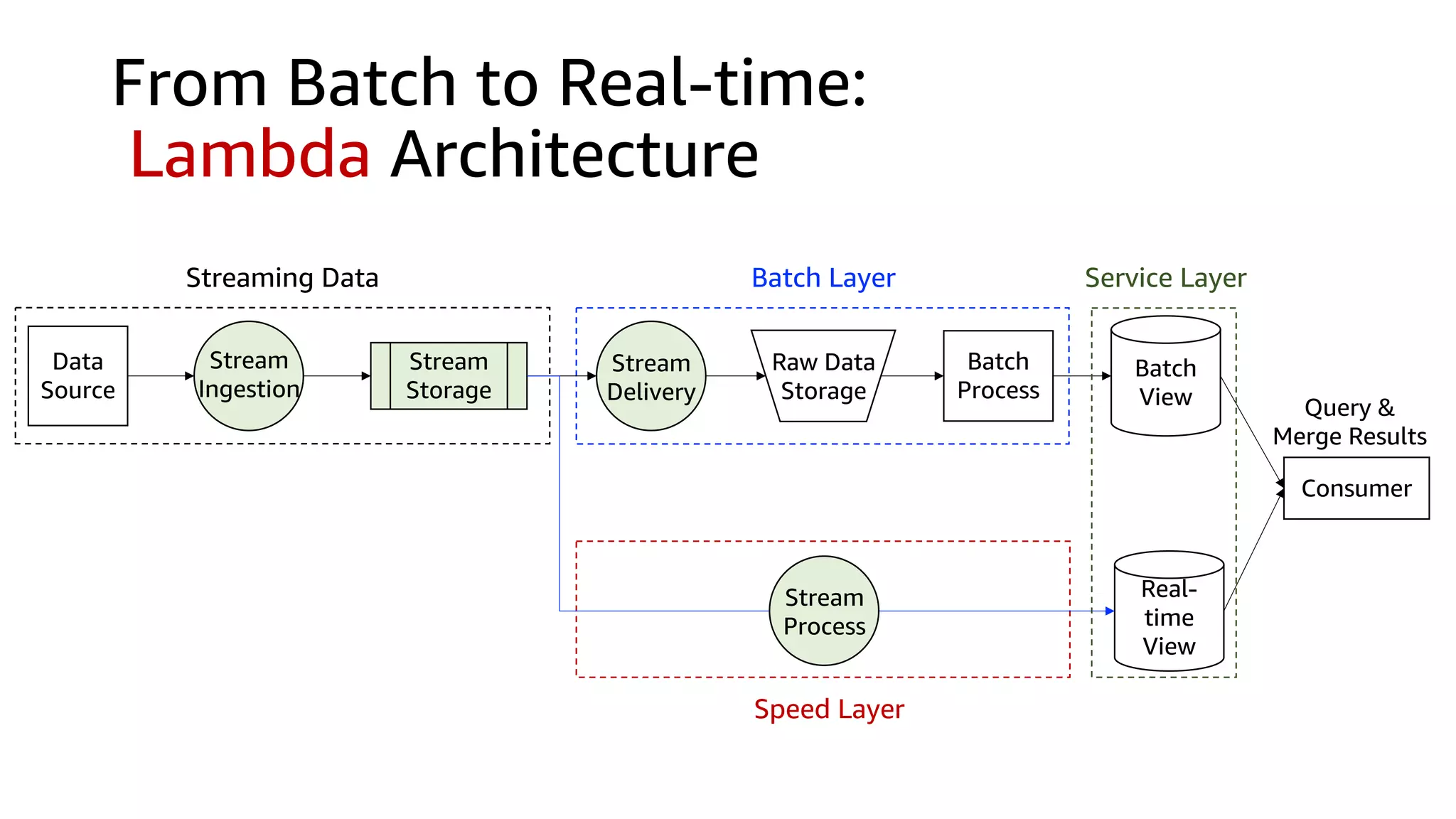
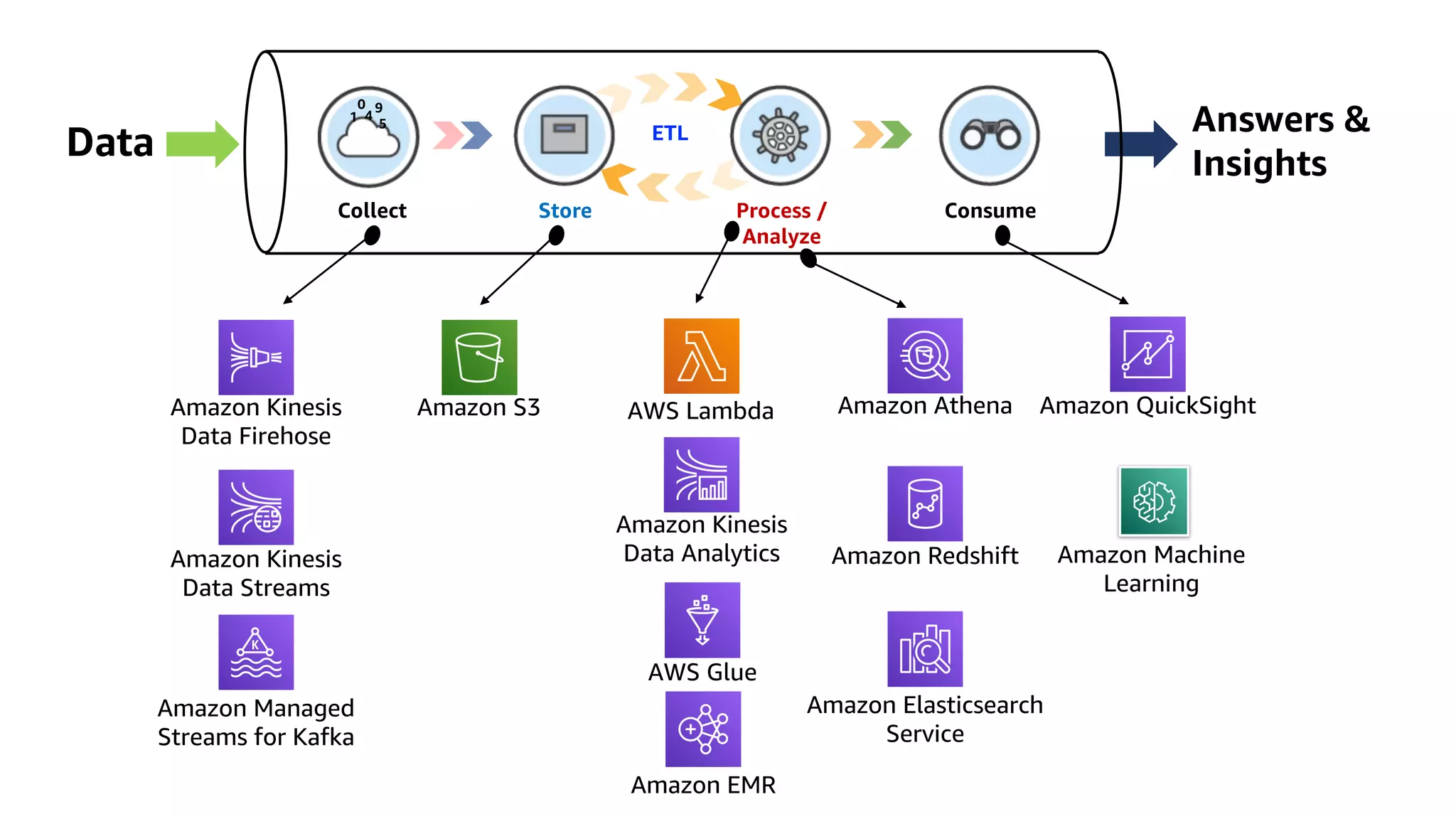
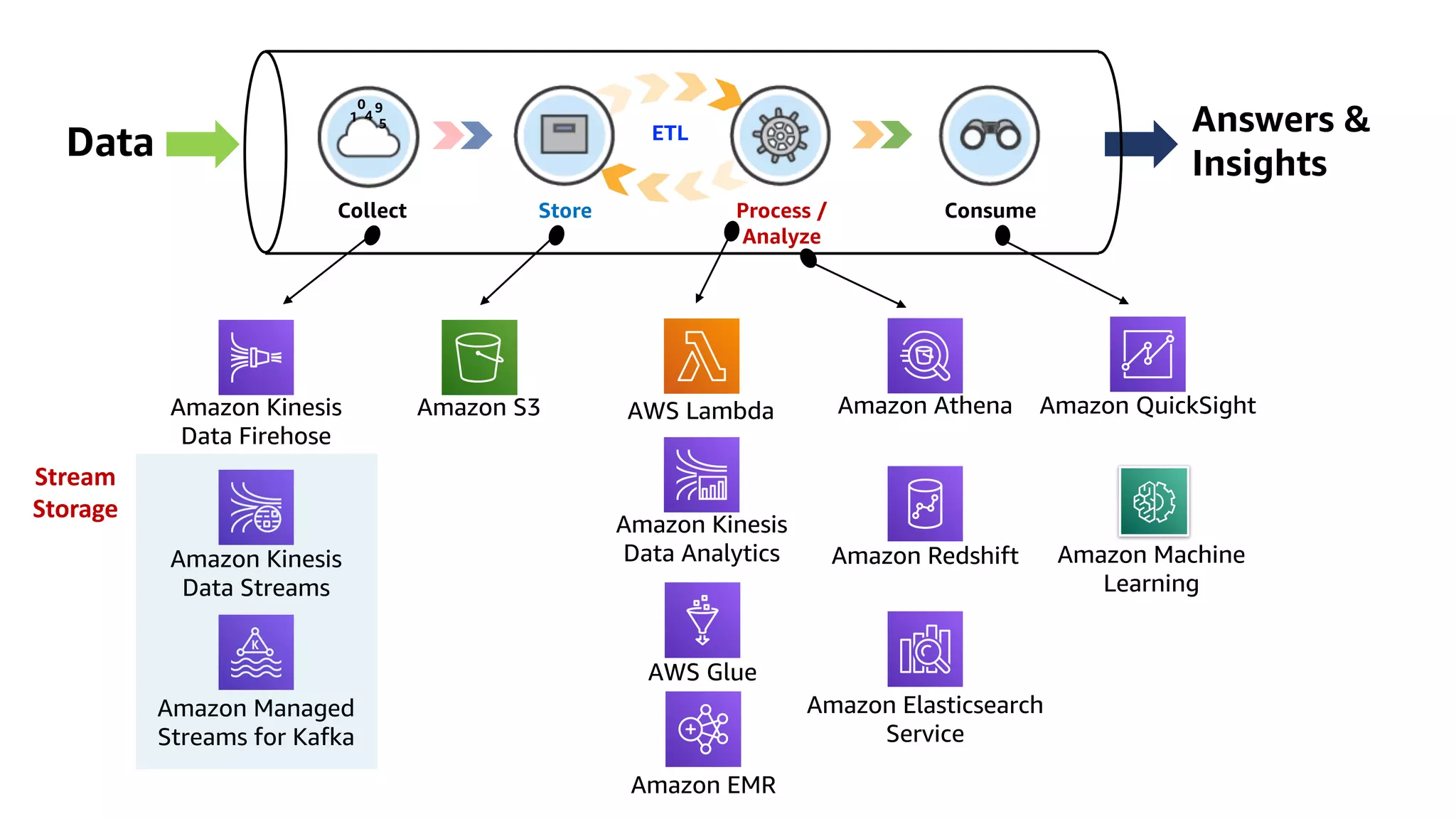
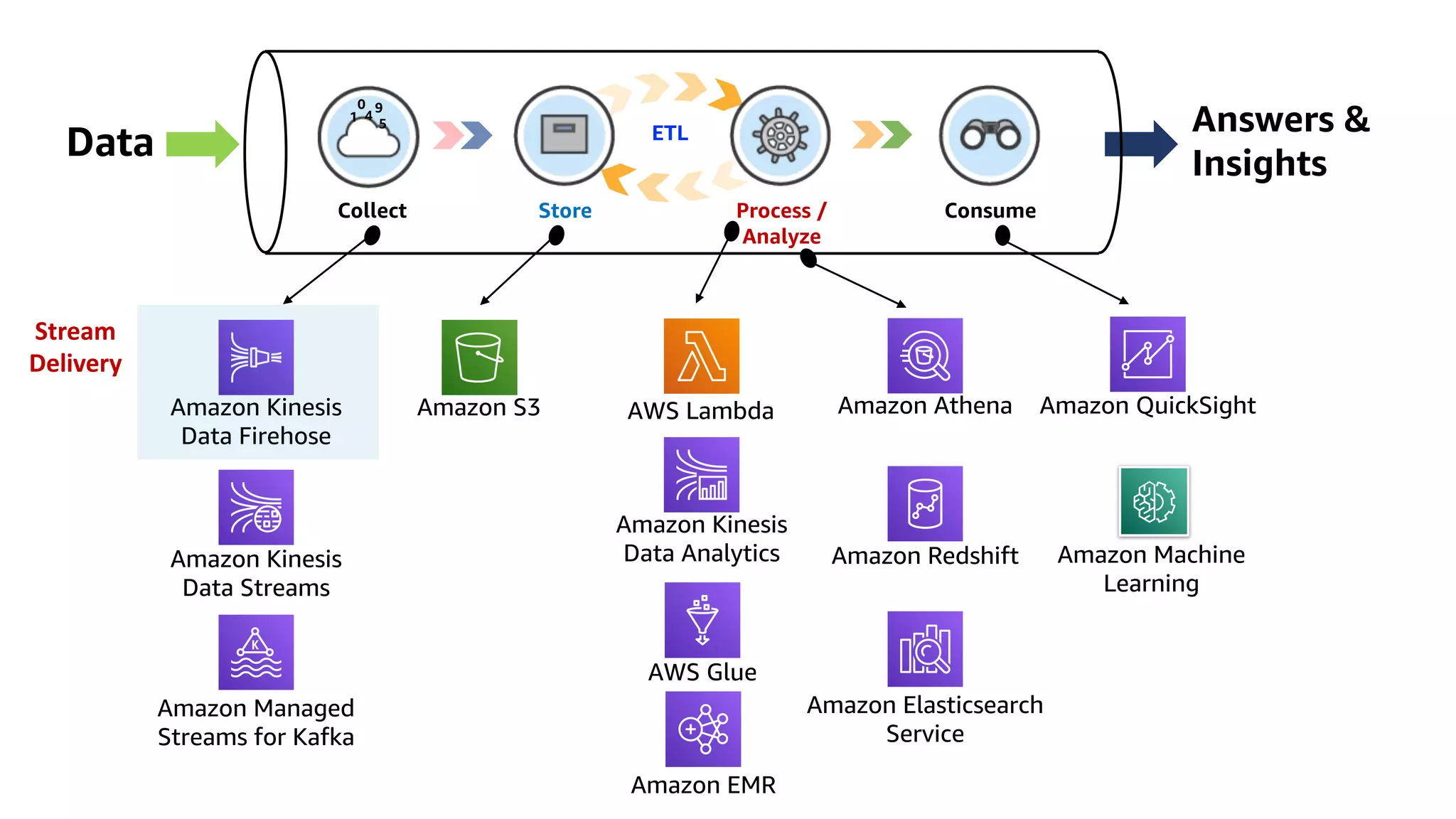
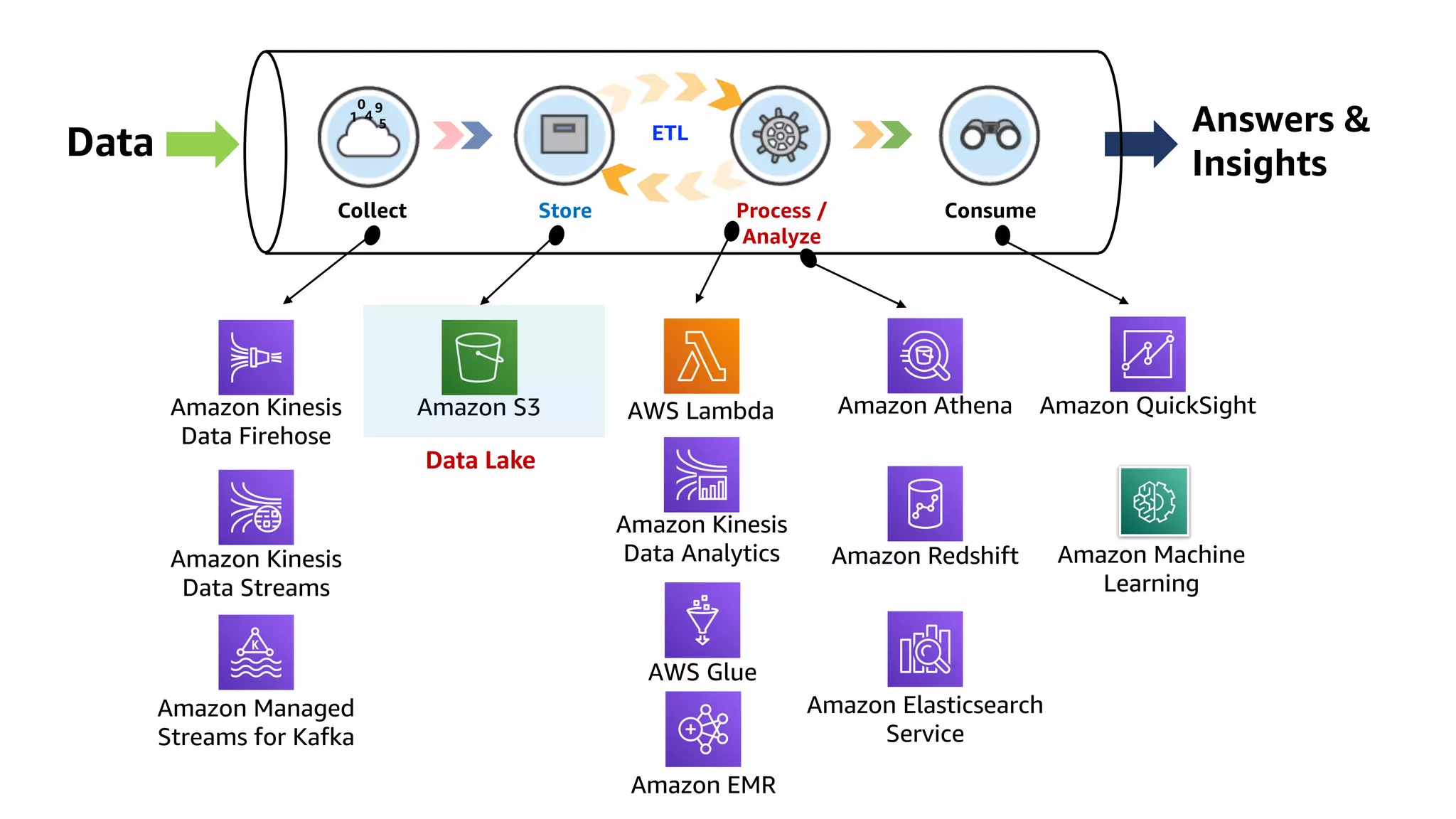
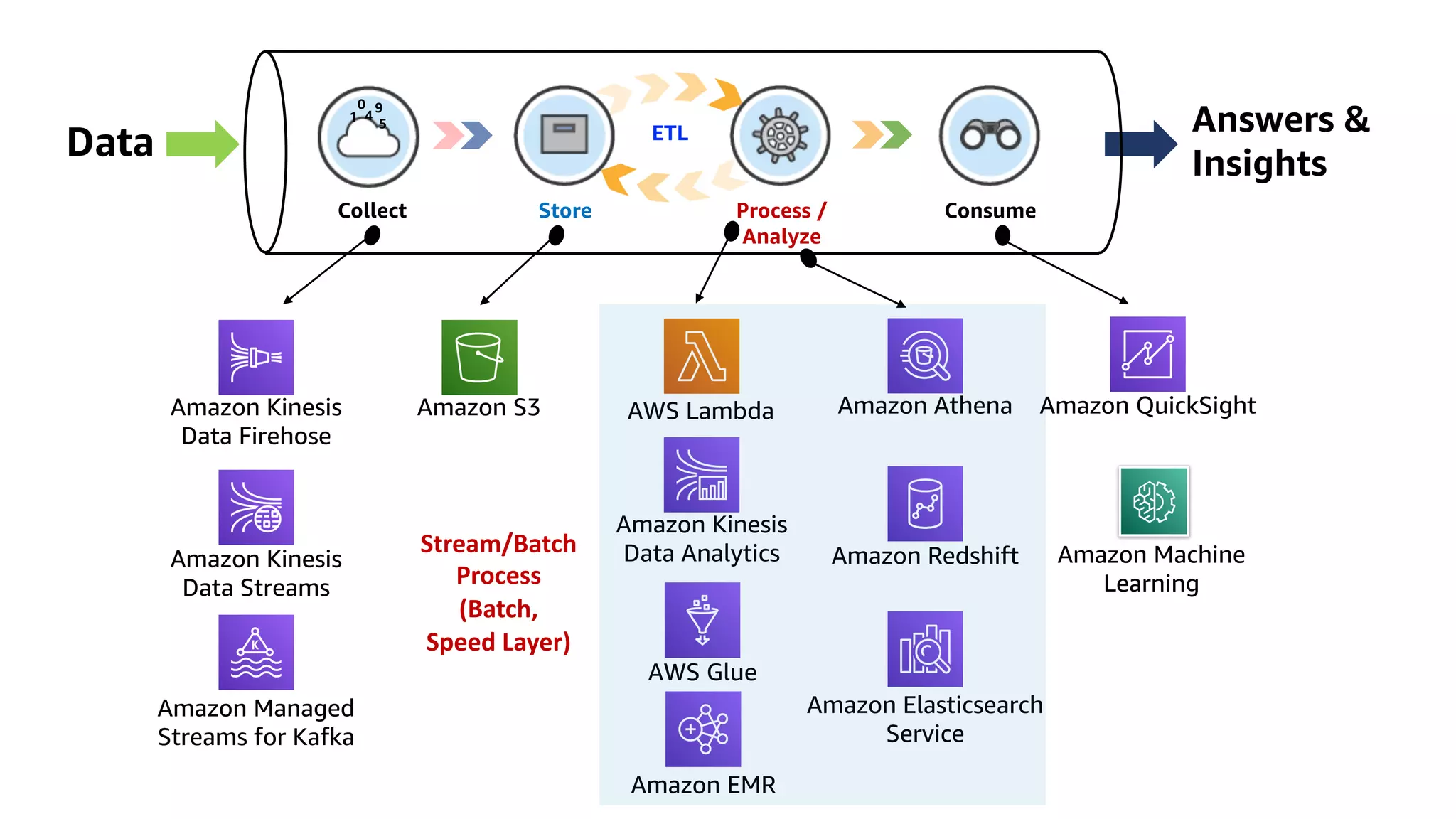
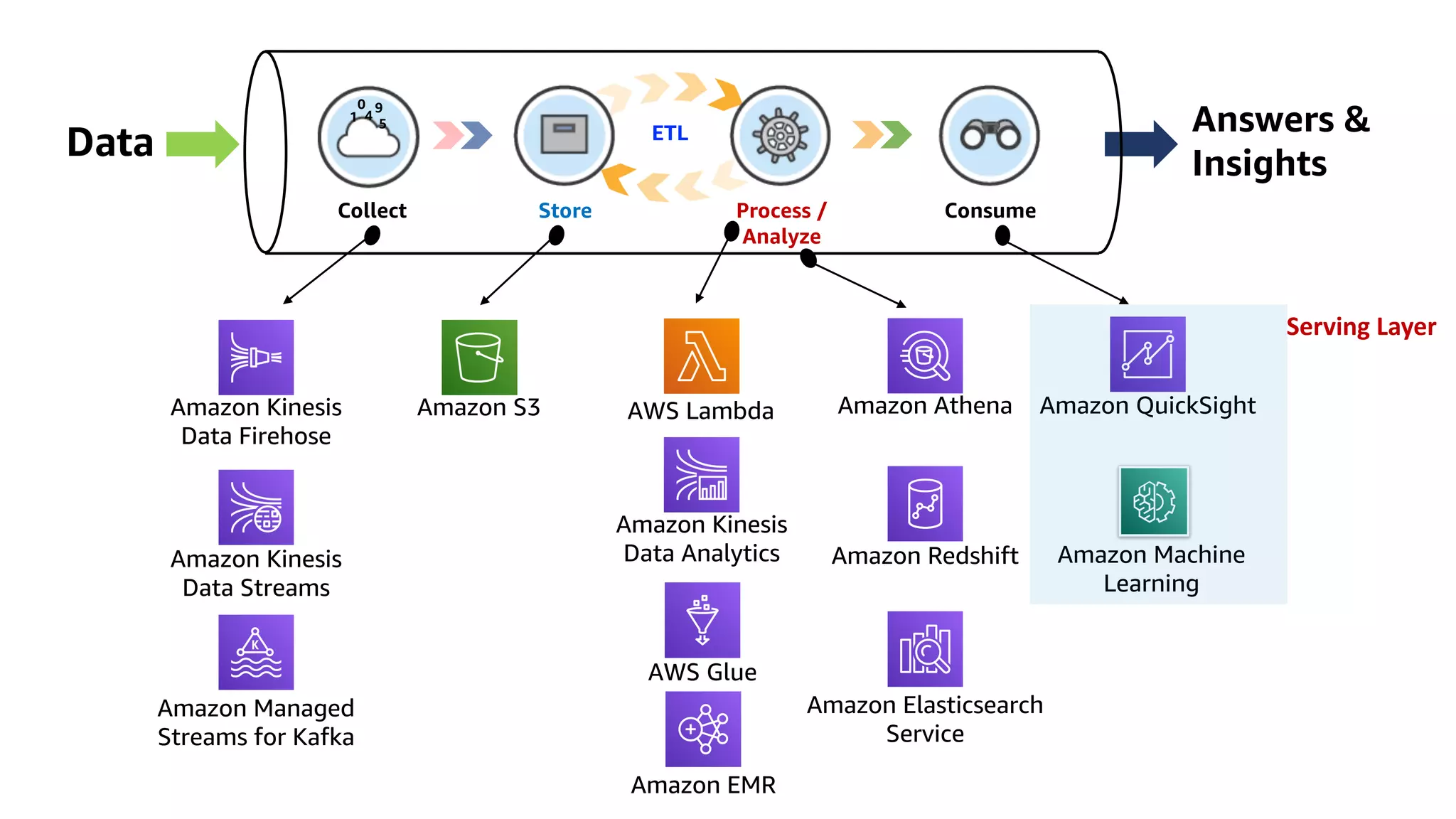
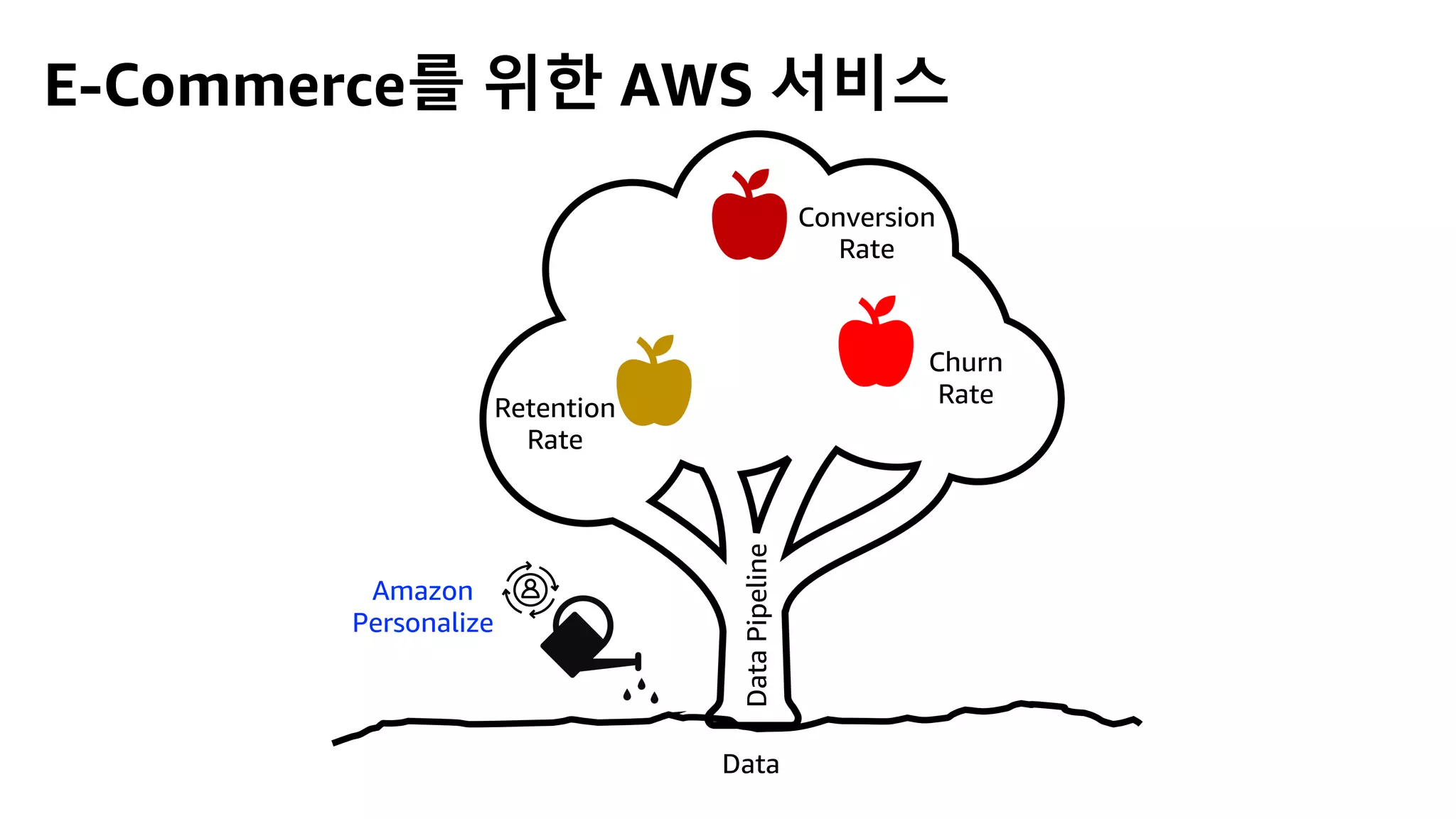
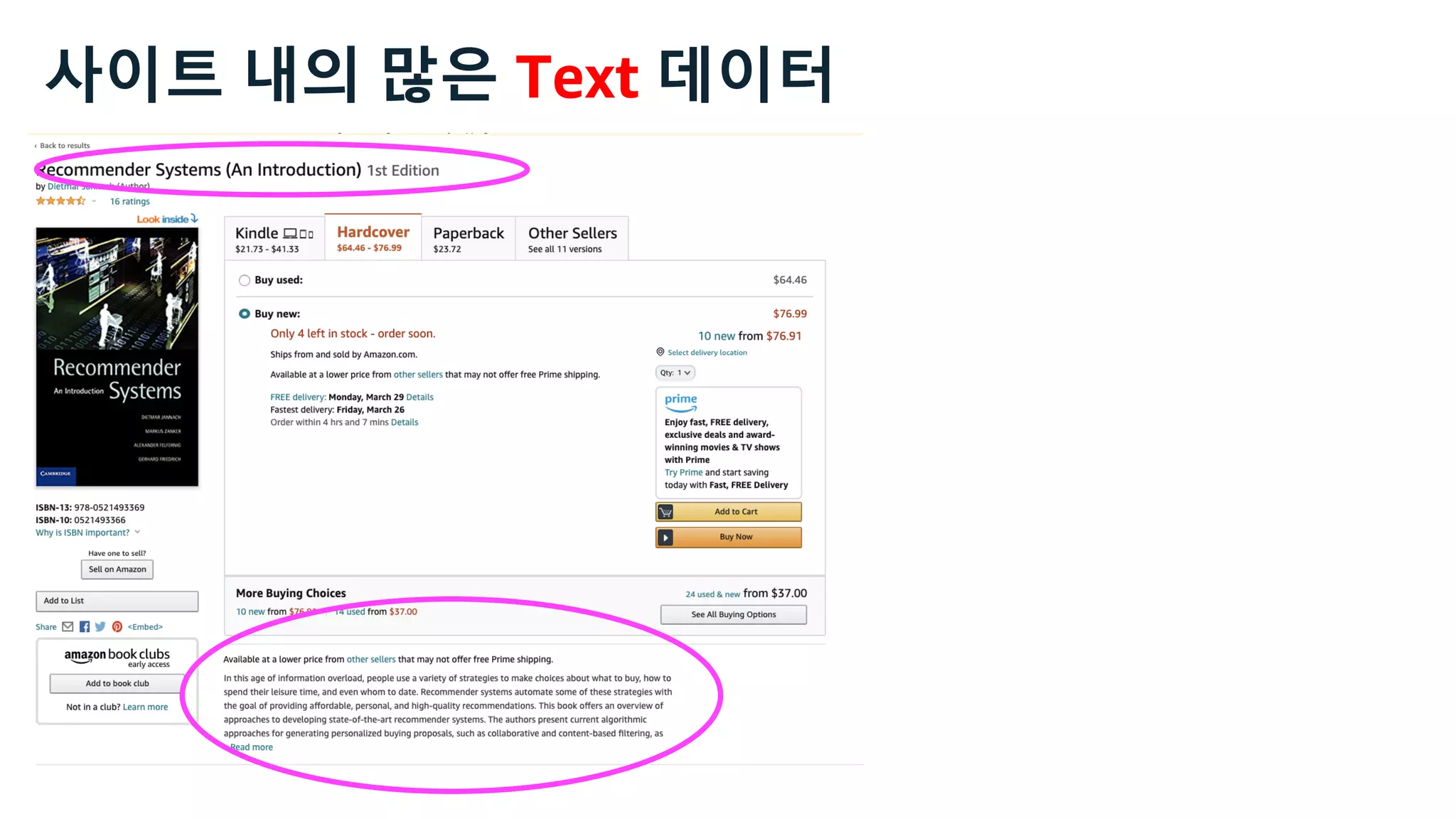
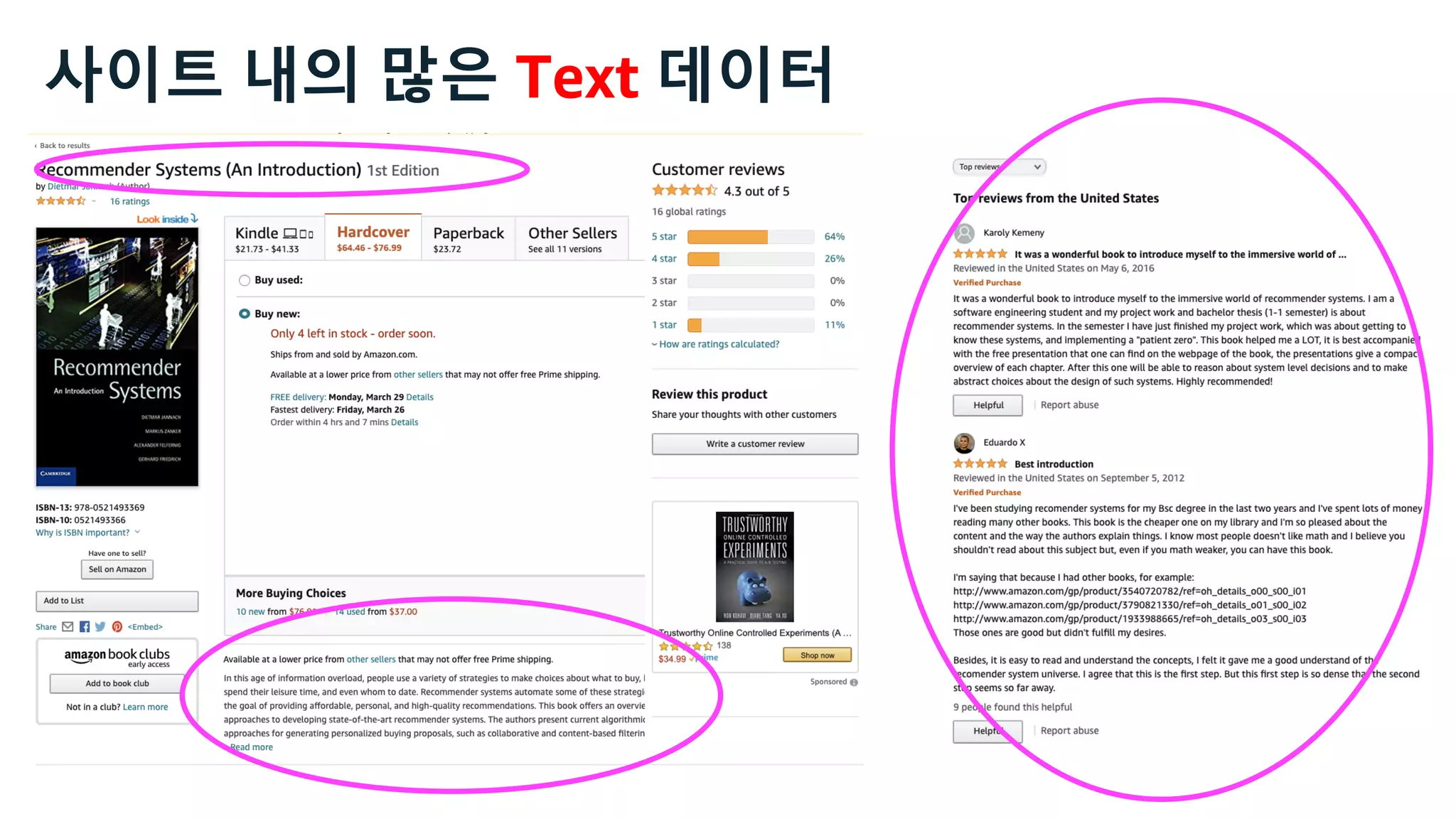
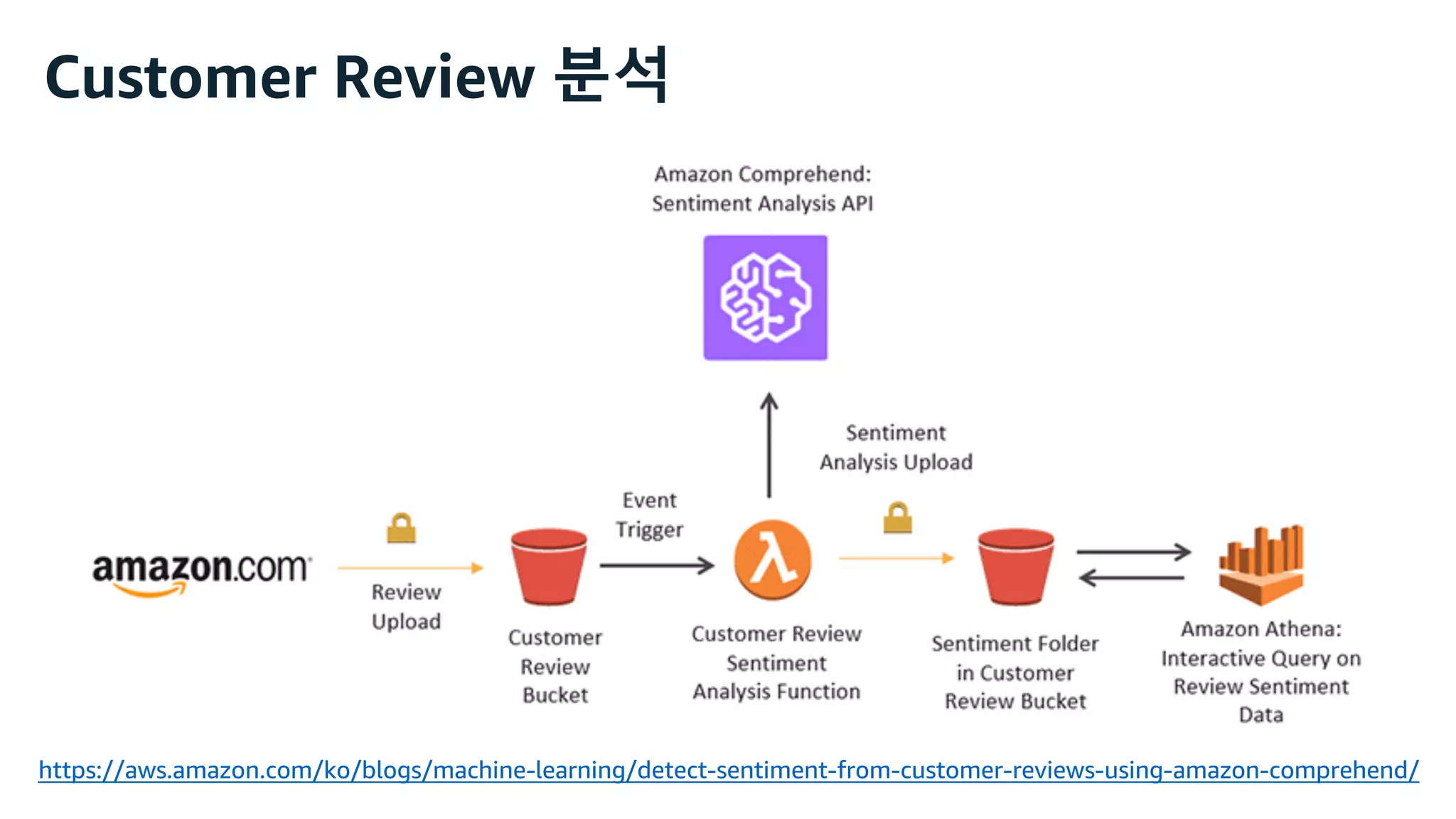
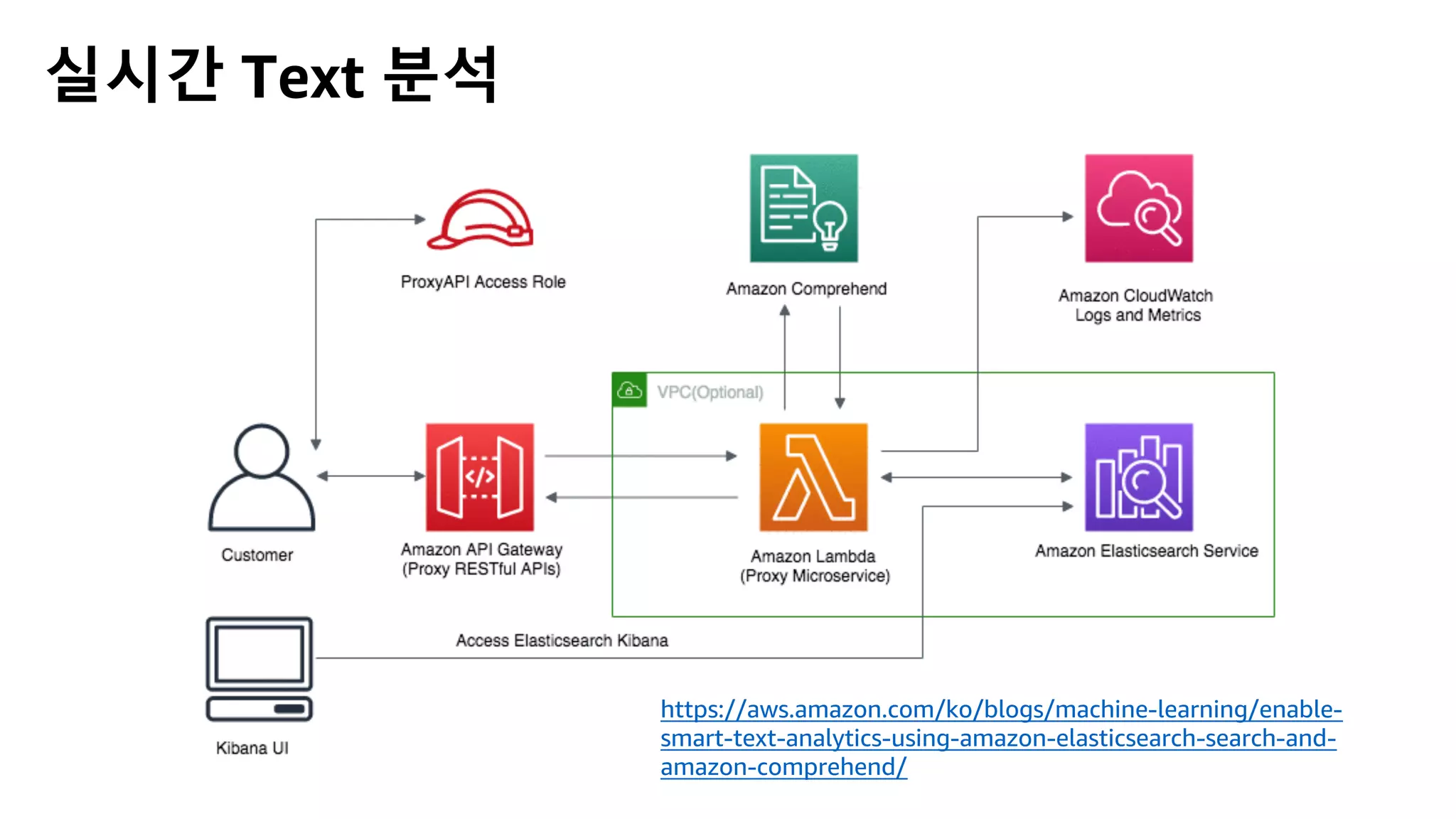
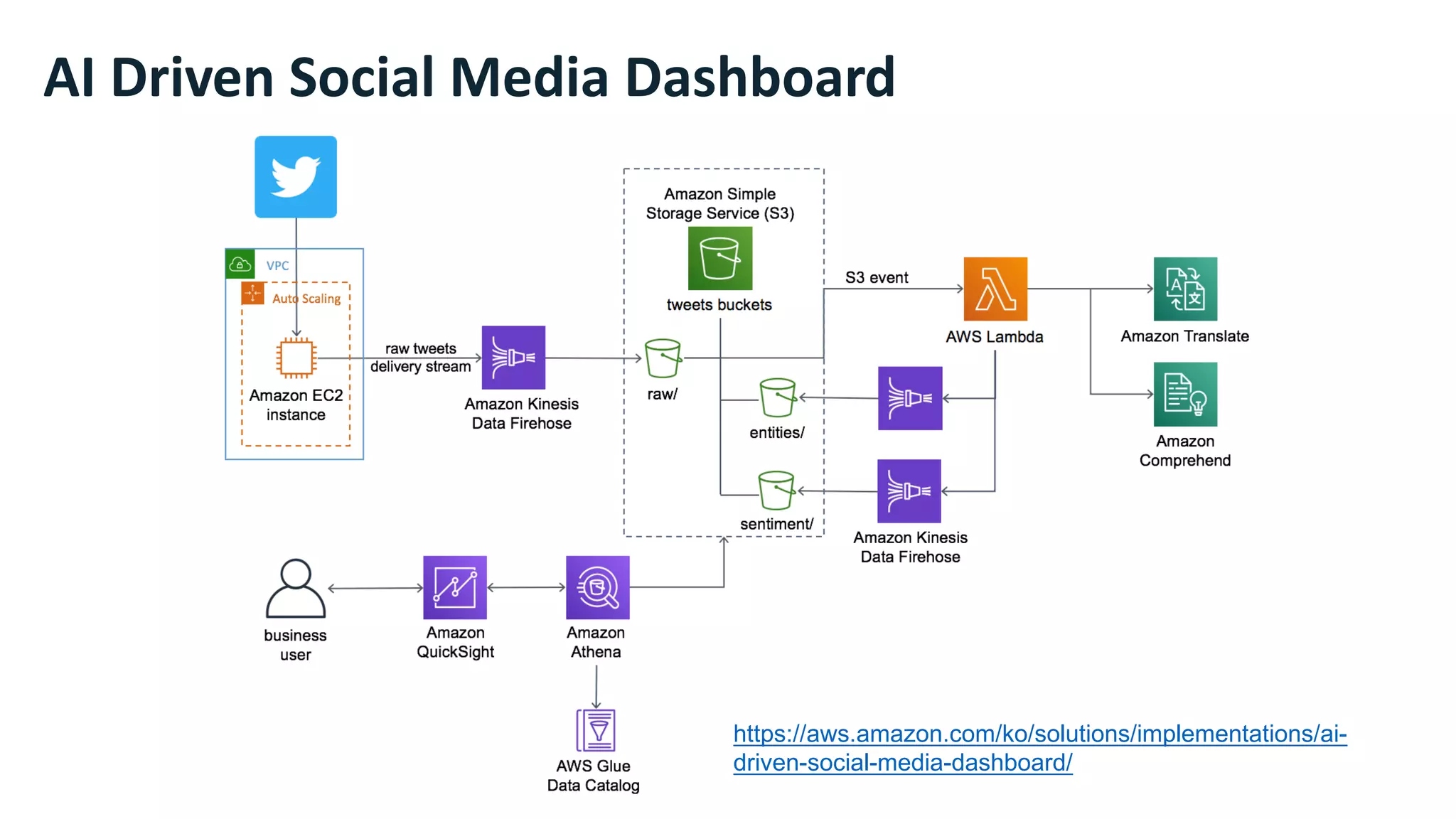
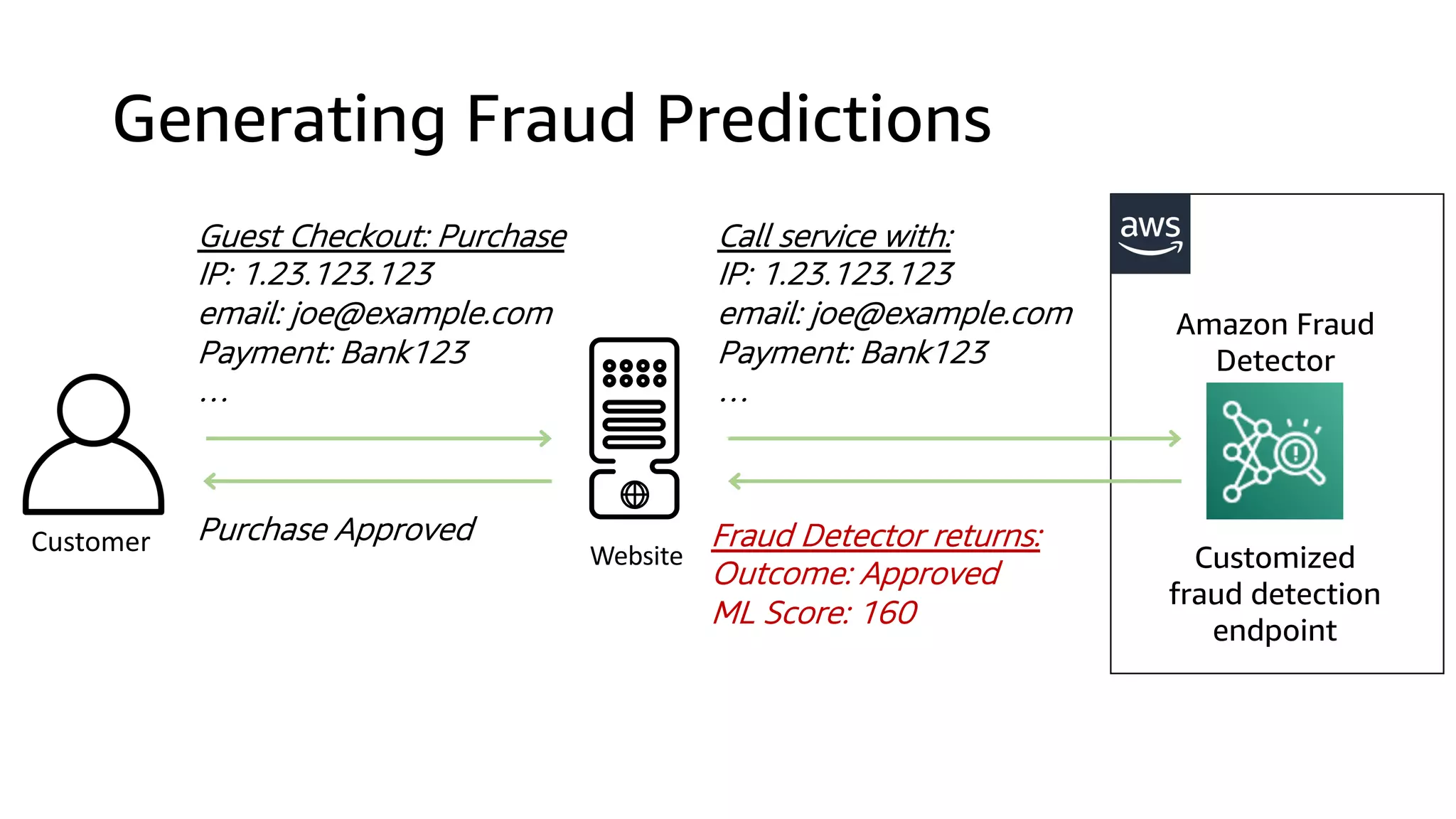
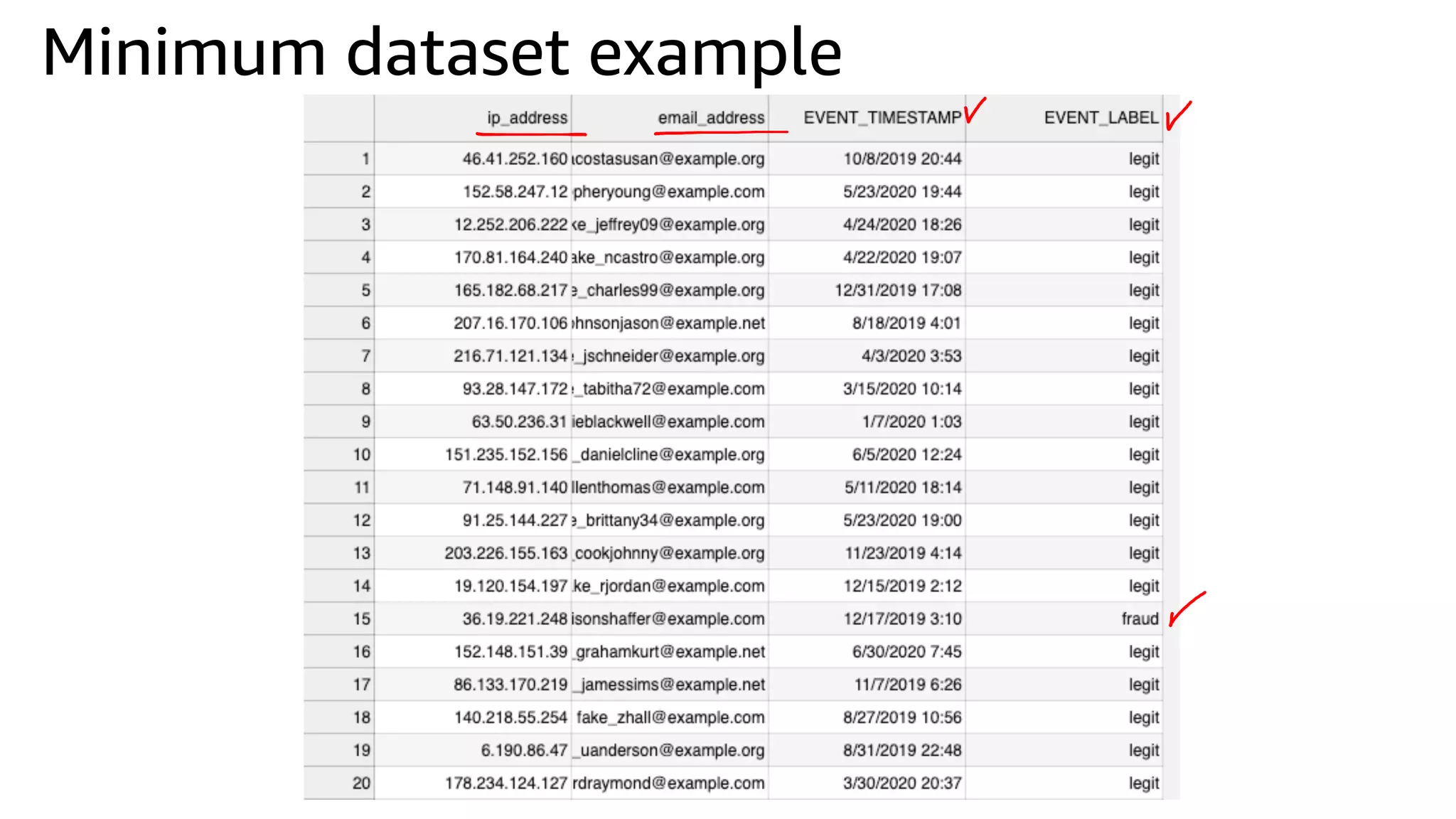
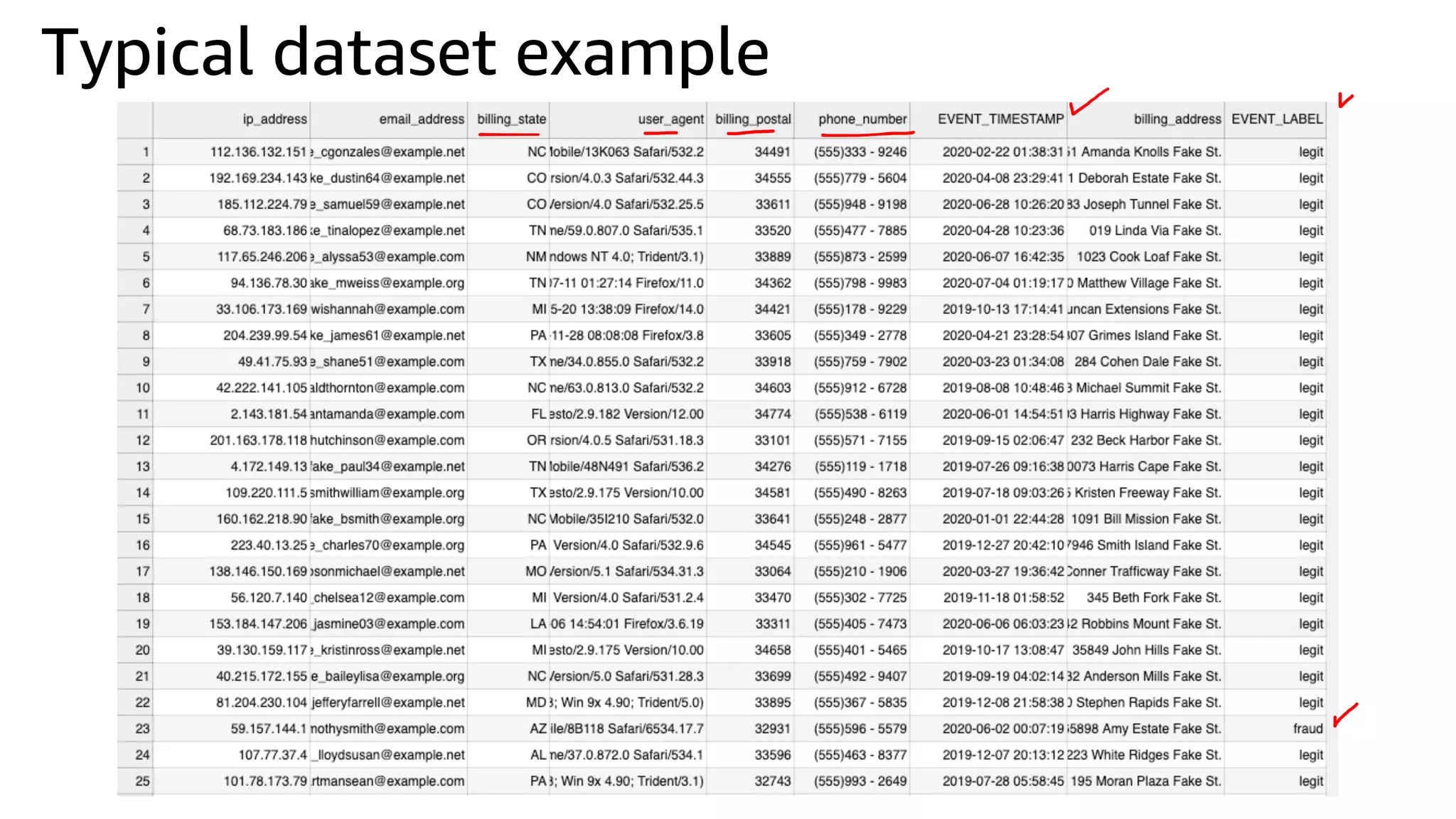
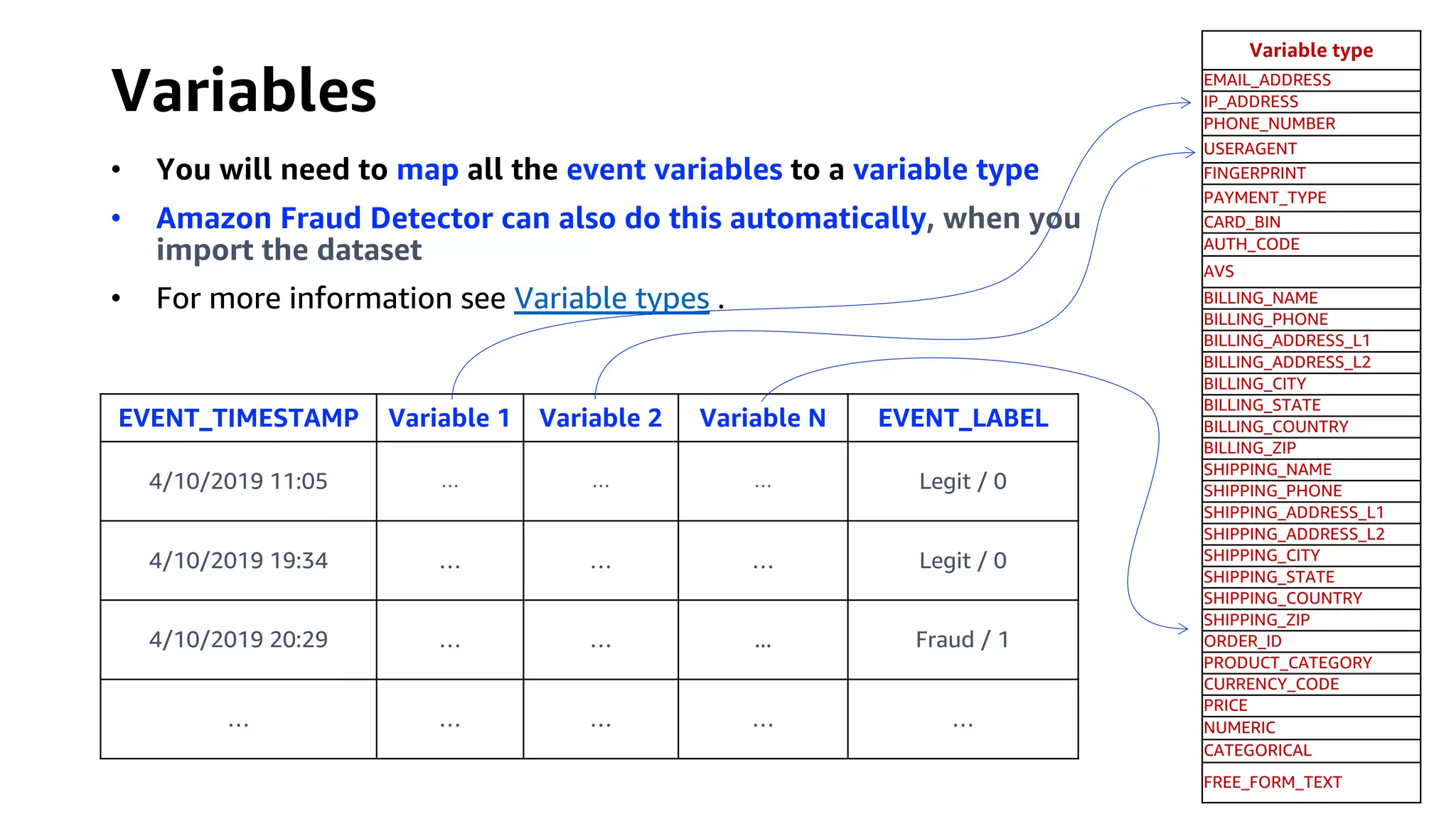
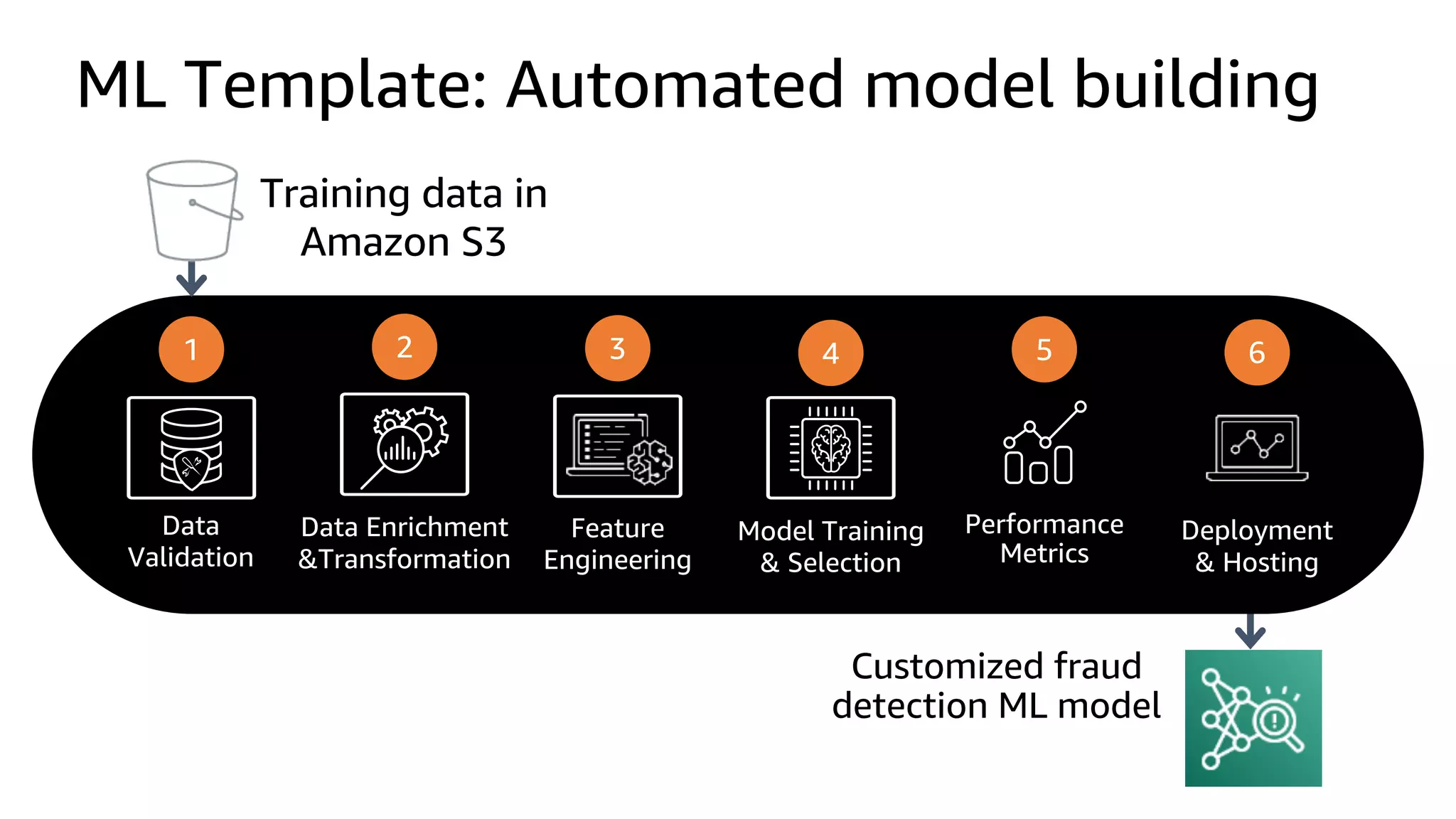
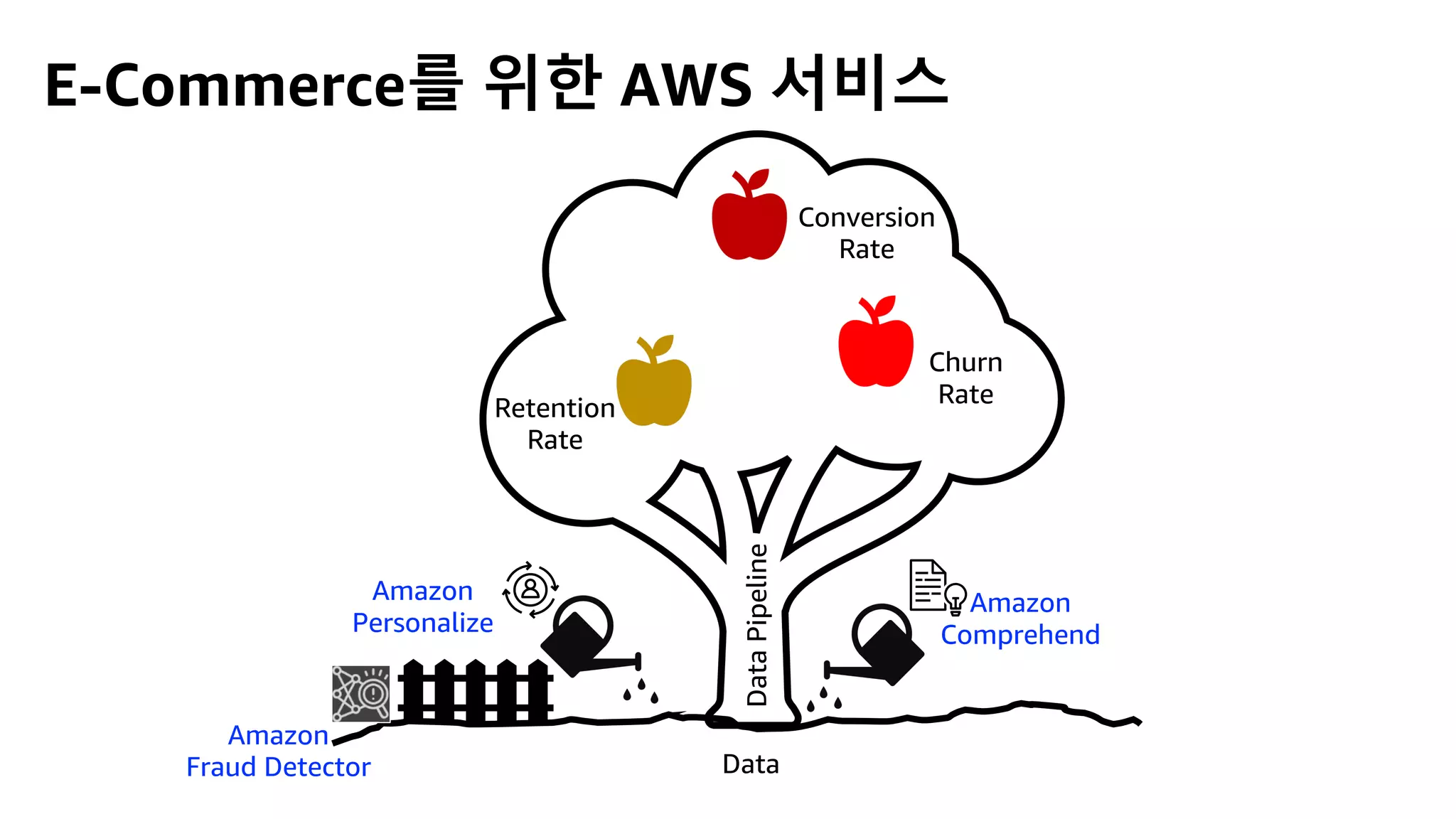
This document discusses the principles and implementation of recommendation systems, particularly focusing on Amazon Personalize. It highlights the importance of recommendations in e-commerce metrics like retention and conversion rates, and details the necessary data formats and architectures for effectively utilizing Amazon's machine learning services. The content also covers various algorithms, real-time event processing, and methods for automating recommendation calculations and filtering outputs.







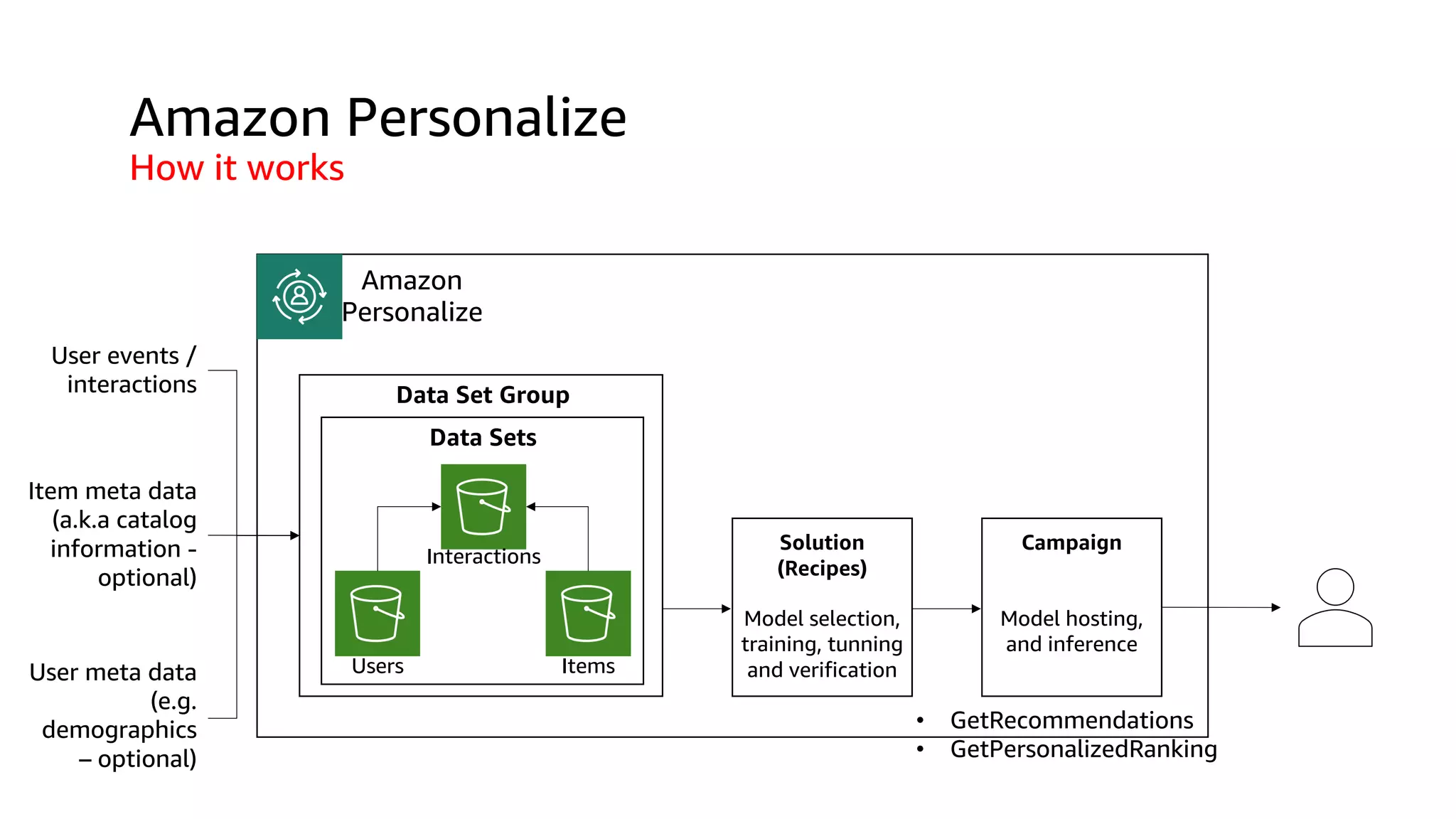


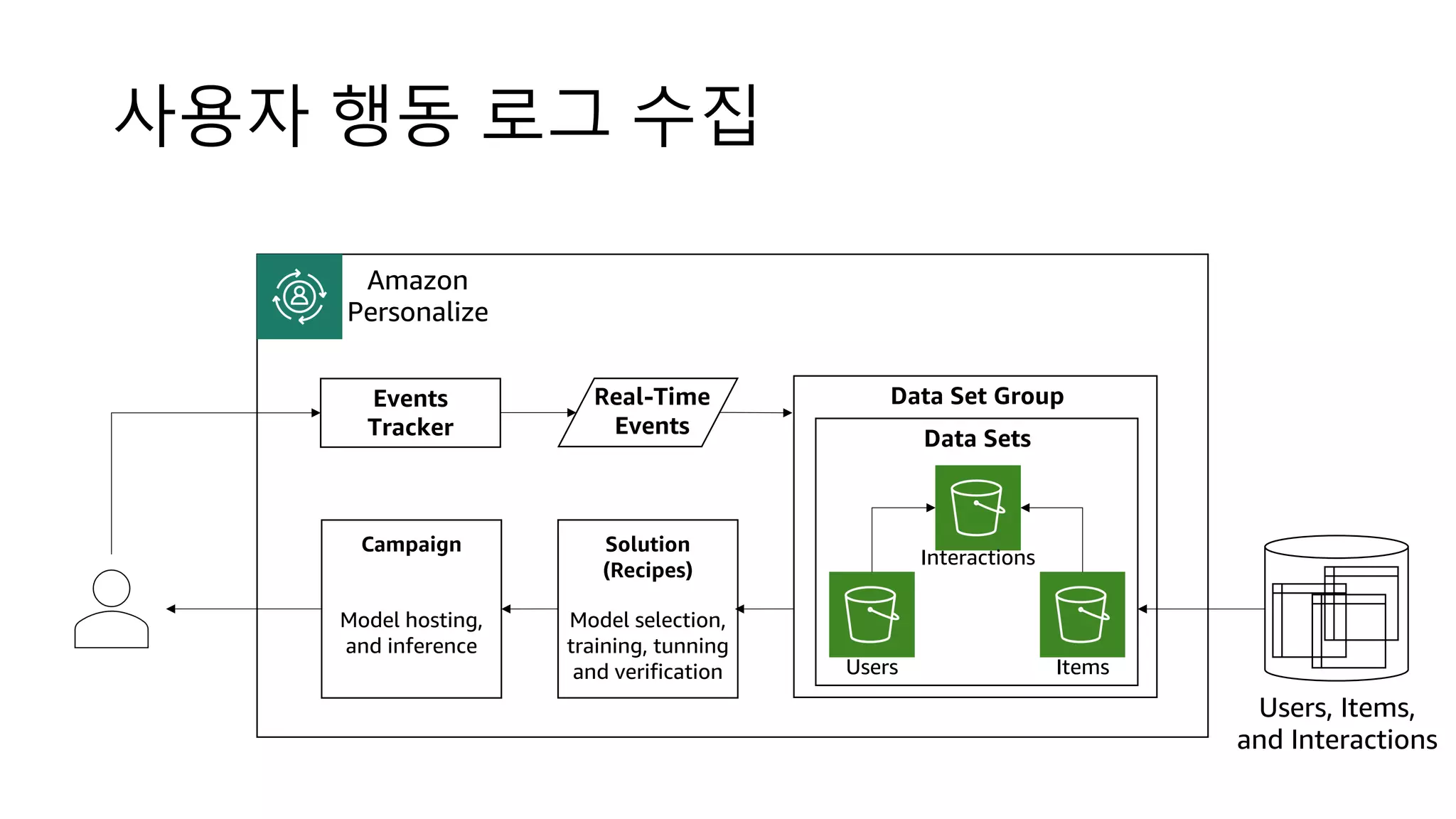
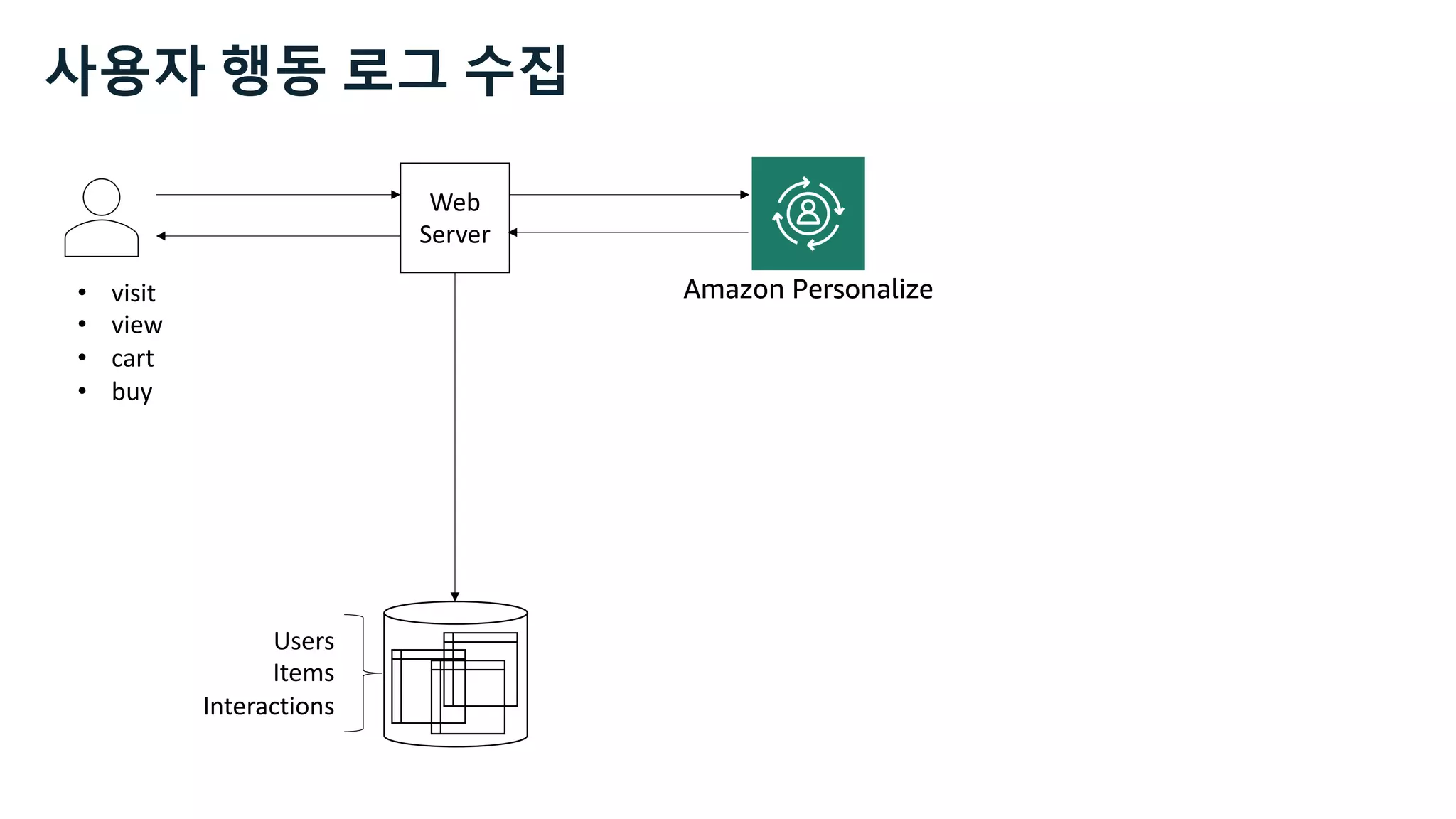
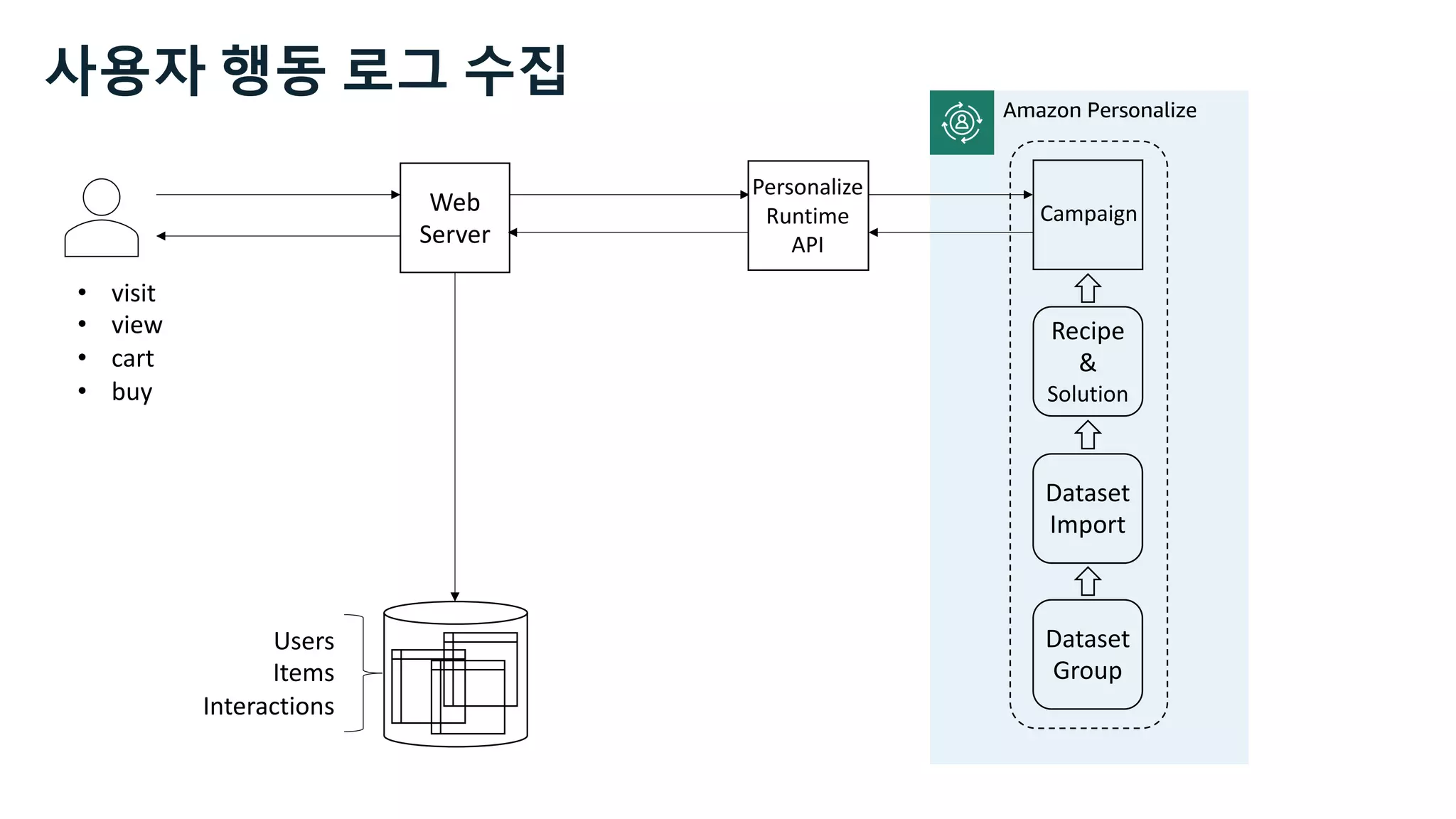
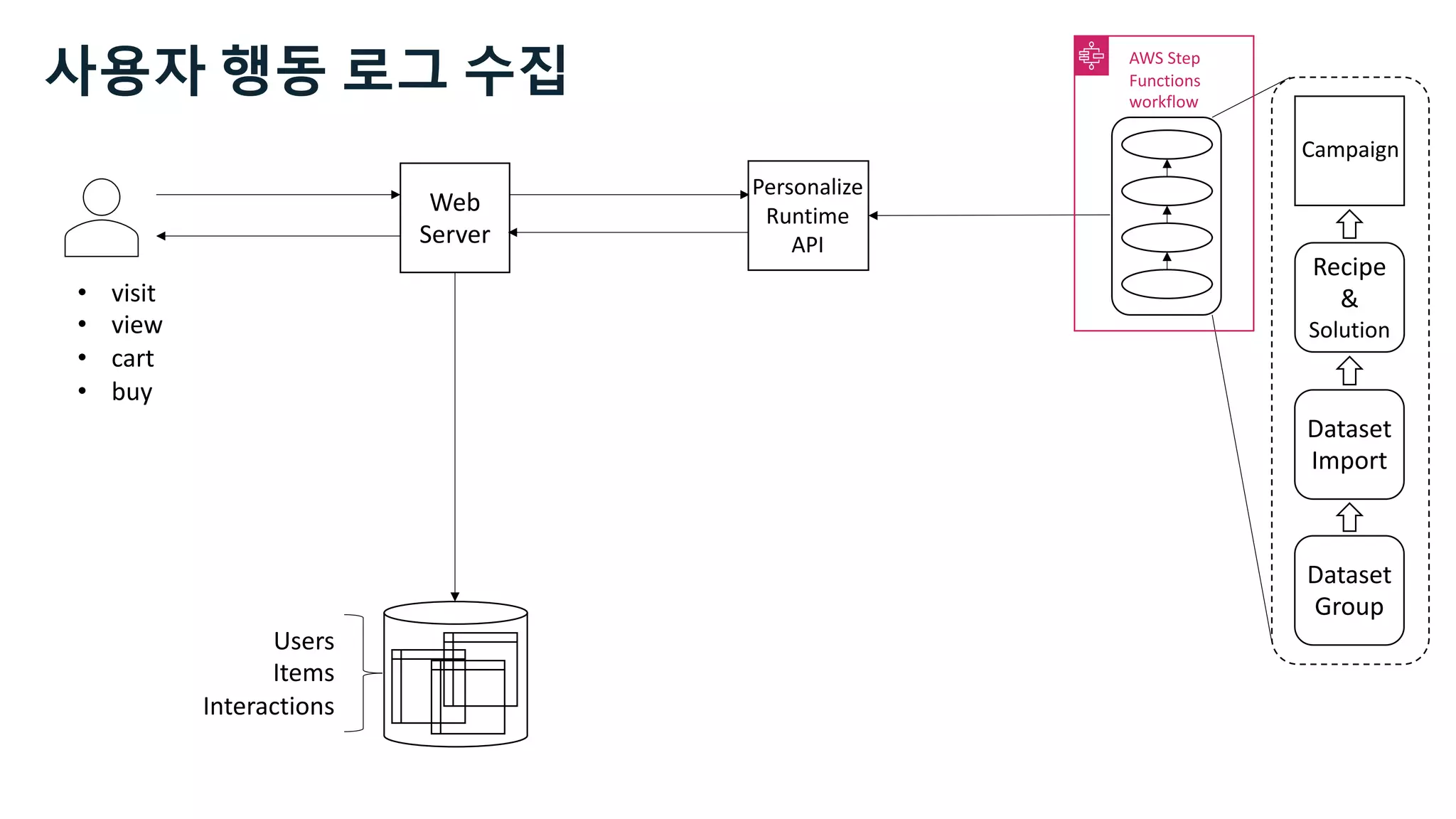
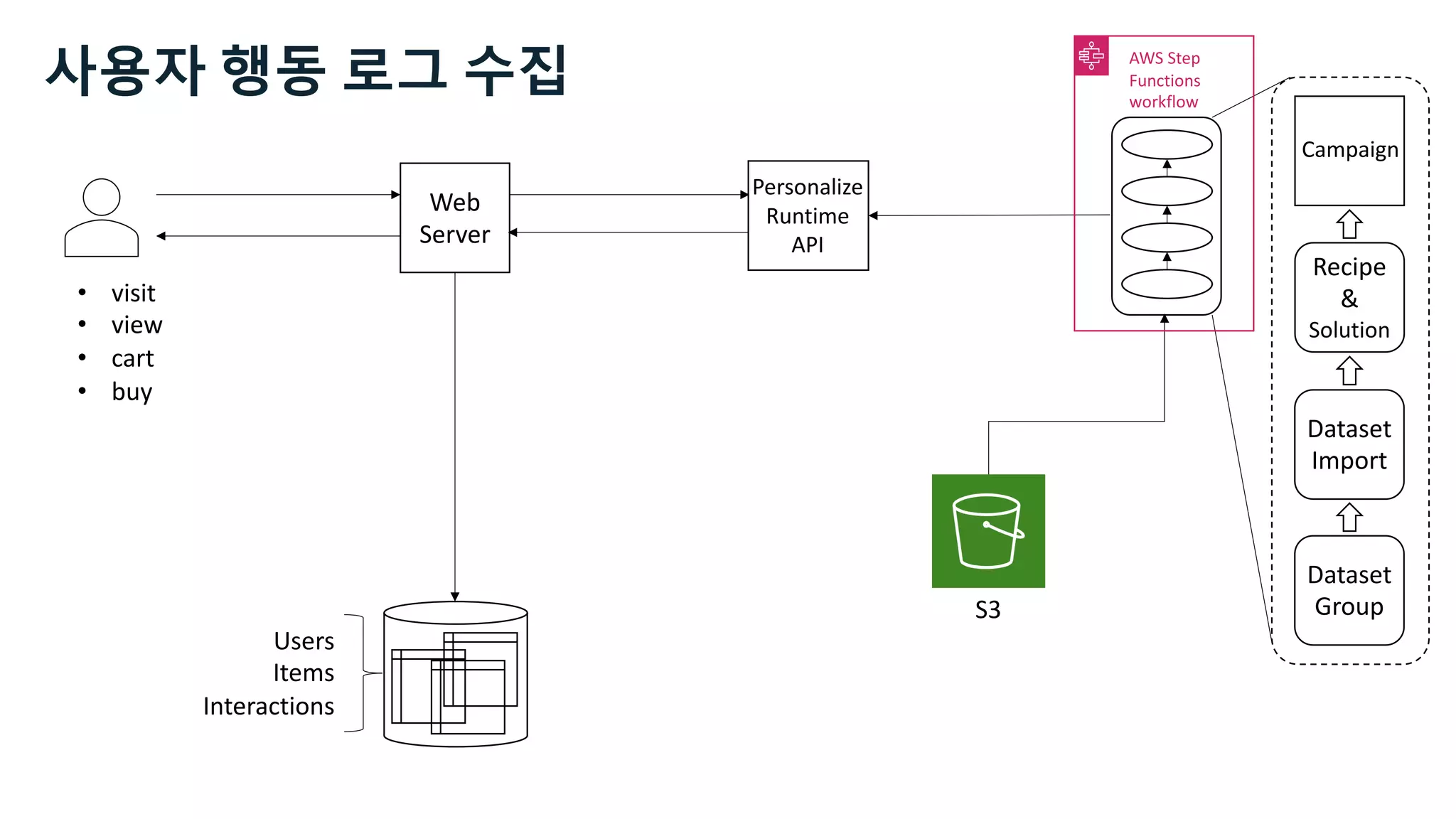
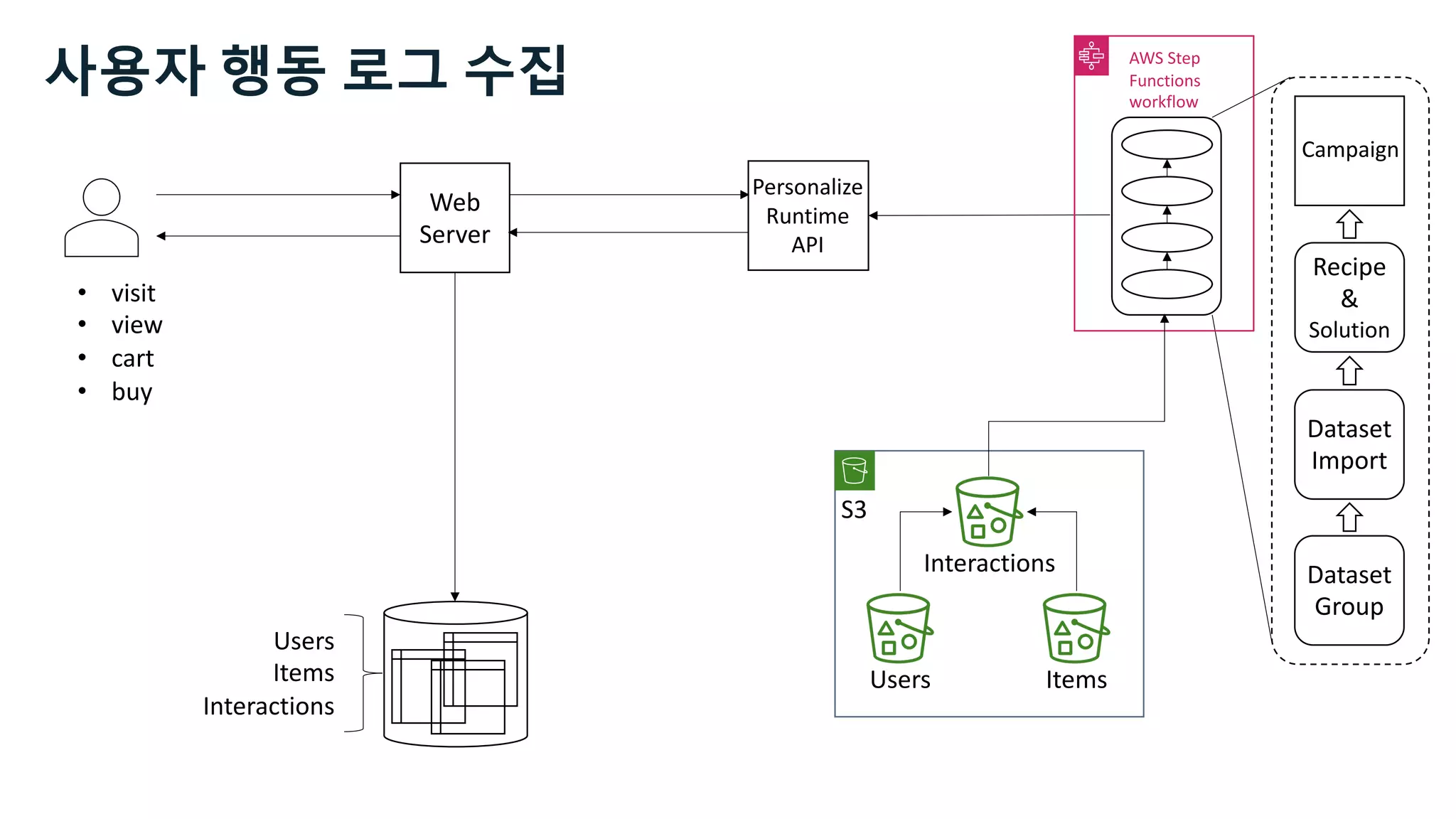
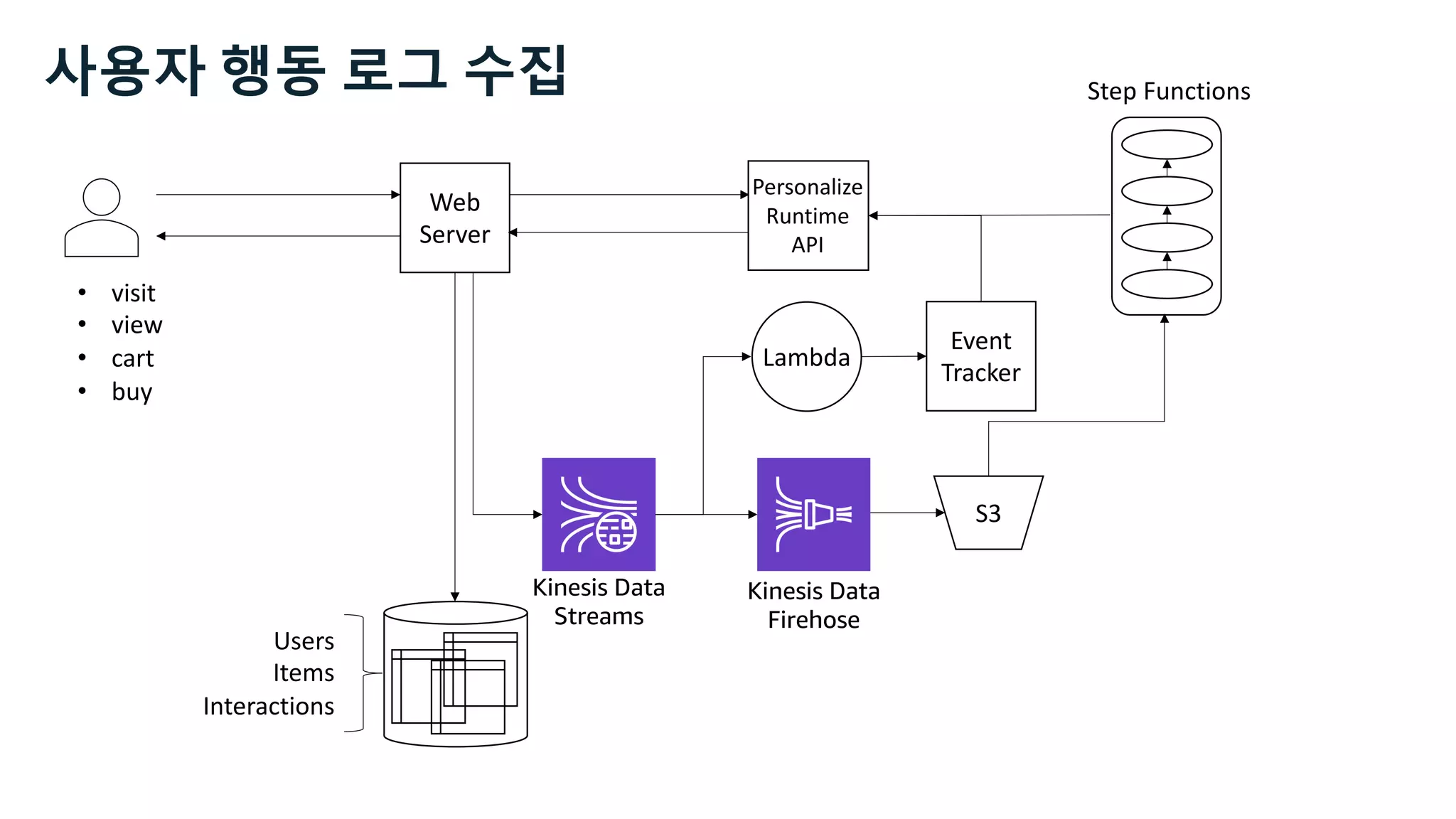
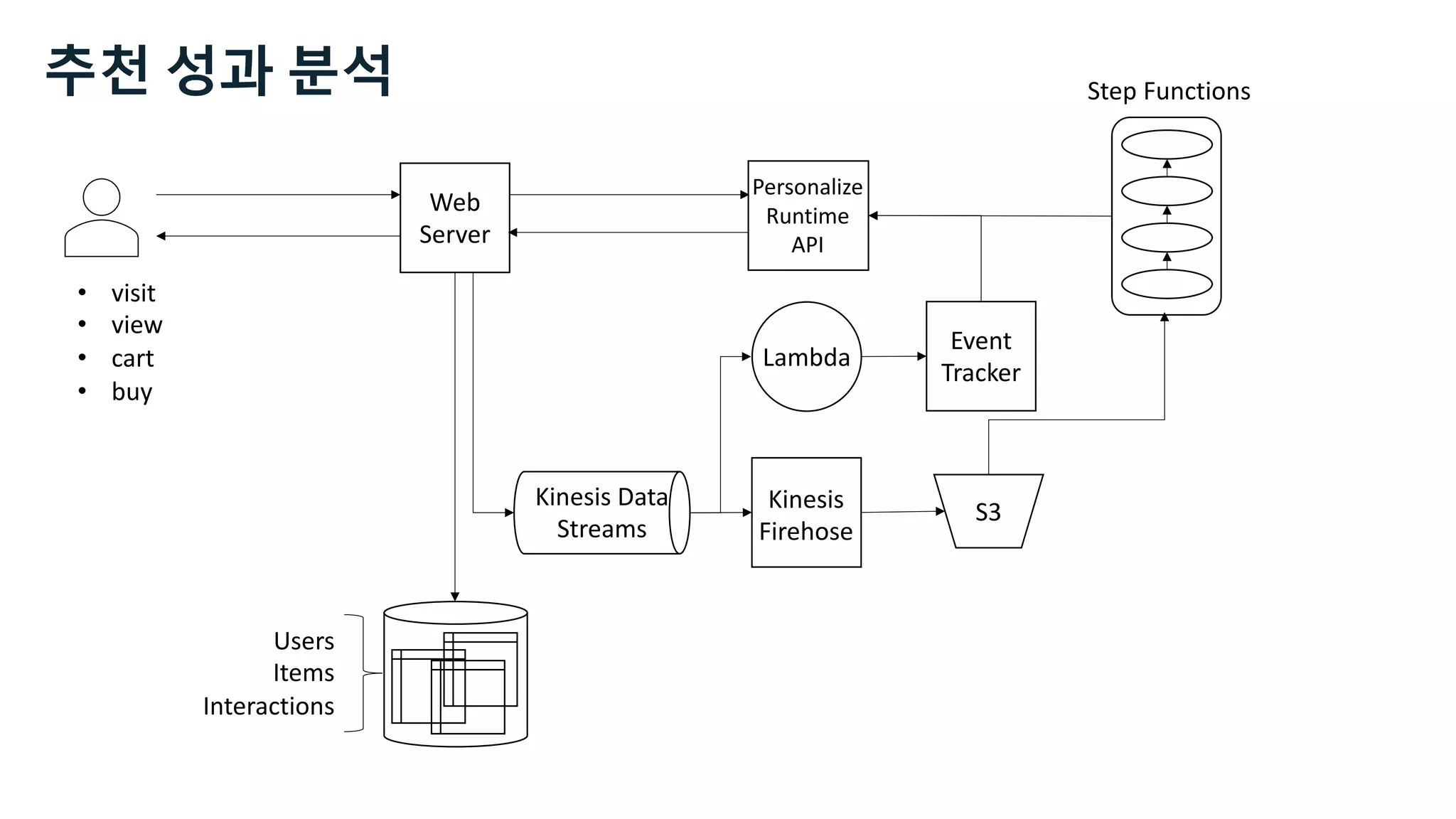
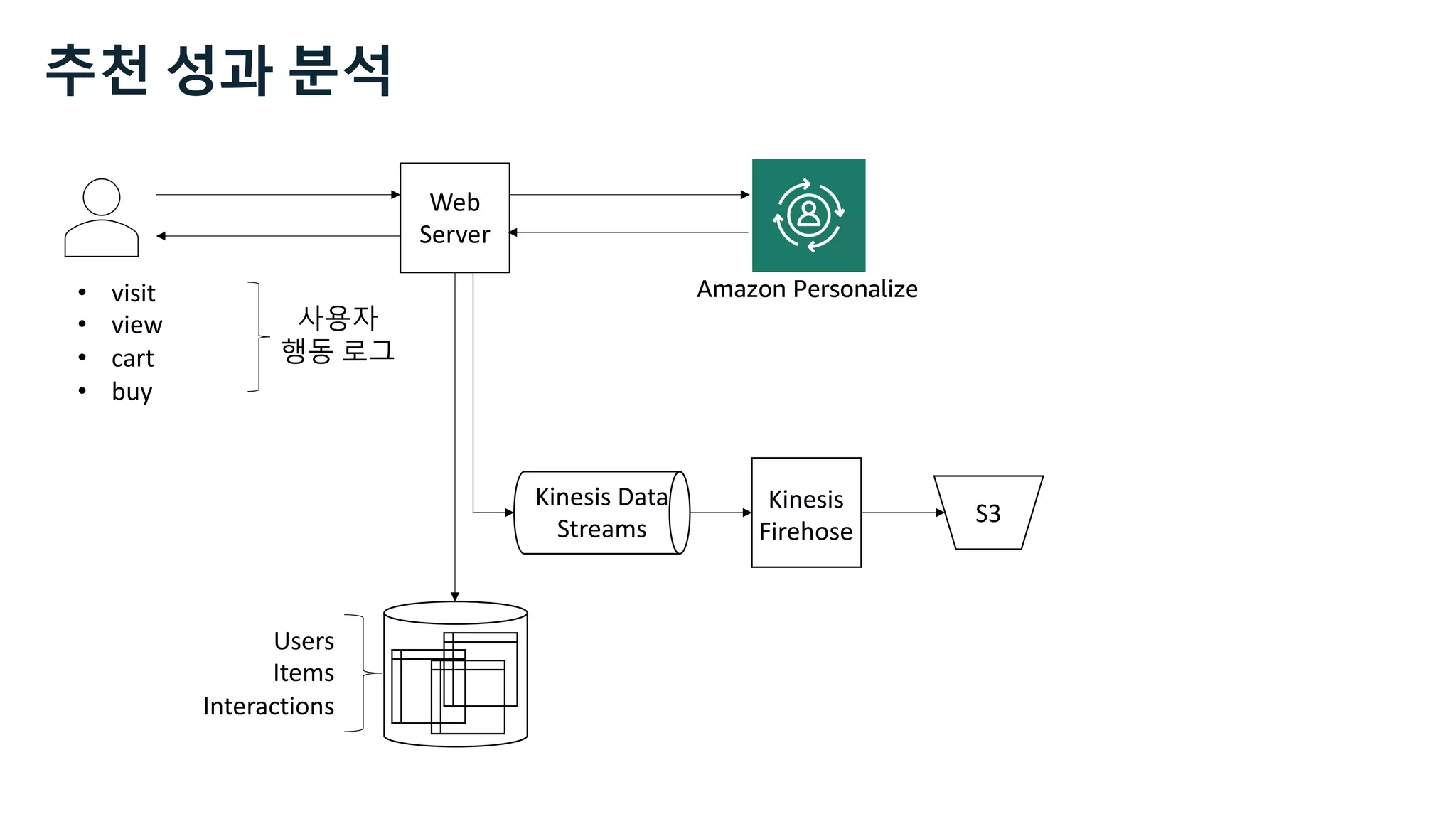
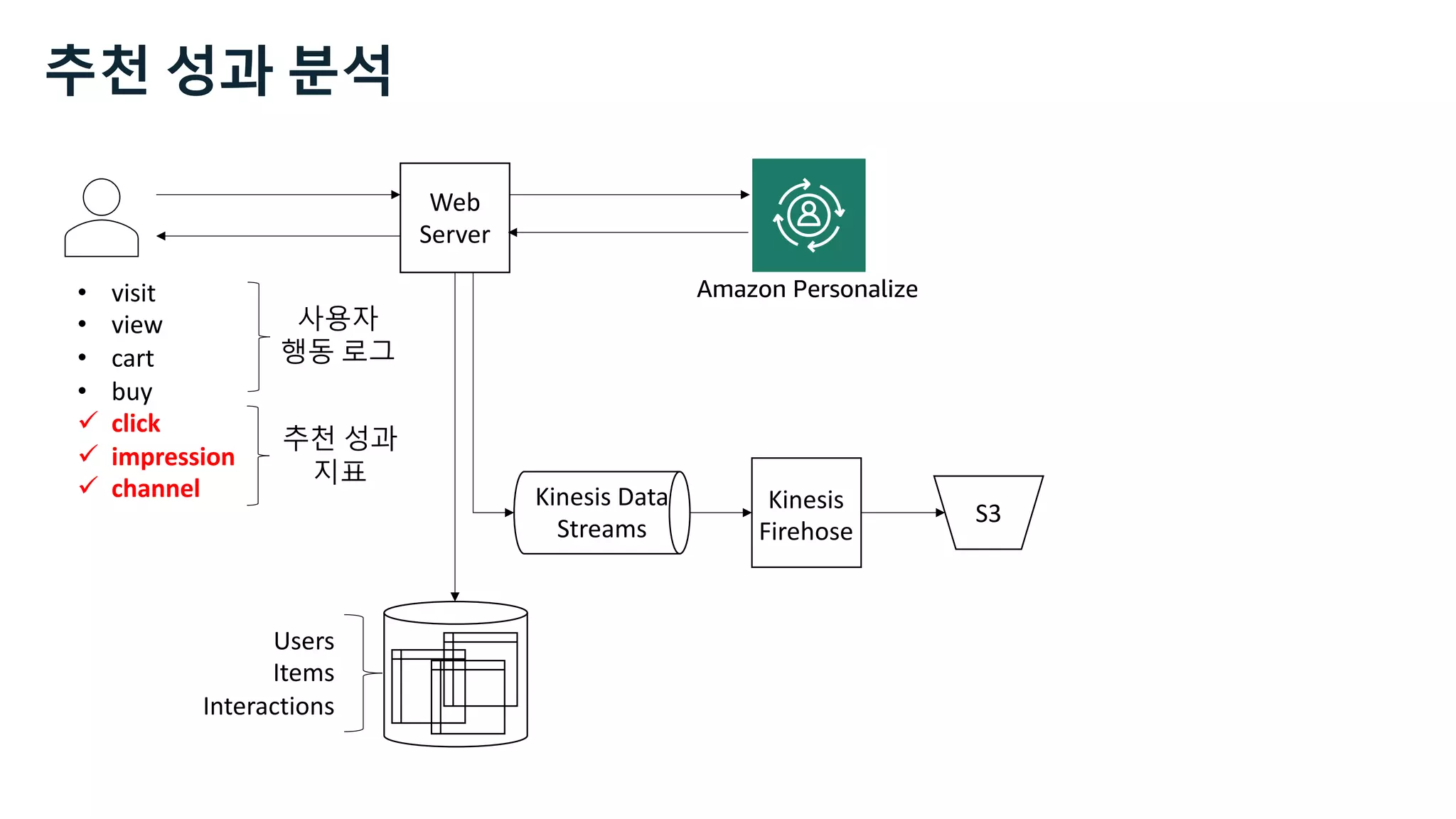
![Users Items Interactions
https://docs.aws.amazon.com/personalize/latest/dg/how-it-
works-dataset-schema.html
{
"type": "record",
"name": "Users | Items | Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "Field Name",
"type": "Data Type"
},
….
],
"version": "1.0"
}](https://image.slidesharecdn.com/aws-personalize-for-e-commerce-20210407-210412095713/75/AWS-Personalize-19-2048.jpg)







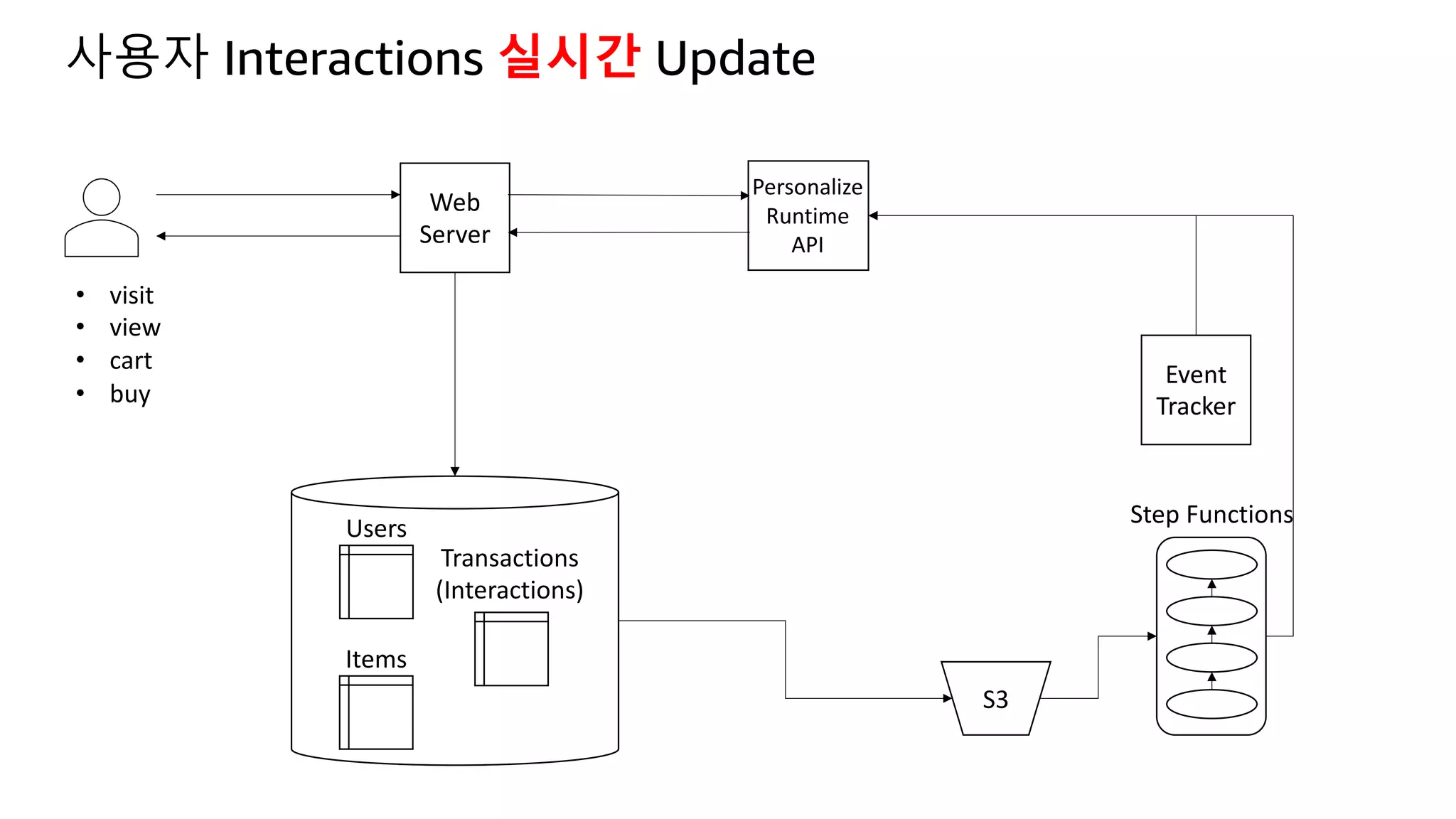
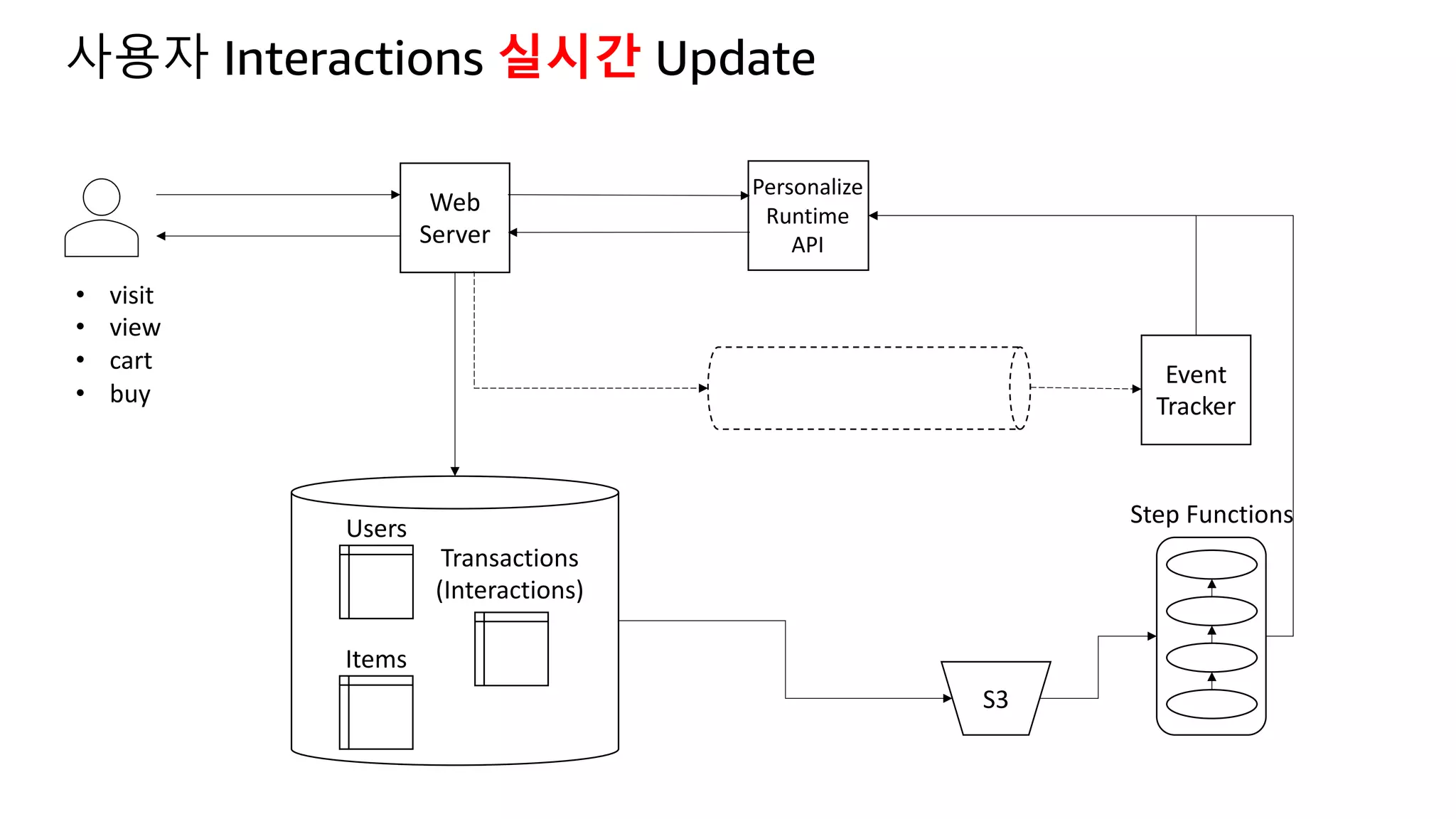
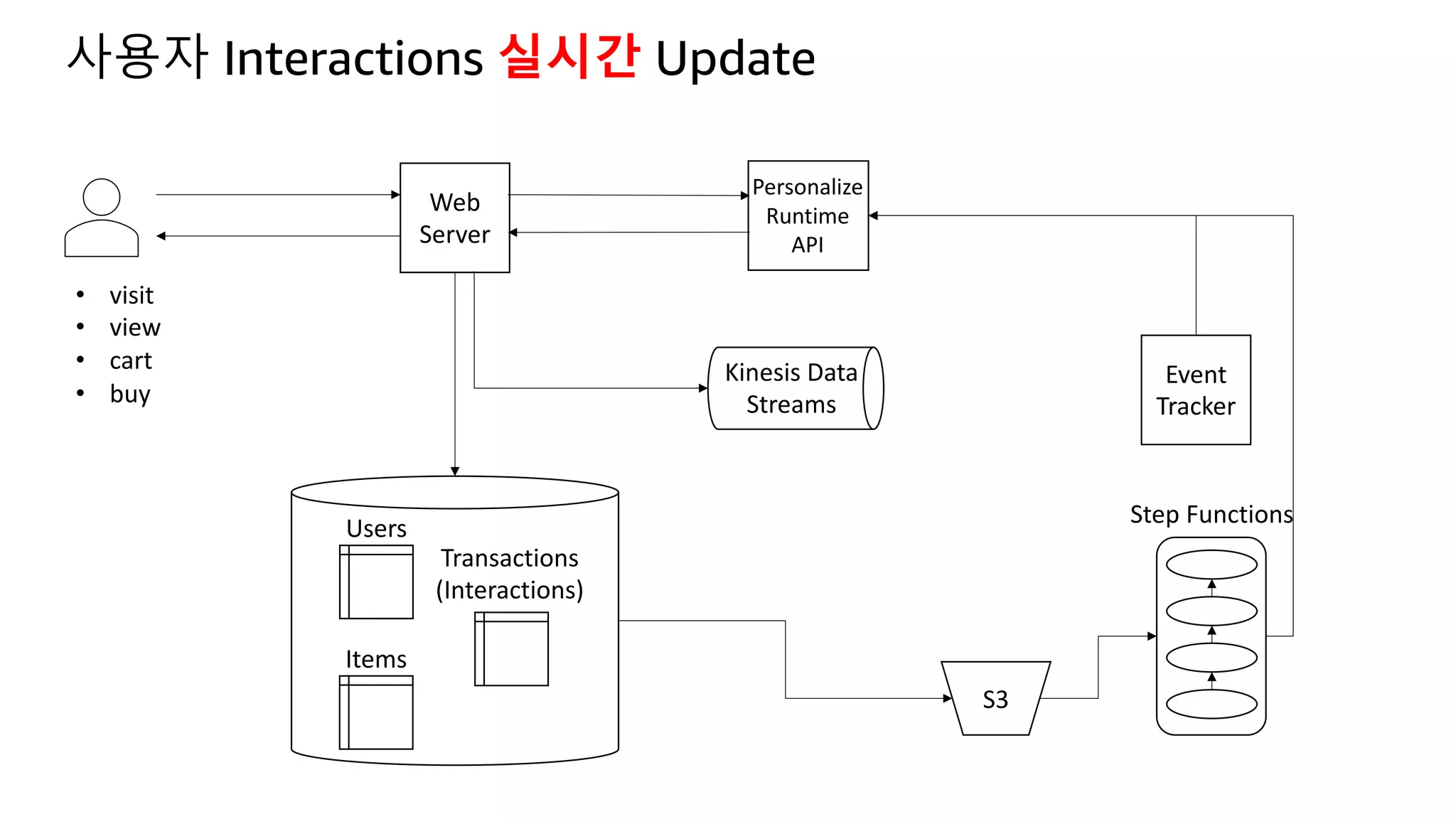
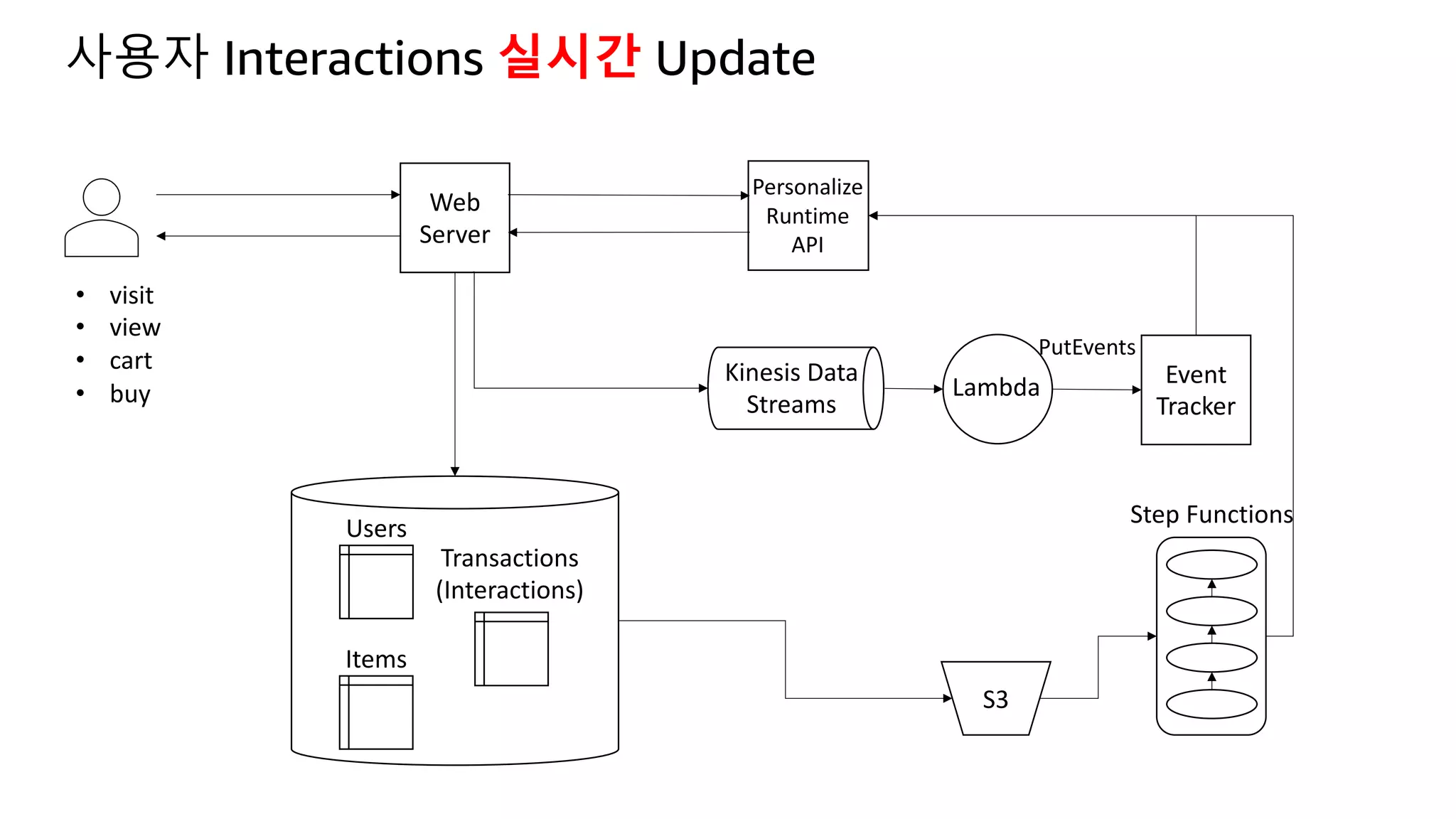
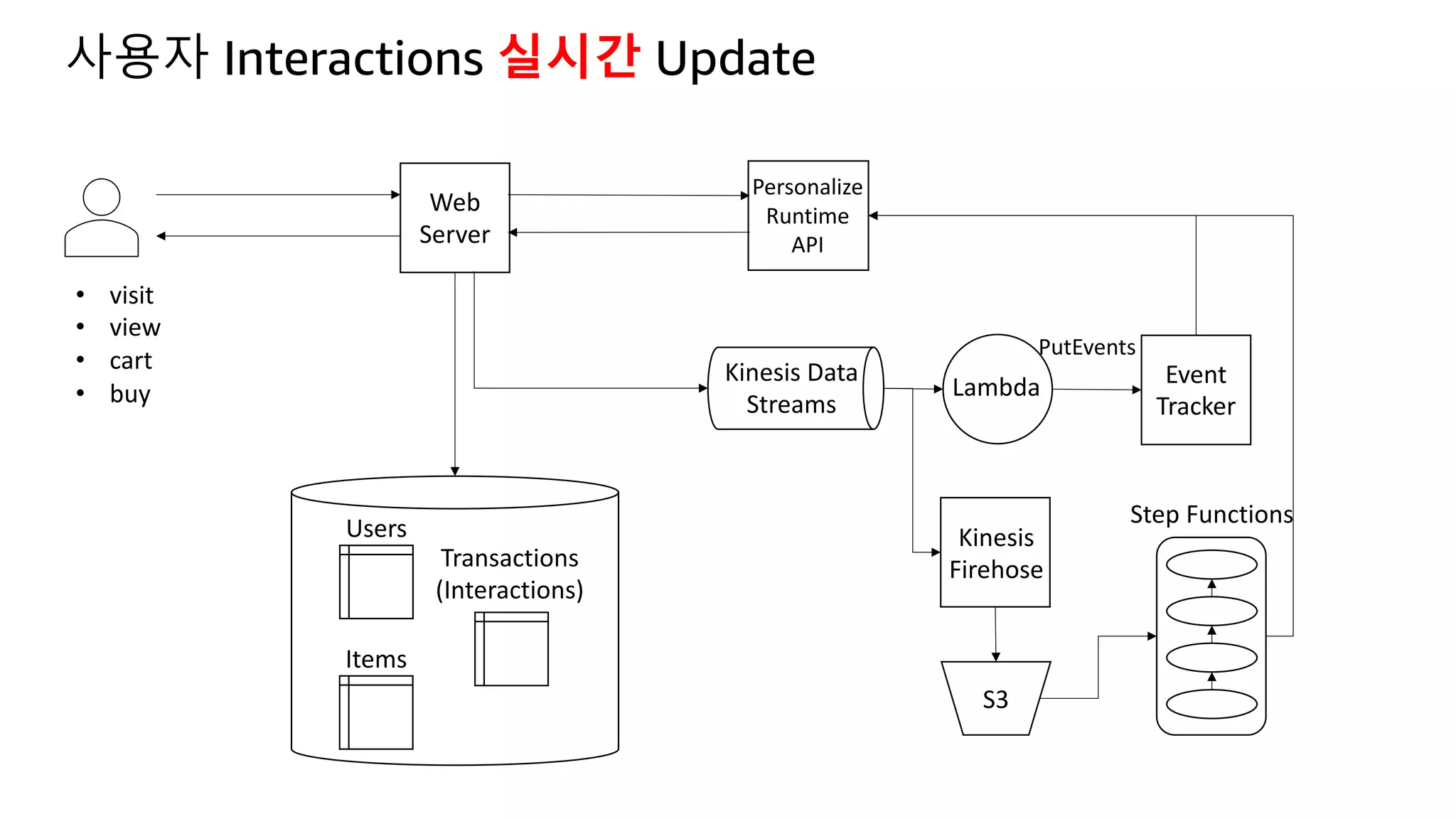
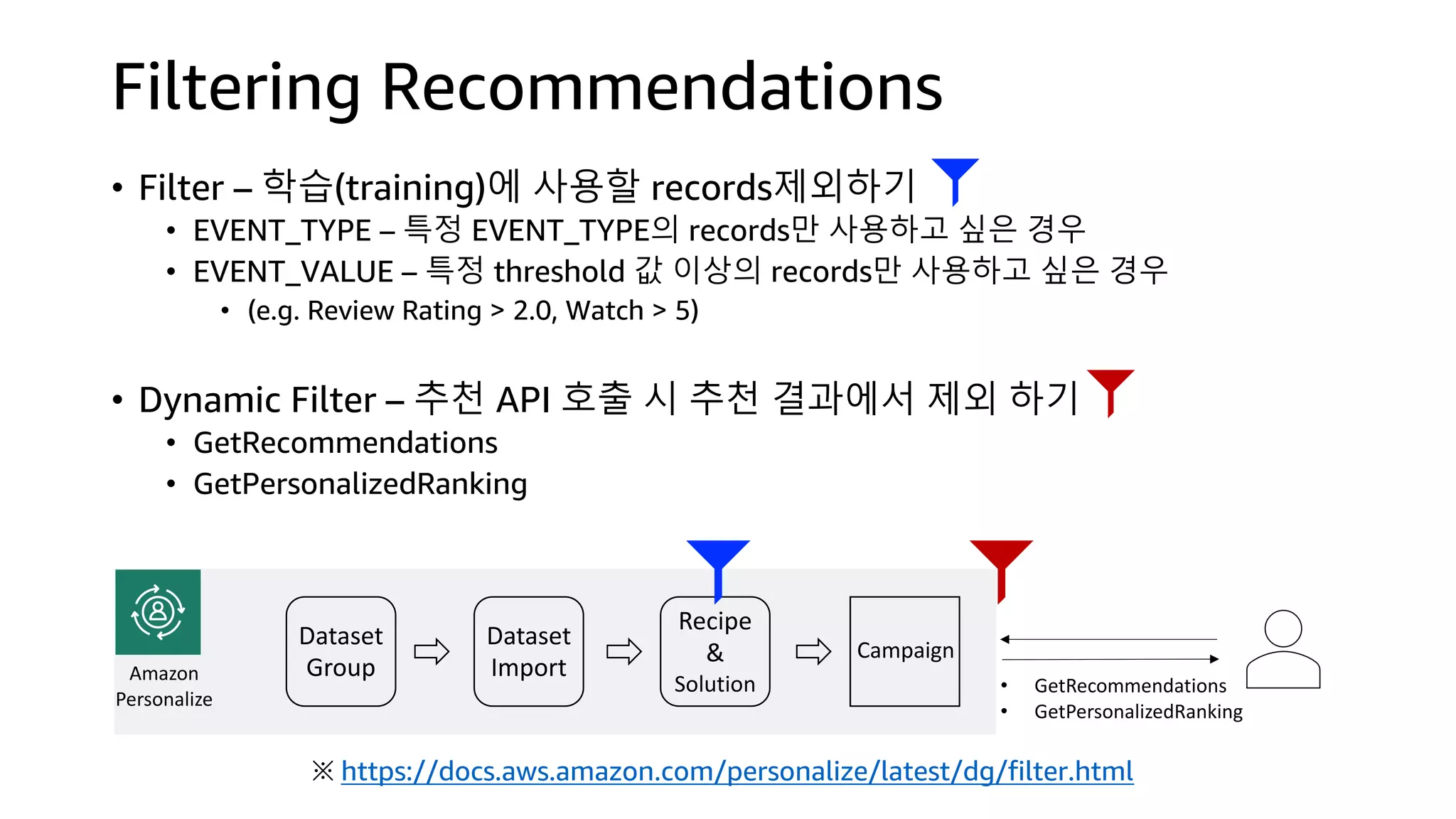

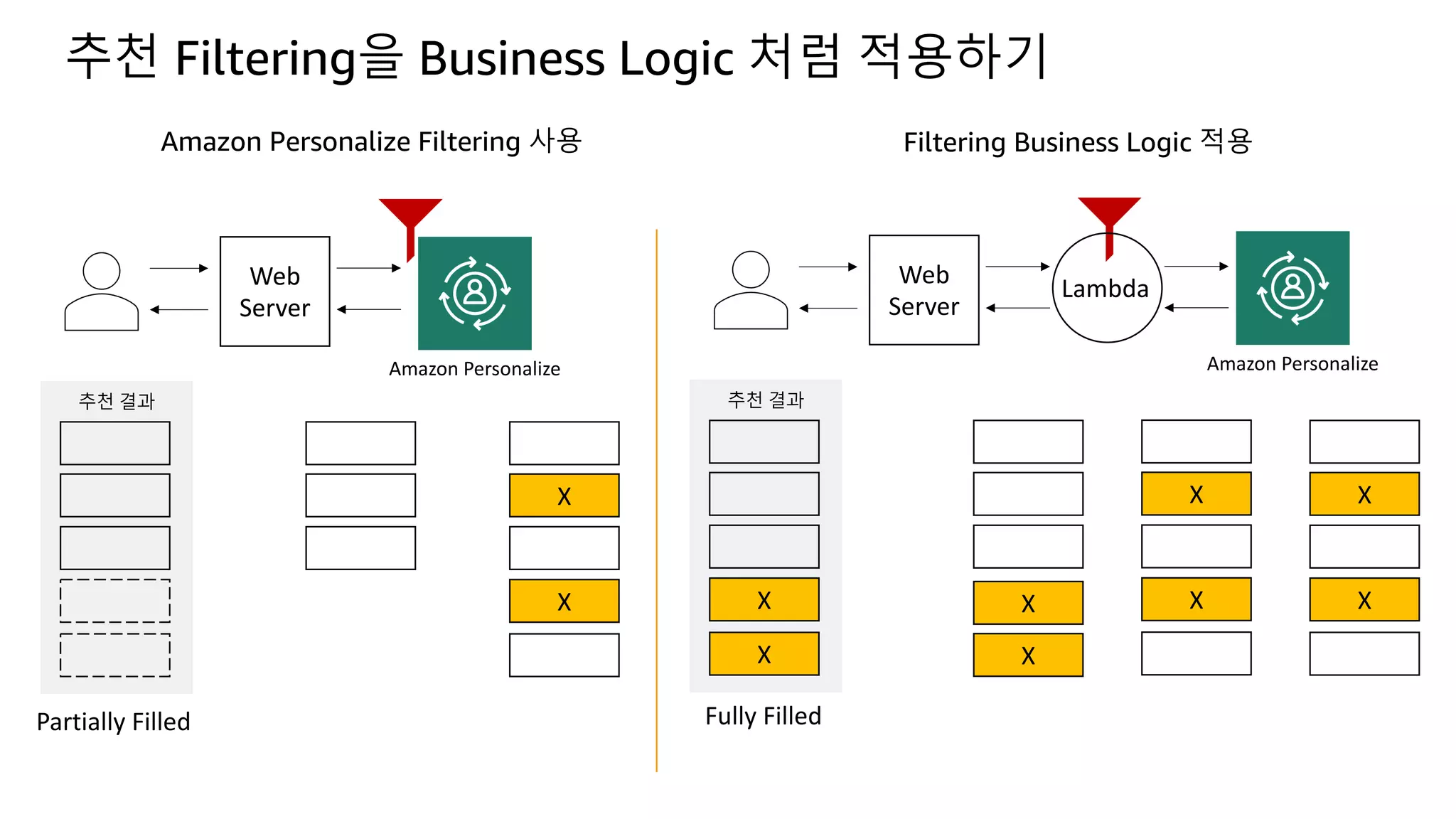

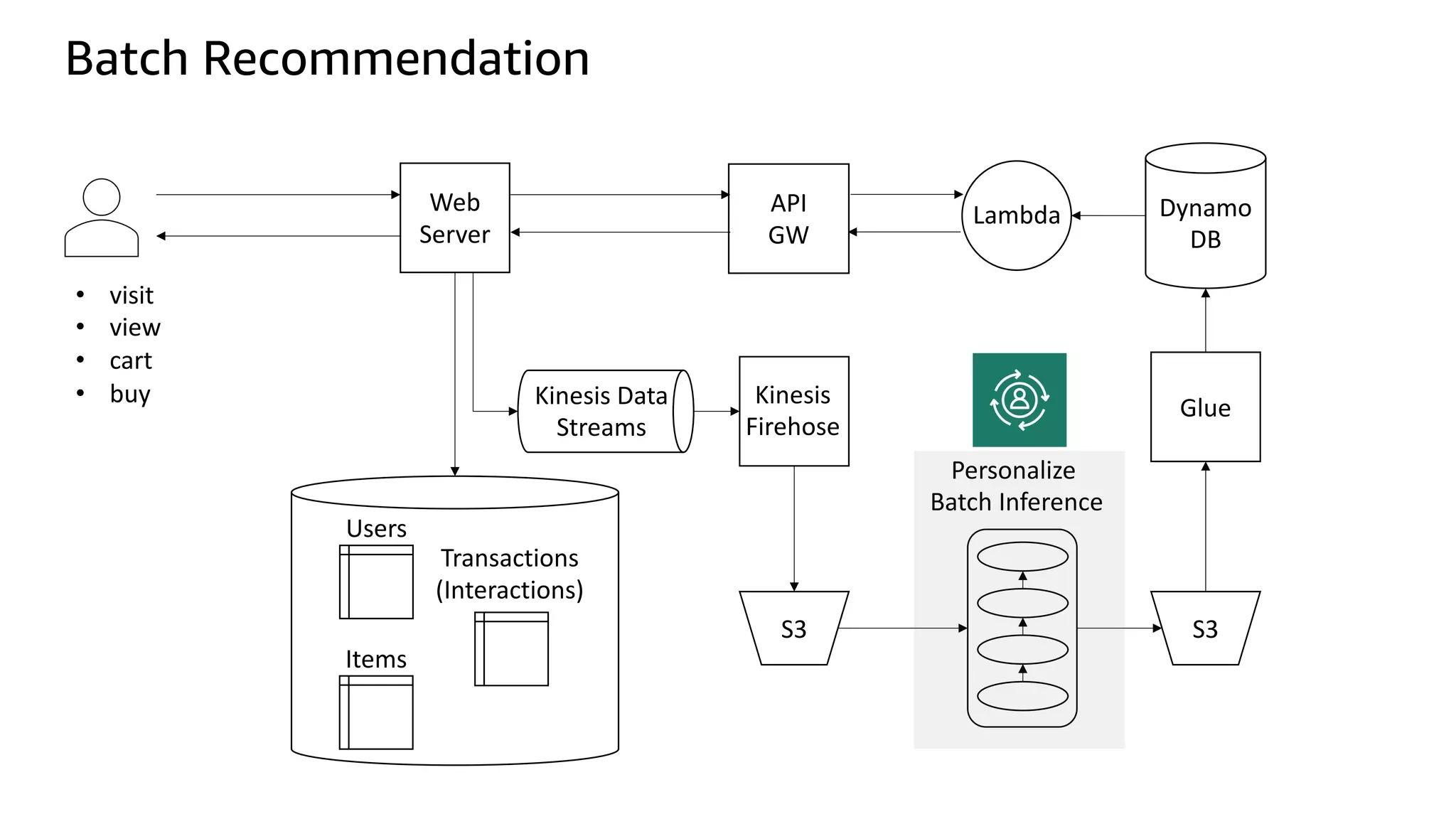
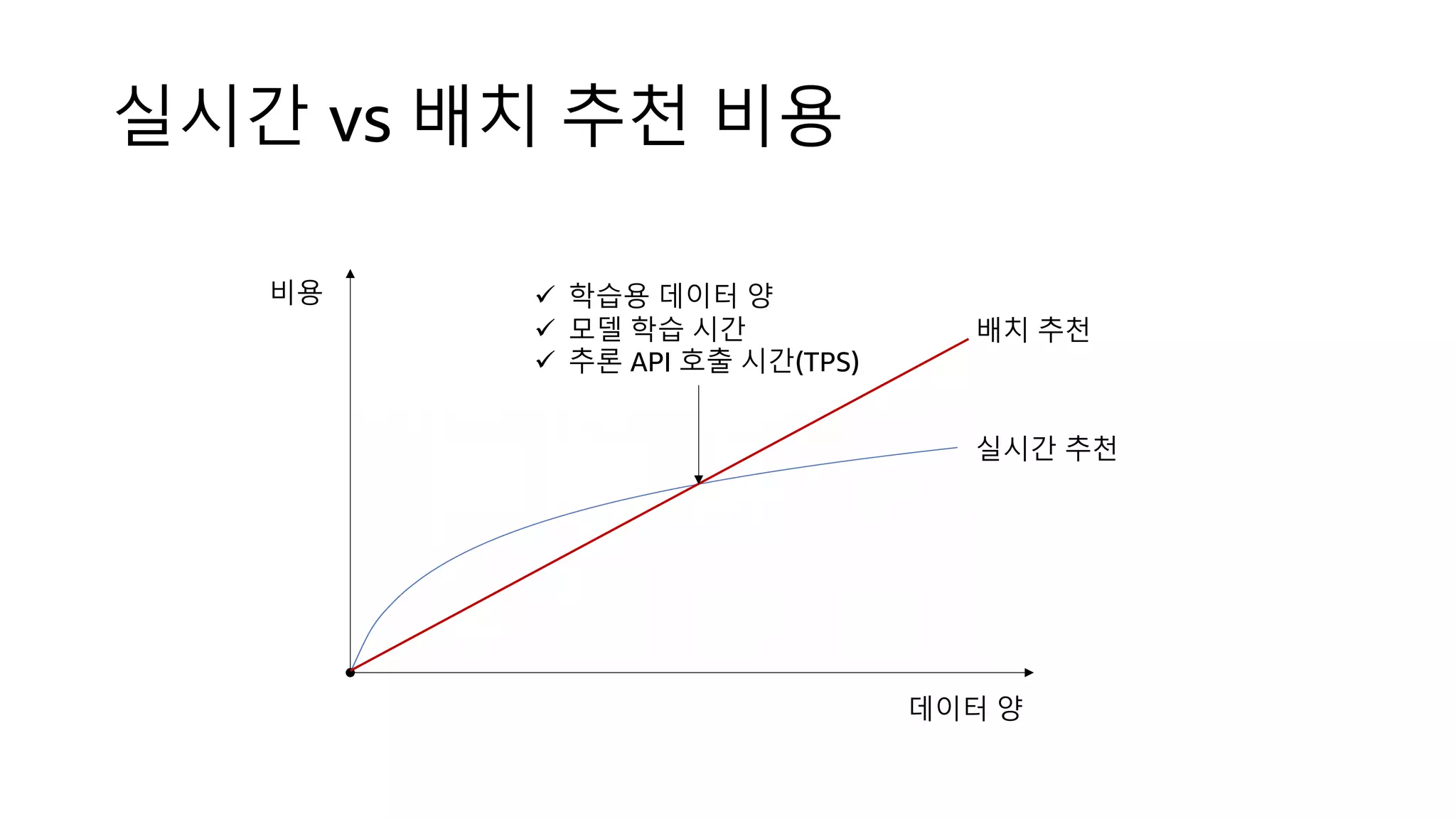





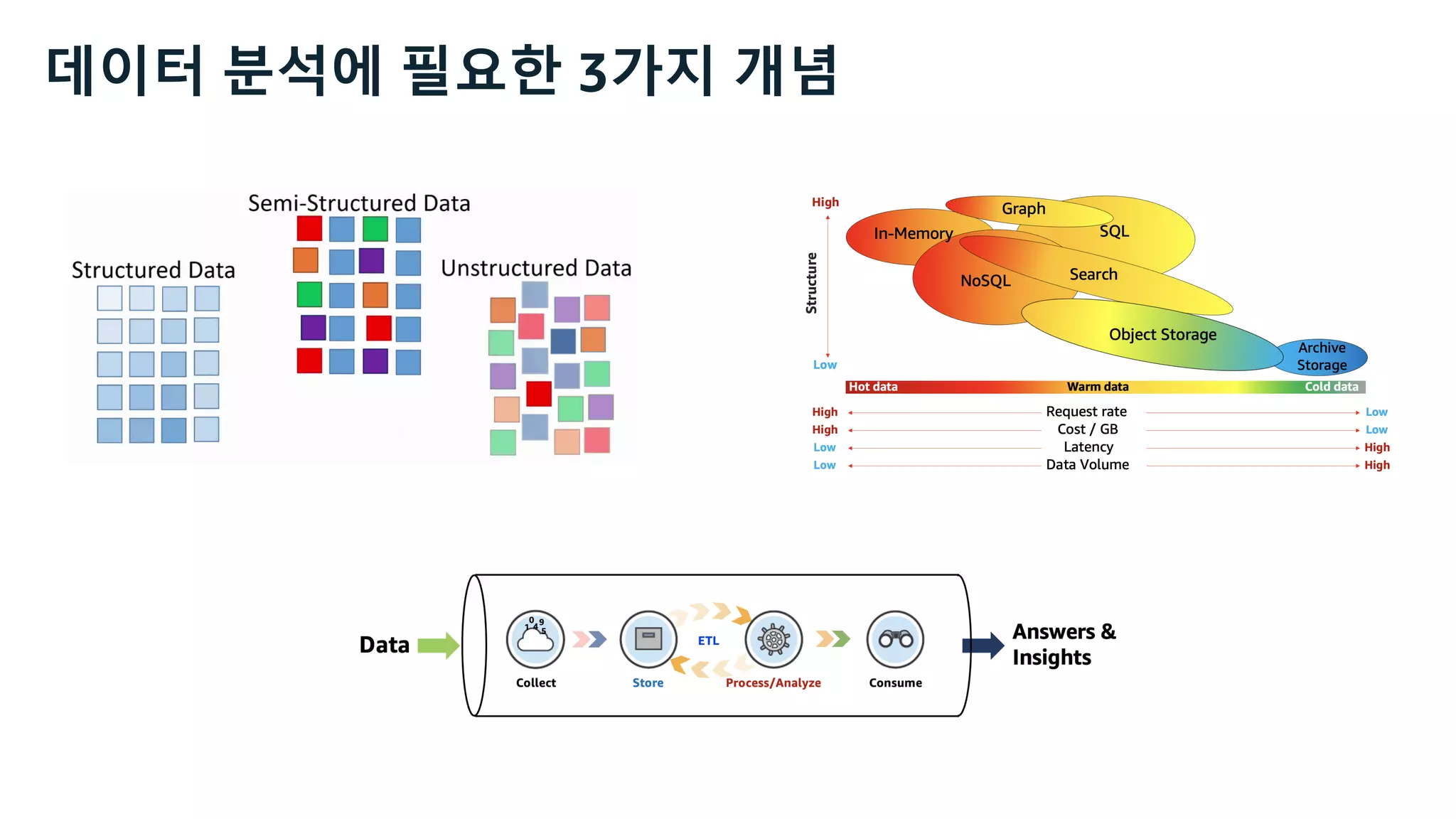
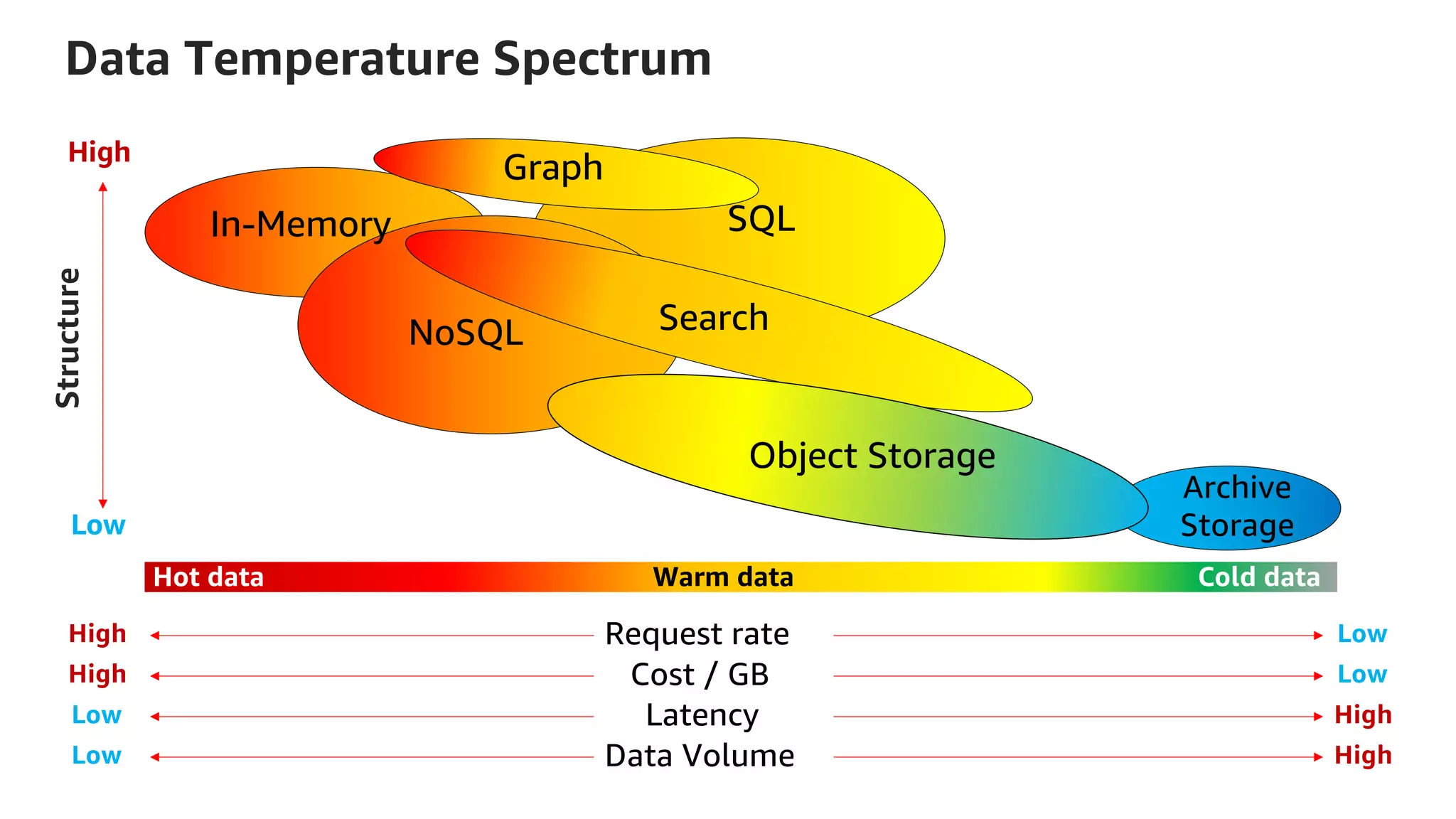
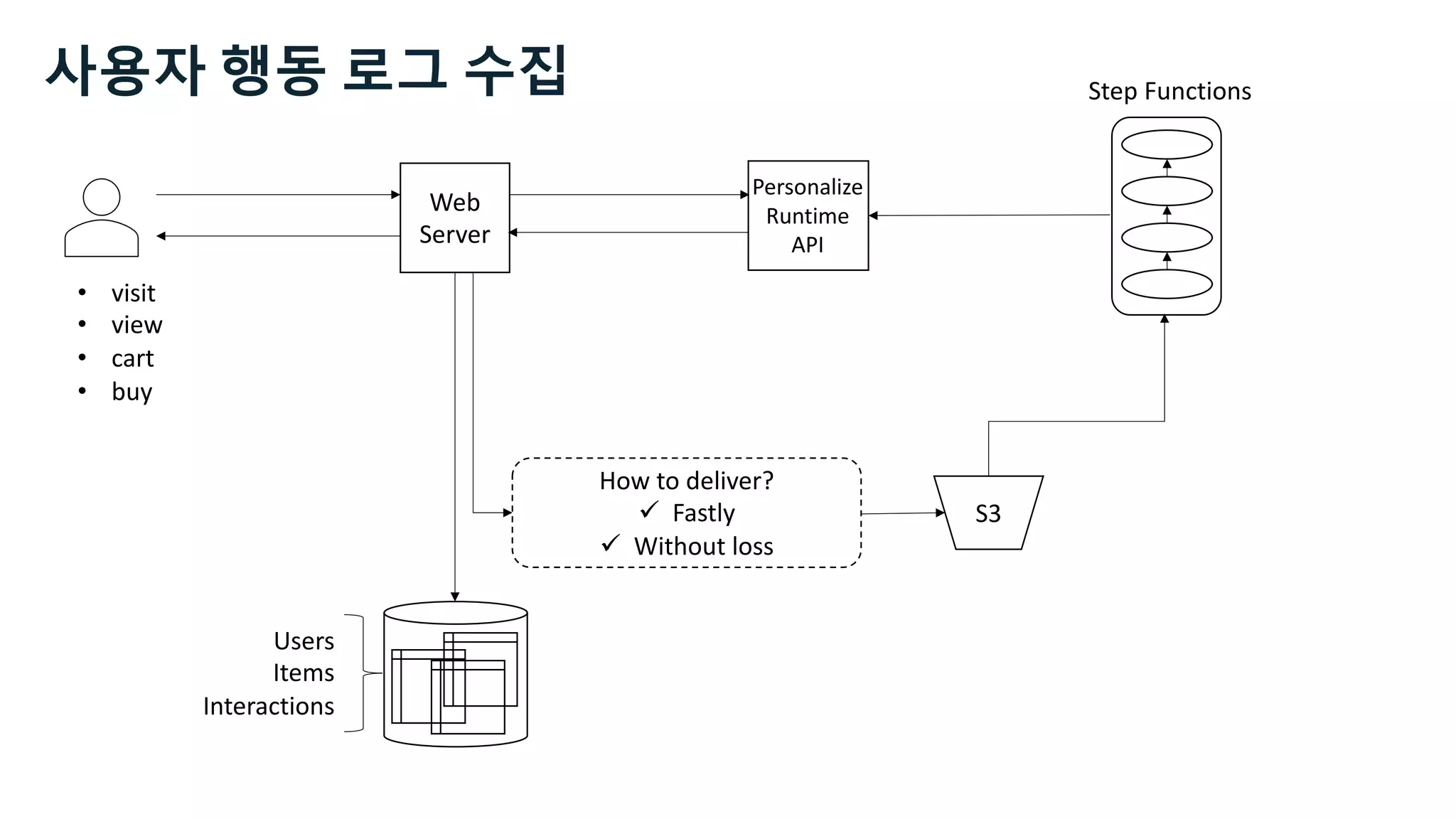
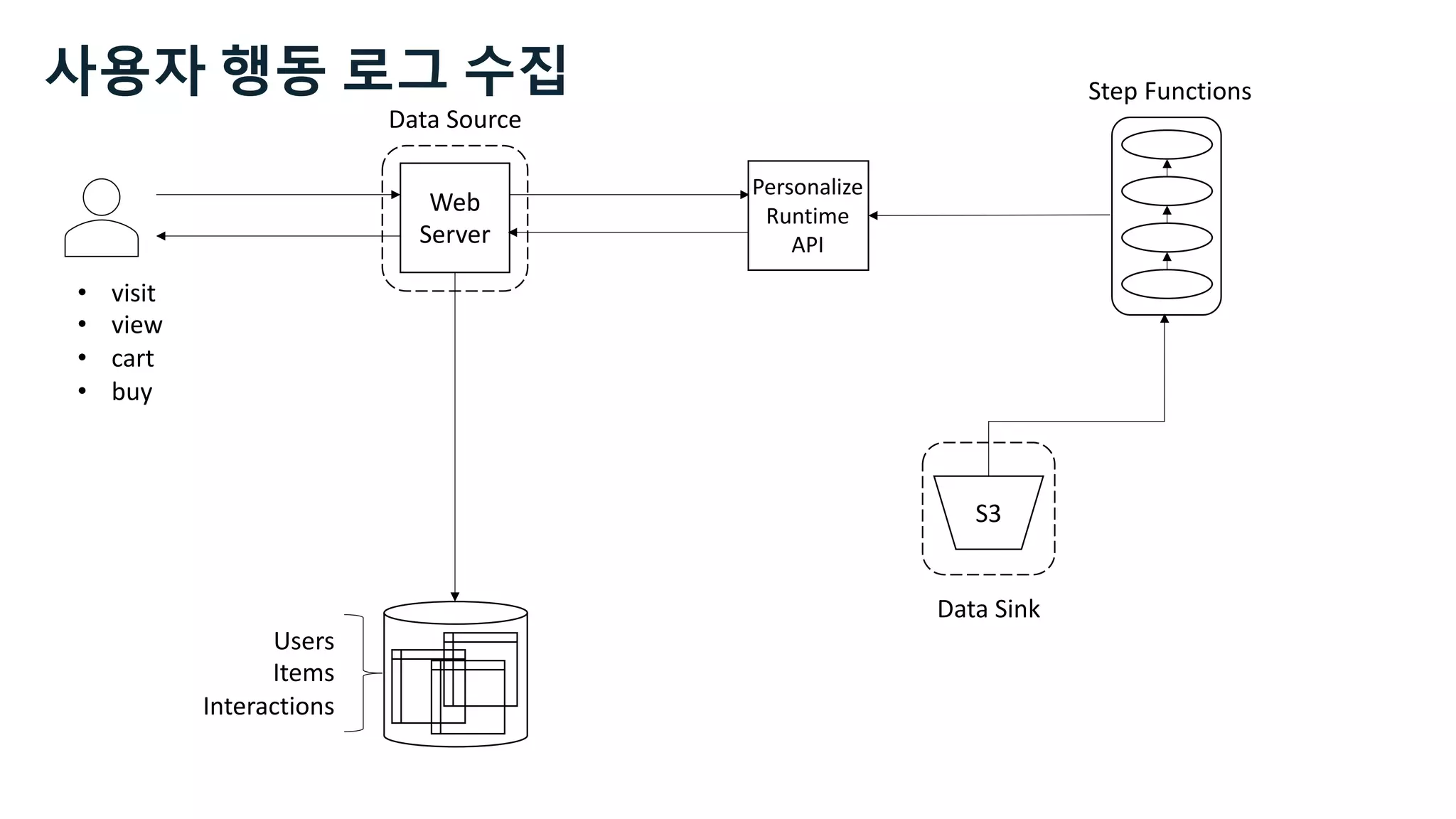
![Kinesis Firehose: Filter, Enrich, Convert
Data
Source
apache log
apache log
json Data
Sink
[Wed Oct 11 14:32:52 2017] [error] [client 192.34.86.178]
[Wed Oct 11 14:32:53 2017] [info] [client 127.0.0.1]
{
"date": "2017/10/11 14:32:52",
"status": "error",
"source": "192.34.86.178",
"city": "Boston",
"state": "MA"
}
geo-ip
{
"recordId": "1",
"result": "Ok",
"data": {
"date": "2017/10/11 14:32:52",
"status": "error",
"source": "192.34.86.178",
"city": "Boston",
"state": "MA"
},
},
{
"recordId": "2",
"result": "Dropped"
}
json
Lambda function
Kinesis
Data Firehose
1
2
3](https://image.slidesharecdn.com/aws-personalize-for-e-commerce-20210407-210412095713/75/AWS-Personalize-85-2048.jpg)

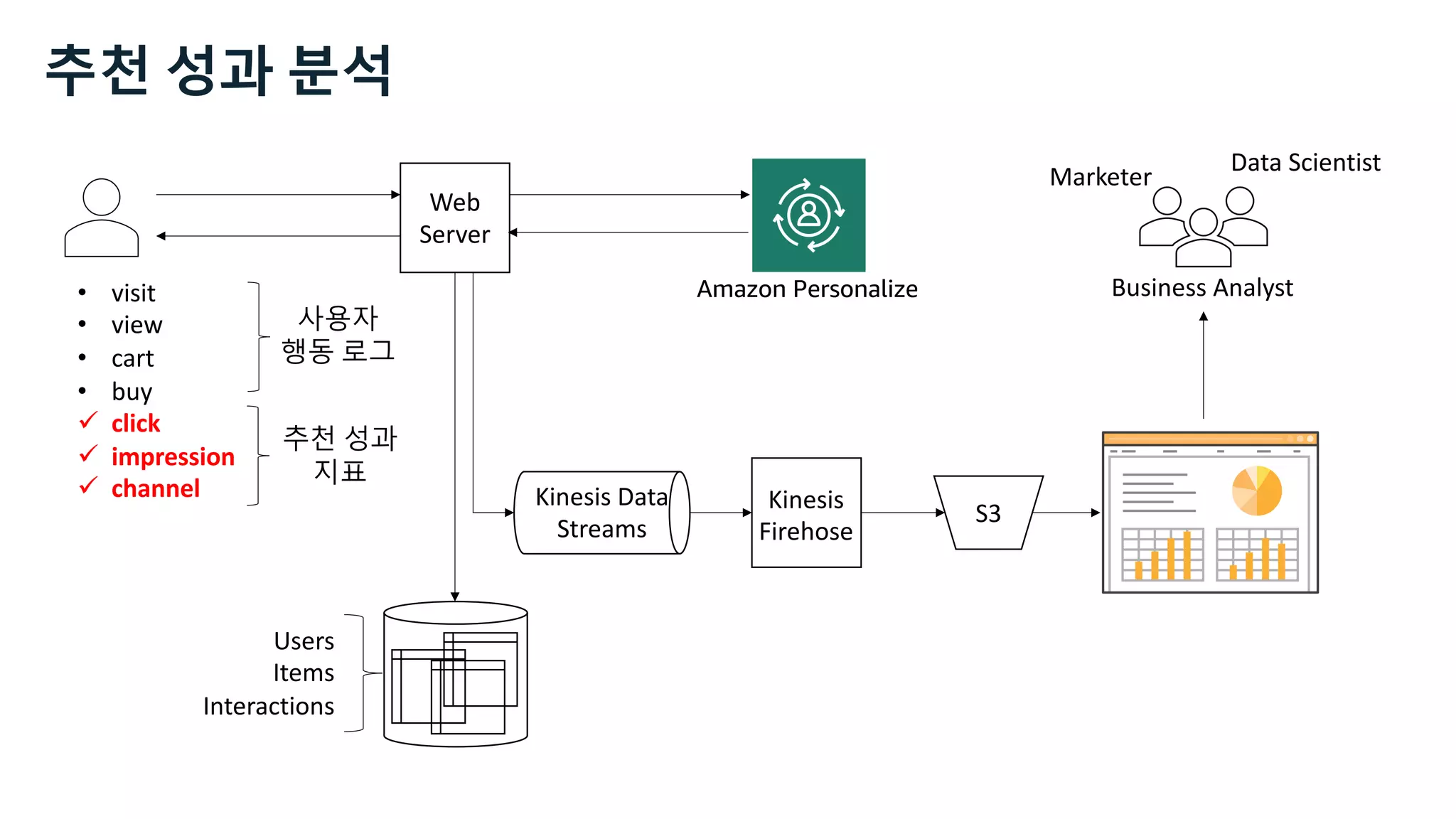
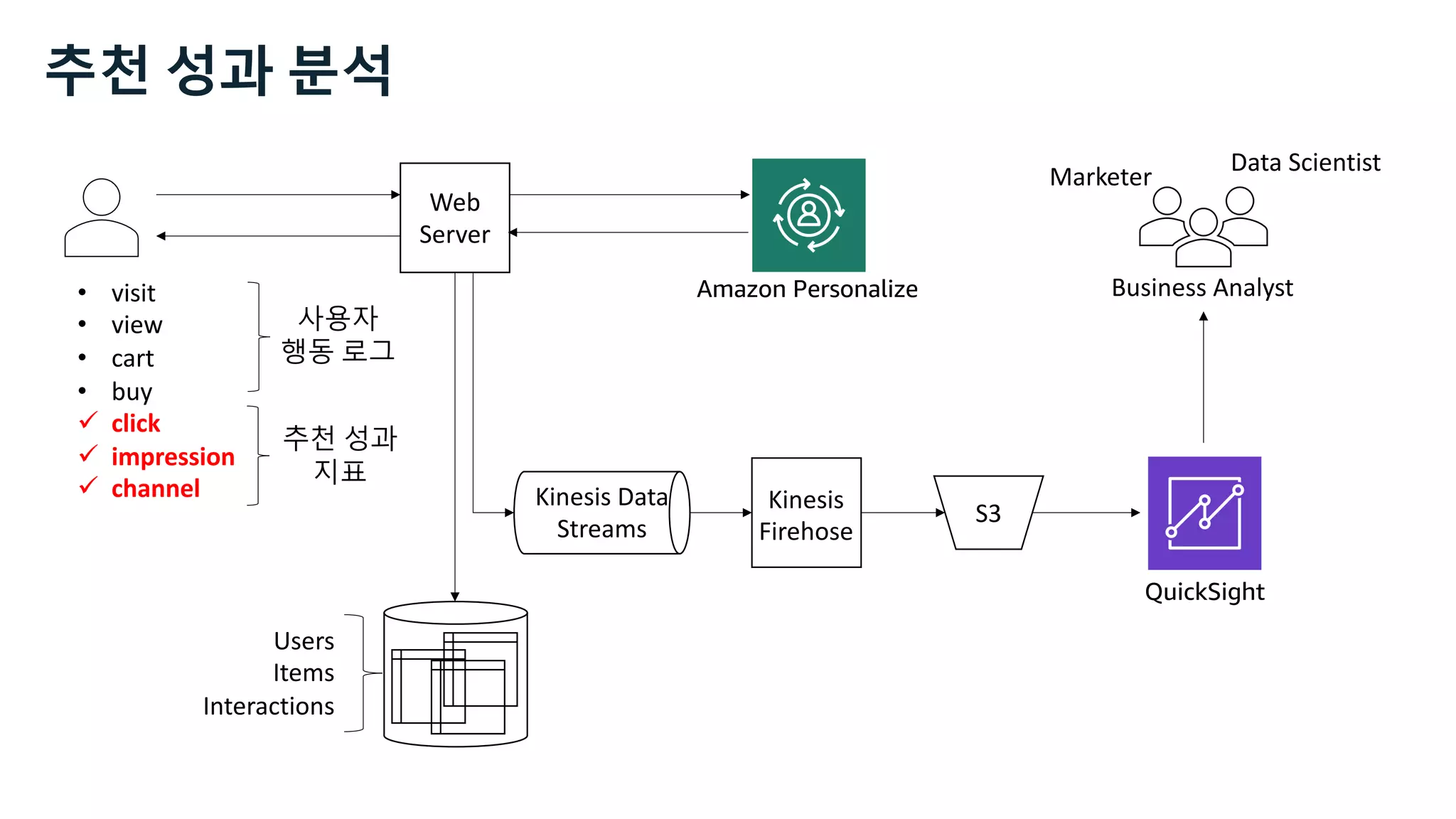

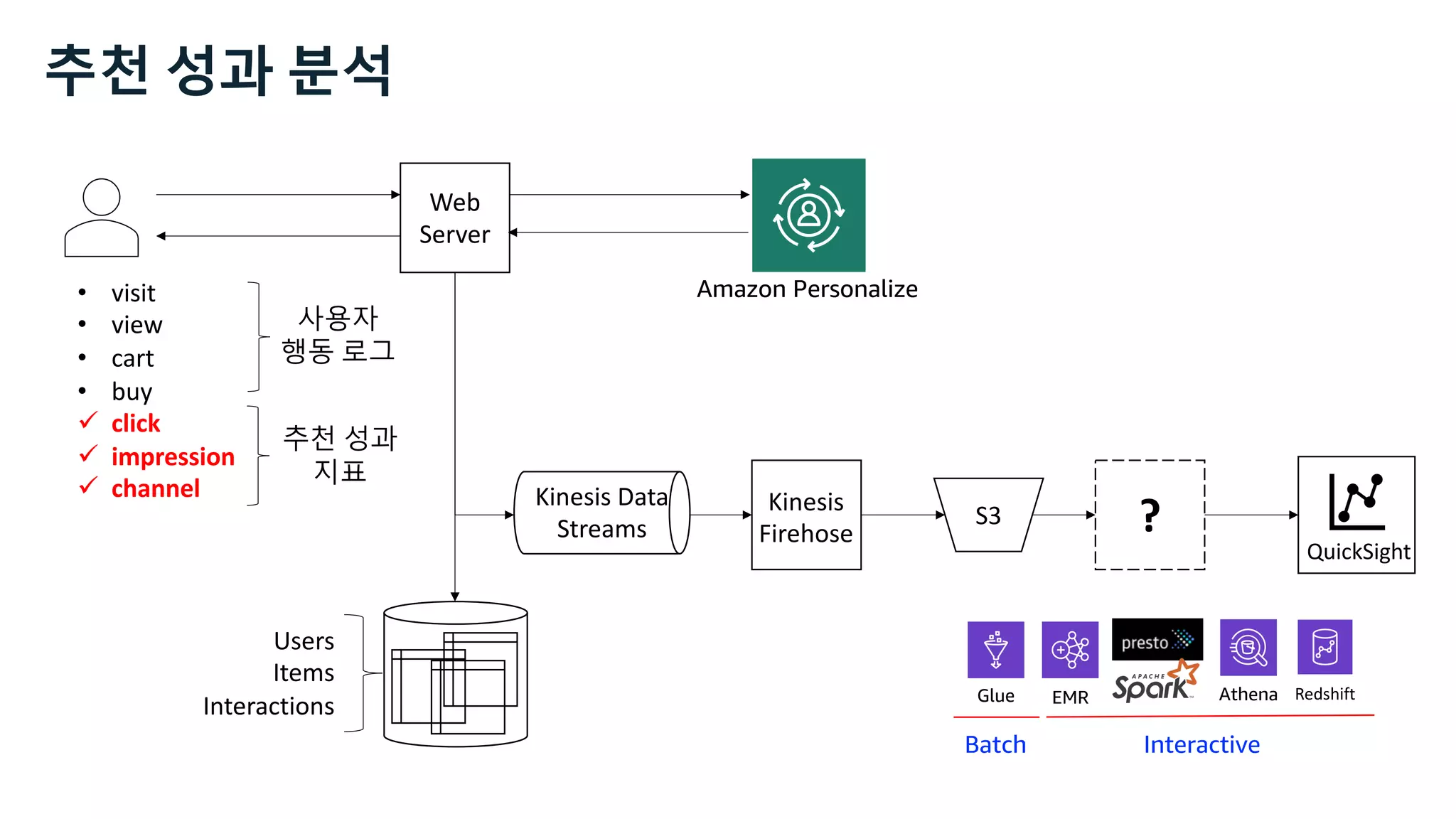
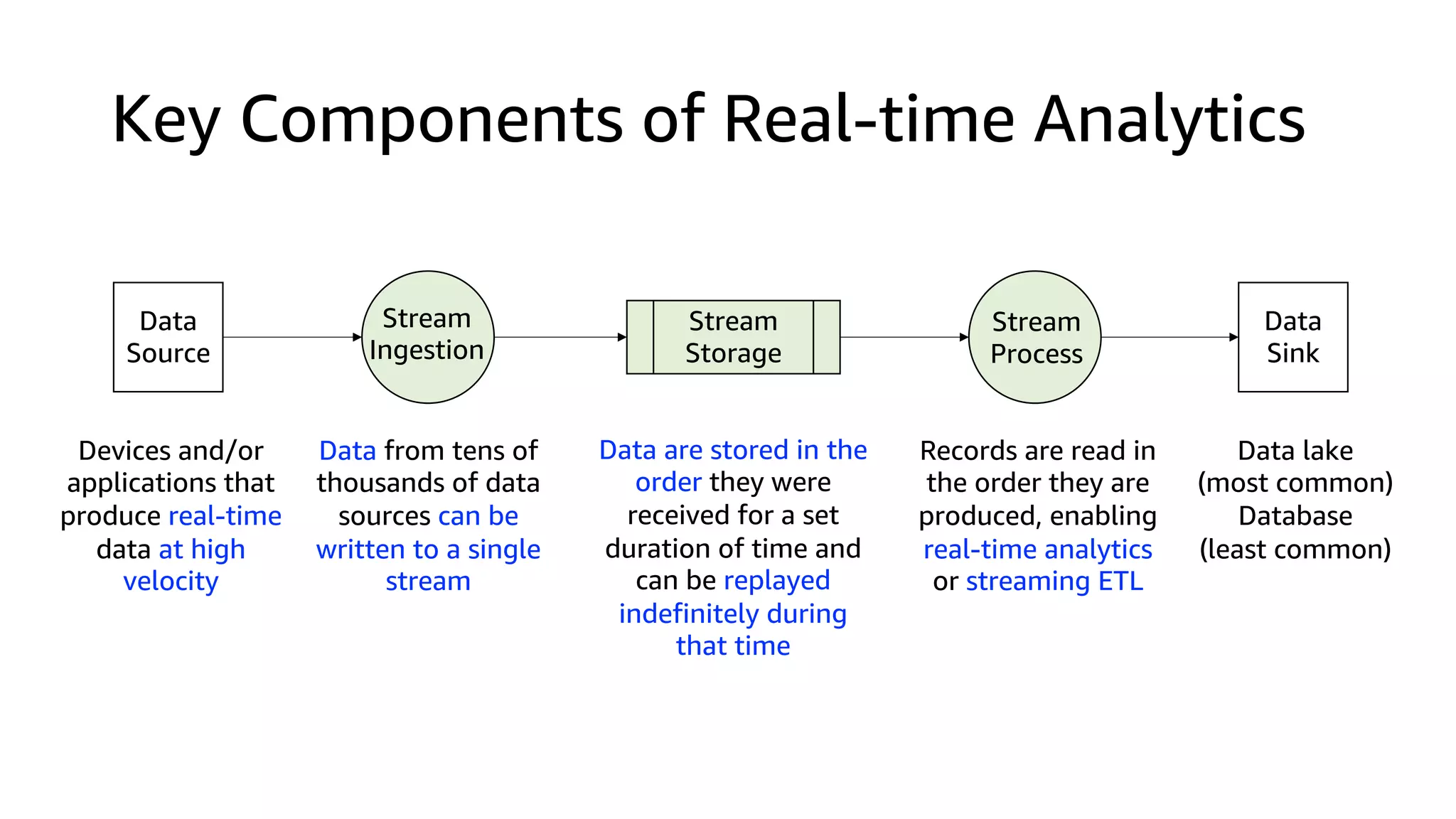
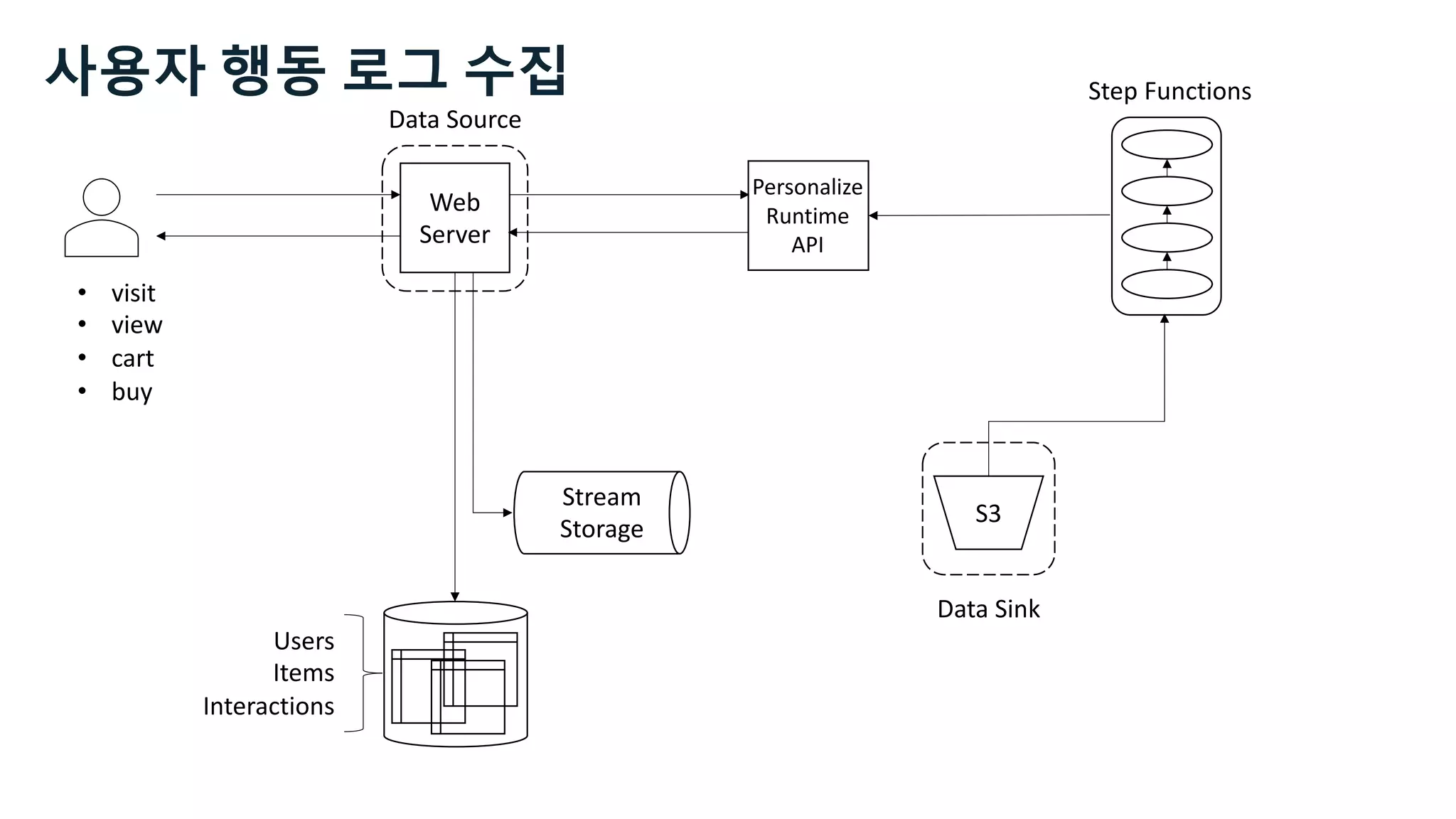
![Kinesis Data Analytics for SQL
Data
Source
Stream
Storage
Stream
Ingestion
Data
Sink
[("It's", 1),
("raining", 1),
("cats", 1),
("and", 1),
("dogs!", 1)]
“It's raining cats and dogs!” It’s 1
raining 1
cats 1
and 1
dogs! 1](https://image.slidesharecdn.com/aws-personalize-for-e-commerce-20210407-210412095713/75/AWS-Personalize-107-2048.jpg)
![Kinesis Data Analytics (SQL)
• STREAM (in-application): a continuously
updated entity that you can SELECT from and
INSERT into like a TABLE
• PUMP: an entity used to continuously
'SELECT ... FROM' a source STREAM, and
INSERT SQL results into an output STREAM
• Create output stream, which can be used to
send to a destination
SOURCE
STREAM
INSERT
& SELECT
(PUMP)
DESTIN.
STREAM
Destination
Source
[("It's", 1),
("raining", 1),
("cats", 1),
("and", 1),
("dogs!", 1)]](https://image.slidesharecdn.com/aws-personalize-for-e-commerce-20210407-210412095713/75/AWS-Personalize-108-2048.jpg)























![대용량 데이터레이크 마이그레이션 사례 공유 [카카오게임즈 - 레벨 200] - 조은희, 팀장, 카카오게임즈 ::: Games on AWS ...](https://cdn.slidesharecdn.com/ss_thumbnails/t4s2-221108115925-5b63bf11-thumbnail.jpg?width=640&height=640&fit=bounds)







![[AWS Hero 스페셜] Amazon Personalize를 통한 개인화/추천 서비스 개발 노하우 - 소성운(크로키닷컴) :: AWS C...](https://cdn.slidesharecdn.com/ss_thumbnails/amazonpersonalize-201017065918-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWS Innovate 온라인 컨퍼런스] Amazon Personalize를 통한 개인화 추천 기능 실전 구현하기 - 최원근, AWS 솔...](https://cdn.slidesharecdn.com/ss_thumbnails/awsinnovateonlineconferenceaimltrack2session4wonkeunchoi-200319071654-thumbnail.jpg?width=640&height=640&fit=bounds)

![[보험사를 위한 AWS Data Analytics Day] 6_Data Analytics의 현재와 미래-토ᄉ...](https://cdn.slidesharecdn.com/ss_thumbnails/awsdataanalyticsday6dataanalytics-joonghoonshin-230608071358-4a8f71ec-thumbnail.jpg?width=640&height=640&fit=bounds)











![[금융사를 위한 AWS Generative AI Day 2023] 4_AWS Generative AI 서비스의 활용 방ᄇ...](https://cdn.slidesharecdn.com/ss_thumbnails/4awsgenerativeaiaws-230818063630-9fd7ffea-thumbnail.jpg?width=640&height=640&fit=bounds)






![[AWS summit 2019] 마이크로 서비스 패턴 데이터 베이스](https://cdn.slidesharecdn.com/ss_thumbnails/awssummit2019jkhkyd20190417final-191217131802-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)