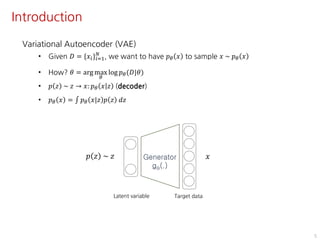
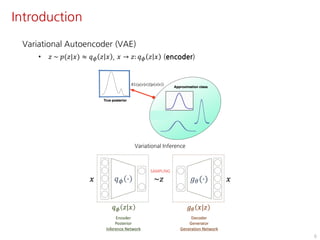
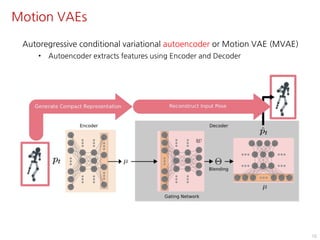
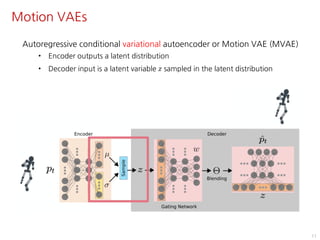
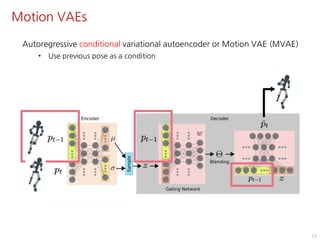
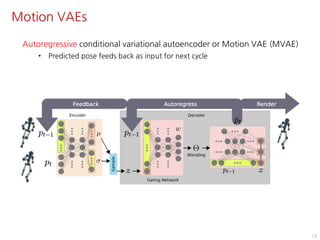
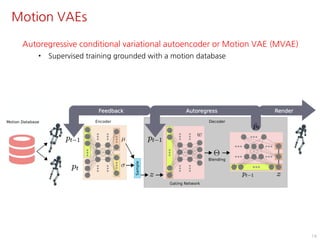
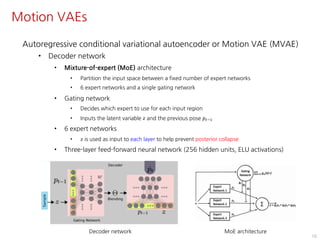
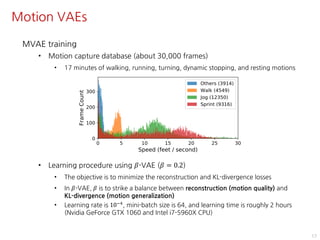
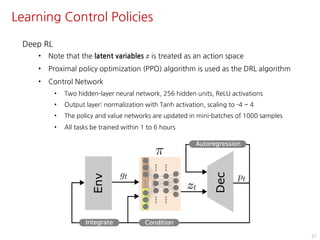
The document discusses the development of character controllers using motion variational autoencoders (MVAEs) and deep reinforcement learning (RL) for generating purposeful motions based on example motions. It outlines a two-step approach, involving a kinematic generative model and a learning controller, and details various locomotion tasks such as target navigation and maze exploration. The training employs a motion capture database and techniques to manage stability and generalization in motion synthesis.


















































![[1808.00177] Learning Dexterous In-Hand Manipulation](https://cdn.slidesharecdn.com/ss_thumbnails/learningdextrousinhandmanipulation-180814000608-thumbnail.jpg?width=640&height=640&fit=bounds)














































