Download to read offline



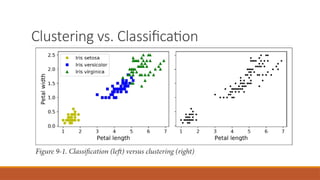









The document discusses unsupervised learning, focusing on clustering as a method to group similar instances without labeled data. It details the k-means algorithm for efficient clustering and highlights improvements like k-means++ for better centroid initialization. Additionally, it covers essential k-means functionalities and parameter settings for optimal performance.
































































