1
DISTRIBUTED STORAGE
A distributeddatabase is basically a database that is not limited to one system, it is
spread over different sites, i.e, on multiple computers or over a network of
computers. A distributed database system is located on various sites that don’t share
physical components. This may be required when a particular database needs to be
accessed by various users globally.
Homogeneous Database:
In a homogeneous database, all different sites store database identically. The
operating system, database management system, and the data structures used – all
are the same at all sites. Hence, they’re easy to manage.
2. Heterogeneous Database:
In a heterogeneous distributed database, different sites can use different schema
and software that can lead to problems in query processing and transactions. Also, a
particular site might be completely unaware of the other sites.
2.
2
Distributed Data Storage:
There are 2 ways in which data can be stored on different sites. These are:
1. Replication –
In this approach, the entire relationship is stored redundantly at 2 or more sites. If the entire
database is available at all sites, it is a fully redundant database. Hence, in replication,
systems maintain copies of data.
This is advantageous as it increases the availability of data at different sites. Also, now query
requests can be processed in parallel.
2. Fragmentation –
In this approach, the relations are fragmented (i.e., they’re divided into smaller parts) and each
of the fragments is stored in different sites where they’re required. It must be made sure that
the fragments are such that they can be used to reconstruct the original relation (i.e, there isn’t
any loss of data).
3.
3
Applications of DistributedDatabase:
•It is used in Corporate Management Information System.
•It is used in multimedia applications.
•Used in Military’s control system, Hotel chains etc.
•It is also used in manufacturing control system.
4.
4
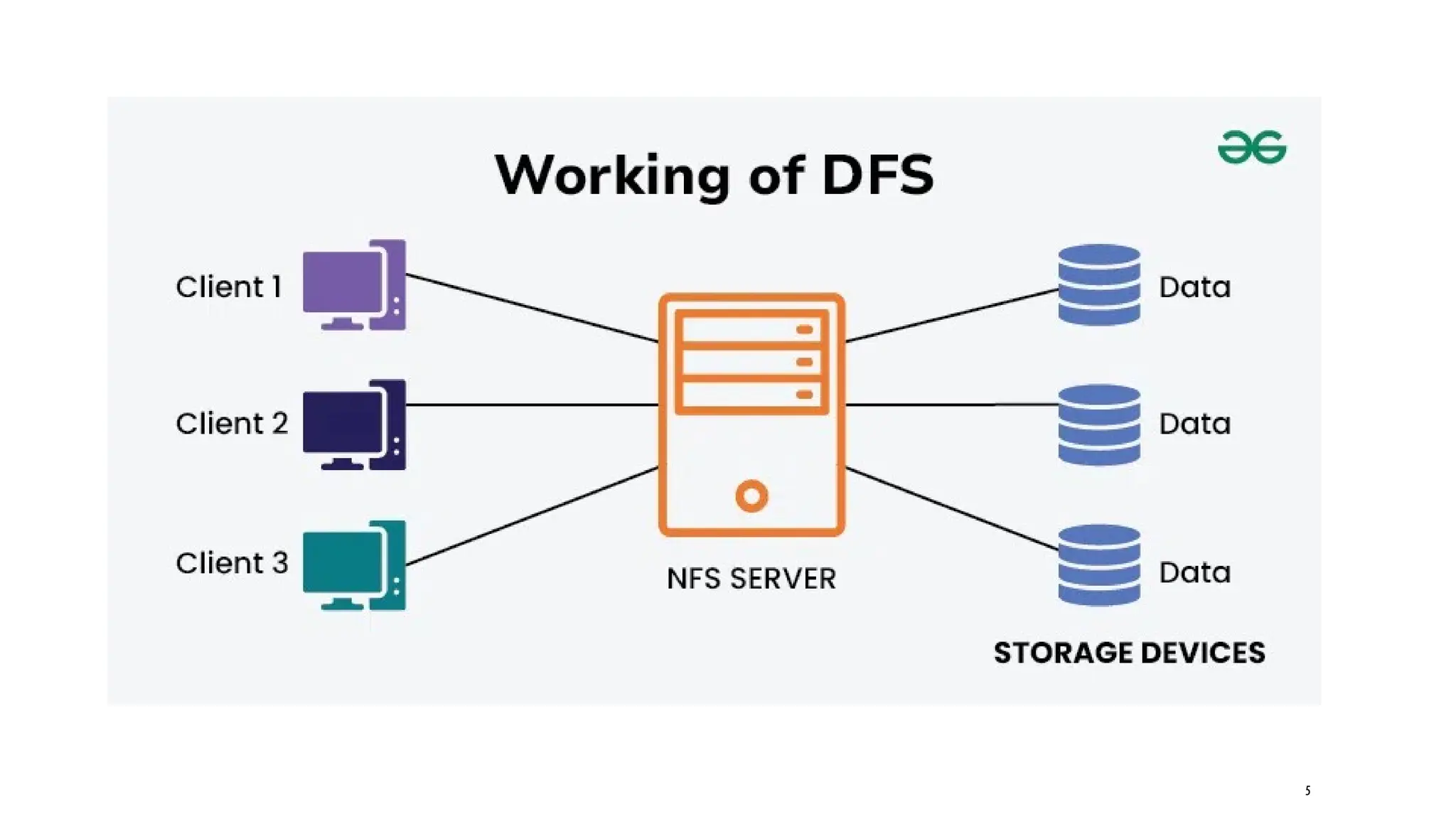
DISTRIBUTED FILE SYSTEM
Adistributed file system (DFS) is a networked architecture that allows multiple users
and applications to access and manage files across various machines as if they were
on a local storage device. Instead of storing data on a single server, a DFS spreads files
across multiple locations, enhancing redundancy and reliability.
There are two ways in which DFS can be implemented:
•Standalone DFS namespace: It allows only for those DFS roots that exist on the local
computer and are not using Active Directory. A Standalone DFS can only be acquired
on those computers on which it is created. It does not provide any fault liberation and
cannot be linked to any other DFS. Standalone DFS roots are rarely come across
because of their limited advantage.
•Domain-based DFS namespace: It stores the configuration of DFS in Active Directory,
creating the DFS namespace root accessible at <domainname><dfsroot>
6
Advantages of DistributedFile System(DFS)
•DFS allows multiple user to access or store the data.
•It allows the data to be share remotely.
•It improved the availability of file, access time, and network efficiency.
Disadvantages of Distributed File System(DFS)
•In Distributed File System nodes and connections needs to be secured
therefore we can say that security is at stake.
•Database connection in case of Distributed File System is complicated.
•Also handling of the database is not easy in Distributed File System as
compared to a single user system.
7.
7
DISTRIBUTED DATABASE ANDITS TRANSPARENCY
Distributed relational database (RDB) design involves organizing a relational database
system such that data is stored across multiple locations (nodes) while maintaining consistency,
availability, and scalability. It aims to improve performance, reliability, and fault tolerance in
large-scale applications.
What is transparency?
Transparency in distributed relational database design refers to how the system hides the
complexities of data distribution, replication, and fragmentation from users and applications.
It ensures that users interact with the database as though it were a centralized system,
regardless of its distributed nature.
8.
8
Location Transparency
•Definition:Users and applications do not need to know where the data is physically
stored.
•Benefits:
• Simplifies query formulation since users do not need to include storage details.
• Makes it easier to move data between nodes without affecting applications.
Replication Transparency
•Definition: Users are unaware of whether data is replicated across multiple nodes or
how replication is managed.
•Benefits:
• Users don’t have to deal with managing replicas or ensuring data consistency.
• Fault tolerance and load balancing are handled behind the scenes.
9.
9
Fragmentation Transparency
•Definition: Usersare not concerned with whether the data is fragmented (divided into smaller
pieces) and distributed across multiple nodes.
•Types of Fragmentation:
• Horizontal Fragmentation: Rows are distributed across nodes.
• Vertical Fragmentation: Columns are distributed across nodes.
Failure Transparency
•Definition: Users do not experience service interruptions or inconsistencies due to node or
network failures.
•Benefits:
• Ensures reliability and fault tolerance.
• Provides a seamless user experience even in the presence of failures.
10.
10
Performance Transparency
•Definition: Thesystem ensures that distributed query execution is optimized for performance
without user intervention.
•Benefits:
• Users don’t need to optimize queries based on data distribution or network latency.